yolo v5训练集和测试集的进阶技巧:数据采样和合成,挖掘数据价值,提升模型精度
发布时间: 2024-08-16 16:51:14 阅读量: 39 订阅数: 49 

河道漂浮物检测数据集:用于YOLO模型训练的高质量数据集

# 1. YOLO v5训练集和测试集概述**
YOLO v5训练集和测试集是机器学习模型训练和评估的关键组成部分。训练集用于训练模型,而测试集用于评估模型的性能。
训练集应包含大量高质量的标记数据。这些数据应代表模型在实际世界中遇到的数据分布。测试集应包含与训练集不同的数据,以确保模型能够泛化到新数据。
训练集和测试集的划分比例通常为80:20,即80%的数据用于训练,20%的数据用于测试。这种划分可以确保模型在训练和评估时具有足够的数据。
# 2. 数据采样和合成技术
### 2.1 数据采样策略
#### 2.1.1 过采样和欠采样
**过采样**:当训练集中某些类别的样本数量较少时,通过复制或生成新样本来增加这些样本的数量。
**欠采样**:当训练集中某些类别的样本数量较多时,通过随机删除部分样本来减少这些样本的数量。
**代码块:**
```python
import numpy as np
from sklearn.utils import resample
# 过采样
X_resampled, y_resampled = resample(X_minority, y_minority, replace=True)
# 欠采样
X_resampled, y_resampled = resample(X_majority, y_majority, replace=False)
```
**逻辑分析:**
* `resample()` 函数用于执行过采样或欠采样。
* `replace=True` 表示在过采样时允许复制样本。
* `replace=False` 表示在欠采样时不允许复制样本。
#### 2.1.2 数据增强技术
**数据增强**:通过对现有样本进行变换,生成新的样本,以增加训练集的多样性。
**常见的数据增强技术:**
* 旋转
* 翻转
* 裁剪
* 缩放
* 色彩抖动
**代码块:**
```python
import albumentations as A
# 定义数据增强变换
transform = A.Compose([
A.RandomRotate90(),
A.HorizontalFlip(),
A.RandomCrop(width=320, height=320),
A.RandomScale(scale_limit=0.2),
A.HueSaturationValue(hue_shift_limit=10, sat_shift_limit=10, val_shift_limit=10),
])
# 应用数据增强
augmented_images = []
for image in images:
augmented_images.append(transform(image=image)['image'])
```
**逻辑分析:**
* `albumentations` 库用于执行数据增强。
* `Compose()` 函数用于组合多个数据增强变换。
* `transform()` 函数将数据增强应用于图像。
### 2.2 数据合成方法
#### 2.2.1 图像生成模型
**图像生成模型**:通过学习真实图像的分布,生成新的图像。
**常见的图像生成模型:**
* 生成对抗网络 (GAN)
* 变分自编码器 (VAE)
**代码块:**
```python
import tensorflow as tf
# 定义 GAN 模型
generator = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(784, activation='sigmoid'),
tf.keras.layers.Reshape((28, 28, 1))
])
# 训练 GAN 模型
generator.compile(optimizer='adam', loss='binary_crossentropy')
generator.fit(noise, real_images, epochs=100)
# 生成新图像
generated_images = generator.predict(noise)
```
**逻辑分析:**
* `tf.keras.models.Seque

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏深入探讨 YOLO v5 训练集和测试集,揭示其优化数据分布、提升模型泛化能力的秘密。它强调避免过拟合和欠拟合的陷阱,并介绍数据验证和交叉验证等秘密武器,以打造稳健的模型。专栏还澄清常见误区,提供解决方案,避免模型训练的弯路。此外,它介绍了数据采样和合成等进阶技巧,以挖掘数据价值,提升模型精度。专栏还涵盖自动化、挑战、基准、深度分析、伦理影响、行业趋势、教育资源、开源工具和商业应用,为数据科学家、机器学习工程师和企业提供全面的指南,帮助他们优化 YOLO v5 模型,推动 AI 发展。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微机接口技术深度解析:串并行通信原理与实战应用
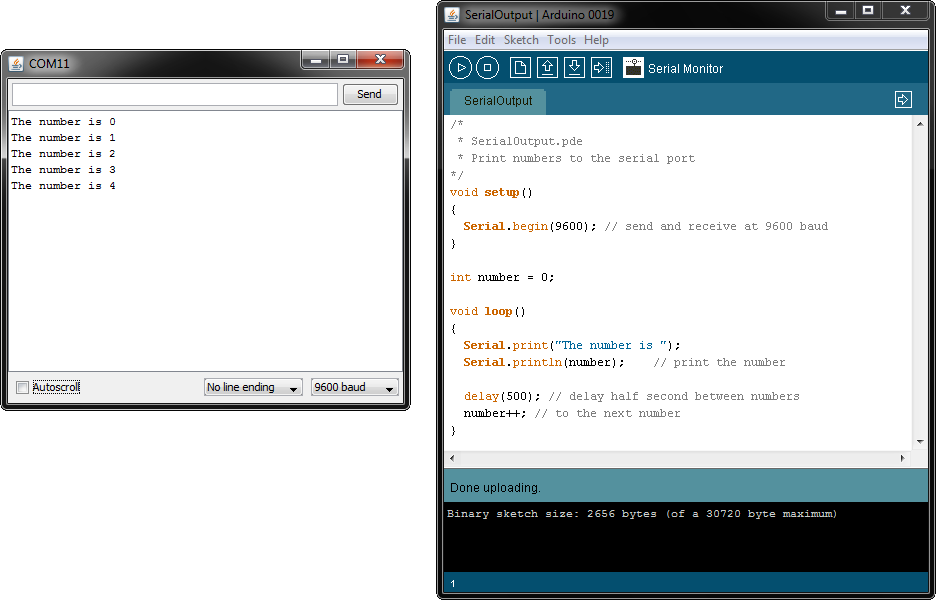
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
【进位链技术大剖析】:16位加法器进位处理的全面解析
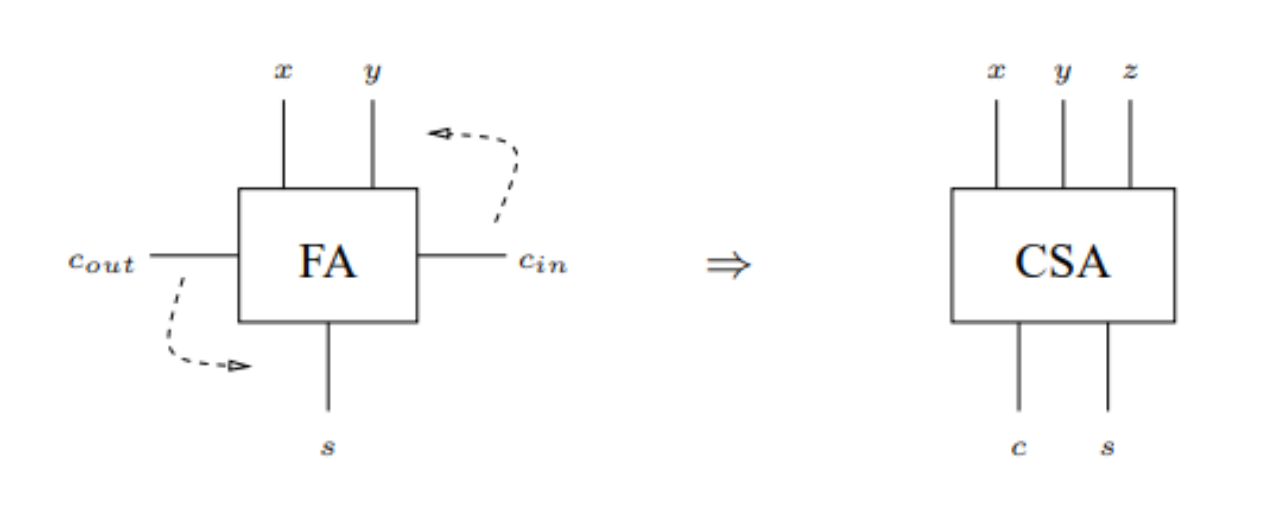
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
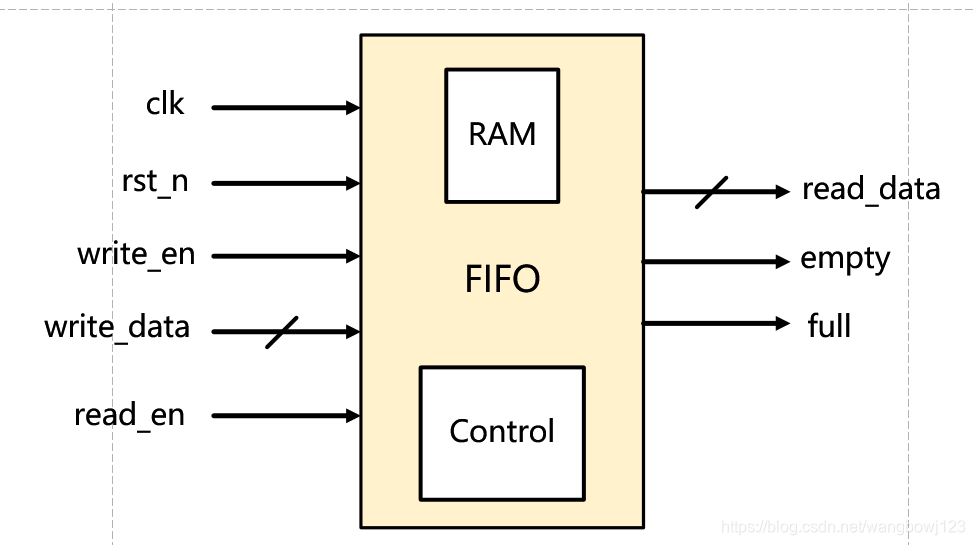
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )