如何解析和处理XML文件
发布时间: 2023-12-16 12:21:45 阅读量: 9 订阅数: 13 
# 一、XML文件简介
## 1.1 什么是XML文件
XML(eXtensible Markup Language)是一种可扩展标记语言,用来描述数据的结构和内容。类似于HTML,XML也使用标签和属性来标记和组织数据,但XML具有更广泛的适用性和灵活性。
XML文件采用纯文本形式保存,可以方便地在不同的系统和平台之间进行数据交换和共享。它是一种独立于软件和硬件的数据格式,不受任何特定语言或技术的限制。
## 1.2 XML文件的结构和特点
XML文件由标签、属性和文本内容组成。标签用于标识数据的类型和结构,属性用于描述标签的特性,文本内容即为标签所表示的实际数据。
XML文件具有以下特点:
- 纯文本:XML文件以纯文本形式保存,可读性强,便于编辑、查看和传输。
- 树状结构:XML文件采用树状结构来组织数据,以标签和子元素的方式表示数据的层次关系。
- 自定义标签:XML文件可以使用自定义标签,灵活性高,适用于各种数据类型和领域。
- 元数据支持:XML文件可以使用属性来描述标签的特性和元数据,增加数据的丰富度和可读性。
- 跨平台兼容:XML文件不依赖特定的软件和硬件环境,在不同平台和系统之间可以保持数据的一致性和可互操作性。
## 1.3 XML文件的应用领域
XML文件在各个领域和行业都得到了广泛的应用,主要包括:
- 数据交换:XML文件作为一种通用的数据交换格式,用于在不同的系统和平台之间进行数据的传输和共享。例如,Web服务中常用的SOAP协议就使用XML格式来传递数据。
- 配置文件:XML文件常用于存储应用程序的配置信息,如数据库连接字符串、用户配置等。通过修改XML配置文件可以灵活地配置和调整应用程序的行为和设置。
- 数据存储:XML文件可以作为一种轻量级的数据库来存储和管理结构化数据。通过解析和操作XML文件,可以实现数据的存储、查询、更新和删除等操作。
- 文档标记:XML文件可以用于标记和描述各种类型的文档,如科技论文、法律文件、企业报告等。通过定义合适的XML结构,可以对文档进行结构化的处理和索引。
- 配置规范:XML文件常被用于定义和约束数据的结构和格式,如DTD(Document Type Definition)、XML Schema等。这些规范可以用于验证和限制XML文件的内容和格式,保证数据的准确性和完整性。
## 二、解析XML文件
### 2.1 基于DOM的解析方法
DOM(Document Object Model)是一种将XML文件表示为树状结构的解析方法,它将整个XML文件加载到内存中,并提供了一系列API来操作和访问XML文件的元素和属性。
#### 2.1.1 DOM解析的原理和使用
DOM解析的原理是将整个XML文件解析为一个包含节点(Node)和元素(Element)的树状结构,通过遍历树的节点和元素,我们可以访问和操作XML文件中的内容。
以下是使用Java语言进行DOM解析的示例代码:
```java
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DOMParserExample {
public static void main(String[] args) {
try {
// 创建DocumentBuilderFactory
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件
Document document = builder.parse("example.xml");
// 获取根节点
Element root = document.getDocumentElement();
// 遍历根节点下的所有子节点
NodeList nodeList = root.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
// 处理节点内容
// ...
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
这段代码首先创建了一个`DocumentBuilderFactory`实例,它是用于创建`DocumentBuilder`对象的工厂。
接着,我们使用`DocumentBuilder`解析XML文件,得到一个`Document`对象。
然后,通过`Document`对象的`getDocumentElement()`方法获取XML文件的根节点。
最后,遍历根节点下的所有子节点,并根据节点的类型来处理对应的元素内容。
DOM解析的使用过程比较简单,但它将整个XML文件都加载到内存中,对于大型XML文件而言,会占用大量的内存。
#### 2.1.2 DOM解析的优缺点
DOM解析的优点是可以方便地操作和修改XML文件的任意节点,具有灵活性和易用性。
然而,由于DOM解析将整个XML文件加载到内存中,对于大型的XML文件来说,会占用大量的内存,影响程序的性能。
### 2.2 基于SAX的解析方法
SAX(Simple API for XML)是另一种解析XML文件的方法,与DOM不同的是,SAX解析是一种基于事件驱动的解析方式。
#### 2.2.1 SAX解析的原理和使用
SAX解析的原理是通过事件回调机制,当解析器读取到XML文件的某个节点时,会触发相应的事件回调方法,我们可以在回调方法中处理对应的节点内容。
以下是使用Python语言进行SAX解析的示例代码:
```python
import xml.sax
class MyContentHandler(xml.sax.ContentHandler):
def __init__(self):
self.current_element = ""
self.current_data = ""
# 开始元素事件回调方法
def startElement(self, name, attrs):
self.current_element = name
# 结束元素事件回调方法
def endElement(self, name):
if self.current_element == "title":
# 处理标题元素内容
print("
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏基于Python文件操作,旨在全面介绍Python中文件操作的方方面面。从基础知识到高级技巧,涵盖了如何创建、打开、读取、写入、复制、移动、删除、重命名文件,以及获取文件信息、判断文件是否存在、处理文件异常、批量处理文件等内容。此外,还包括了文件路径操作、追加写入、读取和写入CSV文件、处理文本文件、解析和处理JSON、XML文件,以及文件加密与解密、文件压缩和解压缩等实用技能。通过本专栏的学习,读者将能够全面掌握Python中文件操作的各种方法和技巧,提高文件处理的效率和质量。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
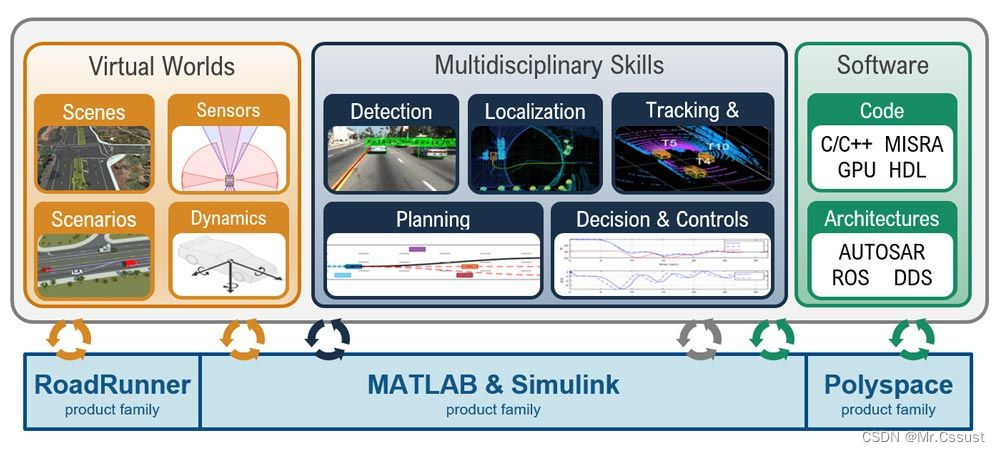
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
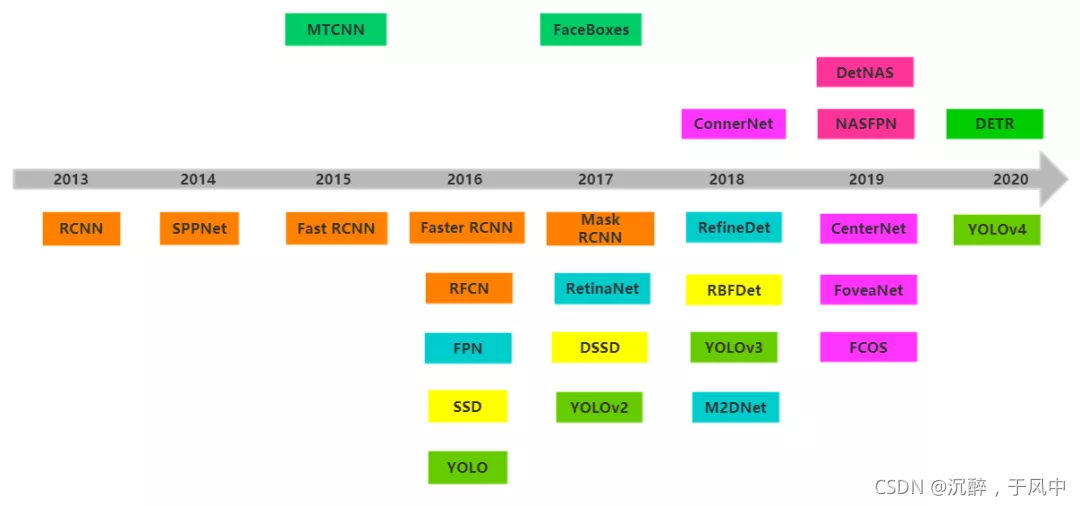
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )