Node.js快速入门:Ubuntu下安装与配置完全指南
发布时间: 2024-12-12 11:48:19 阅读量: 10 订阅数: 5 

The Node.js Little Book 中文版[Node.js 台湾社群协作电子书]1
# 1. Node.js简介与安装基础
Node.js是一种基于Chrome V8引擎的JavaScript运行环境,它让JavaScript能够脱离浏览器,在服务器端运行。与传统的后端语言相比,Node.js最大的优势在于它使用JavaScript作为服务器端编程语言,使前端和后端开发者可以使用同一种语言,减少了团队协作的成本。
## 1.1 Node.js的核心特性
Node.js最核心的特性之一是其事件驱动的非阻塞I/O模型。这种模型非常适合处理成千上万个并发连接,比如实时通信应用和微服务架构。另一个核心特性是其庞大的npm(Node Package Manager)生态系统,提供了数以万计的模块供开发者使用和扩展功能。
## 1.2 安装Node.js
要在您的计算机上安装Node.js,请按照以下步骤操作:
1. 访问[Node.js官网](https://nodejs.org/),下载适合您操作系统的安装包。
2. 安装下载的包。在安装过程中,您可能需要确认是否将Node.js添加到系统的PATH环境变量中,确保在任何位置都能运行Node.js命令。
```bash
node -v
npm -v
```
执行上述命令,如果能显示出Node.js和npm的版本号,则表示Node.js已成功安装在您的系统中。
Node.js安装之后,您就可以开始编写简单的JavaScript代码并运行在服务器端了。在下一章中,我们将详细探讨Node.js环境的配置和项目的基本设置。
# 2. Node.js的环境配置与项目设置
## 2.1 Node.js运行环境的安装
### 2.1.1 下载Node.js安装包
安装Node.js的第一步是获取适当的安装包。Node.js可以从官方网站下载适合你操作系统的安装包。在本小节,我们将主要关注在Windows和Linux操作系统中如何下载和安装Node.js。
对于Windows用户,可以直接从[Node.js官网](https://nodejs.org/en/download/)下载安装程序。对于Linux用户,推荐使用包管理器安装。
### 2.1.2 Ubuntu下的Node.js安装步骤
在Ubuntu操作系统中,Node.js可以通过包管理器`apt`进行安装。下面是安装Node.js的步骤:
1. 首先,更新软件包索引:
```sh
sudo apt update
```
2. 接着,安装Node.js和npm(Node.js的包管理器):
```sh
sudo apt install nodejs npm
```
3. 安装完成后,验证安装是否成功,可以使用以下命令来检查Node.js和npm的版本:
```sh
node -v
npm -v
```
此外,如果你需要在Ubuntu上安装特定版本的Node.js,可以使用`nvm`(Node Version Manager)来进行版本管理,我们将在下一小节详细介绍。
## 2.2 Node.js版本管理工具
### 2.2.1 nvm安装与使用
`nvm`是一个流行的Node.js版本管理工具,它允许你在同一台机器上安装和使用不同版本的Node.js。在Linux和Mac OS上使用nvm是一种常见的做法,因为它提供了安装和切换Node.js版本的灵活性。
1. 安装nvm,首先获取安装脚本并执行:
```sh
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
```
2. 重新加载你的shell配置文件(通常是`.bashrc`或`.zshrc`):
```sh
source ~/.bashrc
```
3. 使用nvm安装特定版本的Node.js:
```sh
nvm install v16.13.0
```
4. 切换到已安装的Node.js版本:
```sh
nvm use v16.13.0
```
### 2.2.2 nvm管理Node.js版本
使用`nvm`可以轻松地切换Node.js版本。以下是切换Node.js版本的步骤:
1. 列出所有可用的Node.js版本:
```sh
nvm list-remote
```
2. 安装一个特定版本的Node.js:
```sh
nvm install 14
```
3. 使用特定版本的Node.js:
```sh
nvm use 14
```
4. 如果想将某个版本设置为默认版本,可以这样做:
```sh
nvm alias default 14
```
`nvm`非常适合开发人员,因为它们通常需要测试代码在不同版本的Node.js中的兼容性。通过nvm,可以快速切换到任何需要的Node.js版本,而无需卸载或重新安装。
## 2.3 常用的Node.js开发工具
### 2.3.1 Node.js包管理器npm
npm是Node.js的官方包管理器,它极大地简化了Node.js项目的依赖管理和包的安装。使用npm,你可以:
- 初始化新项目:`npm init`
- 安装包:`npm install <package-name>`
- 更新包:`npm update <package-name>`
- 卸载包:`npm uninstall <package-name>`
npm还支持编写`package.json`文件来描述项目的依赖项和配置信息。它是Node.js开发过程中不可或缺的工具。
### 2.3.2 代码编辑器与集成开发环境IDE选择
选择适合的代码编辑器或集成开发环境(IDE)对于开发效率至关重要。对于Node.js开发,以下是一些流行的选择:
- **Visual Studio Code**(VS Code):VS Code是一款免费、开源、功能强大的代码编辑器,由微软开发,内置了对Node.js的支持。
- **WebStorm**:WebStorm是IntelliJ IDEA的Web开发版,支持Node.js,适合前端和后端混合开发。
- **Atom**:由GitHub开发的免费开源文本编辑器,插件众多,社区支持良好。
在选择IDE时,应考虑编辑器的易用性、扩展性、代码提示、调试工具以及与Node.js的集成度等因素。
总结而言,在本章节中,我们深入探讨了Node.js环境配置与项目设置的各个方面。我们介绍了如何在不同操作系统中安装Node.js运行环境,阐述了使用nvm进行Node.js版本管理的细节,以及讨论了选择合适的代码编辑器和IDE的建议。这些基础知识点对于构建和维护Node.js应用是至关重要的。在下一章节中,我们将进一步深入了解Node.js的核心概念和基础。
# 3. Node.js基础与核心概念
Node.js自2009年发布以来,因其独特的事件驱动架构和非阻塞I/O操作而在Web开发中获得了广泛应用。本章节将深入探讨Node.js的核心概念,包括其事件驱动架构、模块系统以及异步I/O操作。
## 3.1 Node.js的事件驱动架构
Node.js的事件驱动架构是其区别于传统同步I/O模型的关键特性之一。它利用了JavaScript的单线程特性,通过事件循环机制实现了高效的并发处理。
### 3.1.1 事件循环机制详解
事件循环机制是Node.js处理异步事件的核心。Node.js将任务分为同步任务和异步任务。同步任务直接进入主线程执行,异步任务则由异步I/O处理机制处理。
```javascript
console.log('start');
setTimeout(() => {
console.log('timeout');
}, 0);
console.log('end');
```
在上述代码中,我们首先看到的是同步输出 "start" 和 "end"。紧随其后的 `setTimeout` 是一个异步操作,其回调函数将在事件循环的下一次迭代中执行,因此输出 "timeout" 会在 "end" 之后出现。
Node.js的事件循环有六个阶段:
1. timers:执行 `setTimeout` 和 `setInterval` 的回调。
2. I/O callbacks:执行某些系统操作错误的回调。
3. idle, prepare:仅在内部使用。
4. poll:获取新的I/O事件,执行与I/O相关的回调。
5. check:执行 `setImmediate()` 的回调。
6. close callbacks:执行 `socket.on('close', ...)` 等。
### 3.1.2 异步编程的最佳实践
异步编程中,Callback是最传统的实现方式,但存在多个Callback嵌套时的“回调地狱”问题。Node.js中引入了Promises和async/await来解决这个问题。
```javascript
const fs = require('fs');
// 使用Promise
fs.readFile('/path/to/file', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
// 使用async/await
const { promisify } = require('util');
const readFileAsync = promisify(fs.readFile);
async function readFile() {
try {
const data = await readFileAsync('/path/to/file', 'utf8');
console.log(data);
} catch (err) {
console.error(err);
}
}
readFile();
```
在上述代码中,`promisify` 将带有回调的函数转换为返回Promise的函数。使用`async/await`,我们可以写出更直观、更易于理解的异步代码。
## 3.2 Node.js模块系统
模块系统是Node.js项目组织代码和复用代码的重要手段。Node.js使用CommonJS模块规范,它要求每个文件都是一个模块。
### 3.2.1 CommonJS模块规范
CommonJS规范定义了模块的引入和导出方式。使用 `require` 关键字引入模块,使用 `module.exports` 或 `exports` 导出模块。
```javascript
// fileA.js
module.exports = function() {
console.log('Hello World!');
};
// fileB.js
const hello = require('./fileA');
hello(); // 输出 "Hello World!"
```
在`fileA.js`中,我们将一个函数导出,并在`fileB.js`中通过`require`引入该模块并执行导出的函数。
### 3.2.2 创建和使用自定义模块
自定义模块可以是JavaScript文件,也可以是JSON文件。Node.js内置了对JSON文件的支持。
```javascript
// user.js
module.exports = {
name: 'Alice',
age: 25
};
// main.js
const user = require('./user');
console.log(user.name); // 输出 "Alice"
```
上述代码中,`user.js`文件导出一个包含用户信息的对象。在`main.js`文件中,通过`require`引入`user.js`,然后访问其`name`属性。
Node.js还支持创建模块目录,目录内需要包含`package.json`文件,并在该文件中指定主模块入口。
## 3.3 Node.js的异步I/O操作
Node.js中,异步I/O操作是通过回调函数来实现的。这是Node.js处理文件系统操作、网络请求等I/O密集型操作的关键。
### 3.3.1 Callbacks使用和问题
Node.js原生API广泛使用回调函数来处理异步操作。虽然这种方式可以实现异步编程,但当回调嵌套多层时,代码可读性和可维护性会大大降低。
```javascript
fs.readFile('/path/to/file', 'utf8', (err, data) => {
if (err) {
// 处理文件读取错误
} else {
fs.writeFile('/path/to/file2', data, (err) => {
if (err) {
// 处理文件写入错误
} else {
// 处理文件写入成功
}
});
}
});
```
在上述代码中,可以看到多个回调嵌套,这就是所谓的“回调地狱”。
### 3.3.2 Promises和async/await新特性
为了避免“回调地狱”,Promise被引入作为异步操作的解决方案,而async/await进一步简化了异步代码的写法。
```javascript
const fs = require('fs').promises;
async function readFileAndWrite() {
try {
const data = await fs.readFile('/path/to/file', 'utf8');
await fs.writeFile('/path/to/file2', data);
console.log('File has been copied');
} catch (err) {
console.error(err);
}
}
readFileAndWrite();
```
这段代码使用async/await将异步操作写得和同步操作一样清晰。这样不仅提高了代码的可读性,也更方便错误处理。
接下来的章节将继续深入讨论Node.js在实际项目中的应用,包括如何搭建Node.js服务器、数据库集成与操作以及前后端分离项目的实践。我们将探索Node.js在这些领域的强大功能和实践中的最佳策略。
# 4. Node.js实战项目开发
## 4.1 搭建Node.js服务器
### 4.1.1 Express框架简介与安装
Express是一个灵活的Node.js Web应用框架,提供了一系列强大特性来开发Web和移动应用。它简化了路由、中间件、模板引擎和静态文件服务的配置。通过快速设置一个基本服务器,Express使开发者可以集中精力开发业务逻辑。
安装Express的第一步是初始化项目和安装所需的依赖。首先,通过npm初始化一个新的Node.js项目:
```bash
mkdir node-server
cd node-server
npm init -y
```
这将创建一个`package.json`文件并填充默认值。接下来,安装Express:
```bash
npm install express --save
```
安装完成后,创建一个`index.js`文件,这是主服务器文件。下面是一个基础的Express服务器代码示例:
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.listen(port, () => {
console.log(`Server listening at http://localhost:${port}`);
});
```
在上述代码中,我们首先引入了Express模块,然后创建了一个应用实例。定义了一个路由处理器`app.get('/')`,当访问根URL时,返回`Hello World!`字符串。最后,通过`app.listen()`指定服务器监听端口。
### 4.1.2 基本的RESTful API开发
RESTful API是现代Web服务架构的一种实践标准,它允许客户端和服务端之间以一种简单、可读的方式来交换数据。每个资源都通过一个URL来表示,并且可以使用HTTP方法(如GET、POST、PUT和DELETE)来对资源进行操作。
以下是使用Express创建一个简单的RESTful API示例,其中包括获取用户列表和添加新用户的两个接口:
```javascript
const express = require('express');
const app = express();
const port = 3000;
// 用于解析JSON格式的请求体
app.use(express.json());
// 获取用户列表接口
app.get('/users', (req, res) => {
// 假设这是数据库中的用户数据
const users = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' }
];
res.json(users);
});
// 添加新用户接口
app.post('/users', (req, res) => {
// 获取请求体中的数据
const { name } = req.body;
const newUser = { id: Date.now(), name }; // 简单的ID分配逻辑
// 假设这是数据库操作,这里仅为示例
// database.push(newUser);
res.status(201).json(newUser);
});
app.listen(port, () => {
console.log(`Server listening at http://localhost:${port}`);
});
```
在这个例子中,我们使用了Express的中间件`express.json()`来解析JSON格式的请求体。`app.get('/users')`处理GET请求,用于获取用户列表。`app.post('/users')`处理POST请求,用于添加新用户。
通过这些基础的步骤,你可以快速搭建一个Node.js服务器并开始开发RESTful API。在实际开发中,你还需要考虑到错误处理、数据验证、安全性、性能优化等多方面的因素。
## 4.2 数据库集成与操作
### 4.2.1 MongoDB的Node.js驱动安装与配置
MongoDB是一个面向文档的NoSQL数据库,它支持高性能、高可用性和易扩展的数据存储。在Node.js应用中,通常使用MongoDB数据库来处理大量的非关系型数据。
为了在Node.js中使用MongoDB,首先需要安装MongoDB的Node.js驱动程序`mongodb`。可以使用npm进行安装:
```bash
npm install mongodb --save
```
安装完成后,你可以通过引入`mongodb`模块来连接和操作MongoDB数据库。以下是一个简单的例子,演示了如何连接到MongoDB数据库,并执行一些基础的数据库操作:
```javascript
const { MongoClient } = require('mongodb');
const url = 'mongodb://localhost:27017'; // MongoDB的默认连接字符串
const dbName = 'mydatabase'; // 数据库名称
// 创建MongoClient实例
const client = new MongoClient(url);
// 连接到MongoDB服务器
async function run() {
try {
await client.connect();
console.log('Connected to the MongoDB server');
// 获取数据库
const db = client.db(dbName);
// 获取集合(表)
const collection = db.collection('users');
// 插入一个文档(记录)
await collection.insertOne({ name: 'Charlie', age: 30 });
// 查询所有文档
const result = await collection.find({}).toArray();
console.log('All users:', result);
} finally {
// 断开MongoDB服务器的连接
await client.close();
}
}
run().catch(console.dir);
```
### 4.2.2 实现CRUD数据库操作
CRUD操作是创建(Create)、读取(Read)、更新(Update)和删除(Delete)的简称,这是数据库操作的基础。
在Node.js中使用MongoDB客户端,可以实现以下CRUD操作:
- 创建(Create):
使用`insertOne()`方法可以向集合中插入一个文档。
```javascript
await collection.insertOne({ name: 'Delta', age: 25 });
```
- 读取(Read):
使用`find()`方法可以查询集合中的文档。使用`findOne()`方法可以查询第一个符合条件的文档。
```javascript
// 获取第一个匹配的用户
const firstUser = await collection.findOne({ name: 'Charlie' });
```
- 更新(Update):
使用`updateOne()`或`updateMany()`方法可以更新集合中的文档。
```javascript
// 更新Charlie的信息,增加一个字段
await collection.updateOne({ name: 'Charlie' }, { $set: { email: 'charlie@example.com' } });
```
- 删除(Delete):
使用`deleteOne()`或`deleteMany()`方法可以删除集合中的文档。
```javascript
// 删除Charlie的记录
await collection.deleteOne({ name: 'Charlie' });
```
实现CRUD操作,你可以灵活地对数据库中的数据进行管理。在实际开发中,还需要考虑如何处理异步操作中可能出现的错误、如何优化查询效率、如何保护数据的安全等。
## 4.3 前后端分离项目实践
### 4.3.1 SPA项目的搭建与配置
单页应用(Single Page Application,SPA)是一种网络应用或网站,它能够在加载初始页面后动态更新其内容,无需重新加载整个页面。这种架构提升了用户体验,使应用响应速度更快。
搭建一个SPA项目通常使用前端框架,如React、Vue.js或Angular。以下是使用Vue.js创建SPA项目的基本步骤:
```bash
npm install -g @vue/cli
vue create my-spa-project
cd my-spa-project
npm run serve
```
上述命令创建了一个新的Vue.js项目,并启动了一个开发服务器。在实际的开发过程中,你需要创建组件、编写路由逻辑(Vue Router)、状态管理(Vuex)以及其他前端资源的配置。
### 4.3.2 API接口与前端的数据交互
前后端分离的架构中,前端应用通过API接口与后端服务进行数据交互。Node.js开发的后端服务可以使用Express框架提供的路由中间件来处理前端请求。
当客户端需要从服务器获取数据时,通常会发出GET请求。例如,从我们的Node.js服务器获取用户列表:
```javascript
// 前端请求示例
fetch('http://localhost:3000/users')
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
```
服务器端定义了一个路由来响应这些请求:
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.use(express.json());
// 模拟数据库中的用户数据
let users = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' }
];
// 获取用户列表接口
app.get('/users', (req, res) => {
res.json(users);
});
// 添加新用户接口(省略具体实现)
app.listen(port, () => {
console.log(`Server listening at http://localhost:${port}`);
});
```
在这种配置下,前端应用通过API接口从Node.js服务器中获取或发送数据。在实际应用中,前端会通过Axios等HTTP客户端库来处理请求,与后端进行数据交互。
至此,我们已经介绍了如何使用Node.js搭建服务器、如何集成MongoDB数据库进行CRUD操作,以及如何与前端应用交互数据。Node.js在这些领域的实践为我们提供了灵活的工具来构建高效能的应用程序。在下一章,我们将探索如何进一步优化Node.js应用的性能,以及如何使用中间件和其他高级功能来提升开发效率。
# 5. Node.js进阶与性能优化
Node.js以其事件驱动、非阻塞I/O模型被广泛应用于构建高性能、可扩展的网络应用。本章将深入探讨Node.js的中间件和中间件模式、如何构建高性能的Node.js应用,以及项目调试与监控的最佳实践。
## 5.1 Node.js的中间件和中间件模式
### 5.1.1 中间件的创建和应用
中间件是Node.js应用中一种非常重要的设计模式,它可以在请求和响应之间执行一些通用的处理逻辑。在Express框架中,中间件就像是在一个水管中流动的水,可以用来执行各种任务,如日志记录、身份验证、请求体解析等。
创建一个简单的中间件函数,可以使用如下代码:
```javascript
function logger(req, res, next) {
console.log('Request received at ' + Date.now());
next();
}
app.use(logger);
```
这段代码定义了一个日志记录中间件`logger`,它使用`next()`函数来调用下一个中间件。通过`app.use(logger)`将其应用到所有请求上。
### 5.1.2 中间件在实际项目中的优化策略
中间件可以大幅度简化应用的代码逻辑,提高代码的复用性。在实际项目中,可以采用如下策略来优化中间件的使用:
- **链式中间件**:通过串联多个中间件,可以实现更复杂的请求处理逻辑。
- **局部中间件**:在Express中,中间件也可以绑定到特定的路由或路由组上,以减少对其他请求的影响。
- **第三方中间件**:利用社区贡献的中间件库,如`body-parser`或`compression`等,可以进一步简化应用开发。
## 5.2 高性能Node.js应用构建
### 5.2.1 Node.js的集群模式
Node.js的单线程特性意味着一旦主线程出现错误,整个进程就会崩溃。为了解决这一问题,Node.js引入了集群模式来创建多个子进程,它们共享服务器端口,从而提高应用的可靠性和性能。
实现集群模式的代码示例如下:
```javascript
const cluster = require('cluster');
const numCPUs = require('os').cpus().length;
const express = require('express');
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
const app = express();
app.get('/', (req, res) => {
res.send('hello world\n');
});
app.listen(8080);
console.log(`Worker ${process.pid} started`);
}
```
### 5.2.2 使用cluster模块提高性能
`cluster`模块提供了一个简单的接口,使我们能够轻松创建子进程,以实现负载均衡。在上述代码中,我们创建了一个主进程和多个工作进程。主进程负责创建工作进程,并监听退出事件,而每个工作进程则负责处理请求。
通过这种方式,我们能够利用多核CPU的优势,提高应用的吞吐量,因为每个核可以处理多个请求,从而优化整体性能。
## 5.3 Node.js项目的调试与监控
### 5.3.1 使用Node.js内置调试工具
Node.js内置了调试工具,可以帮助开发者快速定位问题。通过在启动Node.js应用时加入`--inspect`参数,可以启用调试功能。
例如,启动一个调试模式的应用:
```bash
node --inspect app.js
```
然后在Chrome浏览器中访问`chrome://inspect`,就可以看到Node.js应用的调试界面。你可以设置断点、查看调用栈、检查变量值等。
### 5.3.2 应用监控与日志记录技巧
应用监控和日志记录对于持续运行的Node.js应用至关重要。它们可以帮助开发者了解应用的行为,迅速定位问题,并进行性能分析。
使用`console.log`是一种简单的日志记录方式,但它并不适合生产环境。生产环境应使用成熟的日志库,如`winston`或`morgan`。这些库提供了更强大的功能,比如日志级别控制、格式化输出、日志转存到文件或外部服务等。
例如,使用`winston`进行日志记录的基本配置如下:
```javascript
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp({
format: 'YYYY-MM-DD HH:mm:ss'
}),
winston.format.json()
),
defaultMeta: { service: 'your-service-name' },
transports: [
new winston.transports.File({ filename: 'error.log', level: 'error' }),
new winston.transports.File({ filename: 'combined.log' })
]
});
logger.info('Info message');
logger.error('Error message');
```
本章详细介绍了Node.js中间件的创建和优化策略、如何构建高性能应用以及如何进行调试和监控。掌握这些进阶知识,将使你能够构建更可靠、更高效的Node.js应用。在下一章,我们将深入了解前端技术栈与Node.js的整合,探索前后端分离的开发模式。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏聚焦于 Ubuntu 操作系统上编程语言的支持与安装。它提供了详细的教程,指导用户如何在 Ubuntu 中安装和配置 Ruby on Rails、Node.js 和 React 等流行编程语言。这些教程涵盖了从环境搭建到项目初始化的各个步骤,旨在帮助初学者快速上手这些技术。通过遵循本专栏中的指南,用户可以轻松地在 Ubuntu 中创建和运行基于这些编程语言的应用程序,从而为他们的软件开发之旅奠定坚实的基础。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【2023年版】:计算机体系结构与数字设计第二版奇数题答案大全,速学攻略!

参考资源链接:[《数字设计与计算机体系结构》第二版奇数题解](https://wenku.csdn.net/doc/7pb45zfk82?spm=1055.2635.3001.10343)
# 1. 计算机体系结构与数字设计基础
随着数字化转型的加速,计算机体系结构和数字设计在IT行业的重要性日益凸显。本章旨在为读者提供计算机体系结构与数字设计的入门知识,为后续章节打下坚实的基础。
## 1.1 计算机体系结构概述
计算
【ABAQUS热分析速成】:温度场模拟与结果解读技巧
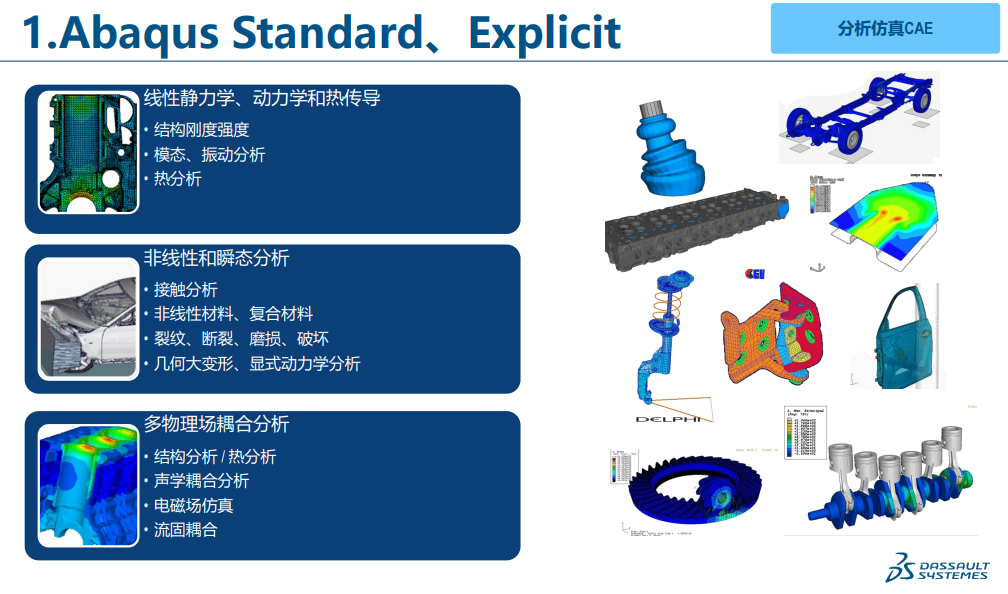
参考资源链接:[ABAQUS 2016分析用户手册:卷II](https://wenku.csdn.net/doc/6412b701be7fbd1778d48c01?spm=1055.2635.3001.10343)
# 1. ABAQUS热分析概述
## 热分析的重要性与应用范围
在工程设计和研究中,热分析是评估材料性能和结构响应在温度变化下的重要工具。ABAQUS作为一款功能强大的有限元分析软件,其热分析
【Yamaha RX-V340家庭影院终极指南】:13个技巧助你打造私人影院!

参考资源链接:[雅马哈RX-V340/430 AV接收机用户手册:连接与高级设置指南](https://wenku.csdn.net/doc/k1bkj6g8x8?spm=1055.2635.3001.10343)
# 1. Yamaha RX-V340家庭影院概览
## 1.1 设备简介
Yamaha RX-V340作为一款功能强大的家庭
CRSF数据包格式解析:精通CRSF,从入门到专家的进阶指南

参考资源链接:[CRSF协议:低延迟高更新率的RC信号与双向通信技术](https://wenku.csdn.net/doc/
图书馆电子资源使用全攻略:7大操作技巧深度解析

参考资源链接:[全国图书馆参考咨询联盟PDF获取指南](https://wenku.csdn.net/doc/6401ad33cce7214c316eea91?spm=1055.2635.3001.10343)
# 1. 图书馆电子资源概述
随着信息技术的飞速发展,图书馆的资源形式已不再局限于
【新手也能玩转MT7981B】:芯片操作快速入门与高级应用教程
参考资源链接:[MT7981B芯片规格书Datasheet详细说明](https://wenku.csdn.net/doc/12ihmq7i4x?spm=1055.2635.3001.10343)
# 1. MT7981B芯片概述
## 1.1 MT7981B芯片简介
MT7981B芯片是一款由知名半导体公司设计并生产的多功能处理器,专为高性能和高效率而优化。该芯片集成了多种高级功能,如先进的图像处理能力、快速的数据传输速度和丰富的外围接口,使得其在消费电子、工业控制和智能设备等领域有广泛应用。
## 1.2 MT7981B芯片的应用领域和市场前景
MT7981B芯片凭借其低功耗和高集成度
远程支持新境界:DameWare远程控制技巧的终极指南

参考资源链接:[DameWare Mini Remote Control 使用教程:远程管理Windows服务器](https://wenku.csdn.net/doc/4ti1g19ipp?spm=1055.2635.3001.10343)
# 1. DameWare远程控制概述
## 1.1 什么是DameWare远程控制
DameWare远程控制是一种允许I
【MATLAB风荷载模拟】:结构设计与安全性评估的3个扩展应用
参考资源链接:[MATLAB实现Davenport风荷载模拟:高精度单点风速仿真](https://wenku.csdn.net/doc/6me4h10wqt?spm=1055.2635.3001.10343)
# 1. MATLAB在风荷载模拟中的基础应用
风荷载模拟是结构工程中不可或缺的一部分,它涉及分析风力对建筑物、桥梁以及其他结构物的影响。MATLAB,作为一种强大的数学计算和模拟
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )