Ubuntu系统管理精髓:揭秘Linux命令行工具与脚本自动化秘籍
发布时间: 2024-12-11 13:17:12 阅读量: 3 订阅数: 16 

Linux命令行与shell脚本编程、Linux C库函数及系统调用编程、Linux内核分析即应用.zip
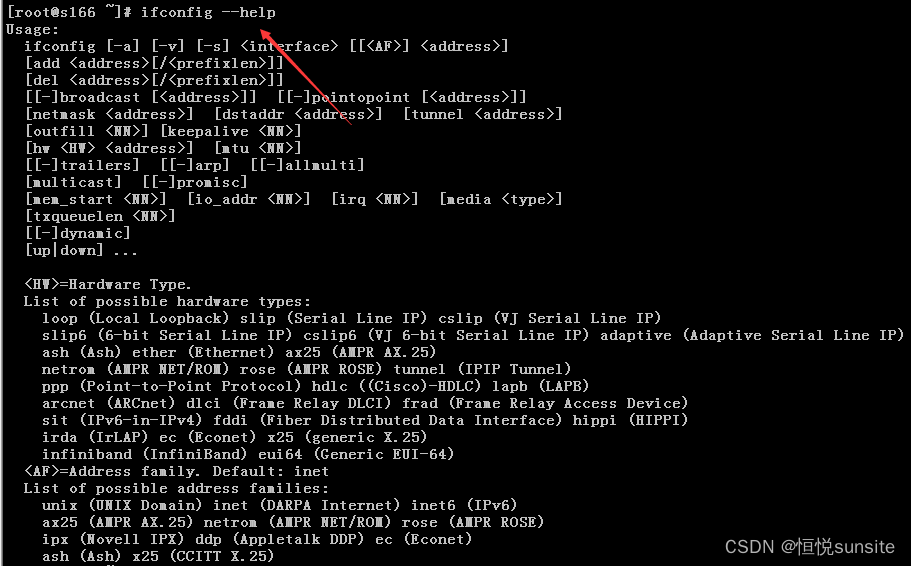
# 1. Linux命令行工具的精要
Linux作为操作系统的核心组件,命令行工具是管理Linux系统不可或缺的一部分。掌握这些工具的精要对于提高工作效率和系统维护具有重要意义。
## 基础命令的使用
首先,基本命令如`ls`,`cd`,`cp`,`mv`,`rm`等是操作文件和目录的基础。例如,`ls -l`可以列出文件的详细信息,`cd ..`可以切换到上级目录。熟悉这些命令可以让我们迅速浏览和管理文件系统。
## 文本处理工具
其次,文本处理工具如`grep`,`awk`,`sed`和`sort`等,它们是处理文本和数据流的强大武器。例如,`grep "pattern" file`可以搜索文件中包含特定模式的行,`awk '{print $1}' file`可以打印文件的每行第一列。
## 管道与重定向
此外,管道和重定向是Linux命令行的高级特性。通过管道`|`可以将一个命令的输出作为另一个命令的输入,而重定向操作符如`>`和`>>`可以用来将输出写入文件。
这些只是Linux命令行工具的冰山一角。随着学习的深入,我们将探索更多的工具和技巧,帮助我们更加高效和智能化地使用Linux系统。在接下来的章节中,我们将逐步深入系统管理、自动化脚本编写和内核定制等领域。
# 2. ```
# 第二章:Ubuntu系统管理基础
## 2.1 用户与权限管理
### 2.1.1 用户账户的创建和管理
用户账户是系统中识别和区分不同用户的标识。在Linux系统中,每个用户都有一个唯一的用户ID(UID)和一个或多个属于用户组的组ID(GID)。创建和管理用户账户是系统管理的基本任务之一。
创建新用户的基本命令是`adduser`或`useradd`。例如,创建一个名为`newuser`的新用户账户,可以使用以下命令:
```bash
sudo adduser newuser
```
该命令执行过程中会提示输入新用户的密码,并要求填写一些用户信息。如果需要在创建用户时指定UID和GID,可以使用`useradd`命令的`-u`和`-g`选项:
```bash
sudo useradd -u 1005 -g users newuser
```
该命令创建一个UID为1005,属于`users`组的新用户`newuser`。
用户账户的管理还包括删除用户、修改用户信息等操作。删除用户可以使用`deluser`或`userdel`命令,而修改用户信息则可以使用`usermod`命令。
用户账户管理不仅仅局限于命令行操作,还可以通过图形化工具进行,例如使用`Users`和`Groups`图形界面程序。
### 2.1.2 权限设置与访问控制列表ACL
文件和目录的权限决定了哪些用户可以读取、写入或执行这些资源。在Linux中,权限通过读(r)、写(w)和执行(x)来表示,分别对应用户(u)、组(g)和其他(o)。
设置权限可以使用`chmod`命令,例如:
```bash
sudo chmod 755 /path/to/directory
```
该命令设置指定目录的权限为755,即拥有者具有读、写和执行权限,组和其他用户具有读和执行权限。
访问控制列表(ACL)提供了比标准权限更灵活的权限设置方式。使用`setfacl`命令可以设置ACL,例如:
```bash
sudo setfacl -m u:newuser:rwx /path/to/directory
```
这条命令将`/path/to/directory`目录的权限赋予`newuser`用户,使其拥有读、写和执行权限。
查看ACL设置可以使用`getfacl`命令:
```bash
getfacl /path/to/directory
```
权限和ACL的正确设置是保障系统安全的关键。在多用户环境中,合理的权限设置可以防止未经授权的访问。
## 2.2 系统监控与性能调优
### 2.2.1 监控工具的使用和分析
监控Linux系统对于确保其稳定性和性能至关重要。系统管理员通常使用一系列的工具来监控系统状态和诊断问题。
常用的系统监控工具有`top`、`htop`和`vmstat`等。`top`命令提供了一个动态更新的系统状态视图,包括CPU使用率、内存使用情况、进程信息等。
```bash
top
```
`htop`是一个增强版的`top`,提供了更友好的界面和更多的交互功能。
`vmstat`命令则提供了关于系统内存、进程、CPU活动的信息。
```bash
vmstat 1
```
该命令将每秒刷新一次输出,帮助用户了解系统资源的实时使用情况。
监控数据的分析对于维护系统性能和稳定性至关重要。管理员需要根据监控数据来判断系统是否过载,是否需要进行优化或升级硬件。
### 2.2.2 性能调优的策略和方法
性能调优的目的是提高系统响应速度和处理能力。这通常涉及调整内核参数、优化文件系统性能和管理内存使用等方面。
调整内核参数可以通过修改`/etc/sysctl.conf`文件实现。例如,更改TCP/IP网络参数,可以添加或修改以下内容:
```conf
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
```
这些设置有助于加快TCP连接的回收和重复使用。
优化文件系统性能可以涉及到日志文件系统的选择和挂载选项的调整。例如,使用`noatime`选项可以减少文件访问时间的更新,从而提高性能。
```bash
/dev/sda1 /mnt/data ext4 defaults,noatime 0 2
```
内存管理优化可能包括调整虚拟内存设置和交换空间的配置。使用`swappiness`参数可以控制内核使用交换空间的倾向:
```bash
sysctl vm.swappiness=10
```
这些性能调优策略应该根据系统的具体应用场景和性能瓶颈来选择性实施。调整之后,使用前面提到的监控工具来评估调优的实际效果。
## 2.3 软件包管理与系统更新
### 2.3.1 APT包管理器的使用
Ubuntu系统使用APT(Advanced Packaging Tool)作为其主要的软件包管理工具,它负责安装、更新、升级和管理软件包。
使用`apt-get`或`apt`命令可以安装和更新软件包。例如,安装`vim`文本编辑器可以使用:
```bash
sudo apt update
sudo apt install vim
```
更新系统中的所有软件包:
```bash
sudo apt update
sudo apt upgrade
```
APT还会处理软件包之间的依赖关系,确保安装的软件包可以正常工作。
APT的源通常配置在`/etc/apt/sources.list`文件中,可以通过编辑该文件来添加新的软件仓库,从而安装更多软件包。
### 2.3.2 系统升级与补丁管理
系统升级是维护系统安全和引入新功能的重要步骤。APT不仅用于安装和更新单个软件包,还可以用来升级整个系统。
升级整个系统到最新版本的命令如下:
```bash
sudo apt update
sudo apt full-upgrade
```
`full-upgrade`命令会安装所有可用的更新,并解决升级过程中可能出现的依赖关系问题。
软件补丁管理是确保系统安全的关键组成部分。在发现安全漏洞时,软件开发商会发布补丁。通过定期运行更新命令,系统管理员可以确保系统中已安装的软件包是最新的,并包含了所有安全补丁。
管理软件包的卸载也很重要,使用以下命令可以卸载不再需要的软件包:
```bash
sudo apt remove package_name
sudo apt autoremove
```
在卸载软件包时,应确保不会移除系统正常运行所必需的依赖包。
软件包管理和系统更新是确保Ubuntu系统安全、稳定和高效运行的关键环节。通过熟练使用APT工具,系统管理员可以有效地管理软件包,并保持系统的最新状态。
```
# 3. Linux脚本自动化实战
在现代IT运维工作中,脚本自动化已成为一项关键技能,它能够帮助工程师高效地执行重复性任务,降低人为错误,提升系统稳定性。本章将深入探索Linux脚本自动化的核心知识点,从基础到应用,为您构建一个坚实的知识体系。
## 3.1 Bash脚本编写基础
编写脚本的第一步是掌握基础的编程概念,包括变量、参数传递、控制结构以及函数。这些元素共同构成了脚本的骨架,是构建任何复杂脚本所必需的。
### 3.1.1 变量、参数和控制结构
在Bash脚本中,变量用于存储信息,可以通过赋值操作来进行设置,并且在脚本中随时使用。参数则是在运行脚本时传递给它的值,这允许脚本更加灵活地根据不同的输入执行不同的逻辑。
#### 示例代码:
```bash
#!/bin/bash
# 定义变量并赋值
name="John Doe"
age=30
# 打印变量内容
echo "Name: $name"
echo "Age: $age"
# 参数传递示例
if [ -n "$1" ]; then
echo "Hello, $1!"
else
echo "Hello, world!"
fi
```
#### 代码逻辑解读:
- `#!/bin/bash`:这行是shebang,告诉系统用哪个解释器来执行此脚本。
- `name="John Doe"` 和 `age=30`:这里我们定义了两个变量,并赋予了它们字符串和数字类型的值。
- `echo`命令用于输出变量内容到终端。
- `$1` 是一个特殊的变量,用于接收脚本运行时传入的第一个参数。
- `if` 条件语句检查 `$1` 是否非空,即是否有参数被传递给脚本。
控制结构,如条件判断(if)、循环(for, while)等,让脚本能够进行逻辑判断和重复性操作。这些结构是脚本能够做出决策和处理数据的核心。
### 3.1.2 函数定义与调用
函数是组织代码、重复使用代码片段的有效方式。在Bash脚本中定义和调用函数是一个强大的功能,它可以使代码更清晰、更易维护。
#### 示例代码:
```bash
#!/bin/bash
# 定义函数
say_hello() {
echo "Hello, $1 from function!"
}
# 调用函数
say_hello "John"
```
#### 代码逻辑解读:
- `say_hello()` 函数定义了输出问候语的行为。`$1` 是该函数的参数。
- 调用 `say_hello "John"` 将参数 `"John"` 传入函数,并输出定制化的问候语。
## 3.2 脚本自动化任务部署
当编写脚本的能力得到加强后,可以开始考虑将脚本应用到实际任务中,实现自动化任务部署。这包括定时任务的设置和管理,以及自动化备份与恢复策略。
### 3.2.1 定时任务的设置与管理
Cron是Linux系统中的定时任务调度器,它允许用户以指定的时间间隔来运行命令或脚本。
#### 示例代码:
```bash
# 编辑cron任务表
crontab -e
# 在打开的编辑器中添加以下行
* * * * * /path/to/your/script.sh
# 保存并退出编辑器,crontab将会自动安装新的任务
```
#### 表格展示:
| 字段 | 描述 | 允许值 |
| --- | --- | --- |
| 第1个字段 | 分钟 | 0 - 59 |
| 第2个字段 | 小时 | 0 - 23 |
| 第3个字段 | 日期 | 1 - 31 |
| 第4个字段 | 月份 | 1 - 12 |
| 第5个字段 | 星期 | 0 - 7 (0 或 7 表示星期天) |
| 第6个字段 | 要运行的命令 | 任何有效的Linux命令 |
### 3.2.2 自动化备份与恢复策略
备份是防止数据丢失的重要措施。利用脚本进行自动化备份可以节省大量的时间和资源。
#### 示例脚本:
```bash
#!/bin/bash
# 定义变量
BACKUP_DIR="/var/backups"
DATE=$(date +%Y%m%d)
FILE="data_file"
# 创建备份目录
mkdir -p ${BACKUP_DIR}
# 执行备份操作
tar -czvf ${BACKUP_DIR}/${FILE}-${DATE}.tgz /path/to/data
# 清理旧备份
find ${BACKUP_DIR} -name "${FILE}-*.tgz" -mtime +7 -exec rm {} \;
```
#### 代码逻辑解读:
- 该脚本首先定义了备份目录和文件名变量。
- 使用 `mkdir` 创建备份目录,如果目录已存在则不会报错。
- `tar` 命令用于创建压缩包,备份数据目录。
- `find` 命令查找7天前的备份文件,并用 `rm` 命令删除它们。
## 3.3 脚本错误处理与日志记录
脚本在执行过程中可能会遇到错误,因此错误处理和日志记录机制对于跟踪脚本执行状态、诊断问题至关重要。
### 3.3.1 错误处理机制的实现
在编写脚本时,应当考虑到错误处理,以便于脚本在遇到问题时能够通知用户或记录错误信息。
#### 示例代码:
```bash
#!/bin/bash
# 错误处理示例
command || {
echo "Error: Command failed" 1>&2
exit 1
}
# 其他操作...
```
#### 逻辑分析:
- `command ||`:如果 `command` 执行失败,则执行大括号内的命令。
- `echo "Error: Command failed" 1>&2`:将错误信息输出到标准错误输出。
- `exit 1`:脚本以非零状态退出,表示失败。
### 3.3.2 日志管理与分析技巧
良好的日志记录能够为维护系统提供重要信息。脚本应当记录关键活动,如执行时间、操作细节、成功或失败的状态等。
#### 示例代码:
```bash
#!/bin/bash
# 定义日志文件路径
LOG_FILE="/var/log/script.log"
# 记录开始时间
echo "Script start: $(date)" >> ${LOG_FILE}
# 执行脚本操作...
# ...
# 记录结束时间
echo "Script end: $(date)" >> ${LOG_FILE}
```
#### 逻辑分析:
- `>>`:使用追加模式将输出信息写入到日志文件中。
- `${LOG_FILE}`:定义了日志文件的存储路径。
- 通过记录脚本开始和结束的时间,可以估计执行时长,并判断脚本是否正确执行。
通过以上章节的介绍,我们已经涵盖了编写Bash脚本的基础知识,实现自动化任务部署的策略,以及脚本中错误处理和日志记录的重要性。接下来,我们可以将这些知识应用于更复杂的实际场景中。在后续章节中,我们将深入探讨更高级的系统管理技巧、系统安全强化、虚拟化与容器技术、自动化部署与配置管理,以及Linux内核的编译、优化和定制化构建。
# 4. 高级系统管理技巧
## 系统安全强化
### 防火墙配置与安全策略
网络安全是任何系统管理员必须要考虑的重要方面。在Linux系统中,防火墙是保护系统免受未经授权访问的关键组件。最常见的防火墙工具是iptables,它允许管理员配置各种过滤规则,来控制进出系统的网络流量。
要配置iptables防火墙,管理员需要对规则链有深入的理解,包括INPUT、OUTPUT和FORWARD链。每条规则决定了是否允许数据包通过或者丢弃。例如,以下是一条简单的iptables规则,用于阻止某个特定IP地址的访问:
```bash
sudo iptables -A INPUT -s 192.168.1.100 -j DROP
```
这条命令添加了一条新的规则到INPUT链,使得所有来自IP地址192.168.1.100的数据包被丢弃,从而阻止来自该地址的访问。
除了iptables之外,一些更现代的防火墙工具,如firewalld和UFW(Uncomplicated Firewall),提供了更简单的接口来管理防火墙规则。UFW尤为受到推崇,因为它提供了更简单的命令行界面来管理iptables规则。例如,要启用UFW并设置默认策略阻止所有传入连接,可以使用以下命令:
```bash
sudo ufw enable
sudo ufw default deny incoming
```
通过合理配置这些工具,管理员可以构建出适用于他们特定环境的安全策略。
#### 安全审计和入侵检测
安全审计和入侵检测系统(IDS)是监控和分析系统活动,用以发现潜在的安全威胁和弱点。在Linux中,可利用如Auditd这类工具来对系统进行审计跟踪,监视重要的系统活动,例如文件访问和用户登录。
一个审计规则示例,记录对/etc/shadow文件的任何读取操作:
```bash
auditctl -w /etc/shadow -k shadow_read
```
此命令将配置Auditd记录对/etc/shadow文件的读取访问。一旦配置了审计规则,管理员需要定期审查生成的日志文件以寻找可疑行为的迹象。这有助于及时识别安全事件,并采取适当措施防止未来的攻击。
### 虚拟化与容器技术
#### KVM和虚拟机管理
虚拟化技术允许在单个物理服务器上运行多个虚拟机,为隔离和管理应用提供了灵活性。KVM(Kernel-based Virtual Machine)是Linux内核的一个模块,允许用户在宿主机上创建和运行虚拟机。
使用KVM管理虚拟机的基本流程包括安装kvm模块,创建虚拟磁盘,安装操作系统等。例如,以下步骤展示了如何使用KVM创建一个新的虚拟机:
1. 安装KVM和相关依赖包:
```bash
sudo apt-get install qemu qemu-kvm libvirt-daemon libvirt-clients bridge-utils virt-manager
```
2. 启动libvirtd服务:
```bash
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
```
3. 创建虚拟磁盘并安装操作系统。
创建虚拟磁盘和安装操作系统的具体步骤较为复杂,涉及使用qemu-img工具创建磁盘镜像,以及使用virt-install来安装操作系统。这通常涉及到多个命令行选项,需要管理员仔细配置。
#### Docker容器技术与应用
Docker容器技术与传统的虚拟化相比,提供了更轻量级的资源隔离方式,它允许在单一操作系统内核上运行多个容器,每个容器运行自己的应用进程,但它们共享系统资源。
Docker容器的快速部署和可移植性使得它成为开发和运维团队的首选。Docker镜像的创建、存储和分发由Docker Hub这样的注册中心进行管理。使用Docker进行应用部署的典型流程如下:
1. 从Docker Hub拉取镜像:
```bash
docker pull ubuntu
```
2. 创建并启动容器:
```bash
docker run -it ubuntu bash
```
上面的命令启动了一个基于Ubuntu镜像的容器,并提供了一个交互式shell。
3. 容器中安装软件并进行应用部署。
部署应用到容器中涉及到将必要的文件和配置添加到容器中,然后启动应用进程。Dockerfile是简化这一过程的关键,它包含了创建镜像所需的所有命令。
### 自动化部署与配置管理
#### Ansible自动化工具介绍
自动化部署和配置管理是现代IT管理不可或缺的一部分。Ansible是一个强大的自动化工具,它可以自动化云部署、配置管理、应用程序部署等任务。Ansible的核心是其无代理架构,使用SSH协议与目标主机通信。
使用Ansible的优势包括其简单性、强大的模块生态系统和无需在目标主机上安装额外的代理。管理员可以通过编写YAML格式的playbook来描述所需的应用状态和执行任务。
一个简单的Ansible playbook例子:
```yaml
- name: Setup Web Server
hosts: webservers
become: yes
tasks:
- name: Install apache
apt:
name: apache2
state: latest
```
在这个例子中,playbook定义了一个简单的任务,即安装最新版本的apache2软件包到webservers组中的所有主机。
#### 自动化部署流程与实践案例
实践自动化部署流程可以显著提高工作效率,并减少人为错误。下面是一个自动化部署流程的实例,假设我们要部署一个LAMP(Linux, Apache, MySQL, PHP)栈。
1. 使用Ansible的GALAXY安装预定义的角色和任务,确保所有组件都是最新的。
```bash
ansible-galaxy install geerlingguy.apache
ansible-galaxy install geerlingguy.mysql
ansible-galaxy install geerlingguy.php
```
2. 准备一个包含所有配置的playbook,包括安装和配置服务的步骤。
```yaml
- name: Provision LAMP Stack
hosts: lamp_group
become: yes
roles:
- geerlingguy.apache
- geerlingguy.mysql
- geerlingguy.php
vars:
mysql_root_password: "securepassword"
```
3. 运行playbook来部署整个栈。
```bash
ansible-playbook site.yml
```
一旦playbook运行成功,整个LAMP栈就会在指定的主机组上部署完成。管理员可以进一步通过Ansible添加更多应用层面的自动化,比如部署CMS系统(如WordPress、Drupal等),以及备份策略等。
自动化部署不仅提高了效率,还确保了部署过程的一致性和可重复性,这对于确保多环境(开发、测试、生产)之间的一致性至关重要。
通过采用这些高级系统管理技巧,Linux系统管理员可以显著提高系统的安全性、灵活性和管理效率。然而,这些技巧需要不断的实践和学习,以适应不断变化的IT环境和挑战。
# 5. 深入探索Linux内核与定制
Linux内核是整个操作系统的核心,它负责硬件抽象、内存管理、进程调度等底层操作。随着技术的发展,内核不断加入新的特性以适应新的硬件和软件需求。本章节将带领读者深入探索Linux内核的编译、优化和定制,以及如何利用内核的新特性来提高系统的性能和安全性。
## 5.1 内核编译与模块管理
### 5.1.1 内核版本与编译过程
Linux内核的版本更新非常频繁,开发者需要定期更新内核来获取最新的安全补丁和性能改进。在编译内核之前,首先要决定是使用官方发布版还是从源代码进行编译。
编译内核的过程大致分为以下步骤:
1. 获取内核源码。
2. 配置内核选项。
3. 编译内核和模块。
4. 安装内核与模块。
5. 更新引导加载器配置。
在命令行中,可以通过以下命令来下载并解压最新版本的内核源码:
```bash
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.x.y.tar.xz
tar xvf linux-5.x.y.tar.xz
cd linux-5.x.y
```
接着配置内核选项,根据系统需求选择相应的模块进行编译。推荐使用`make menuconfig`命令,它会提供一个文本界面来帮助用户选择需要的内核特性:
```bash
make menuconfig
```
然后进行内核编译和模块编译:
```bash
make -j$(nproc)
make modules -j$(nproc)
```
之后安装编译好的内核和模块:
```bash
make modules_install
make install
```
最后更新引导加载器配置,如GRUB:
```bash
update-grub
```
### 5.1.2 模块的加载与管理技巧
Linux内核模块(Kernel Modules)允许内核在运行时动态加载和卸载内核功能,这样可以在不影响系统稳定性的前提下,根据需要添加或移除内核功能。
可以使用`lsmod`命令列出当前加载的模块:
```bash
lsmod
```
使用`modinfo`可以查看模块的详细信息:
```bash
modinfo module_name
```
加载模块可以使用`insmod`或`modprobe`命令:
```bash
modprobe module_name
```
移除模块使用`rmmod`命令:
```bash
rmmod module_name
```
此外,`/etc/modprobe.d/`目录下的配置文件可以用来控制模块的加载行为。
## 5.2 系统调优与定制化
### 5.2.1 内核启动参数优化
内核启动参数(Kernel Boot Parameters)可以在启动时传递给内核,用于控制内核的行为和性能。修改这些参数通常在`/etc/default/grub`文件中进行,并且需要运行`update-grub`来应用更改。
一些常见的启动参数包括:
- `quiet`:减少启动时的冗余信息输出。
- `nomodeset`:在某些情况下,阻止内核使用图形模式。
- `intel_pstate=active`:启用Intel的CPU频率调节器。
例如,修改启动参数可以使用以下命令:
```bash
GRUB_CMDLINE_LINUX="intel_pstate=active quiet"
update-grub
```
### 5.2.2 Ubuntu系统的定制化构建
Ubuntu的定制化构建允许用户创建一个适合特定硬件或软件需求的系统版本。这可以通过使用`debootstrap`和`pbuilder`等工具来完成。
`debootstrap`可以用于在一个空的目录中安装基础的Ubuntu系统:
```bash
sudo debootstrap focal ./ubuntu http://archive.ubuntu.com/ubuntu/
```
`pbuilder`则允许在干净的环境中构建包和创建镜像:
```bash
sudo pbuilder create --distribution focal --debootstrapopts "--variant=buildd"
```
定制化构建的详细步骤和参数说明可以参考官方文档和社区提供的指南。
## 5.3 探索Linux内核的新特性
### 5.3.1 最新内核特性概览
随着技术的发展,Linux内核不断加入新的特性以提高效率、安全性以及对新硬件的支持。例如,最新的内核版本可能包含了对新的文件系统、网络协议、安全机制的支持等。
查看最新内核版本的更新日志可以参考内核邮件列表或官方发布的更新说明。
### 5.3.2 实践内核新特性案例分析
为了将理论应用于实践,可以下载最新内核源码并尝试编译,然后在测试环境中部署以评估新特性的表现。这个过程可以帮助开发者理解新特性的优势和可能的使用场景。
例如,如果最新内核版本引入了一个新文件系统,可以在虚拟机或测试机上安装并使用它,然后评估其性能、兼容性和安全性。
通过实际部署和测试,开发者可以学习如何安全有效地利用内核的新特性来优化系统性能和安全性。
在探索Linux内核的新特性时,始终要关注社区的反馈和安全问题。持续学习和实验是深入理解Linux内核的关键。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到Ubuntu命令行工具与实用程序的专栏,这里将为您提供一系列深入的指南,帮助您掌握Ubuntu系统中的命令行。从基础入门到高级用法,我们涵盖了广泛的主题,包括文本处理、系统监控、文件系统管理、备份和恢复、版本升级、日志分析、定时任务调度和系统优化。通过这些文章,您将掌握命令行工具的强大功能,提升您的Ubuntu使用体验,成为一名高效的系统管理员或高级用户。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
模式识别基础揭秘:从理论到应用,全面解读第四版习题!
# 摘要
模式识别作为人工智能领域的重要分支,通过数据预处理、监督学习和无监督学习方法,实现对复杂数据的有效分类与分析。本文首先介绍了模式识别的基础概念与理论框架,随后详述了数据预处理的关键技术,包括数据清洗、标准化、特征提取与选择、数据集划分及交叉验证。接着,深入探讨了监督学习方法,包括传统模型和神经网络技术,并阐述了模型评估与选择的重要性。此外,本文还分析了无监督学习中的聚类算法,并讨论了异常检测与
【Cadence波形故障排除大全】:常见问题快速解决方案及系统性诊断技巧
# 摘要
本文旨在深入探讨Cadence波形故障排除的基础知识和应用技巧。首先介绍波形故障的理论基础与识别方法,包括波形故障的分类和诊断理论。随后,探讨波形故障排除工具和技术的实际应用,强调了故障定位、分析和修复的过程。文章还详细阐述了系统性诊断技巧,包括高级波形分析方法和故障修复预防措施。最后,针对Ca
VFP命令快速参考指南:提升开发效率的秘诀

# 摘要
Visual FoxPro (VFP) 是一个功能强大的数据库管理系统,提供了丰富的命令集以支持数据操作、查询、文件管理和脚本编程。本文全面概述了VFP的基本命令及其深入应用,包括数据的添加、修改、删除,索引排序,SQL查询构建,文件操作和系统信息获取等。同时,探讨了如何利用高级命令进行自动化表单和报表处理,执行复杂的数据库操作
【SQL优化实战】:5个关键技巧助你查询效率翻倍

# 摘要
本文系统地概述了SQL优化的
【KEIL编译优化秘籍】:BLHeil_S项目开发者的终极指南

# 摘要
KEIL编译器是广泛用于嵌入式系统开发的工具,它提供了丰富的优化选项以提高代码性能。本文首先介绍了KEIL编译器的基础知识和优化机制的重要性,随后深入探讨了静态分析、性能剖析以及代码结构、内存管理和算法的优化策略。文章进一步通过BLHeil_S项目开发中的优化实践,说明了如何结合项目特点进行性能瓶颈分析和采取有效的优化步骤。除此之外,本文还探索了高级编译器优化技巧,
数据处理高手:CS3000系统数据采集与管理技巧

# 摘要
CS3000系统是一套综合性的数据处理平台,涵盖了数据采集、管理和存储,以及数据分析和应用等多个方面。本文首先介绍了CS3000系统的概况,随后深入探讨了数据采集的原理与技术,包括基础采集方法和高级实时处理技术,并讨论了数据采集工具的实战应用。接着,文章着重分析了数据管理与存储的策略,强调了数据库的集成使用、数据清洗、预处理、以及高效安全的存储解决方案。在数据安全性与合规性章
【企业级部署文档全攻略】:零基础打造高效可靠的IT部署策略(B-7部署流程深度解析)
# 摘要
本文深入探讨了企业级部署文档的重要性及其构成,强调了在部署前进行充分的准备工作,包括需求评估、环境配置、风险管理和备份策略。核心部署流程的详解突出了自动化技术和实时监控的作用,而部署后的测试与验证则着重于功能、性能、安全性和用户反馈。此外,文章还探讨了持续
【UFS版本2.2 vs 前代】:技术飞跃如何带来性能质变

# 摘要
UFS(通用闪存存储)技术,作为一种高速非易失性内存标准,广泛应用于现代智能设备中。本文首先概述了UFS技术及其版本迭代,重点分析了UFS 2.2的技术革新,包括性能提升的关键技术、新增的命令与功能、架构优化以及对系统性能的影响。接着,通过智能手机、移动计算设备和大数据存储三个实际应用案例,展示了UFS 2.2如何在不同应用场景下提供性能改善。本文进一步探讨了UFS 2.2的配置、性能调优、故障诊断和维护,最后展望
CPCI规范中文版合规性速查手册:掌握关键合规检查点

# 摘要
CPCI(CompactPCI)规范是一种适用于电信和工业控制市场的高性能计算机总线标准。本文首先介绍了CPCI规范的基本概念、合规性的重要性以及核心原则和历史演变。其次,详细阐述了CPCI合规性的主要组成部分,包括硬件、软件兼容性标准和通讯协议标准,并探讨了合规性检查的基础流程。本文还提供了一份CPCI合规性检查实践指南,涵盖了硬件、软件以及通讯和协议合规性检查的具体操作方法。此外,文中综述了目前存在的CPCI合规性检
电池温度安全阈值设置秘籍:如何设定避免灾难性故障

# 摘要
电池温度安全阈值是确保电池系统稳定和安全运行的关键参数。本文综述了电池温度的理论基础,强调了温度阈值设定的科学依据及对安全系数和环境因素的考量。文章详细探讨了温度监测技术的发展,包括传统和智能传感器技术,以及数据采集系统设计和异常检测算法的应用。此外,本文分析了电池管理系统(BMS)在温度控制策略中的作用,介绍了动态调整温度安全阈值
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )