Pandas库在数据分析中的应用
发布时间: 2024-03-27 15:00:27 阅读量: 7 订阅数: 16 
# 1. Pandas库简介
Pandas是Python中一个强大的数据处理库,广泛应用于数据分析、清洗、转换和处理等领域。本章将带您了解Pandas库的基本信息,包括其定义、历史以及在数据分析中的重要性。接下来,让我们深入了解Pandas库。
# 2. Pandas库基础操作
Pandas库是Python中一个强大的数据分析工具,提供了许多功能丰富且灵活的数据结构,使数据处理更加高效。在这一章节中,我们将介绍Pandas库的一些基础操作,包括数据结构、数据导入和导出,以及数据索引和选择。
- **数据结构:Series和DataFrame**
Pandas主要有两种核心数据结构:Series和DataFrame。
- Series是一维数组,类似于Python中的列表,但是带有标签,可以保存不同类型的数据。
- DataFrame是二维表格,类似于Excel表格,由行和列组成,是最常用的数据结构。
```python
import pandas as pd
# 创建Series
data = pd.Series([1, 2, 3, 4, 5])
print(data)
# 创建DataFrame
data = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': ['a', 'b', 'c', 'd', 'e']})
print(data)
```
- **数据导入和导出**
Pandas可以方便地读取和写入各种数据格式,如CSV、Excel、SQL数据库等。
```python
# 从CSV文件导入数据
data = pd.read_csv('data.csv')
# 将数据保存为Excel文件
data.to_excel('data.xlsx', index=False)
```
- **数据索引和选择**
可以使用标签、位置等方式对数据进行索引和选择,方便获取所需的数据。
```python
# 使用标签选择数据
print(data['A'])
# 使用位置选择数据
print(data.iloc[0])
```
通过这些基础操作,我们可以更加灵活地处理数据,为后续的数据清洗、分析和可视化打下基础。
# 3. 数据清洗与预处理
数据清洗与预处理在数据分析中起着至关重要的作用,能够帮助我们处理数据中的噪声、缺失值和不一致性,使数据更具可靠性和可分析性。在Pandas库中,有许多方法可以用来进行数据清洗与预处理。
- **3.1 缺失值处理**
在实际数据分析中,经常会遇到一些数据缺失的情况,这时我们就需要对缺失值进行处理。Pandas提供了一系列方法来处理缺失值,比如 `dropna()` 方法用于删除包含缺失值的行或列,`fillna()` 方法用于填充缺失值等。
```python
# 导入Pandas库
import pandas as pd
# 创建包含缺失值的DataFrame
data = {'A': [1, 2, None, 4],
'B': [5, None, 7, 8]}
df = pd.DataFrame(data)
# 删除包含缺失值的行
cleaned_df = df.dropna()
print("删除缺失值后的DataFrame:")
print(cleaned_df)
# 填充缺失值为特定值
filled_df = df.fillna(0)
print("填充缺失值后的DataFrame:")
print(filled_df)
```
**代码总结**:以上代码演示了如何使用Pandas处理DataFrame中的缺失值,通过`dropna()`方法删除包含缺失值的行,通过`fillna()`填充缺失值为指定的值。
**结果说明**:经过处理后,得到了删除缺失值和填充缺失值后的DataFrame数据。
- **3.2 重复数据处理**
另一个常见的数据清洗任务是处理重复数据。重复数据可能会对分析结果产生误导,因此需要将其识别并进行处理。Pandas中的`duplicated()`和`drop_duplicates()`方法可以帮助我们处理重复数据。
```python
# 从列表创建包含重复数据的DataFrame
data = {'A': [1, 2, 2, 3, 4],
'B': ['a', 'b', 'b', 'c', 'd']}
df = pd.DataFrame(data)
# 查找重复行
duplicate_rows = df[df.duplicated()]
print("重复行:")
print(duplicate_rows)
# 删除重复行
cleaned_df = df.drop_duplicates()
print("删除重复行后的DataFrame:")
print(cleaned_df)
```
**代码总结**:以上代码展示了如何使用Pandas库处理DataFrame中的重复数据,通过`duplicated()`方法查找重复行,通过`drop_duplicates()`方法删除重复行。
**结果说明**:经过处理后,成功找到重复行并删除,得到了处理后的DataFrame数据。
- **3.3 数据类型转换**
在数据分析中,有时候需要将数据转换为特定的数据类型,比如将字符串转换为数字类型。Pandas提供了`astype()`方法来进行数据类型的转换。
```python
# 创建包含不同数据类型的DataFrame
data = {'A': [1, 2, 3],
'B': ['4', '5', '6']}
df = pd.DataFrame(data)
# 将B列的数据类型从字符串转换为整数
df['B'] = df['B'].astype(int)
print("数据类型转换后的DataFrame:")
print(df)
```
**代码总结**:以上代码演示了如何使用Pandas进行数据类型转换,通过`astype()`方法可以将DataFrame中的某一列数据类型进行转换。
**结果说明**:成功将B列的数据类型从字符串转换为整数类型。
通过以上对数据清洗与预处理的介绍,我们可以看到Pandas库提供了丰富的功能来帮助我们处理数据中的缺失值、重复数据和数据类型转换,为后续的数据分析奠定了基础。
# 4. 数据分析与统计
在数据分析过程中,Pandas库提供了丰富的功能来进行数据的统计分析,包括对数据进行汇总统计、排序排名以及分组聚合等操作。下面将详细介绍Pandas库在数据分析与统计方面的应用。
#### 4.1 汇总统计
在进行数据分析时,经常需要对数据进行汇总统计,例如计算总和、均值、中位数、最大值、最小值等。Pandas库中的`describe()`方法可以一次性输出DataFrame中数值型数据的汇总统计信息,如计数、均值、标准差、最小值、最大值等。
```python
import pandas as pd
# 创建示例DataFrame
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 输出DataFrame的汇总统计信息
summary_stats = df.describe()
print(summary_stats)
```
**代码总结:** 使用`describe()`方法可以快速查看DataFrame中数值型数据的统计信息,有助于对数据的整体了解。
**结果说明:** 上述代码将输出DataFrame `df` 中数值型列的汇总统计信息,包括计数、均值、标准差、最小值、最大值等。
#### 4.2 数据排序与排名
数据排序是数据分析中常用的操作之一,可以通过Pandas库的`sort_values()`方法对DataFrame中的数据进行排序操作。同时,`rank()`方法可以实现数据排名功能,返回每个元素在原始数据中的排名。
```python
# 按列'B'降序排列
df_sorted = df.sort_values(by='B', ascending=False)
print(df_sorted)
# 计算列'A'的排名
df['A_rank'] = df['A'].rank()
print(df)
```
**代码总结:** 使用`sort_values()`方法可以对数据进行排序操作,而`rank()`方法可以得到数据的排名信息。
**结果说明:** 上述代码先按列'B'降序排列DataFrame,并输出排序后的结果;然后计算了列'A'的排名信息,并将结果添加到DataFrame中。
#### 4.3 数据分组与聚合
数据分组与聚合是数据分析中非常重要的环节,通过Pandas库可以轻松实现数据的分组和聚合操作。使用`groupby()`方法可以按照指定的列进行数据分组,然后结合聚合函数对分组后的数据进行统计等操作。
```python
# 创建示例DataFrame
data = {'Key': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40, 50, 60]}
df_group = pd.DataFrame(data)
# 按'Key'列分组,并计算每组的平均值
grouped = df_group.groupby('Key').mean()
print(grouped)
```
**代码总结:** 使用`groupby()`方法可以对数据进行分组操作,然后结合聚合函数实现统计计算等操作。
**结果说明:** 上述代码按'Key'列进行分组,然后计算每组的平均值,并输出结果。
通过Pandas库的数据分析与统计功能,我们可以更深入地理解数据的特征、趋势和规律,为后续的决策提供数据支持。
# 5. 数据可视化
数据可视化在数据分析中扮演着至关重要的角色。通过可视化数据,我们能够更直观地理解数据的特征、趋势和规律,为数据分析提供更直观、更具说服力的结果展示。Pandas库搭配Matplotlib和Seaborn等数据可视化库,能够轻松实现各种图表的绘制。
#### 5.1 数据可视化的重要性
数据可视化不仅可以帮助我们更好地理解数据,还可以帮助我们向他人传达数据分析的结果。图表能够直观展现数据之间的关系,突出数据的规律,帮助我们做出更准确的决策。
#### 5.2 使用Matplotlib和Seaborn库配合Pandas绘制图表
在Pandas库中,可以通过`.plot()`方法直接绘制各种类型的图表,如折线图、柱状图、散点图等。此外,还可以结合Matplotlib和Seaborn库来对图表进行更加灵活的定制和美化。
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 创建一个示例DataFrame
data = {
'A': np.random.rand(50),
'B': np.random.rand(50),
'C': np.random.rand(50)
}
df = pd.DataFrame(data)
# 绘制折线图
df.plot()
plt.show()
# 绘制散点图
sns.scatterplot(x='A', y='B', data=df)
plt.show()
```
通过上述代码,我们可以利用Pandas快速绘制数据的折线图和散点图,并且通过Matplotlib和Seaborn可以进一步对图表进行美化和定制。
#### 5.3 数据图表的优化和美化
除了基本的绘图功能外,我们还可以利用Matplotlib和Seaborn库对数据图表进行优化和美化,比如调整图表大小、添加标题、调整颜色、设置坐标轴名称等。这些操作能够让我们的图表更加易于理解和具有美感。
综上所述,数据可视化是数据分析过程中不可或缺的一环,而Pandas搭配Matplotlib和Seaborn等库能够帮助我们高效地实现数据图表的绘制、优化和美化。
# 6. 实战案例分析
在本章中,我们将通过具体的案例来展示Pandas库在数据分析中的实际运用。我们将分别讨论通过Pandas库进行销售数据分析、处理金融数据以及进行文本数据分析的案例。
#### 6.1 通过Pandas库进行销售数据分析
在这个案例中,我们将使用Pandas库对某公司的销售数据进行分析,以了解销售情况并找出潜在的增长机会。
```python
# 导入Pandas库
import pandas as pd
# 读取销售数据
sales_data = pd.read_csv('sales_data.csv')
# 查看数据结构
print(sales_data.head())
# 分析销售额总和
total_sales = sales_data['Sales'].sum()
print("总销售额为:", total_sales)
# 找出销售额最高的产品
max_sales_product = sales_data.loc[sales_data['Sales'].idxmax(), 'Product']
print("销售额最高的产品是:", max_sales_product)
# 分析每个区域的销售情况
sales_by_region = sales_data.groupby('Region')['Sales'].sum()
print("各区域销售额情况:")
print(sales_by_region)
```
通过这些代码,我们可以对销售数据进行整体分析,包括总销售额、最畅销的产品以及各个区域的销售情况。
#### 6.2 利用Pandas库处理金融数据
这个案例将展示如何使用Pandas库处理金融数据,进行投资组合分析和风险管理。
```python
# 导入Pandas库
import pandas as pd
# 读取金融数据
financial_data = pd.read_csv('financial_data.csv')
# 查看数据结构
print(financial_data.head())
# 计算收益率
financial_data['Return'] = financial_data['Price'].pct_change()
# 计算波动率
volatility = financial_data['Return'].std() * (252 ** 0.5)
print("波动率为:", volatility)
# 计算年收益率
annual_return = (financial_data['Return'].mean() * 252) * 100
print("年收益率为:", annual_return)
```
这段代码展示了如何计算金融数据的收益率、波动率和年收益率,这对于投资者来说是非常重要的指标。
#### 6.3 使用Pandas库进行文本数据分析
在这个案例中,我们将展示如何利用Pandas库对文本数据进行分析,包括处理文本、提取关键信息和进行情感分析。
```python
# 导入Pandas库
import pandas as pd
# 读取文本数据
text_data = pd.read_csv('text_data.csv')
# 查看数据结构
print(text_data.head())
# 统计词频
word_count = text_data['Text'].str.split(expand=True).stack().value_counts()
print("词频统计:")
print(word_count)
# 进行情感分析(以VADER情感分析为例)
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
text_data['Sentiment'] = text_data['Text'].apply(lambda x: analyzer.polarity_scores(x)['compound'])
# 查看情感分析结果
print("情感分析结果:")
print(text_data[['Text', 'Sentiment']])
```
上述代码展示了如何统计文本数据中的词频以及进行情感分析,这对于文本数据处理和挖掘潜在信息非常有帮助。
通过以上三个实战案例,我们可以看到Pandas库在不同领域的应用,展示了其在数据分析中的强大功能和灵活性。
0
0
相关推荐

专栏简介
这个专栏以"Python实现Fama French五因子模型"为主题,内容涵盖了从Python基础入门、数据处理、Pandas库在数据分析中的应用,到数据可视化、线性回归模型、多元线性回归模型等内容。专栏还深入探讨了资本资产定价模型(CAPM)、投资组合理论、风险分析以及资产风险度量方法等主题。特别地,专栏详细解析了Fama French三因子模型及其原理,并重点介绍了Fama French五因子模型的内容。此外,通过一系列Python实现的文章,展示了如何在实践中应用Fama French五因子模型进行量化投资分析。专栏内容丰富、深入,适合对量化投资及资本市场模型感兴趣的读者学习参考。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
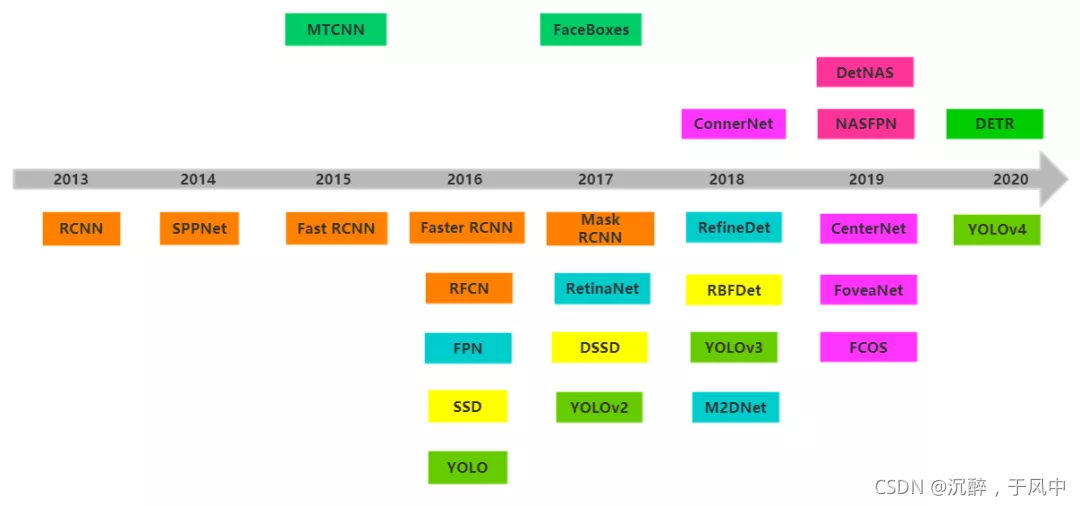
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
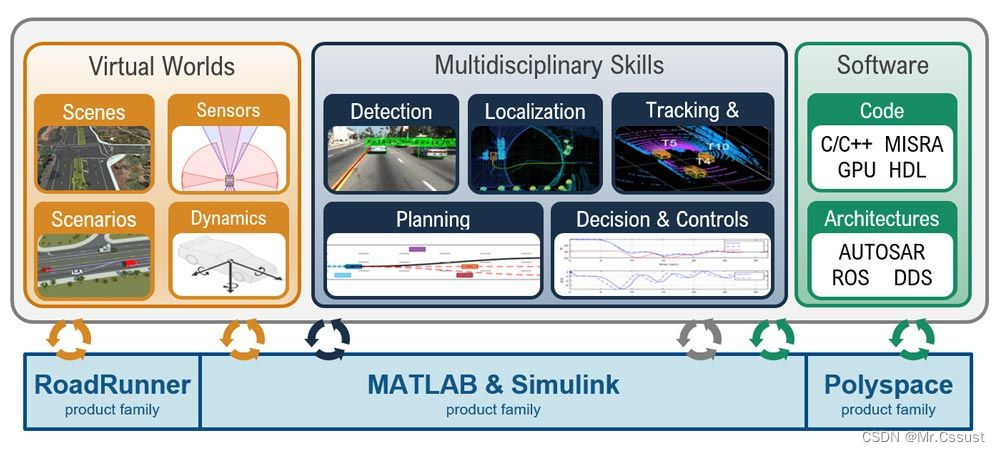
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )