SQLAlchemy水平与垂直分区:大型数据集处理的策略与实践(稀缺性+推荐词汇)
发布时间: 2024-10-13 05:02:31 订阅数: 8 
# 1. SQLAlchemy分区概述
## 1.1 分区技术简介
SQLAlchemy 是一款流行的 Python SQL 工具包,它提供了一系列高级接口,用于数据库交互。在处理大型数据集时,分区技术是提高数据管理效率的关键策略。分区技术通过将数据分散存储在不同的逻辑单元中,可以显著提升查询效率、简化数据维护,并且有助于更好地管理数据增长。
## 1.2 分区技术的重要性
随着数据量的激增,传统数据库的性能往往会受到严重影响。分区技术能够将大型表分解成更小、更易于管理的部分,从而提高数据库的响应速度和可扩展性。这对于需要处理大量数据的企业来说,不仅可以提升系统的整体性能,还能降低数据维护的复杂性。
## 1.3 SQLAlchemy与分区
SQLAlchemy 支持通过编程方式创建和管理分区表。虽然 SQLAlchemy 不直接提供分区功能,但开发者可以通过扩展 SQLAlchemy 的功能或结合原生 SQL 语句来实现复杂的分区策略。这一章将深入探讨 SQLAlchemy 分区的各个方面,包括基本概念、理论与实践、优化以及未来趋势。
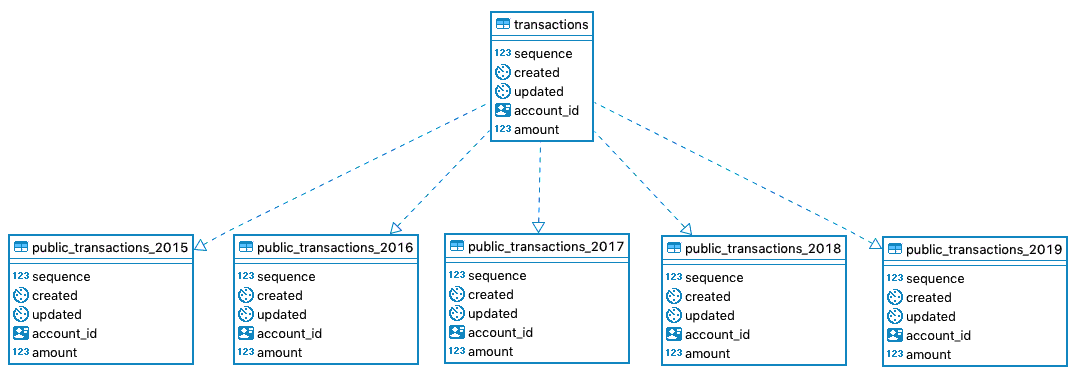
# 2. SQLAlchemy水平分区的理论与实践
## 2.1 水平分区的基本概念
### 2.1.1 水平分区的定义和原理
水平分区(Horizontal Partitioning)是一种数据库架构策略,它将表中的数据分布到不同的物理部分,这些部分在逻辑上是相同的,但在物理上是独立的。这种策略通常用于处理大型数据库表,它可以显著提高查询性能和数据管理的灵活性。
在水平分区中,表被分割成多个较小的、更易于管理的部分,每个部分称为一个分区。每个分区包含了表的一部分数据,这些数据根据分区键(Partition Key)的值来进行分配。分区键通常是一个或多个列的组合,它们用于决定每条记录应该属于哪个分区。
#### 例子
例如,我们有一个电子商务网站的订单表,订单表非常大,包含数百万条记录。我们可以根据订单创建的月份来对这个表进行水平分区,即每个月的数据存放在不同的分区中。
### 2.1.2 水平分区的优势和适用场景
水平分区的主要优势包括:
1. **提高查询性能**:通过将数据分散到多个分区,可以减少单个查询操作的范围,从而提高查询效率。
2. **简化数据管理**:分区有助于简化数据备份和恢复操作,因为可以独立备份和恢复单个分区。
3. **提高数据加载和维护效率**:由于分区数量减少,数据加载和维护操作的性能也会提高。
水平分区适用于以下场景:
1. **大型表的管理**:当表变得非常大时,水平分区可以帮助管理数据。
2. **提高查询效率**:对于经常需要根据某些键值进行查询的应用,水平分区可以显著提高查询性能。
3. **数据生命周期管理**:对于有明确数据保留期限的应用,可以将数据分区按时间划分,便于管理和清理。
## 2.2 水平分区的设计与实现
### 2.2.1 分区键的选择
选择合适的分区键是水平分区设计的关键。分区键应该满足以下条件:
1. **均匀分布**:分区键的值应该均匀分布在所有分区中,避免数据倾斜。
2. **访问模式**:分区键应该与查询模式相匹配,以便查询能够有效地定位到特定的分区。
#### 例子
在我们的电子商务订单表的例子中,如果我们经常根据订单创建的月份来查询数据,那么将月份作为分区键是一个不错的选择。
### 2.2.2 分区策略的制定
分区策略定义了如何将数据分配到各个分区。常见的分区策略包括:
1. **范围分区**:根据分区键的范围将数据分配到不同的分区。
2. **散列分区**:根据分区键的散列值将数据分配到不同的分区。
#### 例子
对于按月份进行范围分区的订单表,每个月的数据都会被存储在不同的分区中。如果使用散列分区,那么具有相似散列值的记录将被存储在同一个分区中。
## 2.3 水平分区的高级应用
### 2.3.1 分区表的性能优化
水平分区表的性能优化可以通过以下方式实现:
1. **索引优化**:对分区键进行索引,以加快查询速度。
2. **查询优化**:设计查询以便只访问相关的分区。
### 2.3.2 分区表的维护和监控
分区表的维护和监控包括:
1. **分区维护**:定期清理和优化分区。
2. **监控性能**:监控分区表的性能,确保查询效率。
### 代码块示例
以下是一个使用SQLAlchemy创建水平分区表的代码示例:
```python
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, Sequence
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Order(Base):
__tablename__ = 'orders'
__table_args__ = {'schema': 'sales'}
id = Column(Integer, Sequence('order_seq'), primary_key=True)
product_id = Column(String)
customer_id = Column(Integer)
# 分区键
order_date = Column(String)
# 创建数据库引擎
engine = create_engine('postgresql://user:password@localhost:5432/mydatabase')
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 创建表
Base.metadata.create_all(engine)
# 插入数据示例
new_order = Order(product_id='P001', customer_id=1, order_date='2023-01')
session.add(new_order)
***mit()
```
#### 参数说明和逻辑分析
- `__tablename__`:定义了表的名称。
- `__table_args__`:定义了表的schema和分区键。
- `order_date`:作为分区键,用于决定记录应该存放在哪个分区。
- `engine`:定义了数据库连接。
- `Session`:用于数据库会话管理。
在本章节中,我们首先介绍了水平分区的基本概念,包括其定义、原理以及优势和适用场景。随后,我们探讨了分区键的选择和分区策略的制定,这些都是设计和实现水平分区的关键步骤。最后,我们通过代码示例展示了如何使用SQLAlchemy创建水平分区表,并进行了参数说明和逻辑分析。通过本章节的介绍,你可以了解到水平分区的理论基础以及如何在实践中应用这一技术。
# 3. SQLAlchemy垂直分区的理论与实践
## 3.1 垂直分区的基本概念
### 3.1.1 垂直分区的定义和原理
垂直分区(Vertical Partitioning)是一种数据库架构策略,它将表中的列划分为多个较小的部分,每个部分被称为一个分区。这种分区方式主要用于提高查询性能和管理大型表。垂直分区的原理是通过将表中频繁一起使用的列组合在一起,减少每次查询需要读取的数据量,从而提高性能。
在SQLAlchemy中,垂直分区的实现通常涉及定义不同的模型类(Table),每个类对应数据库中的一个分区。这些模型类之间通过外键关联,形成一个逻辑上的完整表结构。通过这种方式,可以将大型表分解为多个逻辑上相关联但物理上分离的表。
### 3.1.2 垂直分区的优势和适用场景
垂直分区的主要优势在于它能够减少数据库的I/O负载,提高查询效率,尤其是在以下场景中特别有用:
- **大型表优化**:当一个表非常大,且只有一部分列经常被查询时,垂直分区可以显著减少不必要的数据读取。
- **提高查询性能**:通过减少每次查询所需的数据量,垂直分区可以提高查询响应速度。
- **数据管理**:对于不同类型的数据,垂直分区可以提供更好的管理,如将敏感信息与普通信息分开存储。
垂直分区的适用场景包括但不限于:
- **CRM系统中的用户信息管理**:用户的个人信息(如姓名、地址)和交易信息(如订单、支付记录)可以分别存储在不同的分区中。
- **电子商务平台**:产品信息和用户评论可以分别存储,以优化查询性能。
### 3.1.3 垂直分区的设计与实现
#### *.*.*.* 分区列的选择
在设计垂直分区时,选择合适的列进行分区是关键。通常,我们会根据以下因素来选择分区列:
- **查询模式**:分析数据库的查询模式,找出经常一起被查询的列。
- **数据类型和大小**:考虑数据的类型和大小,将大字段单独分区可以减少不必要的I/O。
- **数据访问频率**:频繁访问的列应放在一个分区中,以减少查询延迟。
#### *.*.*.* 分区策略的制定
垂直分区的策略制定需要考虑数据的物理存储和逻辑访问。以下是一些常用的分区策略:
- **按功能分区**:将相关功能的列放在同一个分区中,如用户信息、订单信息等。
- **按访问频率分区**:将访问频率高的列与低频列分开,以优化性能。
- **按数据敏感性分区**:将敏感数据与非敏感数据分离,增强安全性。
### 3.1.4 垂直分区的高级应用
#### *.*.*.* 分区表的性能优化
垂直分区的性能优化可以从多个方面进行:
- **索引优化**:为分区列创建索引,提高查询效率。
- **查询优化**:优化SQL查询语句,减少不必要的分区访问。
- **数据缓存**:对频繁访问的数据进行缓存,减少数据库负载。
#### *.*.*.* 分区表的维护和监控
分区表的维护包括定期的数据清理、分区的扩展和缩减等。监控则需要关注分区表的性能指标,如查询时间、I/O负载等。
### 3.1.5 分区策略的决策过程
#### *.*.*.* 业务需求分析
在实施垂直分区之前,需要进行详细的业务需求分析,确定哪些列需要分区,以及分区的粒度。
#### *.*.*.* 分区方案的选择
根据业务需求分析的结果,选择合适的分区方案。方案的选择应考虑到实际的数据量、查询模式以及维护成本。
### 3.1.6 分区策略的实践案例
#### *.*.*.* 案例研究:垂直分区实例
在实际应用中,垂直分区可以帮助解决大型数据集的性能问题。以下是一个垂直分区的实践案例:
**案例背景**:一个电商平台的用户表包含用户的基本信息、交易历史和评论信息。用户的基本信息(如姓名、邮箱)和交易历史(如订单号、购买时间)经常一起被查询,而评论信息则较少被访问。
**分区策略**:将用户的基本信息和交易历史放在一个分区,将评论信息单独放在另一个分区。
**实现方式**:
```python
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.orm import declarative_base, relationship, sessionmaker
Base = declarative_base()
class UserInfo(Base):
__tablename__ = 'user_info'
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
# 其他用户基本信息列...
class UserTransaction(Base):
__tablename__ = 'user_transaction'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user_info.id'))
order_number = Column(String)
purchase_time = Column(String)
user = relationship("UserInfo", back_populates="transactions")
# 其他交易信息列.
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【代码重构技巧】:从wsgiref.handlers迁移到高效框架
# 1. 代码重构与性能优化基础
## 1.1 代码重构的定义与原则
代码重构是一种改善现有代码结构而不会改变其外部行为的过程。它是软件开发中持续维护的重要环节,有助于提升代码的可读性、可维护性和可扩展性。重构的核心原则包括:
- **不要改变现有行为**:重构的目标是改进代码结构,而非改变程序的功能。
- **小步快跑**:每次只做一个小的修改,这样更容易发现
【Python mmap内存映射文件的内存管理】:最佳内存分配策略揭秘

# 1. Python内存映射文件概述
Python中的内存映射文件是一种高效的数据处理方法,它允许程序将文件的一部分或全部内容映射到内存地址空间中,这样文件内容就可以像操作内存一样进行读写。这种技术特别适用于处理大型数据文件,因为它可以减少磁盘I/O操作,提高数据访问速度。
## 内存映射技术简介
内存映射技术是一种将文件或设备的物理内存
Python中的POSIX资源管理:系统资源限制与性能监控的策略

# 1. POSIX资源管理概述
在现代操作系统中,POSIX资源管理是确保系统稳定性和性能的关键机制。本章节将概述POSIX资源管理的基本概念,以及它是如何在不同应用场景中发挥作用的。
## 1.1 POSIX资源限制的基本概念
POSIX标准定义了一套用于进程资源管理的接口,这些接口允许系统管理员和开发者对系统资源进行精细控制。通过设置资源限制,可以防止个别进程消耗过多
PythonCom实践指南:揭秘自动化Windows任务和控制台命令的技巧

# 1. PythonCom简介与环境搭建
PythonCom是Python语言的一个扩展库,它提供了一种简单的方式来操作COM(组件对象模型)组件,使得Python脚本能够与Windows应用程序进行交互。在这一章中,我们将介绍PythonCom的基本概念和如何搭建相应的开发环
SCons脚本安全性分析:防范构建过程中的安全风险

# 1. SCons脚本安全性概述
在当今快速发展的IT行业中,自动化构建工具如SCons已经成为构建和管理软件项目不可或缺的一部分。然而,随着脚本在构建过程中的广泛应用,脚本安全性问题逐渐凸显,尤其是SCons脚本的安全性问题。本章将概述SCons脚本安全性的重要性,分析其面临的安全性挑战,并为读者提供一个全面的安全性概览,为后续章节的深入探讨打下基础。我们将
【Nose插件与API测试框架】:构建RESTful API的测试之道

# 1. RESTful API测试基础
在当今的软件开发领域,RESTful API已成为构建现代Web服务的标准。随着微服务架构和物联网的兴起,对RESTful API进行有效测试的需求日益增长。本章旨在介绍RESTful API测试的基础知识,为
流量控制与拥塞避免:Thrift Transport层的6大核心策略

# 1. Thrift Transport层概述
## 1.1 Thrift Transport层的作用与重要性
Apache Thrift是一个接口定义语言和二进制通讯协议,它被广泛用于服务端与客户端之间的高效数据交换。Transport层在Thrift架构中扮演着至关重要的角色,它是Thrift通信
【sre_parse与数据可视化】:准备可视化数据,sre_parse的实用技巧
# 1. sre_parse的基本概念与应用
## 基本概念
sre_parse是一个强大的数据处理工具,它结合了正则表达式和数据解析技术,能够高效地从复杂的文本数据中提取出有用信息。对于IT行业的从业者来说,sre_parse不仅是一个简单的文本处理工具,更是一个在数据预
【Django表单wizard错误处理艺术】:优雅管理表单验证与异常的技巧

# 1. Django表单wizard概述
Django作为一个高级的Web框架,提供了强大的工具来处理表单。其中,表单wizard是Django中处理多步骤表单流程的利器。Wizard(向导)模式允许我们将一个复杂的表单分解成多个步骤,用户可以在完成当前步骤后,逐步进入下一阶段。这种方式不仅可以提高用户体验,还能减轻服务器的负担,因为
数据库高效交互:Tornado HTTPServer数据库操作实践指南

# 1. Tornado HTTPServer基础概览
## 1.1 Tornado框架简介
Tornado是一个Python Web框架和异步网络库,由Facebook开发并开源。它适用于需要处理大量并发连接的场景,比如长轮询、WebSocket和其他需要实时通信的应用。
### 1.1.1 Tornado的特点
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )