贝叶斯vs频率学派:R语言glm模型的对比分析
发布时间: 2024-11-04 06:31:26 阅读量: 34 订阅数: 22 

基于纯verilogFPGA的双线性差值视频缩放 功能:利用双线性差值算法,pc端HDMI输入视频缩小或放大,然后再通过HDMI输出显示,可以任意缩放 缩放模块仅含有ddr ip,手写了 ram,f

# 1. 统计学派的哲学基础与方法论
## 1.1 统计学派的起源与流派划分
统计学作为一门科学,其研究和应用的领域已经远远超出了原始的计数和分类。现今,统计学的理论基础和方法论可以归结为两大主要学派:贝叶斯统计学派和频率学派。每个学派都有其独特的哲学基础和方法论,影响着数据分析师们对问题的解决方式和对统计结果的解读。
## 1.2 频率学派的哲学基础
频率学派是统计学中最早期的学派之一,它的核心观念是概率被定义为在给定条件下,一个特定事件在长期重复实验中发生的频率。此学派依赖于数据本身,主要关注如何根据观测到的数据集来做出统计推断。
## 1.3 贝叶斯学派的哲学基础
贝叶斯学派则以贝叶斯定理为基础,其核心哲学是概率是表示对某事件信念程度的度量,而非频率。该学派认为先验知识和观测数据相结合,形成后验知识,更加关注对不确定性的量化。
在学习接下来的章节时,我们将深入这两个学派的理论基础和方法论,探讨它们在模型构建、推断实践以及如何在R语言中应用这些理论。
# 2. 贝叶斯统计学派的方法论
### 2.1 贝叶斯定理的理论基础
#### 2.1.1 条件概率与贝叶斯公式
在贝叶斯统计中,条件概率是核心概念之一,其描述了在给定某个事件发生的条件下,另一个事件发生的概率。贝叶斯公式是条件概率的一种表达形式,它提供了一种更新我们对某个假设概率的信念的方法,基于新的证据。
用数学公式表达贝叶斯公式如下:
\[ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} \]
这里,\(P(A|B)\) 表示在事件B发生的条件下,事件A发生的概率;\(P(B|A)\) 表示在事件A发生的条件下,事件B发生的概率;\(P(A)\) 和 \(P(B)\) 分别表示事件A和事件B发生的边缘概率。
贝叶斯定理的实际意义在于,当我们面对不确定性时,可以利用已知信息来推断未知信息。例如,如果我们知道在疾病发生的情况下,检测呈阳性的概率(敏感度),以及未患病时检测呈阳性的概率(假阳性率),我们就可以计算出在检测呈阳性的情况下实际患病的概率。
```python
# 示例代码:使用Python计算条件概率
# 假设
# P(Disease) = 0.01 (疾病的发生概率)
# P(Positive|Disease) = 0.99 (在患病的情况下检测呈阳性的概率)
# P(Positive|NoDisease) = 0.05 (在健康的情况下检测呈阳性的概率)
P_disease = 0.01
P_positive_given_disease = 0.99
P_positive_given_nodisease = 0.05
# 计算检测呈阳性时患病的概率
P_disease_given_positive = (P_positive_given_disease * P_disease) / \
(P_positive_given_disease * P_disease + P_positive_given_nodisease * (1 - P_disease))
print("The probability of disease given a positive test result is:", P_disease_given_positive)
```
执行上述代码将输出在检测呈阳性的情况下实际患病的概率,这可以帮助我们更好地理解条件概率的应用。
#### 2.1.2 先验概率与后验概率的理解
在贝叶斯统计中,先验概率和后验概率是两个关键概念。先验概率(Prior Probability)表示在考虑证据之前,我们对一个假设成立可能性的判断。后验概率(Posterior Probability)则是根据已有的证据更新后的概率,它是在先验概率的基础上结合新的证据信息后得到的概率。
贝叶斯方法的核心是使用贝叶斯公式将先验概率与证据结合,得到后验概率。在统计推断和机器学习等领域,这个过程尤其重要,因为它可以帮助我们从数据中提取出最有价值的信息,并更新我们对模型参数的信念。
在实际应用中,选择合适的先验概率是一个挑战。通常,我们可以根据历史数据、专家经验或者采用无信息先验(如均匀分布或Jeffreys先验)来确定先验概率。
### 2.2 贝叶斯统计中的模型构建
#### 2.2.1 概率分布的选择与应用
在贝叶斯统计中,选择合适的概率分布对于模型构建至关重要。概率分布可以描述数据的概率特性,也可以用于构建模型的先验和后验分布。常见的概率分布包括正态分布、二项分布、泊松分布等。
- **正态分布(Normal Distribution)**:常用于表示连续数据,其具有两个参数,均值(mean)和标准差(standard deviation),可以描述数据的集中趋势和离散程度。
- **二项分布(Binomial Distribution)**:适用于描述固定次数试验中的成功次数,其中每次试验成功概率是固定的。
- **泊松分布(Poisson Distribution)**:用于描述在固定时间或空间内发生某事件的概率,适用于描述稀有事件的发生次数。
选择合适分布类型时,需要考虑数据的特性和研究问题的背景。例如,如果我们要分析顾客购买商品的行为,可能需要使用二项分布;如果我们关注的是一定时间范围内电话呼叫中心接到的呼叫次数,那么泊松分布可能更为适合。
#### 2.2.2 Markov Chain Monte Carlo(MCMC)方法
MCMC方法是一种强大的随机模拟技术,广泛用于贝叶斯统计中后验分布的抽样计算。MCMC方法的基本思想是构造一条马尔可夫链,其平稳分布正是我们感兴趣的后验分布,通过模拟马尔可夫链的长序列来得到后验分布的样本。
MCMC方法的核心优势在于它能够模拟复杂的高维后验分布,这对于传统的解析方法是难以实现的。在实际操作中,常用的MCMC算法有Metropolis-Hastings算法和Gibbs采样。
Metropolis-Hastings算法的基本思想是从一个初始点开始,通过不断进行“提议”和“接受”过程,最终达到平稳分布。Gibbs采样则是基于条件分布进行采样,对于每个参数,都将在给定其他参数条件下的后验分布中进行采样。
### 2.3 贝叶斯推断的实践应用
#### 2.3.1 R语言的贝叶斯推断包介绍
R语言提供了多种贝叶斯推断的包,它们可以帮助统计学家和数据科学家构建复杂的贝叶斯模型。其中,比较著名的有:
- **rstan**:Stan是用于贝叶斯统计推断的一个编程语言和软件包,rstan是其R语言接口。
- **JAGS (Just Another Gibbs Sampler)**:JAGS是一个用于执行贝叶斯数据分析的程序,它使用基于Gibbs抽样的MCMC算法。
- **brms**:一个提供了类似于lme4包的语法,用于构建广义线性模型的R包,它实际上是基于Stan的高级接口。
这些工具包极大地简化了贝叶斯推断模型的实现,并允许用户通过简单的命令执行复杂的统计分析。
#### 2.3.2 实际案例分析:贝叶斯glm模型的应用
贝叶斯广义线性模型(Bayesian Generalized Linear Model,简称贝叶斯glm)是将贝叶斯推断应用于广义线性模型。在实际研究中,贝叶斯glm能够有效地处理数据中的不确定性和复杂性,尤其是在样本量较小或者数据结构复杂的情况下。
作为案例,假设我们有一组医疗数据,记录了患者的多个临床指标以及是否患有某种疾病。我们想要建立一个预测模型,以便根据临床指标预测患者是否患病。
以下是使用rstan包中的Stan语言编写的一个简单贝叶斯glm模型的示例:
```r
# 安装和加载rstan包
# install.packages("rstan")
library(rstan)
# 准备数据
# data <- ...
# Stan代码:构建贝叶斯glm模型
stan_glm_code <- "
data {
int<lower=0> N; // 样本数量
int<lower=0> K; // 预测变量的数量
matrix[N, K] X; // 预测变量的矩阵
int<lower=0, upper=1> y[N]; // 输出变量(0或1)
}
parameters {
vector[K] beta; // 模型参数
}
model {
y ~ bernoulli_logit(X * beta); // 使用逻辑回归
}
"
# 生成数据模型
stan_model <- stan_model(model_code = stan_glm_code)
# 拟合模型
fit <- sampling(stan_model, data = list(N = nrow(data), K = ncol(X), X = X, y = data$y))
# 分析拟合结果
summary(fit)
```
在这个案例中,我们使用了逻辑回归模型来处理二分类问题,并通过Stan实现了贝叶斯推断。代码执行后,我们可以得到参数的后验分布,进而进行预测和进一步的统计分析。
上述案例仅作为贝叶斯glm模型在实际问题中应用的一个简单展示。在实际工作中,数据科学家和统计学家可以根据具体问题调整模型结构,选择合适的先验分布,以及进行详细的模型诊断和评价。
# 3. 频率学派的方法论
在统计学中,频率学派与贝叶斯学派是两种主流的统计推断方法。本章节将深入探讨频率学派的方法论,了解其统计推断、线性模型,以及概率模型实践中的应用。
## 3.1 频率学派的统计推断
### 3.1.1 估计理论与假设检验
在频率学派中,统计推断的核心是对总体参数进行估计以及进行假设检验。估计理论关注如何通过样本数据来估计总体参数,而假设检验则关注对总体参数进行推断的可信度。
- **参数估计**:参数估计分为点估计

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一套全面的 R 语言 glm 数据包使用教程,涵盖从基础到高级的各种主题。它包含 10 个高级技巧,指导您掌握广义线性模型,并提供从基础到高级应用的完整操作手册。专栏深入探讨 glm 参数的奥秘,揭示模型选择最佳实践,并提供案例分析以展示 glm 进阶技巧。此外,它还深入研究逻辑回归、二项分布数据处理、泊松回归、链接函数、残差分析、变量选择和模型优化,以及交叉验证和模型评估。专栏还涵盖了过度离散问题解决、贝叶斯变量选择、时间序列建模、多层次模型和缺失数据处理等高级主题。通过本专栏,您将掌握 glm 数据包的全部功能,并能够构建和分析复杂的统计模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
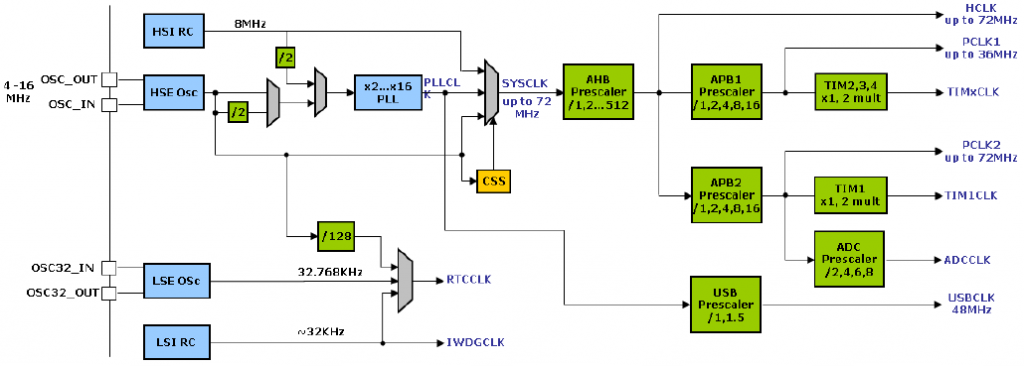
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
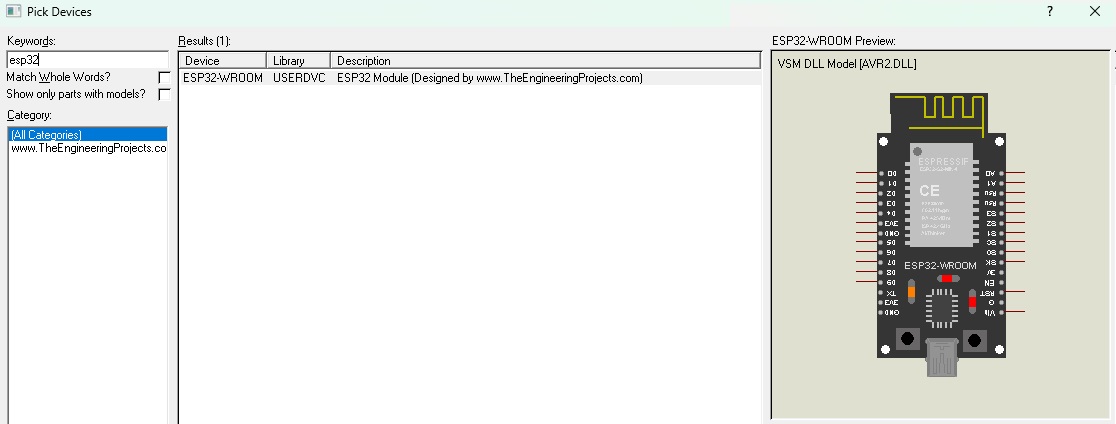
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )