Scrapy框架进阶:如何处理爬取过程中的各种异常情况
发布时间: 2024-01-05 20:31:26 阅读量: 142 订阅数: 24 
# 1. 理解Scrapy框架中的异常处理机制
## 1.1 异常处理的重要性
在爬取数据的过程中, 经常会遇到网络连接异常、页面结构变化、页面动态内容加载等问题,如何有效处理这些异常情况是保障爬虫正常运行的关键。
异常处理的重要性体现在以下几个方面:
- 保障爬虫的稳定性和可靠性,确保数据的完整性和准确性。
- 提高爬虫的鲁棒性,使其能够应对各种意料之外的情况。
- 提升用户体验,当用户访问网站时不希望看到因异常而崩溃的爬虫页面。
## 1.2 Scrapy框架中的异常分类
Scrapy框架中的异常情况大致可以分为以下几类:
- 网络连接异常:如连接超时、DNS解析失败等。
- 页面结构变化:目标网页结构发生变化,导致爬虫无法正常解析数据。
- 页面加载动态内容:部分网页内容通过Ajax或其他方式动态加载,传统的请求方式无法获取完整数据。
- 反爬虫机制导致的异常:网站针对爬虫的反爬虫策略,如IP封锁、访问频率限制等。
## 1.3 异常处理的基本原则
在处理爬取过程中的异常情况时,我们需要遵循一些基本原则:
- 及时捕获和记录异常信息,保证异常信息能够被及时定位和处理。
- 合理设计重试机制,对于一些可恢复的异常情况,可以通过重试来解决问题。
- 良好的日志记录,记录爬虫的运行状态和异常情况,方便进行后续的分析和优化。
# 2.
## 第二章:常见的爬取过程中的异常情况及解决方法
- ### 2.1 网络连接异常
在爬取过程中,经常会遇到网络连接异常,例如超时、拒绝连接等。这时可以通过设置超时时间、使用代理IP等方式来解决。下面是一个Python Scrapy框架中处理网络连接异常的示例代码:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider'
start_urls = ['http://example.com']
def parse(self, response):
# 网络连接异常处理
try:
# 爬取页面内容
pass
except Exception as e:
self.logger.error('网络连接异常:%s' % e)
# 重新发送请求
yield scrapy.Request(response.url, callback=self.parse, dont_filter=True)
```
- **代码说明:**
- 通过捕获异常来处理网络连接异常,记录日志并重新发送请求。
- 使用`dont_filter=True`参数,防止重复过滤同一URL请求。
- **结果说明:**
- 当发生网络连接异常时,将记录错误日志并重新发送请求,提高了爬虫的稳定性和健壮性。
- ### 2.2 爬取页面结构变化
网站页面结构经常会发生变化,导致爬虫无法正常解析数据。针对这种情况,可以定期更新爬虫代码,或者使用数据抽取工具自动适应页面变化。以下是Java Jsoup框架处理页面结构变化的示例代码:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class MyCrawler {
public static void main(String[] args) {
try {
Document doc = Jsoup.connect("http://example.com").get();
// 爬取页面结构变化处理
// ...
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
- **代码说明:**
- 使用Jsoup连接页面并爬取数据,通过捕获`IOException`来处理页面结构变化异常。
- 省略了具体的页面结构变化处理方法。
- **结果说明:**
- 爬取页面结构变化时,通过捕获`IOException`来处理异常,保证了爬虫的稳定性和健壮性。
- ### 2.3 页面加载动态内容
很多网站采用前端技术加载动态内容,传统爬虫无法直接获取动态生成的数据。针对此类情况,可以使用Selenium等工具模拟浏览器行为,或者分析前端接口实现数据的获取。以下是JavaScript Node.js框架中处理页面加载动态内容的示例代码:
```javascript
const axios = require('axios');
const cheerio = require('cheerio');
axios.get('http://example.com')
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
// 页面加载动态内容处理
// ...
})
.catch(error => {
console.log('页面加载动态内容异常:', error);
});
```
- **代码说明:**
- 使用Axios请求页面,并通过Cheerio解析HTML内容,捕获异常来处理页面加载动态内容的情况。
- **结果说明:**
- 通过捕获异常来处理页面加载动态内容的情况,保证了爬虫对动态页面的适应能力。
- ### 2.4 反爬虫机制导致的异常
很多网站会设置反爬虫机制,例如频繁访问限制、验证码验证等。针对这种情况,可以使用代理IP轮换、设置访问间隔、识别验证码等方式来规避反爬虫机制。以下是Go语言中处理反爬虫机制导致的异常的示例代码:
```go
package main
import (
"fmt"
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
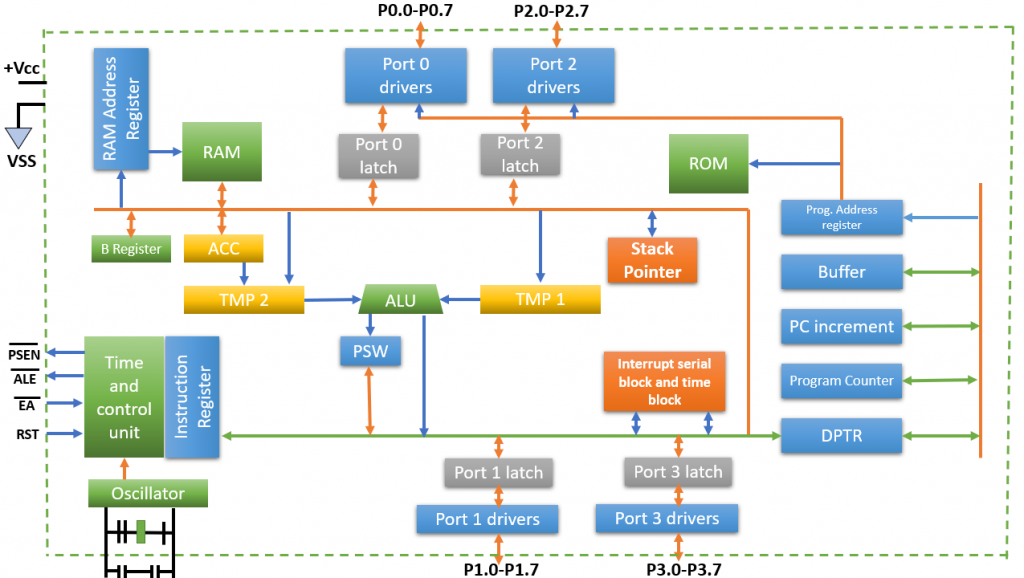
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
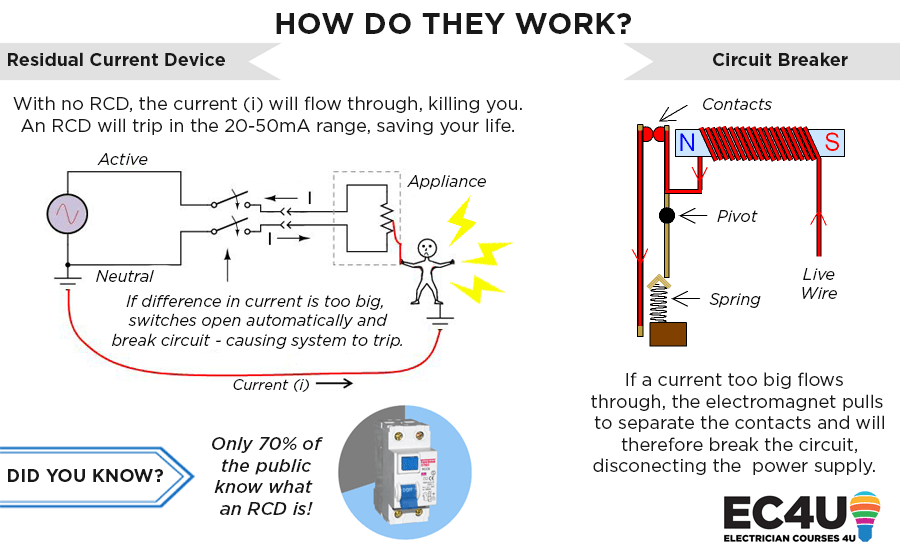
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
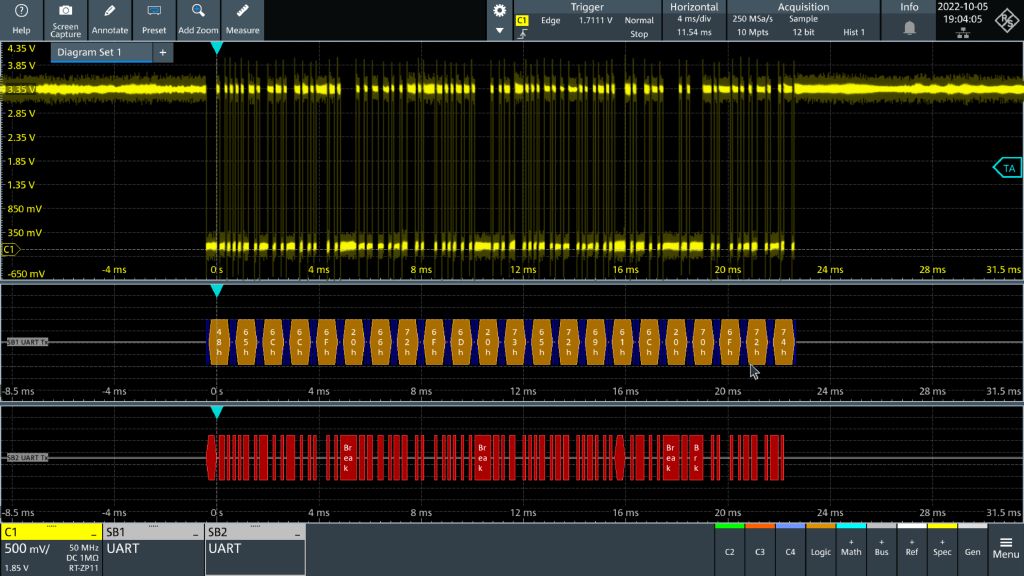
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
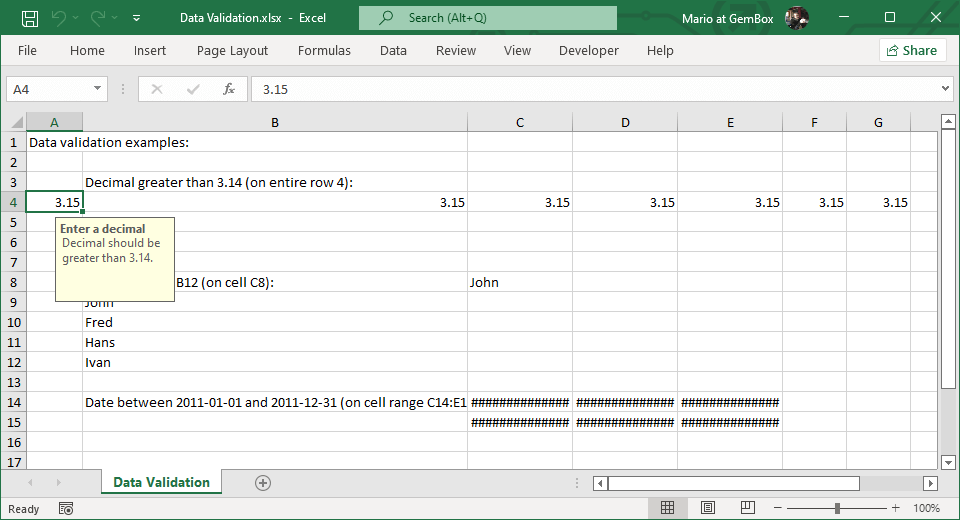
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )