揭秘MySQL数据库性能提升秘诀:5个关键指标帮你提升数据库性能
发布时间: 2024-07-25 13:39:24 阅读量: 29 订阅数: 39 

MySQL数据库设计与优化实战:提升查询性能与系统稳定性

# 1. MySQL数据库性能优化概述
MySQL数据库性能优化是一项至关重要的任务,旨在提高数据库的响应速度、吞吐量和稳定性。通过优化数据库架构、配置和运维,我们可以最大限度地提高数据库的性能,满足业务需求。
本章将概述数据库性能优化的一般原则,包括:
- 性能评估与监控:确定数据库的性能瓶颈并持续监控其健康状况。
- 架构优化:优化表结构、索引和查询以提高查询效率。
- 配置优化:调整数据库参数和缓存设置以最大化性能。
- 运维优化:实施定期维护和故障处理流程以确保数据库的稳定性和可用性。
# 2. 数据库性能评估与监控
数据库性能评估与监控是数据库优化工作的基础,通过对数据库性能的全面了解,才能有针对性地进行优化。本章节将介绍数据库性能评估与监控的方法和工具。
### 2.1 性能指标体系
数据库性能指标体系是一套用来衡量数据库性能的指标集合,它可以帮助我们了解数据库的整体运行状况。常见的数据库性能指标包括:
#### 2.1.1 QPS和TPS
QPS(Queries Per Second)表示每秒处理的查询数,TPS(Transactions Per Second)表示每秒处理的事务数。这两个指标反映了数据库的处理能力。
#### 2.1.2 响应时间和吞吐量
响应时间是指数据库处理一个查询或事务所花费的时间,吞吐量是指数据库单位时间内处理的查询或事务数量。这两个指标反映了数据库的效率。
#### 2.1.3 CPU和内存利用率
CPU利用率和内存利用率反映了数据库服务器的资源使用情况。过高的CPU利用率或内存利用率可能导致数据库性能下降。
### 2.2 性能监控工具
数据库性能监控工具可以帮助我们收集和分析数据库性能数据,从而发现性能瓶颈并进行优化。常见的数据库性能监控工具包括:
#### 2.2.1 MySQL自带的监控工具
MySQL自带的监控工具包括:
- **SHOW STATUS**命令:可以显示数据库的各种状态信息,包括查询次数、连接数、锁等待时间等。
- **mysqladmin**命令:可以监控数据库的连接数、线程数、查询缓存命中率等信息。
- **MySQL Performance Schema**:是一个内置的性能监控框架,可以提供详细的性能数据。
#### 2.2.2 第三方监控工具
第三方数据库性能监控工具有很多,例如:
- **Prometheus**:一个开源的监控系统,可以监控数据库的各种指标,并提供可视化界面。
- **Zabbix**:一个企业级监控系统,可以监控数据库的性能、可用性和安全性。
- **Datadog**:一个SaaS监控平台,可以监控数据库的性能、日志和跟踪信息。
**代码块 1:使用 SHOW STATUS 命令监控数据库状态**
```sql
SHOW STATUS LIKE 'Innodb_buffer_pool_read_requests';
```
**逻辑分析:**
该命令显示了 InnoDB 缓冲池读取请求的次数。如果该值很高,则表明缓冲池命中率低,需要优化查询或调整缓冲池大小。
**参数说明:**
* `Innodb_buffer_pool_read_requests`:InnoDB 缓冲池读取请求的次数。
**表格 1:常见的数据库性能指标**
| 指标 | 描述 |
|---|---|
| QPS | 每秒处理的查询数 |
| TPS | 每秒处理的事务数 |
| 响应时间 | 处理一个查询或事务所花费的时间 |
| 吞吐量 | 单位时间内处理的查询或事务数量 |
| CPU利用率 | 数据库服务器的CPU使用率 |
| 内存利用率 | 数据库服务器的内存使用率 |
**Mermaid流程图 1:数据库性能监控流程**
```mermaid
sequenceDiagram
participant User
participant Database
participant Monitoring Tool
User->Database: Send query
Database->Monitoring Tool: Send performance data
Monitoring Tool->User: Display performance data
```
# 3. 数据库架构优化
### 3.1 表结构优化
#### 3.1.1 数据类型选择
数据类型选择是表结构优化中的重要一环,合适的类型可以提高存储效率、查询性能和数据完整性。
| 数据类型 | 特点 | 适用场景 |
|---|---|---|
| TINYINT | 占用空间小,取值范围有限 | 存储布尔值或小整数 |
| SMALLINT | 占用空间比 TINYINT 大,取值范围更大 | 存储较小的整数 |
| MEDIUMINT | 占用空间比 SMALLINT 大,取值范围更大 | 存储中等的整数 |
| INT | 占用空间比 MEDIUMINT 大,取值范围更大 | 存储一般的整数 |
| BIGINT | 占用空间比 INT 大,取值范围更大 | 存储较大的整数 |
| FLOAT | 存储浮点数,精度较低 | 存储近似值或小数 |
| DOUBLE | 存储浮点数,精度较高 | 存储需要高精度的浮点数 |
| DECIMAL | 存储定点数,精度和范围可自定义 | 存储需要精确计算的数值 |
| CHAR | 固定长度字符串,存储空间固定 | 存储长度固定的字符串 |
| VARCHAR | 可变长度字符串,存储空间根据实际长度分配 | 存储长度不固定的字符串 |
| TEXT | 大文本字符串,存储空间根据实际长度分配 | 存储较长的文本内容 |
| BLOB | 二进制大对象,存储任意二进制数据 | 存储图片、视频等二进制数据 |
#### 3.1.2 索引设计
索引是数据库中一种重要的数据结构,它可以加快数据的查询速度。
**索引类型**
| 索引类型 | 特点 | 适用场景 |
|---|---|---|
| B-Tree 索引 | 平衡二叉树结构,支持范围查询 | 一般查询场景 |
| 哈希索引 | 哈希表结构,支持等值查询 | 等值查询场景 |
| 全文索引 | 支持全文搜索 | 文本搜索场景 |
**索引设计原则**
* **选择合适的数据类型:**索引列的数据类型应与查询条件匹配,例如,对于范围查询,应使用 B-Tree 索引。
* **创建必要的索引:**根据查询模式创建索引,避免过度索引。
* **避免重复索引:**不要创建重复的索引,因为它们会浪费存储空间和降低性能。
* **优化索引列顺序:**对于复合索引,索引列的顺序应根据查询条件进行优化。
### 3.2 查询优化
#### 3.2.1 SQL 语句优化
SQL 语句的编写方式对查询性能有很大影响。以下是一些优化 SQL 语句的技巧:
* **使用适当的连接类型:**根据查询需求选择 INNER JOIN、LEFT JOIN 或 RIGHT JOIN 等连接类型。
* **避免使用子查询:**子查询会降低性能,应尽量使用 JOIN 代替。
* **优化 WHERE 子句:**使用索引列作为 WHERE 子句的条件,并避免使用 OR 条件。
* **使用 LIMIT 子句:**限制查询结果集的大小,避免不必要的全表扫描。
#### 3.2.2 索引使用优化
索引可以显著提高查询性能,但前提是索引被正确使用。以下是一些优化索引使用的技巧:
* **覆盖索引:**创建索引包含查询所需的所有列,避免回表查询。
* **索引合并:**对于复合查询,可以合并多个索引以提高性能。
* **避免索引失效:**避免在索引列上使用函数或表达式,否则索引将失效。
* **定期重建索引:**随着数据量的增加,索引可能会变得碎片化,需要定期重建以保持性能。
**代码示例:**
```sql
-- 优化后的 SQL 语句
SELECT * FROM users WHERE id = 1;
```
**逻辑分析:**
该 SQL 语句使用索引列 `id` 作为 WHERE 子句的条件,避免了全表扫描。
**参数说明:**
* `users`:要查询的表
* `id`:要查询的列
* `1`:要查询的值
# 4. 数据库配置优化
数据库配置优化是通过调整MySQL的配置参数和缓存设置来提高数据库性能。合理的配置可以有效减少资源消耗,提升查询效率。
### 4.1 参数优化
MySQL提供了丰富的配置参数,可以根据不同的业务场景和硬件环境进行调整。常见的参数优化包括:
#### 4.1.1 内存参数优化
**innodb_buffer_pool_size**:设置InnoDB缓冲池大小,用于缓存经常访问的数据和索引。适当增大缓冲池大小可以减少磁盘IO,提高查询性能。
**key_buffer_size**:设置查询缓存大小,用于缓存经常执行的查询语句。适当增大查询缓存大小可以减少解析和编译查询语句的时间,提高查询效率。
**max_connections**:设置最大连接数,限制同时连接到数据库的客户端数量。根据业务并发量和硬件资源合理设置此参数,避免因连接过多导致系统资源耗尽。
#### 4.1.2 连接参数优化
**connect_timeout**:设置客户端连接超时时间,超过此时间未建立连接则断开。合理设置此参数可以防止长时间未响应的连接占用系统资源。
**wait_timeout**:设置客户端查询超时时间,超过此时间未收到查询结果则断开连接。合理设置此参数可以防止长时间未响应的查询占用系统资源。
### 4.2 缓存优化
MySQL提供了两种主要的缓存机制:查询缓存和缓冲池。合理配置这些缓存可以有效提高查询效率。
#### 4.2.1 查询缓存优化
**query_cache_size**:设置查询缓存大小,用于缓存经常执行的查询语句及其结果。适当增大查询缓存大小可以减少解析和编译查询语句的时间,提高查询效率。
**query_cache_type**:设置查询缓存类型,有0、1、2三种模式。0表示禁用查询缓存,1表示缓存所有查询,2表示仅缓存可重复读取的查询。根据业务场景选择合适的缓存类型。
#### 4.2.2 缓冲池优化
**innodb_buffer_pool_instances**:设置缓冲池实例数量,可以提高多核CPU的并发访问性能。根据CPU核心数和业务并发量合理设置此参数。
**innodb_flush_log_at_trx_commit**:设置事务提交时是否立即将日志写入磁盘。设置为0表示不立即写入,而是每秒写入一次。设置为1表示立即写入。根据业务场景和数据安全要求选择合适的设置。
**innodb_log_buffer_size**:设置日志缓冲区大小,用于缓存事务日志。适当增大日志缓冲区大小可以减少日志写入磁盘的频率,提高事务提交效率。
# 5.1 定期维护
### 5.1.1 定期备份
定期备份是数据库运维中至关重要的环节,可以有效防止数据丢失。MySQL提供了多种备份方式,包括:
- **物理备份:**将整个数据库文件拷贝到另一个位置。优点是速度快,缺点是会阻塞数据库操作。
- **逻辑备份:**使用`mysqldump`工具将数据库中的数据导出为SQL语句文件。优点是不会阻塞数据库操作,缺点是速度较慢。
备份频率根据业务需求而定,一般建议每天或每周进行一次全量备份,并定期进行增量备份。
### 5.1.2 定期清理
随着数据库的使用,会产生大量的日志文件、临时文件和已删除的数据。这些文件会占用存储空间,影响数据库性能。因此,需要定期进行清理工作。
- **清理日志文件:**使用`mysqlbinlog`工具删除过期的二进制日志文件。
- **清理临时文件:**使用`rm -rf /tmp/*`命令删除`/tmp`目录下的临时文件。
- **清理已删除数据:**使用`OPTIMIZE TABLE`命令释放已删除数据的空间。
定期清理可以释放存储空间,提高数据库性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在提供全面深入的 MySQL 数据库知识和最佳实践。从启动数据库到优化性能、解决故障和实施安全措施,我们涵盖了所有关键方面。专栏中包含一系列文章,深入探讨了 MySQL 数据库的性能提升、索引失效、表锁问题、备份与恢复、数据迁移、分区表、查询优化、慢查询分析、索引优化、故障恢复、权限管理、审计与监控以及常见错误代码解析。无论你是数据库新手还是经验丰富的专业人士,本专栏都能为你提供宝贵的见解和实用的指导,帮助你充分利用 MySQL 数据库,提高其性能、可靠性和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
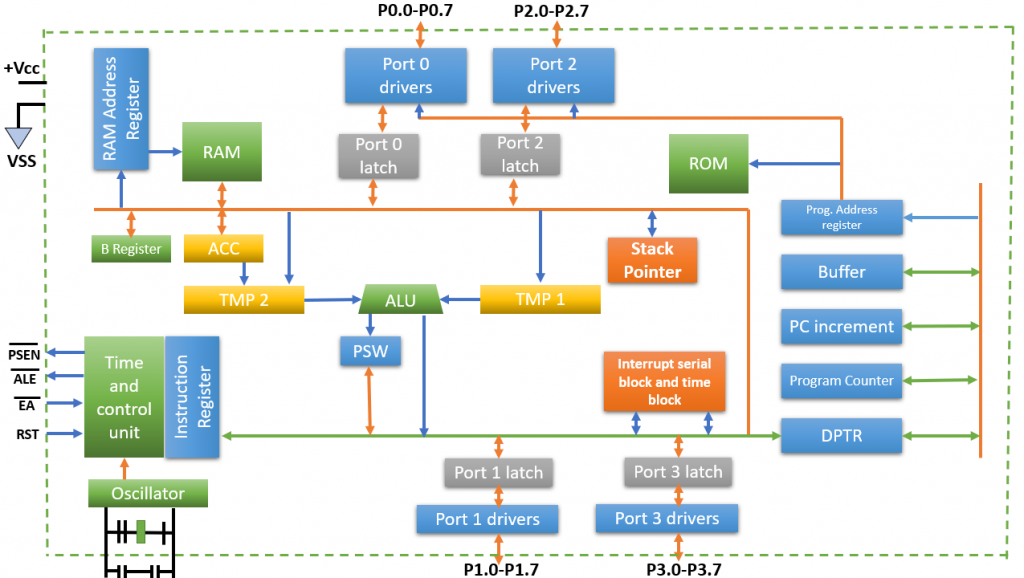
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
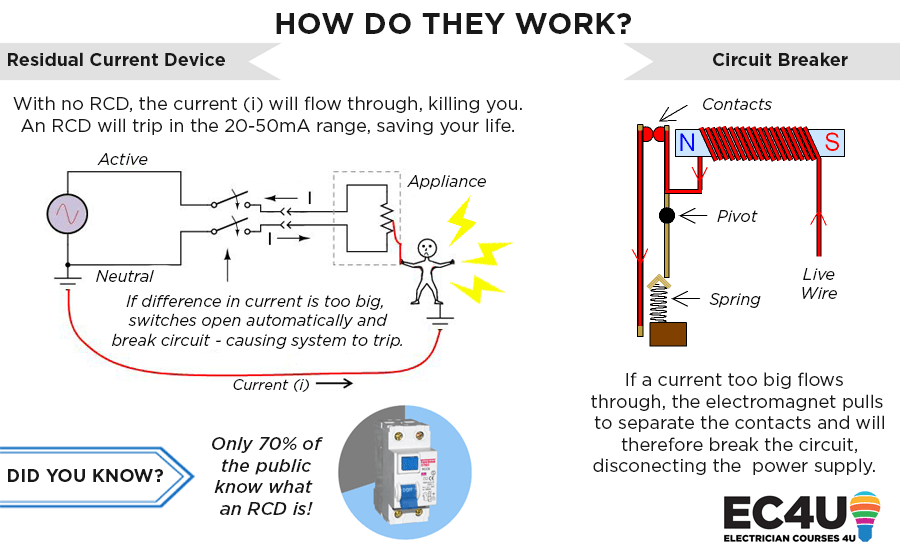
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
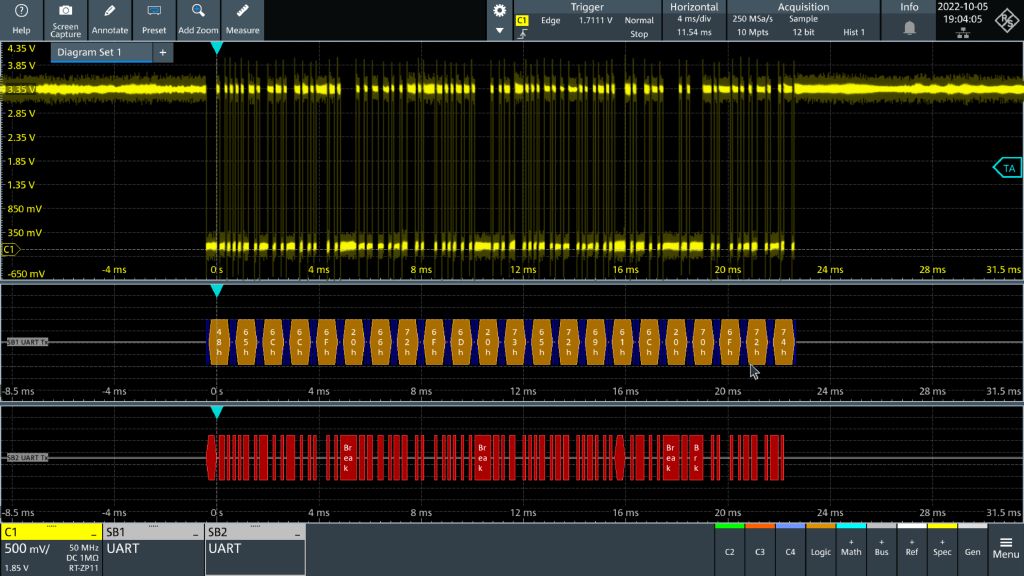
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
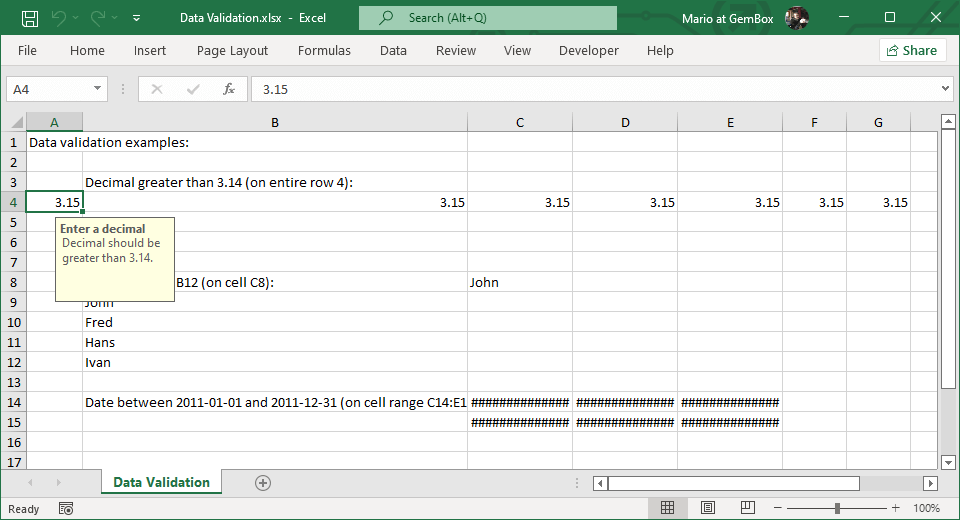
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )