训练集制作中的道德考量:尊重隐私和避免偏见,打造负责任的训练集
发布时间: 2024-08-16 21:45:59 阅读量: 26 订阅数: 22 

algorithmdesign:负责任的道德问题集的添加与Kleinberg和Tardos的算法设计保持一致
# 1. 训练集制作的道德考量
训练集是机器学习模型的基础,其质量直接影响模型的性能和可靠性。在训练集制作过程中,需要考虑道德考量,以确保数据的公平性、隐私性和透明度。
**1.1 数据公平性**
训练集应代表目标人群的分布,避免偏见和歧视。偏见可能来自数据采样、特征工程或模型评估过程中的不当操作。
**1.2 数据隐私**
训练集中包含个人信息,需要采取措施保护隐私。匿名化、去标识化和数据最小化原则可以帮助保护个人隐私,同时保留用于模型训练所需的信息。
# 2. 隐私保护在训练集制作中的实践
### 2.1 数据匿名化和去标识化
#### 2.1.1 匿名化技术
**匿名化**是指从数据中移除个人身份信息 (PII),使其无法再识别特定个人。常见的匿名化技术包括:
- **哈希和加密:**将 PII 转换为不可逆的哈希值或加密文本。
- **伪匿名化:**用随机生成的标识符替换 PII,同时保留某些特征以进行数据分析。
- **数据扰动:**对数据进行随机修改,例如添加噪声或交换值。
**代码块:**
```python
import hashlib
def hash_pii(pii):
"""
对 PII 进行哈希处理。
参数:
pii: 个人身份信息
返回:
哈希值
"""
return hashlib.sha256(pii.encode('utf-8')).hexdigest()
```
**逻辑分析:**
此代码块使用 SHA-256 哈希函数对 PII 进行哈希处理。哈希值是不可逆的,因此无法从哈希值中恢复原始 PII。
#### 2.1.2 去标识化方法
**去标识化**是指从数据中移除或修改 PII,使其无法合理地重新识别特定个人。去标识化方法包括:
- **数据掩码:**使用虚假数据或随机值替换 PII。
- **数据合成:**使用算法生成与原始数据相似的合成数据。
- **差分隐私:**添加随机噪声或扰动数据,以降低重新识别个人的风险。
**代码块:**
```python
import numpy as np
def add_noise(data, epsilon):
"""
向数据添加差分隐私噪声。
参数:
data: 数据
epsilon: 隐私预算
返回:
带噪声的数据
"""
return data + np.random.laplace(0, epsilon / data.shape[0])
```
**逻辑分析:**
此代码块使用拉普拉斯噪声向数据添加差分隐私。拉普拉斯噪声是一种随机噪声,其分布与隐私预算成正比。
### 2.2 数据最小化原则
#### 2.2.1 仅收集必要数据
**数据最小化原则**要求仅收集和使用训练集制作所需的必要数据。这有助于减少隐私风险和数据泄露的可能性。
**代码块:**
```python
import pandas as pd
def filter_data(data, required_columns):
"""
过滤数据,仅保留必需的列。
参数:
data: 数据
required_columns: 必需的列
返回:
过滤后的数据
"""
return data[requir
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列全面的指南,指导读者如何制作自己的训练集,以提升深度学习模型的性能。从零开始打造训练集、图像分割、视频分析、目标检测、数据增强、数据清理、数据平衡、数据验证、数据可视化、数据管理、道德考量、最佳实践、常见错误、案例研究、与模型性能的关系以及特定领域的应用等各个方面,该专栏深入探讨了训练集制作的各个环节。通过遵循这些指南,读者可以获得创建高质量训练集所需的知识和技能,从而显著提升其深度学习模型的准确度、泛化能力和鲁棒性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VS2022升级全攻略】:全面破解.NET 4.0包依赖难题
# 摘要
本文对.NET 4.0包依赖问题进行了全面概述,并探讨了.NET框架升级的核心要素,包括框架的历史发展和包依赖问题的影响。文章详细分析了升级到VS2022的必要性,并提供了详细的升级步骤和注意事项。在升级后,本文着重讨论了VS2022中的包依赖管理新工具和方法,以及如何解决升级中遇到的问题,并对升级效果进行了评估。最后,本文展望了.NET框架的未来发
【ALU设计实战】:32位算术逻辑单元构建与优化技巧

# 摘要
算术逻辑单元(ALU)作为中央处理单元(CPU)的核心组成部分,在数字电路设计中起着至关重要的作用。本文首先概述了ALU的基本原理与功能,接着详细介绍32位ALU的设计基础,包括逻辑运算与算术运算单元的设计考量及其实现。文中还深入探讨了32位ALU的设计实践,如硬件描述语言(HDL)的实现、仿真验证、综合与优化等关
【网络效率提升实战】:TST性能优化实用指南

# 摘要
本文全面综述了TST性能优化的理论与实践,首先介绍了性能优化的重要性及基础理论,随后深入探讨了TST技术的工作原理和核心性能影响因素,包括数据传输速率、网络延迟、带宽限制和数据包处理流程。接着,文章重点讲解了TST性能优化的实际技巧,如流量管理、编码与压缩技术应用,以及TST配置与调优指南。通过案例分析,本文展示了TST在企业级网络效率优化中的实际应用和性能提升措施,并针对实战
【智能电网中的秘密武器】:揭秘输电线路模型的高级应用

# 摘要
本文详细介绍了智能电网中输电线路模型的重要性和基础理论,以及如何通过高级计算和实战演练来提升输电线路的性能和可靠性。文章首先概述了智能电网的基本概念,并强调了输电线路模型的重要性。接着,深入探讨了输电线路的物理构成、电气特性、数学表达和模拟仿真技术。文章进一步阐述了稳态和动态分析的计算方法,以及优化算法在输电线路模型中的应用。在实际应用方面,本文分析了实时监控、预测模型构建和维护管理策略。此外,探讨了当前技术面临的挑战和未来发展趋势,包括人
【扩展开发实战】:无名杀Windows版素材压缩包分析
# 摘要
本论文对无名杀Windows版素材压缩包进行了全面的概述和分析,涵盖了素材压缩包的结构、格式、数据提取技术、资源管理优化、安全性版权问题以及拓展开发与应用实例。研究指出,素材压缩包是游戏运行不可或缺的组件,其结构和格式的合理性直接影响到游戏性能和用户体验。文中详细分析了压缩算法的类型、标准规范以及文件编码的兼容性。此外,本文还探讨了高效的数据提取技
【软件测试终极指南】:10个上机练习题揭秘测试技术精髓
# 摘要
软件测试作为确保软件质量和性能的重要环节,在现代软件工程中占有核心地位。本文旨在探讨软件测试的基础知识、不同类型和方法论,以及测试用例的设计、执行和管理策略。文章从静态测试、动态测试、黑盒测试、白盒测试、自动化测试和手动测试等多个维度深入分析,强调了测试用例设计原则和测试数据准备的重要性。同时,本文也关注了软件测试的高级技术,如性能测试、安全测试以及移动
【NModbus库快速入门】:掌握基础通信与数据交换
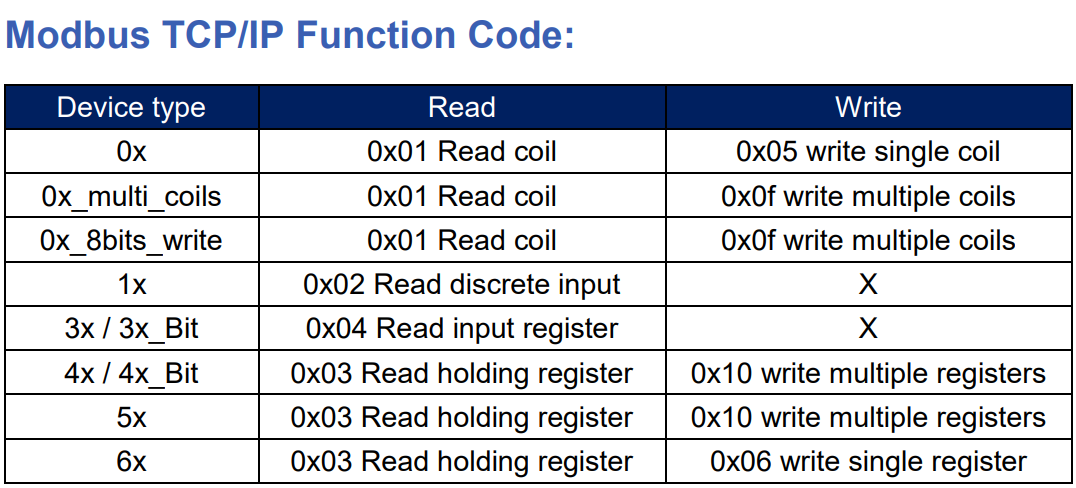
# 摘要
本文全面介绍了NModbus库的特性和应用,旨在为开发者提供一个功能强大且易于使用的Modbus通信解决方案。首先,概述了NModbus库的基本概念及安装配置方法,接着详细解释了Modbus协议的基础知识以及如何利用NModbus库进行基础的读写操作。文章还深入探讨了在多设备环境中的通信管理,特殊数据类型处理以及如何定
单片机C51深度解读:10个案例深入理解程序设计
# 摘要
本文系统地介绍了基于C51单片机的编程及外围设备控制技术。首先概述了C51单片机的基础知识,然后详细阐述了C51编程的基础理论,包括语言基础、高级编程特性和内存管理。随后,文章深入探讨了单片机硬件接口操作,涵盖输入/输出端口编程、定时器/计数器编程和中断系统设计。在单片机外围设备控制方面,本文讲解了串行通信、ADC/DAC接口控制及显示设备与键盘接口的实现。最后,通过综合案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )