机器学习中的概率密度估计:核密度估计与高斯混合模型的实用技巧
发布时间: 2024-12-25 01:10:58 阅读量: 6 订阅数: 4 

核密度估计大作业KDE ,核密度估计的例题,matlab
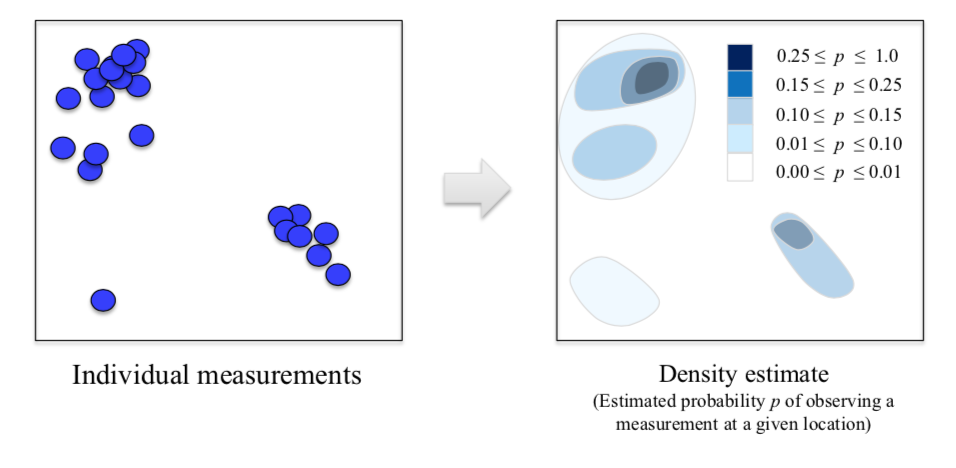
# 摘要
本文首先介绍了概率密度估计的基础知识,随后详细阐述了核密度估计和高斯混合模型的理论与应用。核密度估计部分重点讲解了其基本概念、核函数的选择、带宽选择的重要性以及在实际中的应用技巧。高斯混合模型章节则从模型简介出发,覆盖了参数估计、评估与选择方法,并探讨了其在数据聚类中的应用。两者的比较与实践应用分析了它们在密度估计中的优势与局限,提出了选择和结合两者的策略,并探讨了性能优化技巧。最后,通过金融数据、生物信息学数据以及社交媒体行为的案例研究,展示了所讨论技术在实际问题中的应用与效果。
# 关键字
概率密度估计;核密度估计;高斯混合模型;核函数;带宽选择;数据聚类
参考资源链接:[概率视角下的机器学习:深度解析与实践探索](https://wenku.csdn.net/doc/6412b67fbe7fbd1778d46eff?spm=1055.2635.3001.10343)
# 1. 概率密度估计基础
在统计学和机器学习中,概率密度估计是一项基础而重要的任务,它致力于根据有限的样本数据推断出总体的概率分布特征。本章将首先介绍概率密度估计的基本概念及其重要性,并为理解后续章节中核密度估计和高斯混合模型打下坚实的基础。
## 1.1 概率密度估计的重要性
概率密度函数(Probability Density Function, PDF)对于理解随机变量的行为至关重要。PDF 描述了变量取某个值或落在某个区间内的概率密度。在实际应用中,往往需要估计这个分布,特别是在数据样本有限的情况下。正确的概率密度估计能帮助我们更好地进行预测、分类和决策。
## 1.2 概率密度估计的方法
概率密度估计的方法多种多样,包括直方图法、核密度估计法和参数估计方法等。直方图法简单直观,但依赖于区间的选择;核密度估计克服了直方图的一些局限性,提供了一种更平滑的估计方式;而参数估计方法则需要假定数据符合某个分布模型。在这一章节中,我们将重点介绍核密度估计,因为它在现实世界中的应用更为广泛且效果显著。
# 2. 核密度估计的理论与应用
核密度估计(Kernel Density Estimation,简称KDE)是一种用于估计概率密度函数的非参数方法。它通过在每个数据点附近放置一个核函数,然后将这些核函数叠加起来形成整个数据集的概率密度估计。核密度估计在许多领域,如统计学、机器学习、信号处理和数据分析中都得到了广泛应用。
## 2.1 核密度估计的基本概念
### 2.1.1 概率密度函数的重要性
在概率论和统计学中,概率密度函数(Probability Density Function,简称PDF)对于描述连续随机变量的分布至关重要。PDF可以告诉我们某个值在多大程度上是可能的,但它不直接给出随机变量取特定值的概率。取而代之,概率密度函数允许我们计算随机变量落在某个区间内的概率。概率密度估计则是寻找一个连续的概率密度函数,最准确地反映数据集中的分布。
### 2.1.2 核密度估计的定义和原理
核密度估计是一种非参数估计方法,其核心思想是在每个数据点周围放置一个核函数(kernel function),常见的核函数包括高斯核、Epanechnikov核等。核函数的选择决定了密度估计的平滑程度和形状。通过将这些核函数在数据点处叠加,我们可以得到数据集的概率密度估计。
核密度估计的公式可以表示为:
\[ f(x) = \frac{1}{n}\sum_{i=1}^{n}K_h(x-x_i) \]
其中,\( f(x) \) 是概率密度函数的估计值,\( n \) 是样本数量,\( x_i \) 是数据点,\( K_h \) 是带有带宽参数 \( h \) 的核函数,它负责调节每个数据点对密度估计的影响。
## 2.2 核函数的选择与应用
### 2.2.1 常见核函数的特性对比
不同的核函数会影响核密度估计的结果,因此选择合适的核函数非常重要。下面列出一些常见的核函数及其特性:
| 核函数名称 | 公式 | 特性 |
| --- | --- | --- |
| 高斯核 | \( K(u) = \frac{1}{\sqrt{2\pi}} e^{-\frac{u^2}{2}} \) | 形状接近正态分布,对异常值不敏感。 |
| Epanechnikov核 | \( K(u) = \frac{3}{4}(1-u^2), |u|\leq 1 \) | 最优的均方误差特性。 |
| 矩形核 | \( K(u) = \frac{1}{2} \) | 计算简单,但边界效应明显。 |
| 三角核 | \( K(u) = \frac{3}{4}(1-|u|), |u|\leq 1 \) | 介于矩形核和Epanechnikov核之间。 |
### 2.2.2 如何选择合适的核函数
选择核函数时需要考虑数据的特性以及密度估计的目的。一般来说,高斯核是应用最广泛的选择,因为它对异常值的鲁棒性较好,且数学性质较为稳定。Epanechnikov核在理论上是最优的,但在实际中使用较少,因为其导数在边界处不连续。矩形核计算简单,但边缘效应过于明显,而三角核则是在矩形核和Epanechnikov核之间的一个折中选择。
## 2.3 核密度估计的带宽选择
### 2.3.1 带宽的理论基础
带宽(bandwidth)是核密度估计中非常重要的一个超参数,决定了每个核函数的宽度。带宽的选择直接影响到密度估计的平滑程度。如果带宽太小,密度估计会出现很多“峰值”,对噪声过度敏感;如果带宽太大,密度估计又会过于平滑,可能掩盖真实的分布特征。
### 2.3.2 实践中带宽选择的策略
带宽的选择策略可以分为两类:经验规则和交叉验证方法。
经验规则中最常用的是Silverman规则:
\[ h = \min\left\{ \sigma, \frac{IQR}{1.34} \right\} n^{-1/5} \]
其中,\( \sigma \) 是样本标准差,\( IQR \) 是四分位距,\( n \) 是样本大小。
交叉验证方法包括留一法(leave-one-out cross-validation,简称LOOCV)和最小化交叉验证均方误差(cross-validation mean square error,简称CV-MSE)等。这些方法通过优化准则函数,可以更客观地选择带宽。
## 2.4 核密度估计的实践技巧
### 2.4.1 使用Python进行核密度估计
Python通过`scipy`和`numpy`库提供了核密度估计的功能。这里展示一个简单的使用例子:
```python
import numpy as np
from scipy.stats import gaussian_kde
# 假设有一些样本数据
data = np.random.randn(100)
# 创建核密度估计器对象
kde = gaussian_kde(data)
# 计算在一组点上的密度估计值
x = np.linspace(-4, 4, 200)
density_values = kde.evaluate(x)
# 输出结果
print(density_values)
```
在上述代码中,我们首先生成了一组随机数据,然后使用`gaussian_kde`方法创建了一个高斯核密度估计器,并在一系列点上计算了概率密度估计值。
### 2.4.2 核密度估计的参数调优案例
核密度估计参数调优的案例,可以使用交叉验证的方法选择带宽。以下代码展示了使用`scipy`库中`gaussian_kde`的带宽选择过程:
```python
import numpy as np
from scipy.stats import gaussian_kde
from sklearn.model_selection import GridSearchCV
# 创建样本数据
data = np.random.randn(100)
# 设置带宽候选值
bandwidths = np.logspac
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《机器学习——概率视角》专栏深入探讨了机器学习中的概率方法。它涵盖了各种主题,包括:
* 高维数据的概率学习,提供应对挑战的策略和实践案例。
* 数据缺失下的概率模型,介绍高效处理不完整数据的技术。
* 概率编程语言,比较了 PyMC3 和 TensorFlow Probability,并提供选择指南。
* 机器学习中的概率密度估计,分享核密度估计和高斯混合模型的实用技巧。
* 概率机器学习中的参数估计,对比分析了极大似然估计和贝叶斯估计。
* 预测模型的不确定性量化,深入研究概率方法和案例分析。
* 概率机器学习中的模型选择和交叉验证方法,提供专家级指导。
该专栏旨在为读者提供机器学习中概率方法的全面理解,涵盖从理论基础到实际应用的各个方面。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyEcharts数据可视化入门至精通(14个实用技巧全解析)

# 摘要
PyEcharts是一个强大的Python图表绘制库,为数据可视化提供了丰富和灵活的解决方案。本文首先介绍PyEcharts的基本概念、环境搭建,并详细阐述了基础图表的制作方法,包括图表的构成、常用图表类型以及个性化设置。接着,文章深入探讨了PyEcharts的进阶功能,如高级图表类型、动态交互式图表以及图表组件的扩展。为了更有效地进行数据处理和可视化,本文还分
【单片机温度计终极指南】:从设计到制造,全面解读20年经验技术大咖的秘诀
# 摘要
本文系统地介绍了单片机温度计的设计与实现。首先,概述了温度计的基础知识,并对温度传感器的原理及选择进行了深入分析,包括热电偶、热阻和NTC热敏电阻器的特性和性能比较。接着,详细讨论了单片机的选择标准、数据采集与处理方法以及编程基础。在硬件电路设计章节,探讨了电路图绘制、PCB设计布局以及原型机制作的技巧。软件开发方面,本文涉及用户界
MQTT协议安全升级:3步实现加密通信与认证机制
# 摘要
本文全面探讨了MQTT协议的基础知识、安全性概述、加密机制、实践中的加密通信以及认证机制。首先介绍了MQTT协议的基本通信过程及其安全性的重要性,然后深入解析了MQTT通信加密的必要性、加密算法的应用,以及TLS/SSL等加密技术在MQTT中的实施。文章还详细阐述了MQTT协议的认证机制,包括不同类型的认证方法和客户端以
【继电器分类精讲】:掌握每种类型的关键应用与选型秘籍

# 摘要
继电器作为电子控制系统中的关键组件,其工作原理、结构和应用范围对系统性能和可靠性有着直接影响。本文首先概述了继电器的工作原理和分类,随后详细探讨了电磁继电器的结构、工作机制及设计要点,并分析了其在工业控制和消费电子产品中的应用案例。接着,文章转向固态继电器,阐述了其工作机制、特点优势及选型策略,重点关注了光耦合器作用和驱动电路设计。此外,本文还分类介绍了专用继电器的种类及应用,并分析了选型考虑因素。最后,提出了继电器选型的基本步骤和故障分析诊断方
【TEF668x信号完整性保障】:确保信号传输无懈可击
# 摘要
本文详细探讨了TEF668x信号完整性问题的基本概念、理论基础、技术实现以及高级策略,并通过实战应用案例分析,提供了具体的解决方案和预防措施。信号完整性作为电子系统设计中的关键因素,影响着数据传输的准确性和系统的稳定性。文章首先介绍了信号完整性的重要性及其影响因素,随后深入分析了信号传输理论、测试与评估方法。在此基础上,探讨了信号
【平安银行电商见证宝API安全机制】:专家深度剖析与优化方案

# 摘要
本文对平安银行电商见证宝API进行了全面概述,强调了API安全机制的基础理论,包括API安全的重要性、常见的API攻击类型、标准和协议如OAuth 2.0、OpenID Connect和JWT认证机制,以及API安全设计原则。接着,文章深入探讨了API安全实践,包括访问控制、数据加密与传输安全,以及审计与监控实践。此外,还分
cs_SPEL+Ref71_r2.pdf实战演练:如何在7天内构建你的第一个高效应用
# 摘要
本文系统介绍了cs_SPEL+Ref71_r2.pdf框架的基础知识、深入理解和应用实战,旨在为读者提供从入门到高级应用的完整学习路径。首先,文中简要回顾了框架的基础入门知识,然后深入探讨了其核心概念、数据模型、业务逻辑层和服务端编程的各个方面。在应用实战部分,详细阐述了环境搭建、应用编写和部署监控的方法。此外,还介绍了高级技巧和最
【事件处理机制深度解析】:动态演示Layui-laydate回调函数应用

# 摘要
本文系统地探讨了Layui-laydate事件处理机制,重点阐述了回调函数的基本原理及其在事件处理中的实现和应用。通过深入分析Layui-laydate框架中回调函数的设计和执行,本文揭示了回调函数如何为Web前端开发提供更灵活的事件管理方式。文章进一步介绍了一些高级技巧,并通过案例分析,展示了回调函数在解决实际项目问题中的有效性。本文旨在为前端开
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )