【YOLO算法实战手册】:从原理到应用,全面掌握目标检测利器
发布时间: 2024-08-14 16:04:32 阅读量: 25 订阅数: 50 
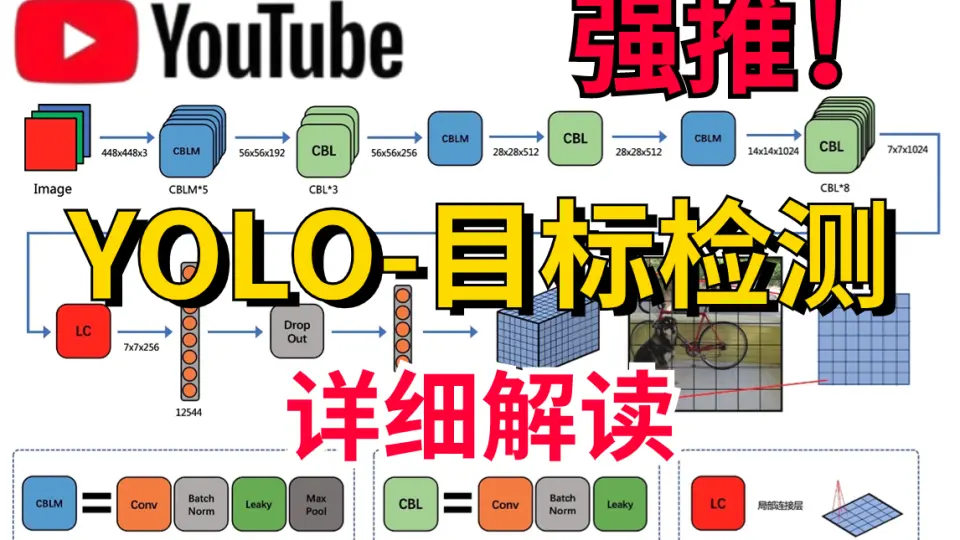
# 1. YOLO算法理论基础**
YOLO(You Only Look Once)算法是一种单次卷积神经网络,用于实时目标检测。与传统的两阶段检测方法(如R-CNN)不同,YOLO算法在单次前向传播中直接预测目标边界框和类别。
YOLO算法的核心思想是将目标检测任务视为回归问题。它使用卷积神经网络提取图像特征,然后将这些特征输入到一个全连接层,该层预测目标边界框和类别概率。这种单次预测机制使得YOLO算法能够以极快的速度进行目标检测。
# 2. YOLO算法实践应用
### 2.1 YOLOv1:基础模型
#### 2.1.1 架构和原理
YOLOv1(You Only Look Once)算法于2015年提出,是目标检测领域的开创性工作。它将目标检测任务视为一个单次卷积神经网络(CNN)的回归问题,实现了实时目标检测的突破。
YOLOv1的网络架构包括:
* **卷积层:**用于提取图像特征。
* **池化层:**用于降低特征图分辨率,提高网络鲁棒性。
* **全连接层:**用于预测边界框和类别概率。
YOLOv1的工作原理如下:
1. 输入一张图像。
2. 将图像输入CNN,提取特征。
3. 将特征图划分为网格,每个网格负责检测一个目标。
4. 每个网格预测一个边界框和类别概率分布。
5. 通过非极大值抑制(NMS)算法过滤冗余边界框,得到最终检测结果。
#### 2.1.2 训练和评估
**训练:**
YOLOv1使用PASCAL VOC 2012数据集进行训练。训练过程包括:
1. 初始化网络权重。
2. 将图像输入网络,前向传播。
3. 计算损失函数,包括边界框回归损失和分类损失。
4. 反向传播更新网络权重。
**评估:**
YOLOv1的评估指标包括:
* **平均精度(mAP):**在不同置信度阈值下的平均检测精度。
* **每秒帧数(FPS):**算法的实时处理速度。
### 2.2 YOLOv2:改进和优化
#### 2.2.1 Batch Normalization和Anchor Box
YOLOv2在YOLOv1的基础上进行了改进,主要包括:
* **Batch Normalization(BN):**提高网络稳定性和训练速度。
* **Anchor Box:**预定义一组边界框形状,提高检测精度。
BN通过对每个批次的数据进行归一化,减少了内部协变量偏移,提高了网络的鲁棒性。Anchor Box则通过预先定义一组不同形状和大小的边界框,为网络提供了先验知识,提高了检测精度。
#### 2.2.2 训练技巧和性能提升
YOLOv2还采用了以下训练技巧来提高性能:
* **数据增强:**通过图像翻转、裁剪和颜色抖动等方式扩充训练数据。
* **多尺度训练:**使用不同尺寸的图像进行训练,增强网络对不同尺寸目标的鲁棒性。
* **类平衡损失:**对不同类别的目标分配不同的损失权重,以解决类别不平衡问题。
### 2.3 YOLOv3:全面升级
#### 2.3.1 Darknet-53主干网络
YOLOv3采用Darknet-53作为主干网络,它是一个深度卷积神经网络,具有53个卷积层。Darknet-53提取图像特征的能力更强,为YOLOv3提供了更丰富的特征信息。
#### 2.3.2 多尺度预测和特征融合
YOLOv3采用多尺度预测机制,在不同尺度的特征图上进行检测。它将特征图划分为3个尺度,分别负责检测不同尺寸的目标。此外,YOLOv3还使用上采样和跳层连接将不同尺度的特征图融合,增强了特征的丰富性和鲁棒性。
# 3. YOLO算法进阶应用
### 3.1 实时目标检测
#### 3.1.1 视频流处理
YOLO算法在实时目标检测中有着广泛的应用,尤其是在视频流处理方面。视频流处理涉及连续的视频帧,需要算法以高帧率进行实时处理。
为了实现实时目标检测,YOLO算法通常采用以下步骤:
1. **视频帧预处理:**将视频帧调整为模型输入尺寸,并进行必要的预处理操作,如归一化和数据增强。
2. **YOLO模型推理:**将预处理后的视频帧输入YOLO模型进行推理,得到目标检测结果,包括目标类别和边界框坐标。
3. **后处理:**对检测结果进行后处理,如非极大值抑制(NMS)和置信度阈值过滤,以去除冗余检测和提高检测精度。
#### 3.1.2 优化和部署
在视频流处理中,优化YOLO算法的性能至关重要。以下是一些优化和部署策略:
- **模型选择:**选择轻量级的YOLO模型,如YOLOv5s或YOLOv6s,以实现更高的帧率。
- **GPU加速:**使用GPU进行YOLO推理,以显著提高处理速度。
- **批处理:**将多个视频帧打包成批处理进行推理,以提高吞吐量。
- **部署优化:**采用部署优化技术,如TensorRT或ONNX Runtime,以进一步提高推理效率。
### 3.2 目标跟踪
#### 3.2.1 Kalman滤波和匈牙利算法
目标跟踪是YOLO算法的另一重要应用。目标跟踪涉及在连续的视频帧中跟踪目标的运动。YOLO算法通常与Kalman滤波和匈牙利算法相结合来实现目标跟踪。
- **Kalman滤波:**Kalman滤波是一种状态空间模型,用于预测目标的运动状态(位置、速度等)。它利用历史观测数据来更新目标状态,并估计其未来的运动轨迹。
- **匈牙利算法:**匈牙利算法是一种分配算法,用于将检测到的目标与跟踪的目标进行关联。它根据目标之间的距离或相似性,找到最佳的匹配,从而实现目标跟踪的连续性。
#### 3.2.2 在线学习和自适应
为了提高目标跟踪的鲁棒性和适应性,YOLO算法可以采用在线学习和自适应策略。
- **在线学习:**YOLO算法可以利用新观测数据在线更新Kalman滤波模型,以适应目标运动模式的变化。
- **自适应:**YOLO算法可以动态调整跟踪参数,如Kalman滤波的协方差矩阵和匈牙利算法的距离阈值,以应对不同的跟踪场景和目标类型。
### 3.3 目标分类和识别
#### 3.3.1 特征提取和分类器
YOLO算法还可以用于目标分类和识别。它通过提取目标的特征并使用分类器对其进行分类来实现这一功能。
- **特征提取:**YOLO算法利用卷积神经网络(CNN)从目标中提取特征。CNN可以学习目标的形状、纹理和颜色等特征。
- **分类器:**特征提取后,YOLO算法使用分类器对目标进行分类。分类器可以是线性分类器(如支持向量机)或非线性分类器(如神经网络)。
#### 3.3.2 多标签分类和置信度评估
在目标分类和识别中,YOLO算法可以支持多标签分类,即一个目标可以属于多个类别。此外,YOLO算法还提供目标检测的置信度评估,以指示检测结果的可信度。
- **多标签分类:**YOLO算法通过使用sigmoid激活函数来实现多标签分类。每个类别都对应一个sigmoid输出,表示目标属于该类别的概率。
- **置信度评估:**YOLO算法使用逻辑回归来评估目标检测的置信度。置信度表示目标检测的准确性,范围从0到1,其中0表示低置信度,1表示高置信度。
# 4. YOLO算法在实际场景中的应用**
**4.1 自动驾驶**
**4.1.1 车道线检测和障碍物识别**
YOLO算法在自动驾驶领域得到了广泛应用,其中一项重要的任务是车道线检测和障碍物识别。通过实时处理车载摄像头采集的图像,YOLO算法可以快速准确地检测出车道线和各种障碍物,如行人、车辆、交通标志等。
```python
import cv2
import numpy as np
# 加载 YOLO 模型
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
# 初始化视频流
cap = cv2.VideoCapture("video.mp4")
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 将帧转换为 Blob
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# 将 Blob 输入网络
net.setInput(blob)
# 前向传播
detections = net.forward()
# 遍历检测结果
for detection in detections:
# 获取置信度
confidence = detection[5]
# 过滤低置信度检测
if confidence > 0.5:
# 获取边界框坐标
x1, y1, x2, y2 = detection[0:4] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])
# 绘制边界框
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# 显示帧
cv2.imshow("Frame", frame)
# 按键退出
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放视频流
cap.release()
cv2.destroyAllWindows()
```
**逻辑分析:**
这段代码使用 OpenCV 和 YOLO 模型实现了车道线检测和障碍物识别。它从视频流中读取帧,将其转换为 Blob,并将其输入到 YOLO 模型中。然后,模型进行前向传播,输出检测结果。对于每个检测,代码检查置信度,并仅绘制置信度大于 0.5 的边界框。
**4.1.2 行人检测和避让**
在自动驾驶中,行人检测和避让至关重要。YOLO算法可以快速检测行人,并预测其运动轨迹。通过与其他传感器(如雷达和激光雷达)融合,YOLO算法可以帮助自动驾驶汽车及时发现行人,并采取适当的避让措施。
**4.2 安防监控**
**4.2.1 人脸识别和入侵检测**
YOLO算法在安防监控领域也得到了广泛应用。它可以实时处理监控摄像头采集的图像,快速准确地检测出人脸。通过与人脸识别数据库进行匹配,YOLO算法可以识别已知人员,并对陌生人发出警报。此外,YOLO算法还可以检测入侵行为,如非法闯入、越界等。
```python
import cv2
import numpy as np
# 加载 YOLO 模型
net = cv2.dnn.readNet("yolov3-face.weights", "yolov3-face.cfg")
# 初始化视频流
cap = cv2.VideoCapture("video.mp4")
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 将帧转换为 Blob
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# 将 Blob 输入网络
net.setInput(blob)
# 前向传播
detections = net.forward()
# 遍历检测结果
for detection in detections:
# 获取置信度
confidence = detection[5]
# 过滤低置信度检测
if confidence > 0.5:
# 获取边界框坐标
x1, y1, x2, y2 = detection[0:4] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])
# 绘制边界框
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# 显示帧
cv2.imshow("Frame", frame)
# 按键退出
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放视频流
cap.release()
cv2.destroyAllWindows()
```
**逻辑分析:**
这段代码使用 OpenCV 和 YOLO 模型实现了人脸识别和入侵检测。它从视频流中读取帧,将其转换为 Blob,并将其输入到 YOLO 模型中。然后,模型进行前向传播,输出检测结果。对于每个检测,代码检查置信度,并仅绘制置信度大于 0.5 的边界框。
**4.2.2 行为分析和异常事件检测**
YOLO算法还可以用于行为分析和异常事件检测。通过分析连续的帧,YOLO算法可以检测出异常行为,如打架、奔跑、跌倒等。此外,YOLO算法还可以检测出异常事件,如火灾、爆炸、枪击等。
**4.3 医疗影像**
**4.3.1 医学图像分割和病灶识别**
在医疗影像领域,YOLO算法可以用于医学图像分割和病灶识别。通过处理医学图像,如 X 射线、CT 扫描和 MRI 图像,YOLO算法可以准确地分割出感兴趣的区域,并识别出病灶。这有助于医生进行诊断和治疗规划。
```python
import cv2
import numpy as np
# 加载 YOLO 模型
net = cv2.dnn.readNet("yolov3-medical.weights", "yolov3-medical.cfg")
# 加载医学图像
image = cv2.imread("medical_image.jpg")
# 将图像转换为 Blob
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# 将 Blob 输入网络
net.setInput(blob)
# 前向传播
detections = net.forward()
# 遍历检测结果
for detection in detections:
# 获取置信度
confidence = detection[5]
# 过滤低置信度检测
if confidence > 0.5:
# 获取边界框坐标
x1, y1, x2, y2 = detection[0:4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
# 绘制边界框
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# 显示图像
cv2.imshow("Image", image)
# 按键退出
if cv2.waitKey(0) & 0xFF == ord("q"):
cv2.destroyAllWindows()
```
**逻辑分析:**
这段代码使用 OpenCV 和 YOLO 模型实现了医学图像分割和病灶识别。它加载医学图像,将其转换为 Blob,并将其输入到 YOLO 模型中。然后,模型进行前向传播,输出检测结果。对于每个检测,代码检查置信度,并仅绘制置信度大于 0.5 的边界框。
**4.3.2 辅助诊断和治疗决策**
YOLO算法还可以用于辅助诊断和治疗决策。通过分析医学图像,YOLO算法可以帮助医生识别疾病,评估疾病严重程度,并制定治疗计划。这有助于提高诊断和治疗的准确性和效率。
# 5. YOLO算法的未来发展**
**5.1 轻量化和高效化**
**5.1.1 模型压缩和加速**
为了在移动设备和边缘设备等资源受限的平台上部署YOLO算法,模型压缩和加速至关重要。模型压缩技术可以减少模型的大小和计算复杂度,而加速技术可以提高模型的推理速度。
**模型压缩**
* **剪枝:**移除对模型性能影响较小的权重和神经元。
* **量化:**将浮点权重和激活值转换为低精度格式(如int8或int16)。
* **蒸馏:**将大型模型的知识转移到较小的学生模型中。
**模型加速**
* **并行化:**在多个GPU或CPU核上并行执行模型。
* **优化内核:**使用定制的内核和优化算法来提高特定操作的效率。
* **推理引擎:**使用专门的推理引擎来优化模型的推理过程。
**5.1.2 边缘设备部署**
随着边缘计算的兴起,在边缘设备上部署YOLO算法变得越来越重要。边缘设备通常具有有限的计算能力和存储空间,因此需要轻量化和高效化的模型。
**优化边缘设备部署**
* **选择轻量级模型:**使用专门为边缘设备设计的轻量级YOLO模型。
* **使用模型压缩和加速技术:**进一步减少模型的大小和计算复杂度。
* **优化推理流程:**使用低延迟推理技术和优化算法来提高推理速度。
**5.2 多模态融合**
**5.2.1 图像、视频和激光雷达数据的融合**
YOLO算法通常用于处理图像数据,但它也可以与其他模态数据(如视频和激光雷达数据)融合,以增强目标检测性能。
**多模态融合的好处**
* **互补信息:**不同模态的数据提供互补的信息,可以提高检测准确性。
* **鲁棒性:**融合多种模态数据可以提高算法对不同环境和条件的鲁棒性。
* **实时性:**视频和激光雷达数据可以提供实时信息,从而实现实时目标检测。
**5.2.2 跨模态目标检测和跟踪**
跨模态目标检测和跟踪涉及在不同模态数据之间关联和跟踪目标。这对于自动驾驶、安防监控和医疗影像等应用至关重要。
**跨模态目标检测和跟踪的挑战**
* **数据异质性:**不同模态的数据具有不同的表示形式和特征。
* **时间同步:**确保不同模态数据的同步至关重要,以实现准确的关联和跟踪。
* **鲁棒性:**跨模态目标检测和跟踪算法需要对不同的环境和条件具有鲁棒性。
# 6. YOLO算法学习资源和社区**
**6.1 官方文档和代码库**
* **YOLO官方网站:**https://pjreddie.com/darknet/yolo/
* **Darknet框架代码库:**https://github.com/AlexeyAB/darknet
* **YOLOv5代码库:**https://github.com/ultralytics/yolov5
**6.2 研究论文和会议**
* **YOLOv1论文:**You Only Look Once: Unified, Real-Time Object Detection
* **YOLOv2论文:**YOLO9000: Better, Faster, Stronger
* **YOLOv3论文:**YOLOv3: An Incremental Improvement
* **CVPR会议:**计算机视觉和模式识别会议,经常发表YOLO算法相关论文
* **ICCV会议:**国际计算机视觉会议,同样发表了许多YOLO算法相关论文
**6.3 在线论坛和讨论组**
* **YOLO官方论坛:**https://forum.pjreddie.com/
* **Reddit YOLO子版块:**https://www.reddit.com/r/YOLO/
* **GitHub YOLO讨论组:**https://github.com/AlexeyAB/darknet/discussions
* **Stack Overflow YOLO标签:**https://stackoverflow.com/questions/tagged/yolo
**其他学习资源:**
* **Coursera YOLO课程:**https://www.coursera.org/specializations/yolo-object-detection
* **Udemy YOLO教程:**https://www.udemy.com/course/yolo-object-detection-with-python-and-opencv/
* **YouTube YOLO视频教程:**https://www.youtube.com/results?search_query=yolo+tutorial

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了 YOLO 算法,从原理到应用,为读者提供了一份目标检测利器的使用指南。它深入探讨了 YOLO 算法的机制,并提供了从实战手册到优化指南的全面指导。此外,专栏还展示了 YOLO 算法在医疗影像、安防监控、零售业、农业、工业检测、无人机、虚拟现实、增强现实、体育分析、交通管理、环境监测、科学研究、金融科技、自动驾驶和机器人等领域的广泛应用,揭示了其在各个行业赋能创新和提升效率的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言数据包性能监控:实时跟踪使用情况的高效方法
# 1. R语言数据包性能监控概述
在当今数据驱动的时代,对R语言数据包的性能进行监控已经变得越来越重要。本章节旨在为读者提供一个关于R语言性能监控的概述,为后续章节的深入讨论打下基础。
## 1.1 数据包监控的必要性
随着数据科学和统计分析在商业决策中的作用日益增强,R语言作为一款强大的统计分析工具,其性能监控成为确保数据处理效率和准确性的重要环节。性能监控能够帮助我们识别潜在的瓶颈,及时优化数据包的使用效率,提
R语言数据包安全使用指南:规避潜在风险的策略
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
【Tau包社交网络分析】:掌握R语言中的网络数据处理与可视化
# 1. Tau包社交网络分析基础
社交网络分析是研究个体间互动关系的科学领域,而Tau包作为R语言的一个扩展包,专门用于处理和分析网络数据。本章节将介绍Tau包的基本概念、功能和使用场景,为读者提供一个Tau包的入门级了解。
## 1.1 Tau包简介
Tau包提供了丰富的社交网络分析工具,包括网络的创建、分析、可视化等,特别适合用于研究各种复杂网络的结构和动态。它能够处理有向或无向网络,支持图形的导入和导出,使得研究者能够有效地展示和分析网络数据。
## 1.2 Tau与其他网络分析包的比较
Tau包与其他网络分析包(如igraph、network等)相比,具备一些独特的功能和优势。
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
模型验证的艺术:使用R语言SolveLP包进行模型评估
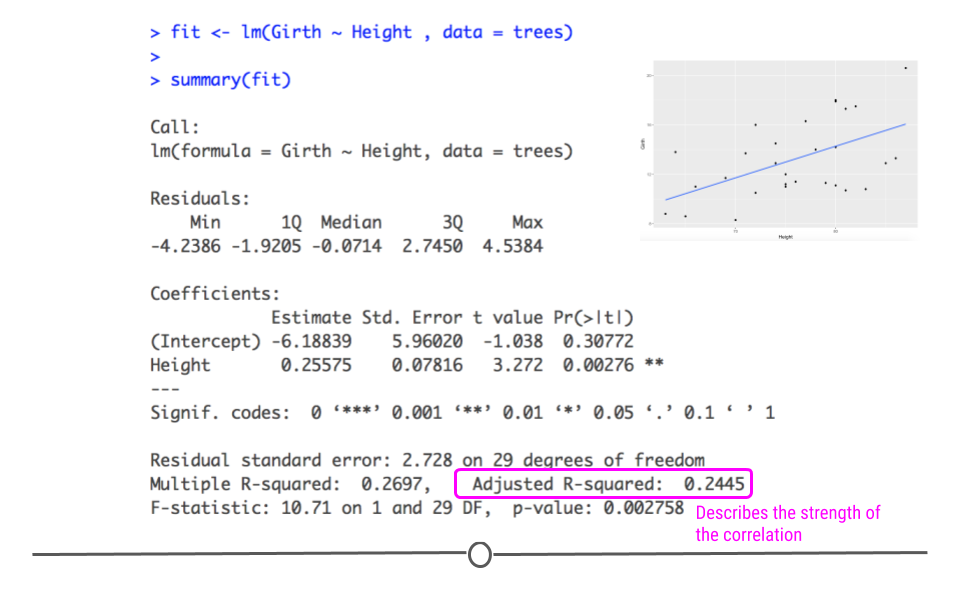
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
模型结果可视化呈现:ggplot2与机器学习的结合
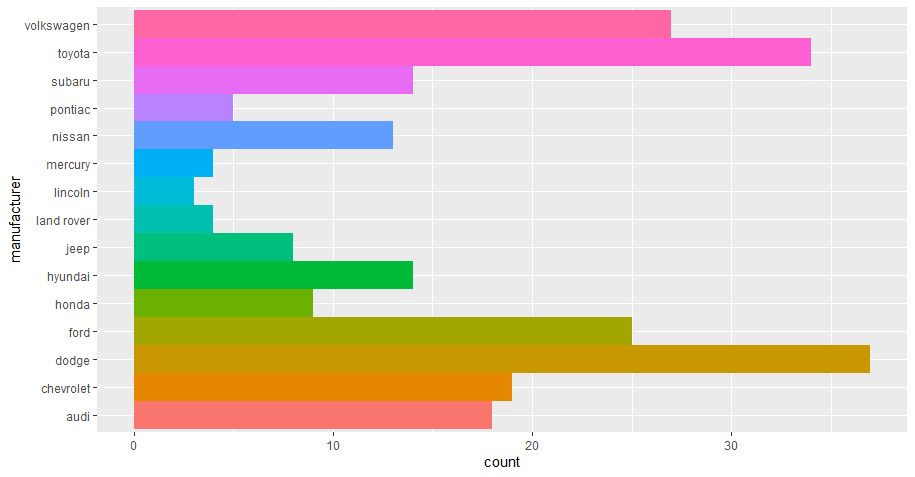
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【lattice包的三维图形绘制】:数据第三维度的探索之旅

# 1. lattice包概述与三维数据的准备
在R语言社区中,lattice包是三维数据可视化的重要工具,它允许用户创建丰富且具有高度自定义功能的图形。本章节旨在为读者提供一个关于lattice包功能的全面概述,并指导用户如何准备适合lattice包进行三维可视化的数据。
## 1.1 lattice包功能概览
lattice包提供了一套灵活的函数来绘制三维图形,特别适合于多变量数据的可视化。
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
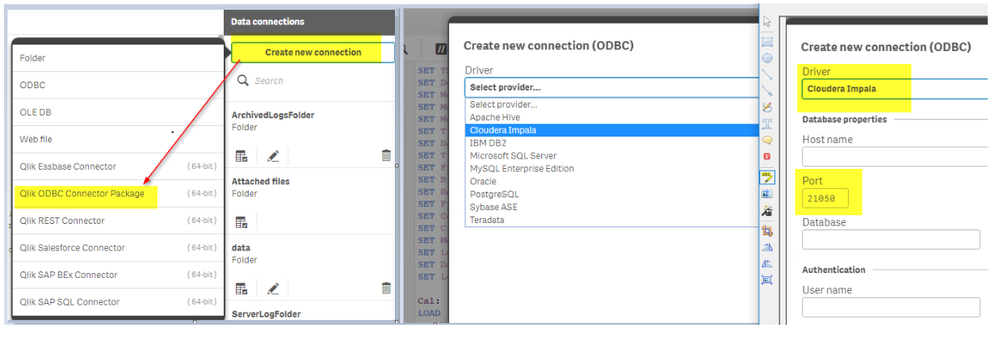
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )