Python reStructuredText指令详解:入门篇,开启文档自动化之旅
发布时间: 2024-10-13 15:15:25 阅读量: 43 订阅数: 25 

pyembed-rst:Python reStructuredText指令,用于使用OEmbed嵌入内容
# 1. reStructuredText的简介与安装
## 简介
reStructuredText (简称 reST) 是一种轻量级标记语言,主要用于编写技术文档。它以纯文本形式存在,易于阅读和编辑,同时能够转换成多种输出格式,如 HTML、PDF 和其他格式。reST 被广泛用于 Python 社区,特别是在 Sphinx 文档生成器中,它支持内嵌的 Python 代码和扩展标记,使得文档更加生动和实用。
## 安装
要开始使用 reStructuredText,首先需要安装 Python 环境,因为 reST 是 Python 的一个库。通过 Python 的包管理工具 pip,可以轻松安装 Docutils,这是 reST 的核心库。
```bash
pip install docutils
```
安装完成后,你可以使用 `rst2html.py` 这个命令行工具来将 reST 文件转换为 HTML 格式,例如:
```bash
rst2html.py example.rst > example.html
```
以上命令将 `example.rst` 文件转换为 HTML 文件 `example.html`。这只是 reST 使用的起点,随着文章的深入,我们将探索更多高级功能和应用场景。
# 2. reStructuredText的文本排版基础
## 2.1 文本格式化指令
### 2.1.1 加粗与斜体的使用
reStructuredText提供了简单的格式化指令来实现文本的加粗和斜体。加粗通常使用双星号`**`包围要加粗的文本,而斜体则使用单星号`*`。这种简单的标记方法使得文档易于阅读和编辑。
```plaintext
*这是一个斜体文本示例*,而 **这是加粗文本的示例**。
```
在上面的例子中,星号`*`和`**`分别用来表示斜体和加粗。当这些标记被解析时,它们会转换成相应的HTML格式,如`<em>`和`<strong>`标签,这些标签在网页上分别表示斜体和加粗文本。
### 2.1.2 字体大小和颜色的设置
虽然reStructuredText本身不直接支持设置字体大小和颜色,但是它可以通过内联的HTML标签来实现这些效果。例如,你可以使用HTML的`<span>`标签和其`style`属性来设置字体大小和颜色。
```plaintext
这是一个普通文本,而 <span style="color:blue;font-size:150%;">这是一个蓝色加大的文本示例</span>。
```
在这个例子中,`<span>`标签被用来包裹文本,并通过`style`属性来设置字体颜色和大小。请注意,过度使用HTML标签可能会影响文档的可移植性和可维护性。
## 2.2 列表和块引用
### 2.2.1 无序列表和有序列表的创建
reStructuredText支持创建无序列表和有序列表。无序列表通常使用星号`*`、加号`+`或减号`-`作为列表项目的前缀,而有序列表则使用数字或字母加点`.`作为前缀。
```plaintext
* 第一个无序列表项
* 第二个无序列表项
1. 第一个有序列表项
2. 第二个有序列表项
```
以上代码将分别创建一个无序列表和一个有序列表。在生成的HTML中,无序列表会使用`<ul>`标签,有序列表会使用`<ol>`标签,列表项则使用`<li>`标签。
### 2.2.2 块引用的嵌套与应用
块引用(Blockquotes)通常用于表示文本引用或者强调内容。在reStructuredText中,可以使用`>`符号来创建块引用。
```plaintext
> 这是一个块引用的示例。它通常用于引用或者强调某些内容。
>
> > 这是嵌套的块引用,可以用来展示引用的层次结构。
```
在上面的例子中,第一行文本后面跟了一个`>`符号,表示这是一个块引用。嵌套的块引用使用了两个`>`符号,表示引用的层次。
## 2.3 超链接和图片的嵌入
### 2.3.1 超链接的基本语法
reStructuredText提供了灵活的方式来嵌入超链接。基本的超链接语法包括链接文本、网址和可选的标题信息。
```plaintext
这是一个指向 `reStructuredText官方文档 <***>`_ 的超链接示例。
```
在这个例子中,反引号`` ` ``用来包围链接文本,而URL地址则紧跟在反引号后面,并用空格分隔。当文档被解析时,这段文本会变成一个可点击的超链接。
### 2.3.2 图片插入与尺寸调整
插入图片与插入超链接类似,不同的是图片的语法前面有一个感叹号`!`。图片同样可以有尺寸的调整。
```plaintext
.. image:: ***
***
***
```
在这个例子中,`.. image::`指令用来插入图片,后面跟的是图片的URL地址。`:width:`和`:height:`是可选的参数,用来指定图片的尺寸。这些参数在生成的HTML中会被转换为`<img>`标签的`width`和`height`属性。
# 3. reStructuredText的高级排版技巧
## 3.1 表格的创建与格式化
### 3.1.1 简单表格的构建方法
在reStructuredText中创建表格是一个简单而直观的过程。基本的表格结构由表头、分隔行和数据行组成。下面是一个简单表格的示例:
```reStructuredText
+------------+------------+-----------------+
| Header 1 | Header 2 | Header 3 |
+============+============+=================+
| Row 1 Col 1 | Row 1 Col 2 | Row 1 Col 3 |
+------------+------------+-----------------+
| Row 2 Col 1 | Row 2 Col 2 | Row 2 Col 3 |
+------------+------------+-----------------+
```
在这个例子中,`+` 符号用来表示表格的边界,`=` 用于分隔表头和数据行。列之间的分隔符 `-` 用来表示列宽。
### 3.1.2 复杂表格的高级格式化
对于更复杂的表格,我们可以使用 `list-table` 指令来创建。这种表格允许我们定义列宽,行跨列等高级功能。下面是一个复杂表格的示例:
```reStructuredText
.. list-table:: 示例列表表格
:header-rows: 1
:widths: 20 20 60
* - 名称
- 描述
- 值
* - 客户ID
- 用户的唯一标识
- 12345
* - 订单号
- 订单的唯一标识
- A123456
```
在这个例子中,我们使用了 `list-table` 指令来定义一个列表表格。`header-rows` 参数指定了表头行数,而 `widths` 参数定义了每列的宽度比例。
### 3.1.3 表格的其他高级功能
reStructuredText还支持其他高级表格功能,如跨行或跨列的单元格,以及表格中的子表格。这些功能可以帮助我们创建更复杂的文档结构。
### 3.1.4 表格创建的实践操作步骤
1. 定义表格结构,包括表头和数据行。
2. 使用 `+` 和 `=` 符号来手动创建简单表格。
3. 使用 `list-table` 指令来创建复杂表格,并定义相关的参数。
### 3.1.5 表格格式化的技巧
- 使用 `widths` 参数来控制列宽,使得表格更加美观。
- 对于简单表格,可以适当使用 `-` 来强调列的分隔。
- 在复杂表格中,可以使用 `header-rows` 和 `stub-columns` 来定义表头和列标题。
### 3.1.6 表格创建的代码块分析
在代码块中,我们使用了 `list-table` 指令来创建复杂表格,并且可以通过参数来调整表格的外观。例如:
```reStructuredText
.. list-table:: 一个复杂的表格示例
:widths: 15 10 75
:header-rows: 1
:stub-columns: 1
* - 名称
- 描述
- 详细信息
* - 客户ID
- 用户的唯一标识
- 12345
* - 订单号
- 订单的唯一标识
- A123456
```
在这个代码块中,我们定义了一个名为“一个复杂的表格示例”的表格,其中包含三列。`widths` 参数定义了每列的宽度比例,`header-rows` 参数指定表头的行数,而 `stub-columns` 参数定义了包含额外列的列数。
## 3.2 段落控制与特殊字符
### 3.2.1 段落缩进与行距调整
在reStructuredText中,我们可以通过缩进来控制段落的格式。例如,以下代码展示了如何缩进段落:
```reStructuredText
This is a paragraph with normal indentation.
This is an indented paragraph.
```
此外,我们还可以使用特定的指令来调整行距。例如,`:line-height:` 指令可以用来设置行距:
```reStructuredText
.. raw:: html
<p style="line-height:150%;">这是一段行距为150%的文本。</p>
```
### 3.2.2 特殊字符的插入与显示
在reStructuredText文档中,我们可以插入各种特殊字符,如版权符号(©)、商标符号(™)等。例如,以下代码展示了如何插入特殊字符:
```reStructuredText
这是一个版权符号 ©,这是一个商标符号 ™。
```
### 3.2.3 段落控制的实践操作步骤
1. 使用空白行或缩进来控制段落格式。
2. 使用 `:line-height:` 指令来调整行距。
### 3.2.4 特殊字符插入的技巧
- 使用反斜杠 `\` 来插入需要转义的特殊字符,如 `\*` 表示 `*` 符号。
- 使用HTML实体或Unicode代码来插入不在标准ASCII字符集中的特殊字符。
### 3.2.5 段落控制与特殊字符的代码块分析
在代码块中,我们展示了如何缩进段落以及如何调整行距。例如:
```reStructuredText
.. raw:: html
<p style="line-height:150%;">这是一段行距为150%的文本。</p>
```
在这个代码块中,我们使用了HTML的 `<p>` 标签和 `style` 属性来设置行距。这是一个在reStructuredText中使用HTML标签来实现特定格式的示例。
## 3.3 代码块和文件的引用
### 3.3.1 代码块的高亮显示
在reStructuredText中,我们可以使用 `code-block` 指令来创建代码块,并且可以指定语言来实现代码的高亮显示。例如,以下代码展示了如何创建一个Python代码块:
```reStructuredText
.. code-block:: python
print("Hello, World!")
```
### 3.3.2 文件引用与版本控制
我们还可以引用文件中的代码,这在文档中展示配置文件或脚本时非常有用。例如,以下代码展示了如何引用一个文件:
```reStructuredText
.. literalinclude:: /path/to/file.py
:language: python
:emphasize-lines: 2
:linenos:
```
### 3.3.3 代码块和文件引用的实践操作步骤
1. 使用 `code-block` 指令来创建代码块。
2. 使用 `literalinclude` 指令来引用文件中的代码。
### 3.3.4 代码块的高亮显示技巧
- 使用 `:language:` 参数来指定代码的语言,以便实现高亮显示。
- 使用 `:emphasize-lines:` 参数来高亮显示特定的代码行。
- 使用 `:linenos:` 参数来显示代码的行号。
### 3.3.5 代码块和文件引用的代码块分析
在代码块中,我们展示了如何创建一个带有高亮显示的Python代码块。例如:
```reStructuredText
.. code-block:: python
def hello_world():
print("Hello, World!")
```
在这个代码块中,我们定义了一个简单的 `hello_world` 函数,并使用 `code-block` 指令来实现代码的高亮显示。
通过本章节的介绍,我们了解了reStructuredText中表格的创建与格式化、段落控制与特殊字符的使用,以及代码块和文件引用的方法。这些高级排版技巧可以帮助我们创建更加专业和易于阅读的文档。在本章节中,我们通过具体的示例和操作步骤,详细解释了如何使用这些功能,并展示了如何通过代码块来实现这些高级排版技巧。总结来说,掌握这些技巧对于提高文档的可读性和专业性至关重要。
# 4. reStructuredText在文档自动化中的应用
在本章节中,我们将深入探讨reStructuredText在文档自动化中的应用,包括文档结构的组织与目录生成、自定义指令和角色的创建,以及模板与主题的应用。这些知识不仅有助于提高文档编写的效率,还能增强文档的可读性和可维护性。
## 4.1 文档结构的组织与目录生成
### 4.1.1 章节与子章节的组织
reStructuredText使用一系列的指令来组织文档结构。通过正确地使用这些指令,可以清晰地定义文档的层次结构。例如,使用`#`来定义一级标题,`##`来定义二级标题,以此类推。
```markdown
# 第一章:简介
## 第一节:基础知识
### 第一小节:概念介绍
文本内容...
```
这种结构化的文档层次有助于读者快速定位信息,并且在生成文档时可以自动创建目录。
### 4.1.2 自动生成目录的方法
Sphinx是一个基于reStructuredText的文档生成工具,它可以自动生成文档的目录。要在Sphinx中生成目录,需要在文档的`conf.py`配置文件中启用`toctree`指令,并在文档中使用它。
```markdown
.. toctree::
:maxdepth: 2
chapter1
chapter2
```
`toctree`指令告诉Sphinx哪些文件应该包含在目录中,并且`maxdepth`参数定义了目录的层级深度。在文档的主文件中,使用`toctree`指令后,Sphinx会在该位置插入目录。
## 4.2 自定义指令和角色的创建
### 4.2.1 创建自定义指令
reStructuredText支持用户创建自定义指令,以扩展其功能。这可以通过Sphinx的`conf.py`配置文件中的`directives`字典来实现。
```python
from docutils.parsers.rst import Directive
class MyDirective(Directive):
required_arguments = 1
final_argument_whitespace = True
option_spec = {}
def run(self):
# 自定义逻辑
pass
def setup(app):
app.add_directive('mydirective', MyDirective)
```
在这个例子中,我们创建了一个名为`mydirective`的自定义指令。在文档中,我们可以这样使用它:
```markdown
.. mydirective:: 参数1
:选项: 值
额外的文本内容...
```
### 4.2.2 定义和使用自定义角色
角色是reStructuredText中的另一种扩展机制,它们类似于Markdown中的链接语法。可以通过`roles`字典在`conf.py`中注册自定义角色。
```python
def setup(app):
app.add_role('myrole', my_role_role)
```
在文档中,可以这样使用自定义角色:
```markdown
一些文本,其中包含 :myrole:`链接文本`。
```
## 4.3 模板与主题的应用
### 4.3.1 使用Sphinx主题定制外观
Sphinx支持多种主题,可以轻松地改变文档的外观。要在Sphinx中使用不同的主题,需要在`conf.py`文件中设置`html_theme`变量。
```python
html_theme = 'alabaster'
```
### 4.3.2 模板继承与扩展
Sphinx允许通过模板继承来定制文档的布局。这涉及到修改`_templates`文件夹中的HTML模板文件,例如`layout.html`。
```html
{%- extends "!layout.html" -%}
{%- block footer %}
{{ super() }}
<!-- 自定义页脚内容 -->
{%- endblock %}
```
在这里,我们通过继承默认的`layout.html`文件并重写`footer`块来自定义页脚。这种方式可以用来添加额外的脚本、样式或信息。
通过本章节的介绍,我们可以看到reStructuredText在文档自动化中的强大功能。它不仅提供了丰富的排版选项,还允许通过自定义指令和角色来扩展其功能。此外,Sphinx的模板和主题系统为定制文档的外观和结构提供了极大的灵活性。这些知识将帮助我们在实际项目中更有效地使用reStructuredText,从而提高文档编写的效率和质量。
# 5. reStructuredText的扩展与插件
## 5.1 reStructuredText的扩展机制
### 5.1.1 内置扩展指令介绍
reStructuredText作为一种强大的标记语言,其内置的扩展指令为文档提供了丰富的功能。这些内置扩展可以通过特定的指令语法激活,使得文档的排版和内容展示更加多样化。例如,`meta`指令用于在文档中嵌入元数据,如文档的作者、版本等信息。
```restructuredtext
.. meta::
:keywords: reStructuredText, extensions, metadata
:description: A detailed explanation of reStructuredText extensions.
:author: Your Name
```
上述代码块中的`meta`指令用于定义文档的元数据,这些元数据不会直接显示在文档内容中,但可以被搜索引擎抓取,增加文档的SEO友好度。
### 5.1.2 扩展的编写与使用
除了内置扩展,reStructuredText还支持编写自定义扩展,以满足特定的排版需求。自定义扩展通常需要Python编程知识,因为它们通常是通过Python代码实现的。自定义扩展的编写涉及对reStructuredText解析器的深入了解,以及对Python编程的熟练掌握。
```python
# 示例:自定义扩展
from docutils.parsers.rst import Directive
from docutils import nodes
class CustomDirective(Directive):
def run(self):
node = nodes.literal_block(self.block_text, self.block_text)
return [node]
def setup(app):
app.add_directive('customdirective', CustomDirective)
```
在本例中,我们创建了一个名为`customdirective`的自定义指令,它可以将文本块以代码块的形式展示,但不进行任何格式化处理。
### 5.1.3 第三方扩展与工具集成
reStructuredText的第三方扩展也非常丰富,这些扩展可以通过pip安装,并且通常提供额外的功能,如图表生成、代码高亮等。例如,`sphinxcontrib-plantuml`扩展允许直接在reStructuredText文档中嵌入PlantUML生成的图表。
```restructuredtext
.. plantuml::
@startuml
Alice -> Bob: Authentication Request
Bob --> Alice: Authentication Response
@enduml
```
上述代码块展示了如何使用`sphinxcontrib-plantuml`扩展在文档中嵌入UML序列图。
### 5.1.4 扩展的集成与管理
将第三方扩展集成到reStructuredText项目中需要一定的配置和管理。通常,这些扩展的配置在项目的`conf.py`文件中进行。例如,配置Sphinx以使用`plantuml`扩展:
```python
# conf.py配置示例
extensions = [
'sphinxcontrib.plantuml',
]
plantuml = 'java -jar plantuml.jar'
```
在上述配置中,我们添加了`plantuml`扩展,并指定了PlantUML可执行文件的路径。
## 5.2 第三方扩展与工具集成
### 5.2.1 常见的第三方扩展应用
第三方扩展极大地扩展了reStructuredText的功能,使其能够处理更复杂的文档需求。例如,`sphinxcontrib-mermaid`扩展可以将Mermaid图表嵌入到文档中,而`sphinxcontrib-programoutput`可以将程序的输出嵌入到文档中。
```restructuredtext
.. mermaid::
graph LR
A[Hard] -->|Text| B(Round)
B --> C{Decision}
C -->|One| D[Result 1]
C -->|Two| E[Result 2]
```
上述代码块展示了如何使用`sphinxcontrib-mermaid`扩展在文档中嵌入Mermaid流程图。
### 5.2.2 与其他工具如Doxygen的集成
reStructuredText也可以与其他文档生成工具集成,例如Doxygen。通过这种方式,可以将C++等语言的注释文档转换为reStructuredText格式,然后利用Sphinx进行进一步的处理和展示。
```restructuredtext
.. code-block:: doxygen
:caption: 示例C++注释
/** \file main.cpp
* \brief Main application logic
*/
```
在上述代码块中,我们使用了一个假设的`doxygen`代码块指令,展示如何在reStructuredText文档中嵌入Doxygen注释。
## 5.3 社区资源与学习路径
### 5.3.1 重要社区资源分享
reStructuredText的社区资源非常丰富,包括官方文档、论坛和社区提供的教程。官方文档是学习reStructuredText最权威的资源,而论坛和社区则提供了用户间的交流和问题解答。
### 5.3.2 学习资源和进阶路线推荐
对于初学者,可以从官方的Quick Reference入手,然后逐步阅读完整的User Documentation。进阶学习者可以参考社区的高级教程,以及阅读优秀的reStructuredText项目源代码。
```markdown
- [reStructuredText Quick Reference](***
* [reStructuredText User Documentation](***
* [Sphinx Documentation](***
```
以上是一些推荐的学习资源链接,涵盖了从入门到进阶的reStructuredText学习路径。
在本章节中,我们介绍了reStructuredText的扩展机制、第三方扩展与工具集成,以及社区资源和学习路径。通过这些内容,我们可以看到reStructuredText不仅是一个简单的标记语言,它还具有强大的可扩展性,使其能够适应各种复杂的文档需求。同时,丰富的社区资源为学习者提供了多方面的学习支持。
# 6. reStructuredText的实践案例分析
## 6.1 文档自动化项目概述
### 6.1.1 项目背景与需求分析
在现代软件开发中,文档不仅仅是项目的一部分,它也是项目成功的关键。文档可以帮助开发者记录设计决策、指导用户使用产品,同时也是维护和后续开发的重要参考。然而,传统的文档编写方式常常是手动的、耗时的,并且容易出错。文档自动化成为了解决这一问题的有效手段。
本文将通过一个案例分析,展示如何使用reStructuredText(reST)来实现文档自动化,提高文档编写的效率和质量。我们将从一个简单的文档自动化项目的需求分析开始,逐步深入到实现步骤和总结思考。
### 6.1.2 文档结构设计
在确定了项目需求之后,我们需要设计文档的结构。一个好的文档结构应该清晰、合理,并且能够反映项目的需求。以下是我们的文档结构设计:
```plaintext
项目文档
├── 概述
│ ├── 项目背景
│ └── 目标与范围
├── 安装指南
│ └── 环境搭建
├── 用户指南
│ ├── 快速开始
│ └── 功能介绍
├── 开发指南
│ ├── 代码规范
│ └── 测试策略
└── 参考资料
├── 相关文档
└── 联系方式
```
## 6.2 实现步骤详解
### 6.2.1 环境搭建与配置
为了使用reStructuredText编写文档,我们需要搭建一个适合的环境。通常,我们会使用Sphinx来生成HTML或其他格式的文档。以下是环境搭建的步骤:
1. 安装Python环境(Python 3.x)。
2. 使用pip安装Sphinx:`pip install sphinx`
3. 创建一个空目录作为文档项目的基础,并进入该目录。
4. 使用Sphinx初始化文档项目:`sphinx-quickstart`
在执行`sphinx-quickstart`时,会有一系列的配置选项,可以根据实际情况进行选择。
### 6.2.2 文档编写的最佳实践
文档编写是整个项目的核心部分。以下是reStructuredText的一些最佳实践:
#### *.*.*.* 使用代码块
代码块是文档中不可或缺的部分,它可以展示代码示例。reStructuredText中的代码块使用如下:
```python
def hello_world():
print("Hello, world!")
```
#### *.*.*.* 列表和表格
列表和表格可以清晰地展示信息。例如,展示安装步骤的列表:
```plaintext
安装步骤
1. 安装Python环境
2. 使用pip安装Sphinx
3. 创建文档项目目录
```
表格则可以用来展示配置选项:
| 选项 | 描述 |
|------|------|
| -D | 设置配置变量 |
| -o | 输出目录 |
## 6.3 案例总结与扩展思考
### 6.3.1 项目成果与反馈
通过使用reStructuredText和Sphinx,我们的文档自动化项目取得了显著的成果。文档的编写效率得到了提升,维护变得更加容易。项目完成后,我们收到了来自团队成员和用户的积极反馈。
### 6.3.2 对未来文档自动化的展望
随着技术的发展,文档自动化将会变得越来越重要。未来,我们期望看到更多的工具和方法来支持reStructuredText和Sphinx,使其更加易用和强大。同时,我们也希望能够看到更多的社区资源和学习路径,帮助更多的人掌握文档自动化技术。
通过这个案例分析,我们可以看到reStructuredText在文档自动化中的实际应用,以及如何有效地利用它来提高工作效率。希望这篇文章能够为您的文档编写提供有价值的参考和启示。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库文件 docutils.parsers.rst.directives 的方方面面,旨在帮助读者提升代码效率和文档处理能力。从指令的工作原理到高级指令的使用技巧,再到自定义指令的创建和管理,专栏提供了全面的指导。此外,还涵盖了指令的参数处理、调试、测试、安全性、性能优化和应用场景分析,以及与外部工具的集成。通过阅读本专栏,读者将掌握 docutils.parsers.rst.directives 的核心概念和实用技术,从而编写出更有效、更可靠、更专业的文档处理代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【QT基础入门】:QWidgets教程,一步一个脚印带你上手
# 摘要
本文全面介绍了Qt框架的安装配置、Widgets基础、界面设计及进阶功能,并通过一个综合实战项目展示了这些知识点的应用。首先,文章提供了对Qt框架及其安装配置的简要介绍。接着,深入探讨了Qt Widgets,包括其基本概念、信号与槽机制、布局管理器等,为读者打下了扎实的Qt界面开发基础。文章进一步阐述了Widgets在界面设计中的高级用法,如标准控件的深入使用、资源文件和样式表的应用、界面国际化处理。进阶功能章节揭示了Qt对话框、多文档界面、模型/视图架构以及自定义控件与绘图的强大功能。最后,实战项目部分通过需求分析、问题解决和项目实现,展示了如何将所学知识应用于实际开发中,包括项目
数学魔法的揭秘:深度剖析【深入理解FFT算法】的关键技术

# 摘要
快速傅里叶变换(FFT)是信号处理领域中一项关键的数学算法,它显著地降低了离散傅里叶变换(DFT)的计算复杂度。本文从FFT算法的理论基础、实现细节、在信号处理中的应用以及编程实践等多方面进行了详细讨论。重点介绍了FFT算法的数学原理、复杂度分析、频率域特性,以及常用FFT变体和优化技术。同时,本文探讨了FFT在频谱分析、数字滤波器设计、声音和图像处理中的实
MTK-ATA技术入门必读指南:从零开始掌握基础知识与专业术语

# 摘要
MTK-ATA技术作为一种先进的通信与存储技术,已经在多个领域得到广泛应用。本文首先介绍了MTK-ATA技术的概述和基础理论,阐述了其原理、发展以及专业术语。随后,本文深入探讨了MTK-ATA技术在通信与数据存储方面的实践应用,分析了其在手机通信、网络通信、硬盘及固态存储中的具体应用实例。进一步地,文章讲述了MTK-ATA技术在高
优化TI 28X系列DSP性能:高级技巧与实践(性能提升必备指南)

# 摘要
本文系统地探讨了TI 28X系列DSP性能优化的理论与实践,涵盖了从基础架构性能瓶颈分析到高级编译器技术的优化策略。文章深入研究了内存管理、代码优化、并行处理以及多核优化,并展示了通过调整电源管理和优化RTOS集成来进一步提升系统级性能的技巧。最后,通过案例分析和性能测试验证了优化
【提升响应速度】:MIPI接口技术在移动设备性能优化中的关键作用

# 摘要
移动设备中的MIPI接口技术是实现高效数据传输的关键,本论文首先对MIPI接口技术进行了概述,分析了其工作原理,包括MIPI协议栈的基础、信号传输机制以及电源和时钟管理。随后探讨了MIPI接口在移动设备性能优化中的实际应用,涉及显示和摄像头性能提升、功耗管理和连接稳定性。最后,本文展望了MIPI技术的未来趋势,分析了新兴技术标准的进展、性能优化的创新途径以及当前面临的技术挑战。本论文旨在为移动
PyroSiM中文版高级特性揭秘:精通模拟工具的必备技巧(专家操作与界面布局指南)
# 摘要
PyroSiM是一款功能强大的模拟软件,其中文版提供了优化的用户界面、高级模拟场景构建、脚本编程、自动化工作流以及网络协作功能。本文首先介绍了PyroSiM中文版的基础配置和概览,随后深入探讨了如何构建高级模拟场景,包括场景元素组合、模拟参数调整、环境动态交互仿真、以及功能模块的集成与开发。第三章关注用户界面的优化
【云计算优化】:选择云服务与架构设计的高效策略
# 摘要
本文系统地探讨了云计算优化的各个方面,从云服务类型的选择到架构设计原则,再到成本控制和业务连续性规划。首先概述了云计算优化的重要性和云服务模型,如IaaS、PaaS和SaaS,以及在选择云服务时应考虑的关键因素,如性能、安全性和成本效益。接着深入探讨了构建高效云架构的设计原则,包括模块化、伸缩性、数据库优化、负载均衡策略和自动化扩展。在优化策
性能飙升指南:Adam's CAR性能优化实战案例
# 摘要
随着软件复杂性的增加,性能优化成为确保应用效率和响应速度的关键环节。本文从理论基础出发,介绍了性能优化的目的、指标及技术策略,并以Adam's CAR项目为例,详细分析了项目性能需求及优化目标。通过对性能分析与监控的深入探讨,本文提出了性能瓶颈识别和解决的有效方法,分别从代码层面和系统层面展示了具体的优化实践和改进措施。通过评估优化效果,本文强调了持续监控和分析的重要性,以实现性能的持续改进和提升。
#
【Oracle服务器端配置】:5个步骤确保PLSQL-Developer连接稳定性
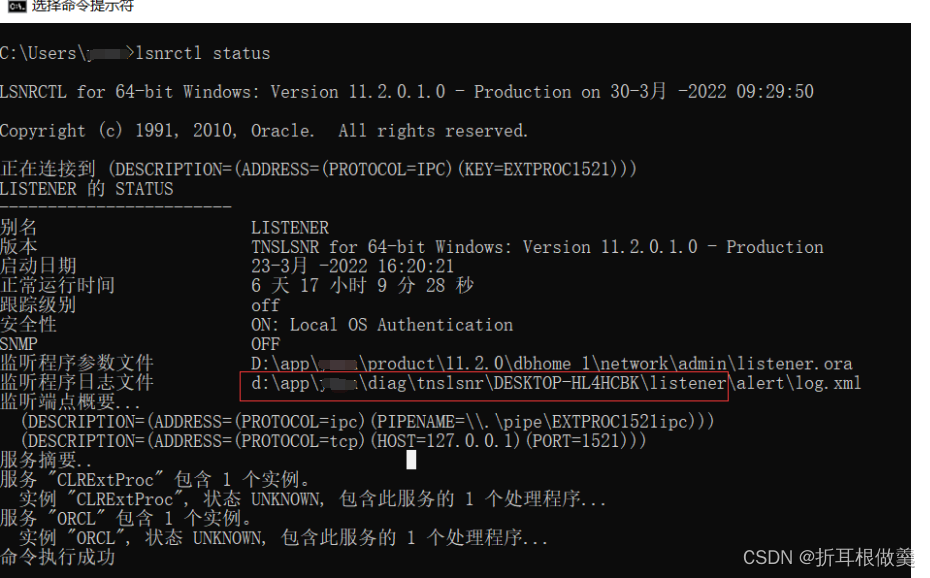
# 摘要
本文对Oracle数据库服务器端配置进行了详细阐述,涵盖了网络环境、监听器优化和连接池管理等方面。首先介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )