JSTL的循环标签
发布时间: 2023-12-16 07:22:17 阅读量: 71 订阅数: 49 

JSTL标签
# 第一章:JSTL概述
## 1.1 JSTL简介
JSTL(JavaServer Pages Standard Tag Library)是一组以标签为基础的库,用于简化在JSP页面中编写Java代码的操作。它提供了一组简单易用的标签,用于处理常见的任务,如循环、条件判断、字符串操作等。JSTL是通过标签库的方式实现的,可以直接在JSP页面中使用这些标签,无需编写任何Java代码。
## 1.2 JSTL的作用及优势
JSTL的主要作用是简化JSP页面的开发,使开发者能够更专注于页面的展示逻辑,而不需要过多关注底层的Java代码。通过使用JSTL,开发者可以将一些常见的、重复性的代码抽象成标签,提高开发效率,减少代码重复。同时,JSTL还提供了一些高级的标签,用于处理集合、字符串等数据类型,增加了JSP页面的灵活性和功能性。
## 1.3 JSTL循环标签的作用
JSTL中的循环标签主要用于对集合、数组等数据进行迭代循环,将数据逐个取出并进行处理。循环标签可以简化对数据的遍历操作,省去了传统的Java循环代码的编写过程,提高了代码的简洁性和可读性。常见的JSTL循环标签包括`forEach`、`foreach`、`forTokens`等。
## 第二章:JSTL循环标签介绍
JSTL提供了多种循环标签,可以方便地在JSP页面中进行数据的遍历和操作。以下是常用的JSTL循环标签:
### 2.1 foreach标签
`foreach`标签用于对集合或数组进行遍历,它会迭代集合中的每个元素,并将当前元素赋值给指定的变量。可以使用 `var`属性指定变量名,用于在循环体内操作当前元素。
```java
<c:forEach items="${collection}" var="item">
<!-- 循环体内容 -->
</c:forEach>
```
### 2.2 forTokens标签
`forTokens`标签用于将字符串按指定的分隔符进行分割,并将分割的结果依次赋值给指定的变量。可使用 `var`属性指定变量名,`delims`属性指定分隔符。
```java
<c:forTokens items="${string}" delims="," var="token">
<!-- 循环体内容 -->
</c:forTokens>
```
### 2.3 forEach标签
`forEach`标签用于对指定范围内的数字进行迭代。可以指定起始值、结束值和步长,循环会依次迭代这个范围内的值,并将当前值赋值给指定的变量。可使用 `begin`、`end`、`step`和 `var`属性指定相应的值。
```java
<c:forEach begin="1" end="10" step="2" var="i">
<!-- 循环体内容 -->
</c:forEach>
```
### 2.4 其他循环标签的介绍
除了上述介绍的循环标签外,JSTL还提供了其他一些循环标签,如:
- `<c:forTokens>`:用于将字符串按指定的分隔符进行分割。
- `<c:import>`:用于导入外部JSP页面,并在循环中进行引用。
这些标签提供了更灵活的循环方式,可以根据具体需求选择合适的标签进行使用。
### 第三章:使用JSTL循环标签
在本章中,我们将介绍如何在JSP页面中引入JSTL库,并利用JSTL循环标签实现数据的循环展示。我们将重点介绍foreach标签和forTokens标签的具体用法,同时给出在JSP页面中的应用实例。
#### 3.1 如何在JSP页面中引入JSTL库
要在JSP页面中使用JSTL,首先需要在页面的头部引入JSTL的核心标签库。通过以下代码引入JSTL库:
```html
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
```
引入之后,我们就可以在JSP页面中使用JSTL的各种标签了。
#### 3.2 使用foreach标签进行循环
foreach标签是JSTL中最常用的循环标签之一。它可以对集合、数组、Map等数据进行迭代,将其中的元素逐个取出并在页面上进行展示。以下是一个使用foreach标签的简单示例:
```jsp
<c:forEach var="item" items="${items}">
${item}<br/>
</c:forEach>
```
在上面的例子中,我们通过`<c:forEach>`标签对名为items的集合进行了迭代,并将每个元素的值显示在页面上。其中,var属性指定了迭代时的临时变量名,items属性指定了要进行迭代的集合。
#### 3.3 使用forTokens标签进行字符串分割
forTokens标签可以将一个字符串按指定的分隔符进行分割,并对分割后的各部分进行遍历。下面是一个使用forTokens标签的示例:
```jsp
<c:forTokens items="apple,banana,orange" delims="," var="fruit">
${fruit}<br/>
</c:forTokens>
```
在上面的例子中,我们使用逗号作为分隔符,将字符串"apple,banana,orange"分割成三部分,并分别将它们显示在页面上。
#### 3.4 在JSP页面中的应用实例
现在让我们来看一个实际的应用场景。假设我们有一个名为students的学生列表,每个学生对象包含id和name两个属性。我们希望在JSP页面上展示所有学生的姓名,可以这样实现:
```jsp
<c:forEach var="student" items="${students}">
${student.name}<br/>
</c:forEach>
```
# 第四章:JSTL循环标签的高级应用
在上一章节中,我们介绍了JSTL的循环标签的基本用法。本章将进一步探讨JSTL循环标签的高级应用,包括嵌套循环、条件判断、处理集合和数组等。
## 4.1 嵌套循环
JSTL循环标签允许嵌套循环,即在循环体内部再次使用循环标签。这样可以方便地处理多重嵌套的数据结构,如二维数组、多层嵌套的集合等。
示例代码:
```java
<c:forEach items="${outerList}" var="outer">
<c:forEach items="${outer}" var="inner">
${inner}
</c:forEach>
</c:forEach>
```
在上述代码中,`${outerList}`是一个包含多个列表的列表,外层循环遍历每个列表,内层循环遍历列表中的每个元素。`${inner}`表示内层循环中的当前元素。
## 4.2 循环中的条件判断
JSTL循环标签中可以使用`begin`、`end`和`step`属性来指定循环的开始值、结束值和步长。通过配合条件判断,可以根据不同的条件来控制循环的执行。
示例代码:
```java
<c:forEach begin="1" end="10" var="i" step="2">
<%-- 只输出奇数 --%>
<c:if test="${i % 2 != 0}">
${i}
</c:if>
</c:forEach>
```
在上述代码中,循环从1到10,步长为2。通过条件判断`${i % 2 != 0}`,只有在`i`为奇数时才输出。`${i}`表示当前循环中的计数器值。
## 4.3 处理集合和数组
JSTL循环标签可以方便地处理集合和数组。通过`items`属性,可以指定要遍历的集合或数组。
示例代码:
```java
<c:forEach items="${myList}" var="item">
${item}
</c:forEach>
```
在上述代码中,`${myList}`是一个集合,循环遍历集合中的每个元素,并输出。`${item}`表示当前循环中的元素。
## 4.4 其他高级应用示例
除了嵌套循环、条件判断和处理集合、数组外,JSTL循环标签还可以用于实现一些高级功能,如分页列表、树形结构的遍历等。根据不同的需求,可以灵活运用JSTL循环标签来实现各种复杂的循环操作。
示例代码:
```java
<c:forEach items="${userList}" var="user">
<tr>
<td>${user.username}</td>
<td>${user.email}</td>
<td>${user.age}</td>
</tr>
</c:forEach>
```
在上述代码中,`${userList}`是一个包含用户信息的集合,循环遍历集合中的每个用户,并输出其用户名、邮箱和年龄。
本章介绍了JSTL循环标签的高级应用,包括嵌套循环、条件判断、处理集合和数组等。通过灵活使用这些高级应用,我们可以更加方便地处理各种复杂的循环操作。在下一章节中,我们将介绍JSTL循环标签的注意事项与常见问题。
请继续阅读第五章的内容。
### 5. 第五章:JSTL循环标签的注意事项与常见问题
在使用JSTL循环标签时,有一些注意事项和常见问题需要我们特别关注和解决。本章将围绕这些内容展开讨论。
#### 5.1 JSTL常见错误
在使用JSTL循环标签时,可能会遇到一些常见的错误,比如标签未正确引入、循环嵌套错误、循环条件设置不当等。针对这些问题,我们需要了解常见错误的原因,并学会如何排查和解决这些错误。
#### 5.2 循环标签的性能注意事项
虽然JSTL提供了便利的循环标签,但在实际应用中我们也需要关注性能方面的问题。循环标签的性能优化是很重要的,特别是在处理大数据量的情况下。本节将介绍一些提升循环标签性能的注意事项和技巧。
#### 5.3 与Java循环语句的比较
除了使用JSTL循环标签,我们也可以使用Java中的循环语句来实现相同的功能。本节将比较JSTL循环标签与Java循环语句的异同,帮助读者更好地选择合适的循环方式。
#### 5.4 常见问题的解决方法
最后,我们将总结一些在使用JSTL循环标签时常见的问题,并提供相应的解决方法。这些问题可能涉及到循环输出顺序、循环结束条件、循环内部变量的作用域等方面,我们将一一进行讨论和解答。
第六章:JSTL扩展标签库中的循环标签
## 6.1 自定义循环标签
在前面的章节中,我们已经学习了JSTL内置的循环标签,但是有时候我们还需要更多的功能或者更灵活的循环方式。JSTL提供了扩展标签库的功能,允许开发者自定义循环标签来满足自己的需求。
## 6.2 扩展标签库的使用方法
要使用JSTL扩展标签库,我们需要下载对应的jar包,并将其放置在WEB-INF/lib目录下。然后在JSP页面中引入扩展标签库的命名空间,就可以使用自定义的循环标签了。
```jsp
<%@ taglib prefix="my" uri="http://example.com/mytags"%>
```
在上面的代码中,`prefix`是指定标签的前缀名称,`uri`是指定标签库的唯一标识符。
## 6.3 扩展标签库中的常用循环标签介绍
扩展标签库中的循环标签有很多种,下面介绍几个常用的:
- **my:foreach**:与JSTL中的foreach标签类似,用于遍历集合或数组。
- **my:while**:类似于Java语言中的while循环,根据条件反复执行某一段代码。
- **my:doWhile**:类似于Java语言中的do-while循环,先执行一次代码,再判断条件是否满足。
下面是一个使用自定义循环标签的示例:
```jsp
<my:foreach items="${users}" var="user">
<p>${user.name}</p>
</my:foreach>
```
在上面的代码中,我们使用了自定义的foreach标签遍历了一个名为`users`的集合,然后输出每个用户的姓名。
## 6.4 自定义循环标签的开发方法
要开发自定义的循环标签,我们需要创建一个Java类,实现循环标签接口,并重写相应的方法。然后将该类打包成jar包,并放置在WEB-INF/lib目录下即可使用。
以下是一个简单的自定义循环标签的代码示例:
```java
package com.example.mytags;
import java.util.Collection;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.BodyContent;
import javax.servlet.jsp.tagext.BodyTagSupport;
import javax.servlet.jsp.tagext.Tag;
public class MyForeachTag extends BodyTagSupport {
private Collection items;
private String var;
public void setItems(Collection items) {
this.items = items;
}
public void setVar(String var) {
this.var = var;
}
@Override
public int doStartTag() throws JspException {
if (items != null && !items.isEmpty()) {
pageContext.setAttribute(var, items.iterator().next());
return EVAL_BODY_INCLUDE;
} else {
return SKIP_BODY;
}
}
@Override
public int doAfterBody() throws JspException {
BodyContent body = getBodyContent();
if (body != null) {
body.clearBody();
}
if (items != null && !items.isEmpty()) {
items.remove(items.iterator().next());
if (!items.isEmpty()) {
pageContext.setAttribute(var, items.iterator().next());
return EVAL_BODY_AGAIN;
}
}
return SKIP_BODY;
}
@Override
public int doEndTag() throws JspException {
pageContext.removeAttribute(var);
return EVAL_PAGE;
}
}
```
在上面的代码中,我们定义了一个名为`MyForeachTag`的类,实现了JSP的循环标签接口。通过设置`items`和`var`属性,我们可以传递集合或数组以及变量名给循环标签。在标签的`doStartTag`方法中,我们判断集合是否为空,如果不为空,则将第一个元素赋值给指定的变量,并返回`EVAL_BODY_INCLUDE`,表示执行标签体。在标签的`doAfterBody`方法中,我们将集合中的第一个元素移除,并再次赋值给指定的变量,直到集合为空为止。最后,在标签的`doEndTag`方法中,我们移除变量的属性,并返回`EVAL_PAGE`,表示继续执行页面的剩余部分。
希望通过上述示例能够帮助您理解如何开发自定义的循环标签。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将全面介绍JSTL(JavaServer Pages Standard Tag Library)在Java Web应用开发中的应用。从JSTL的基础语法和简介开始,逐步深入探讨JSTL核心标签库的使用、数据操作、条件判断、循环等方面的内容,同时结合EL(表达式语言)、JSP和Servlet进行全方位的应用实践。同时,还将深入讨论JSTL在国际化、本地化、页面重定向、数据库操作、性能优化、用户认证与授权、MVC框架应用、异常处理以及在RESTful API开发中的应用等方面的具体实践。通过本专栏的学习,读者将全面掌握JSTL在Web应用开发中的应用技巧,为构建高质量、高效率的Java Web应用提供有力支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
理解SN29500-2010:IT专业人员的标准入门手册

# 摘要
SN29500-2010标准作为行业规范,对其核心内容和历史背景进行了概述,同时解析了关键条款,如术语定义、管理体系要求及信息安全技术要求等。本文还探讨了如何在实际工作中应用该标准,包括推广策略、员工培训、监督合规性检查,以及应对标准变化和更新的策略。文章进一步分析了SN29500-2010带来的机遇和挑战,如竞争优势、技术与资源
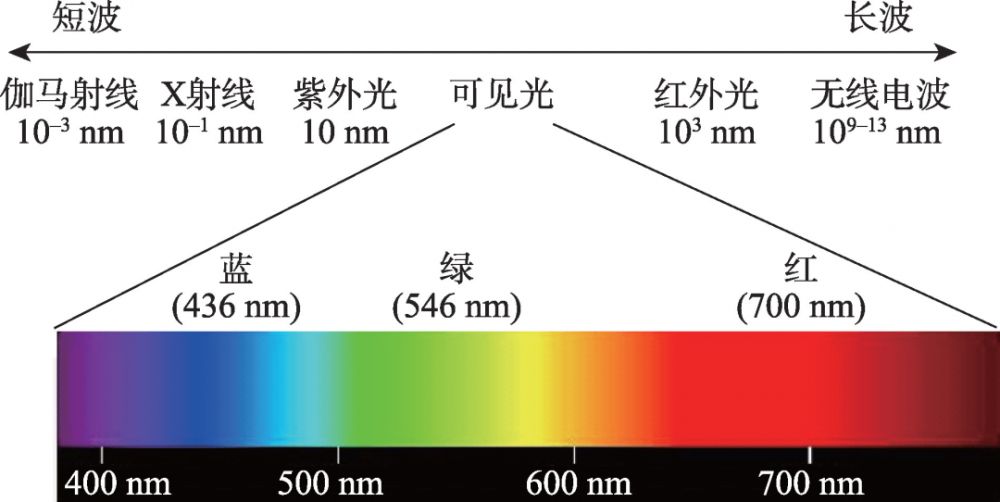
红外遥控编码:20年经验大佬揭秘家电控制秘籍
# 摘要
红外遥控技术作为无线通信的重要组成部分,在家电控制领域占有重要地位。本文从红外遥控技术概述开始,详细探讨了红外编码的基础理论,包括红外通信的原理、信号编码方式、信号捕获与解码。接着,本文深入分析了红外编码器与解码器的硬件实现,以及在实际编程实践中的应用。最后,本文针对红外遥控在家电控制中的应用进行了案例研究,并展望了红外遥控技术的未来趋势与创新方向,特别是在智能家居集成和技术创新方面。文章旨在为读者提
【信号完整性必备】:7系列FPGA SelectIO资源实战与故障排除
# 摘要
随着数字电路设计复杂度的提升,FPGA(现场可编程门阵列)已成为实现高速信号处理和接口扩展的重要平台。本文对7系列FPGA的SelectIO资源进行了深入探讨,涵盖了其架构、特性、配置方法以及在实际应用中的表现。通过对SelectIO资源的硬件组成、电气标准和参数配置的分析,本文揭示了其在高速信号传输和接口扩展中的关键作用。同时,本文还讨论了信号完整性
C# AES加密:向量化优化与性能提升指南
# 摘要
本文深入探讨了C#中的AES加密技术,从基础概念到实现细节,再到性能挑战及优化技术。首先,概述了AES加密的原理和数学基础,包括其工作模式和关键的加密步骤。接着,分析了性能评估的标准、工具,以及常见的性能瓶颈,着重讨论了向量化优化技术及其在AES加密中的应用。此外,本文提供了一份实践指南,包括选择合适的加密库、性能优化案例以及在安全性与性能之间寻找平衡点的策略。最后,展望了AES加密技术的未来趋势,包括新兴加密算法的演进和性能优化的新思路。本研究为C#开发者在实现高效且安全的AES加密提供了理论基础和实践指导。
# 关键字
C#;AES加密;对称加密;性能优化;向量化;SIMD指令
RESTful API设计深度解析:Web后台开发的最佳实践

# 摘要
本文全面探讨了RESTful API的设计原则、实践方法、安全机制以及测试与监控策略。首先,介绍了RESTful API设计的基础知识,阐述了核心原则、资源表述、无状态通信和媒体类型的选择。其次,通过资源路径设计、HTTP方法映射到CRUD操作以及状态码的应用,分析了RESTful API设计的具体实践。
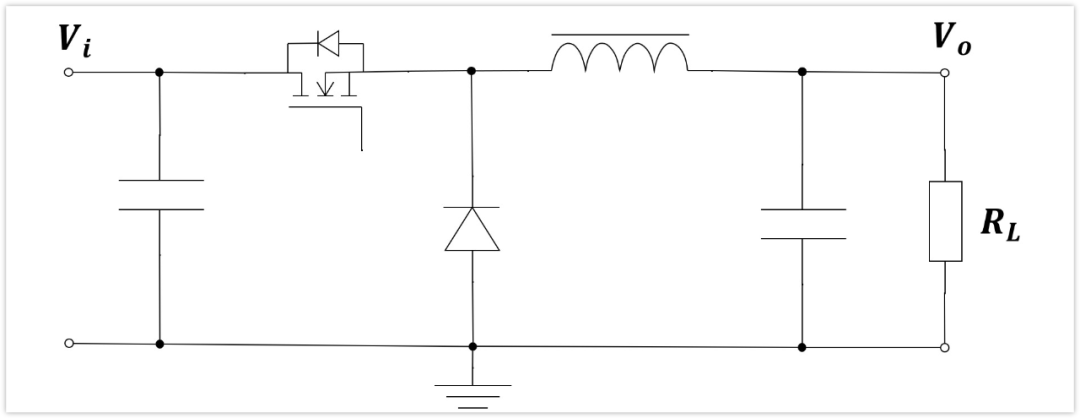
【Buck电路布局绝招】:PCB设计的黄金法则
# 摘要
Buck转换器是一种广泛应用于电源管理领域的直流-直流转换器,它以高效和低成本著称。本文首先阐述了Buck转换器的工作原理和优势,然后详细分析了Buck电路布局的理论基础,包括关键参数、性能指标、元件选择、电源平面设计等。在实践技巧方面,本文提供了一系列提高电路布局效率和准确性的方法,并通过案例分析展示了低噪声、高效率以及小体积高功率密度设计的实现。最后,本文展望了Buck电
揭秘苹果iap2协议:高效集成与应用的终极指南
# 摘要
本文系统介绍了IAP2协议的基础知识、集成流程以及在iOS平台上的具体实现。首先,阐述了IAP2协议的核心概念和环境配置要点,包括安装、配置以及与iOS系统的兼容性问题。然后,详细解读了IAP2协议的核心功能,如数据交换模式和认证授权机制,并通过实例演示了其在iOS应用开发和数据分析中的应用技巧。此外,文章还探讨了IAP2协议在安全、云计算等高级领域的应用原理和案例,以及性能优化的方法和未来发展的方向。最后,通过大
ATP仿真案例分析:故障相电压波形A的调试、优化与实战应用
# 摘要
本文对ATP仿真软件及其在故障相电压波形A模拟中的应用进行了全面介绍。首先概述了ATP仿真软件的发展背景与故障相电压波形A的理论基础。接着,详细解析了模拟流程,包括参数设定、步骤解析及结果分析方法。本文还深入探讨了调试技巧,包括ATP仿真环境配置和常见问题的解决策略。在此基础上,提出了优化策略,强调参数优化方法和提升模拟结果精确性的重要性。最后,通过电力系统的实战应用案例,本文展示了故障分析、预防与控制策略的实际效果,并通过案例研究提炼出有价值的经验与建议。
# 关键字
ATP仿真软件;故障相电压波形;模拟流程;参数优化;故障预防;案例研究
参考资源链接:[ATP-EMTP电磁暂
【流式架构全面解析】:掌握Kafka从原理到实践的15个关键点

# 摘要
流式架构作为处理大数据的关键技术之一,近年来受到了广泛关注。本文首先介绍了流式架构的概念,并深入解析了Apache Kafka作为流式架构核心组件的引入背景和基础知识。文章深入探讨了Kafka的架构原理、消息模型、集群管理和高级特性,以及其在实践中的应用案例,包括高可用集群的实现和与大数据生态以及微
【SIM卡故障速查速修秘籍】:10分钟内解决无法识别问题

# 摘要
本文旨在为读者提供一份全面的SIM卡故障速查速修指导。首先介绍了SIM卡的工作原理及其故障类型,然后详细阐述了故障诊断的基本步骤和实践技巧,包括使用软件工具和硬件检查方法。本文还探讨了常规和高级修复策略,以及预防措施和维护建议,以减少SIM卡故障的发生。通过案例分析,文章详细说明了典型故障的解决过程。最后,展望了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )