【查询语句】:编写高效SQL的秘诀


63.基于51单片机的酒精气体检测器设计(实物).pdf
1. SQL基础回顾与优化概述
1.1 数据库与SQL的演进
SQL(Structured Query Language)是数据库领域中用于存储、检索和操作数据的标准编程语言。自1970年代诞生以来,SQL经历了多次版本更迭,包括MySQL、PostgreSQL、SQL Server和Oracle等众多数据库管理系统(DBMS)对其进行了支持和扩展。
1.2 SQL优化的必要性
在大数据量和高并发的数据库应用中,SQL语句的执行效率直接影响到系统的整体性能。优化SQL语句可以减少不必要的数据加载,降低I/O操作和CPU占用,从而提升响应速度和处理能力。
1.3 优化的原则与步骤
优化SQL语句应遵循逐步细化的原则。首先,确保数据库设计合理,如适当的数据类型和索引设置。其次,使用合适的查询结构,避免复杂嵌套。最后,利用工具如EXPLAIN来分析SQL执行计划,找出潜在的性能瓶颈,并进行针对性的优化。
- -- 示例:EXPLAIN分析SQL执行计划
- EXPLAIN SELECT * FROM users WHERE age > 30;
通过执行上述EXPLAIN命令,我们可以获得查询的详细执行步骤和资源消耗情况,从而进行后续的优化工作。
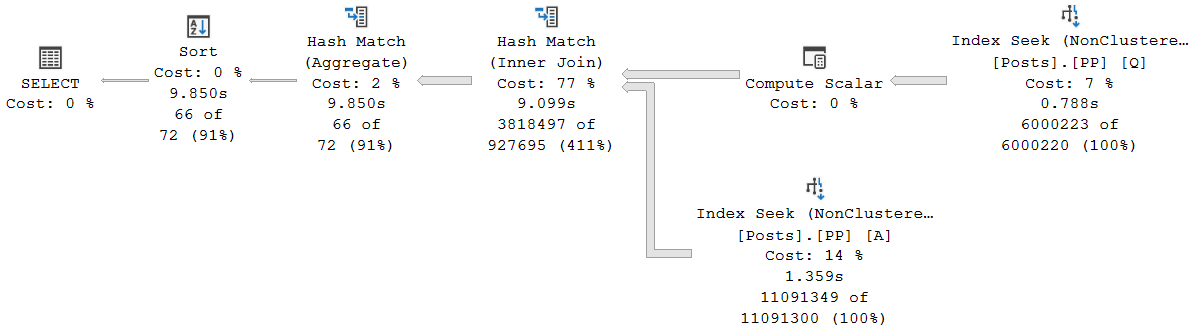
2. 深入理解SQL的执行计划
2.1 SQL执行计划的作用与解读
2.1.1 执行计划的基本概念
执行计划是SQL语句在数据库中执行时,优化器生成的一系列操作步骤,它决定了数据从存储介质中取出并返回给用户的顺序和方式。理解执行计划是优化SQL语句的前提,因为只有知道数据库是如何执行一条SQL语句的,才能发现其性能瓶颈并进行改进。
执行计划通常包括以下几个部分:
- 操作符(Operator):描述了数据库执行操作的步骤,如扫描表、排序、聚合等。
- 访问方法(Access Method):描述了如何访问数据,比如是全表扫描还是利用索引。
- 成本估算(Cost Estimate):数据库基于统计信息对操作所需资源的估算。
- 数据流(Data Flow):表示数据如何在操作符之间流转。
理解执行计划,就是分析上述各个组成部分,找到可能造成性能问题的环节,并进行针对性优化。
2.1.2 如何获取和解读执行计划
获取执行计划的方法依赖于使用的数据库系统,例如在MySQL中,可以在SQL语句前加上EXPLAIN关键字来获取,而在Oracle中,则使用EXPLAIN PLAN FOR语句。不同的数据库产品可能有不同的命令来显示执行计划。
解读执行计划时,需要关注以下关键信息:
- 操作符类型:如
TABLE ACCESS BY INDEX ROWID,NESTED LOOP等。 - 访问方法:例如
INDEX或FULL TABLE SCAN。 - 成本:通常表示为执行计划的一个数字,越低越好,但也需要注意实际的响应时间和资源消耗。
- 行数估算:优化器对返回行数的估计,可以帮助判断优化器是否合理估算了数据分布。
- 输出排序:是否需要额外的排序操作,排序通常非常耗时。
一个具体的执行计划实例可能如下所示:
- EXPLAIN
- SELECT * FROM employees WHERE department_id = 10;
执行后得到的执行计划可能看起来像这样:
- +----+-------------+-----------+------------+-------+---------------+----------+---------+------+--------+----------+-------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | rows | filtered | Extra |
- +----+-------------+-----------+------------+-------+---------------+----------+---------+------+--------+----------+-------+
- | 1 | SIMPLE | employees | NULL | index | NULL | idx Dept | 5 | 282 | 100.00 | Using where|
- +----+-------------+-----------+------------+-------+---------------+----------+---------+------+--------+----------+-------+
在这个例子中,数据库选择了使用idx Dept索引来快速定位到department_id = 10的记录。
2.2 优化器的选择与影响因素
2.2.1 优化器的工作原理
SQL优化器的主要任务是生成一个高效的执行计划,以最小的成本获取查询结果。它通常会考虑许多因素,如表的统计信息、索引的可用性、查询条件、表之间的关联关系等。
优化器的工作过程可以分为以下几个阶段:
- 查询转换:优化器尝试将原始的查询语句转换成更优的形式,例如子查询的扁平化、谓词下推等。
- 搜索空间:生成一个可能的执行计划列表,也就是搜索空间。
- 成本估算:对搜索空间中的每个计划计算成本。
- 选择最佳计划:根据成本估算,选择成本最低的计划执行。
优化器使用启发式规则和成本模型来评估不同执行路径的成本。启发式规则依赖于经验,而成本模型则基于统计信息和硬编码的成本常数。
2.2.2 影响优化器选择的因素
优化器的选择受许多因素的影响,主要包括:
- 表统计信息:统计信息包括表和索引中的行数、数据分布等。优化器根据这些信息来估算执行计划的成本。
- 索引的可用性和质量:如果可用,优化器会考虑使用索引,但索引并不总是最好的选择,特别是在涉及多个索引的情况下。
- 查询表达式:优化器会分析WHERE子句中的条件,以决定如何最高效地获取数据。
- 表之间的关联类型:如何连接表会显著影响性能,如嵌套循环、哈希连接、合并连接等。
- 并行执行选项:一些数据库系统支持并行查询,优化器会评估是否启用并行执行来加速查询。
- 资源限制:CPU、内存等系统资源的限制也会影响优化器的选择。
2.3 常见的查询优化技术
2.3.1 索引的使用与注意事项
索引是数据库性能优化中最重要的工具之一。它能够显著提高数据检索的速度,但使用不当也会造成性能下降。以下是一些关于索引使用的重要注意事项:
- 选择性高的列:在经常用于过滤和连接操作的列上创建索引可以显著提高性能。
- 复合索引:当查询条件涉及多个列时,复合索引(多列索引)通常比单列索引更有效。
- 索引列的顺序:在复合索引中,列的顺序决定了索引的效率,应根据查询模式来确定。
- 索引的维护开销:创建索引会增加数据修改操作(如INSERT、UPDATE、DELETE)的开销,因为索引也需要相应更新。
2.3.2 查询重写与逻辑优化策略
查询重写是通过对原始查询语句的逻辑调整来改善性能的一种方法。以下是一些常见的查询重写策略:
- 谓词下推:将WHERE子句中的条件尽可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PLC编程实战指南】:专家分享装入和传送指令的高效编码策略
【跨平台ECDSA实战指南】:在不同操作系统上顺利部署ECDSA
【高频电路设计】:无线通信挑战的应对策略
【拆机实践】:ThinkPad X220 的内部构造详解
系统扩展与维护两不误:【图书馆管理系统数据流图】绘制策略
ilitek电容屏驱动跨平台兼容性挑战:Windows_Linux_MacOS的适配策略
Buildroot交叉编译工具链调优指南:性能与效率兼得
玖逸云黑系统数据不丢失:备份与恢复的黄金策略
网络安全攻防演练:提升团队应对网络威胁的实战技巧!
三晶SAJ变频器行业应用案例:10个成功故事与经验分享


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )