【Anaconda安装Python的终极指南】:一步步掌握Python环境配置,避免常见问题和性能优化
发布时间: 2024-06-22 05:52:20 阅读量: 7 订阅数: 17 

# 1. Anaconda安装Python环境概述
Anaconda是一个用于科学计算、数据科学和机器学习的开源平台。它提供了Python环境,其中包含了一系列预安装的科学包和库,使开发人员能够轻松地设置和管理Python项目。
Anaconda安装提供了多种好处,包括:
- **预配置的Python环境:**Anaconda提供了预先配置的Python环境,其中包含了用于科学计算和数据科学的常用包和库。
- **包管理:**Anaconda附带了Conda包管理器,它可以轻松地安装、更新和管理Python包。
- **跨平台兼容性:**Anaconda可在Windows、macOS和Linux系统上使用,提供了跨平台的兼容性。
# 2. Python环境搭建实践
### 2.1 Anaconda安装步骤详解
#### 2.1.1 下载和安装Anaconda
1. **下载Anaconda安装程序:**访问Anaconda官方网站(https://www.anaconda.com/products/individual),根据你的操作系统选择对应的安装程序。
2. **运行安装程序:**双击下载的安装程序,按照提示进行安装。
3. **选择安装路径:**选择Anaconda的安装路径,建议安装在默认路径(C:\ProgramData\Anaconda3)。
4. **安装选项:**选择“Just Me”选项,仅为当前用户安装Anaconda。
5. **环境变量设置:**勾选“Add Anaconda to my PATH environment variable”选项,将Anaconda添加到系统环境变量中。
6. **完成安装:**单击“Install”按钮开始安装。
#### 2.1.2 创建和激活Python环境
1. **打开Anaconda Navigator:**安装完成后,打开Anaconda Navigator,这是一个图形化界面,用于管理Anaconda环境。
2. **创建新环境:**单击“Environments”选项卡,然后单击“Create”按钮。
3. **命名环境:**输入新环境的名称,例如“myenv”。
4. **选择Python版本:**从下拉菜单中选择所需的Python版本。
5. **安装包:**在“Packages”选项卡中,搜索并安装所需的包。
6. **激活环境:**单击“Apply”按钮创建环境,然后单击环境名称将其激活。
### 2.2 常见问题及解决方法
#### 2.2.1 安装失败
* **解决方案:**
* 检查网络连接是否稳定。
* 确保有足够的磁盘空间。
* 尝试使用管理员权限重新安装。
#### 2.2.2 环境激活失败
* **解决方案:**
* 确保已安装Anaconda。
* 检查环境变量是否已正确设置。
* 尝试使用命令行激活环境:`conda activate myenv`。
#### 2.2.3 依赖包安装问题
* **解决方案:**
* 检查网络连接是否稳定。
* 确保Anaconda已更新到最新版本。
* 尝试使用命令行安装包:`conda install package_name`。
* 如果安装失败,尝试使用`--force`选项:`conda install package_name --force`。
# 3. Python环境配置优化
### 3.1 性能优化技巧
#### 3.1.1 优化代码结构
- **避免使用嵌套循环:**嵌套循环会显著降低代码效率,特别是当内层循环的迭代次数较多时。
- **使用列表解析式和生成器:**列表解析式和生成器可以代替传统的循环,提高代码可读性和效率。
- **使用函数和模块:**将代码组织成函数和模块可以提高代码的可重用性和可维护性,同时也能优化性能。
#### 3.1.2 使用高效的数据结构
- **选择合适的列表类型:**Python提供了多种列表类型,如列表、元组和字典。选择合适的列表类型可以提高代码效率。
- **使用NumPy数组:**NumPy数组是用于科学计算的高性能数据结构,比Python列表具有更好的性能。
- **使用Pandas数据框:**Pandas数据框是用于数据处理和分析的高性能数据结构,具有丰富的功能和高效的算法。
#### 3.1.3 避免不必要的循环
- **使用惰性求值:**惰性求值可以推迟计算,直到需要结果时才执行,从而避免不必要的循环。
- **使用切片操作:**切片操作可以高效地提取列表或数组的子集,避免不必要的循环。
- **使用集合操作:**集合操作可以快速查找和合并元素,避免不必要的循环。
### 3.2 依赖包管理
#### 3.2.1 安装和更新依赖包
- **使用pip命令:**pip是Python的包管理工具,用于安装和更新依赖包。
- **使用requirements.txt文件:**requirements.txt文件列出项目所需的依赖包,可以方便地管理和更新依赖包。
- **使用虚拟环境:**虚拟环境可以隔离不同项目的依赖包,避免冲突和版本问题。
#### 3.2.2 卸载和管理依赖包
- **使用pip uninstall命令:**pip uninstall命令用于卸载依赖包。
- **使用pip freeze命令:**pip freeze命令列出已安装的依赖包及其版本。
- **使用pip list命令:**pip list命令列出已安装的依赖包及其详细信息。
#### 3.2.3 依赖包冲突解决
- **检查依赖包版本:**依赖包冲突通常是由不同版本的依赖包引起的。
- **使用pip install --upgrade命令:**pip install --upgrade命令可以更新已安装的依赖包,解决版本冲突。
- **使用pip install --force-reinstall命令:**pip install --force-reinstall命令可以强制重新安装依赖包,解决冲突。
# 4. Python环境使用技巧
### 4.1 Python虚拟环境
#### 4.1.1 创建和管理虚拟环境
虚拟环境是Python中的一种隔离机制,它允许用户在隔离的环境中安装和运行Python包,而不会影响系统范围内的Python安装。
要创建虚拟环境,可以使用以下命令:
```
python -m venv venv_name
```
其中`venv_name`是虚拟环境的名称。
创建虚拟环境后,可以通过以下命令激活它:
```
source venv_name/bin/activate
```
激活虚拟环境后,所有在该环境中安装的包都将与系统范围内的Python安装隔离。要退出虚拟环境,可以使用以下命令:
```
deactivate
```
#### 4.1.2 虚拟环境的优势和局限性
虚拟环境具有以下优势:
- **隔离性:**虚拟环境中的包与系统范围内的Python安装隔离,因此不会影响其他应用程序或系统组件。
- **可移植性:**虚拟环境可以轻松地打包和共享,允许用户在不同的机器上使用相同的Python环境。
- **版本控制:**虚拟环境可以版本控制,允许用户跟踪和管理不同的Python环境。
虚拟环境也有一些局限性:
- **资源消耗:**每个虚拟环境都包含自己的Python解释器和库,这可能会消耗额外的系统资源。
- **管理复杂性:**管理多个虚拟环境可能会变得复杂,尤其是当需要在不同的环境之间切换时。
### 4.2 Python包和模块
#### 4.2.1 安装和导入Python包
Python包是一组相关的模块,用于执行特定任务。包可以从Python包索引(PyPI)安装,这是一个包含大量Python包的中央存储库。
要安装一个包,可以使用以下命令:
```
pip install package_name
```
安装包后,可以使用以下命令导入它:
```
import package_name
```
#### 4.2.2 创建和发布自己的Python包
用户还可以创建和发布自己的Python包。要创建包,需要创建一个包含以下文件的目录:
- `__init__.py`:一个空文件,表示目录是一个Python包。
- `setup.py`:一个包含包元数据(如名称、版本和依赖项)的脚本。
创建包后,可以使用以下命令将其发布到PyPI:
```
python setup.py sdist upload
```
# 5. Python环境高级应用
### 5.1 Python与其他语言集成
#### 5.1.1 Python与C/C++集成
Python与C/C++集成主要通过以下两种方式实现:
- **使用Cython:** Cython是一种编译器,可以将Python代码编译成C/C++代码,从而提高Python代码的执行效率。
- **使用Ctypes:** Ctypes是一个Python库,允许Python代码直接调用C/C++函数和数据结构。
**代码块:**
```python
# 使用Cython编译Python代码
import cython
@cython.cclass
class MyClass:
def __init__(self, value):
self.value = value
def square(self):
return self.value ** 2
```
**逻辑分析:**
这段代码使用Cython将一个简单的Python类编译成C/C++代码。`@cython.cclass`装饰器将类标记为一个C/C++类,而`__init__`和`square`方法则定义了类的构造函数和一个方法。
**参数说明:**
- `value`:`MyClass`类的构造函数参数,用于初始化类的`value`属性。
#### 5.1.2 Python与Java集成
Python与Java集成主要通过以下两种方式实现:
- **使用Jython:** Jython是一个Python解释器,可以运行在Java虚拟机上,从而允许Python代码与Java代码交互。
- **使用JPype:** JPype是一个Python库,允许Python代码直接调用Java类和方法。
**代码块:**
```python
# 使用JPype调用Java类
import jpype
# 启动Java虚拟机
jpype.startJVM()
# 加载Java类
MyClass = jpype.JClass("com.example.MyClass")
# 创建Java对象
my_object = MyClass()
# 调用Java方法
result = my_object.square(5)
# 关闭Java虚拟机
jpype.shutdownJVM()
```
**逻辑分析:**
这段代码使用JPype调用一个Java类的方法。`jpype.startJVM()`启动Java虚拟机,`jpype.JClass()`加载Java类,`MyClass()`创建Java对象,`my_object.square()`调用Java方法,最后`jpype.shutdownJVM()`关闭Java虚拟机。
**参数说明:**
- `com.example.MyClass`:要加载的Java类的完全限定名。
- `5`:要传递给Java方法的参数。
### 5.2 Python并发编程
#### 5.2.1 多线程和多进程
Python支持多线程和多进程两种并发编程方式:
- **多线程:** 在同一进程中创建多个线程,共享同一内存空间。
- **多进程:** 创建多个进程,每个进程都有自己的内存空间。
**代码块:**
```python
# 多线程示例
import threading
def worker(num):
print(f"Worker {num} started")
# 模拟耗时操作
time.sleep(1)
print(f"Worker {num} finished")
# 创建和启动线程
threads = []
for i in range(5):
thread = threading.Thread(target=worker, args=(i,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
```
**逻辑分析:**
这段代码创建了5个线程,每个线程都运行`worker()`函数。`threading.Thread()`创建线程,`target`参数指定要运行的函数,`args`参数传递给函数的参数。`thread.start()`启动线程,`thread.join()`等待线程完成。
**参数说明:**
- `num`:传递给`worker()`函数的参数,用于标识线程。
```python
# 多进程示例
import multiprocessing
def worker(num):
print(f"Worker {num} started")
# 模拟耗时操作
time.sleep(1)
print(f"Worker {num} finished")
# 创建和启动进程
processes = []
for i in range(5):
process = multiprocessing.Process(target=worker, args=(i,))
processes.append(process)
process.start()
# 等待所有进程完成
for process in processes:
process.join()
```
**逻辑分析:**
这段代码创建了5个进程,每个进程都运行`worker()`函数。`multiprocessing.Process()`创建进程,`target`参数指定要运行的函数,`args`参数传递给函数的参数。`process.start()`启动进程,`process.join()`等待进程完成。
**参数说明:**
- `num`:传递给`worker()`函数的参数,用于标识进程。
#### 5.2.2 并发编程的最佳实践
在进行并发编程时,应遵循以下最佳实践:
- **避免共享可变数据:** 共享可变数据会导致数据竞争和不可预测的行为。
- **使用锁和同步原语:** 使用锁和同步原语来协调对共享资源的访问。
- **考虑线程和进程的开销:** 创建和管理线程和进程会带来开销,因此应根据需要谨慎使用。
- **使用线程池和进程池:** 线程池和进程池可以管理线程和进程的创建和销毁,提高效率。
- **进行性能测试和分析:** 对并发代码进行性能测试和分析,以识别和解决瓶颈。
# 6. Python环境维护和故障排除
### 6.1 环境更新和维护
#### 6.1.1 更新Anaconda和Python环境
- 定期更新Anaconda和Python环境以确保稳定性和安全性。
- 使用以下命令更新Anaconda:
```
conda update conda
```
- 使用以下命令更新Python环境:
```
conda update python
```
#### 6.1.2 维护环境的稳定性
- 定期备份环境以防止数据丢失。
- 使用版本控制系统(如Git)跟踪环境的更改。
- 避免在生产环境中安装或更新软件包,除非绝对必要。
### 6.2 故障排除和调试
#### 6.2.1 常见错误和解决方法
| 错误 | 解决方法 |
|---|---|
| ImportError: No module named 'package_name' | 确保已正确安装所需的包。 |
| AttributeError: 'module' object has no attribute 'function' | 确保模块中存在该函数。 |
| SyntaxError: invalid syntax | 检查代码语法是否存在错误。 |
| NameError: name 'variable' is not defined | 确保已正确定义变量。 |
#### 6.2.2 使用调试工具
- 使用pdb调试器进行交互式调试。
- 使用logging模块记录错误和警告。
- 使用单元测试框架编写测试用例以检测错误。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了使用 Anaconda 安装和配置 Python 环境的各个方面。从初学者到高级用户,本专栏提供了全面的指南,涵盖了安装、常见问题解答、性能优化、环境管理、包管理、依赖管理、IDE 比较,以及与 Jupyter Notebook、Spyder 和 VS Code 等工具的集成。通过遵循本专栏中的分步指南和最佳实践,读者可以轻松避免常见问题,优化 Python 环境的性能,并创建和管理多个独立的开发环境。本专栏旨在帮助读者充分利用 Anaconda,提升 Python 开发效率,并探索数据科学和机器学习的广阔世界。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】使用Docker与Kubernetes进行容器化管理
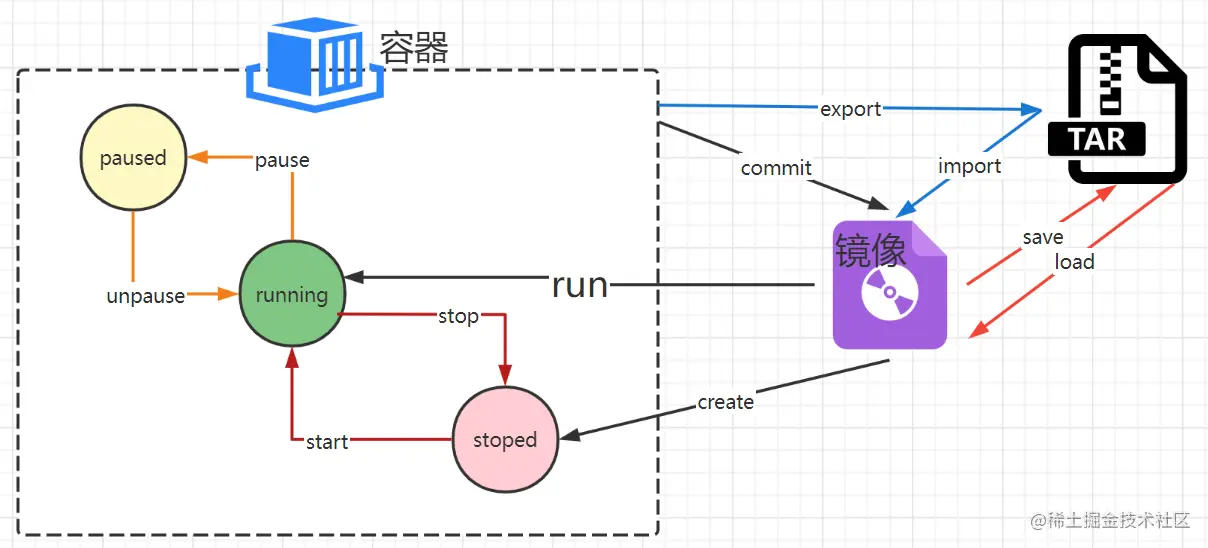
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【进阶】入侵检测系统简介
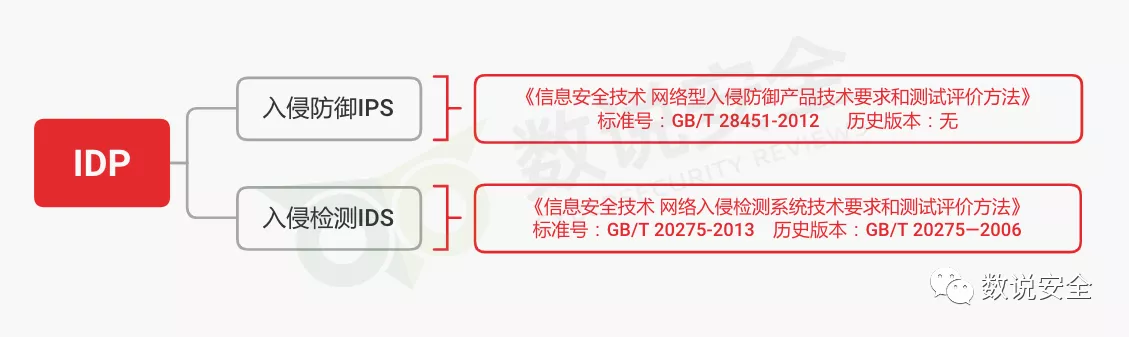
# 1. 入侵检测系统概述**
入侵检测系统(IDS)是一种网络安全工具,用于检测和预防未经授权的访问、滥用、异常或违反安全策略的行为。IDS通过监控网络流量、系统日志和系统活动来识别潜在的威胁,并向管理员发出警报。
IDS可以分为两大类:基于网络的IDS(NIDS)和基于主机的IDS(HIDS)。NIDS监控网络流量,而HIDS监控单个主机的活动。IDS通常使用签名检测、异常检测和行
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】python云数据库部署:从选择到实施
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】通过强化学习优化能源管理系统实战
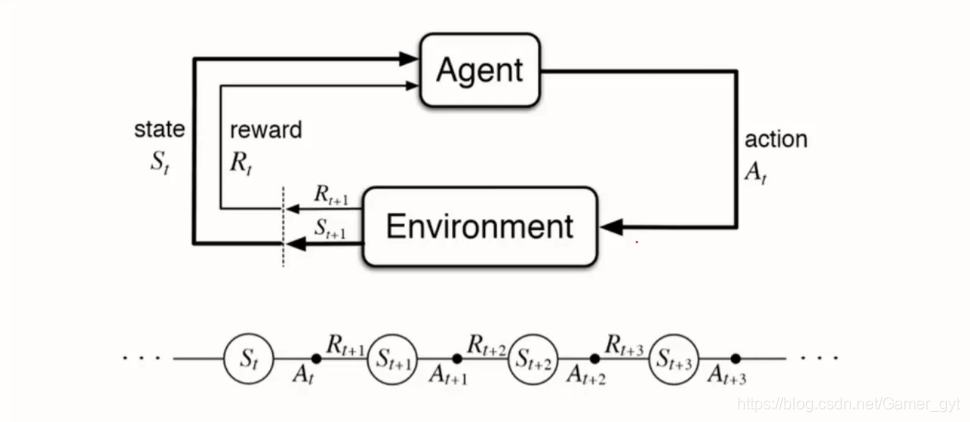
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )