数据预处理:构建高质量的训练数据集
发布时间: 2024-02-29 06:54:18 阅读量: 13 订阅数: 19 
# 1. 简介
## 1.1 数据预处理的重要性
数据预处理是机器学习和数据分析中不可或缺的一步。它涉及到对原始数据进行清洗、转换和加工,以使数据适合模型的输入。数据预处理的重要性体现在以下几个方面:
- **数据质量保证**: 数据预处理有助于保证数据的质量,包括数据的完整性、准确性和一致性。
- **提高模型准确性**: 经过预处理的数据能够提高模型的准确性和性能,因为模型往往不能直接处理原始的、未经加工的数据。
- **降低模型过拟合风险**: 通过数据预处理,可以降低模型过拟合的风险,使模型更加泛化。
## 1.2 为什么构建高质量的训练数据集是关键的
构建高质量的训练数据集对于机器学习模型的性能和效果至关重要。一个高质量的训练数据集能够为模型提供充分、准确、多样化的样本,使模型更好地学习特征和规律。此外,高质量的训练数据集也能够降低模型的偏差和方差,提高模型的泛化能力和稳定性。
在接下来的章节中,我们将逐步介绍数据预处理的关键步骤,以构建高质量的训练数据集。
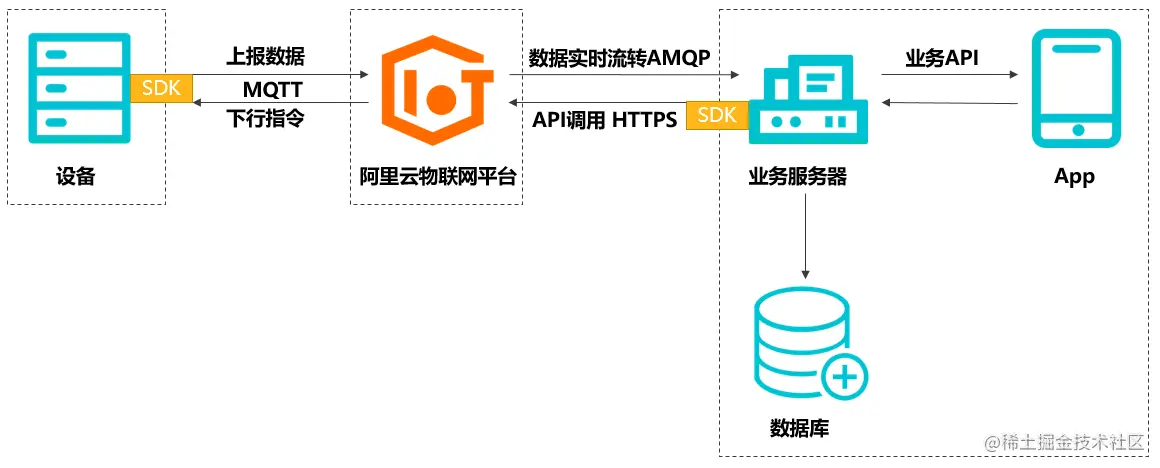
# 2. 数据采集
数据采集是构建高质量训练数据集的第一步,本章将介绍数据来源与获取方式,以及数据质量评估与筛选的相关内容。
### 2.1 数据来源与获取方式
数据可以来源于各种渠道,包括公开数据集、API接口、爬虫等方式。合适的数据来源选择对于训练数据集的质量至关重要。以下是一个示例Python代码,演示如何通过API获取数据:
```python
import requests
url = 'https://api.example.com/data'
response = requests.get(url)
if response.status_code == 200:
data = response.json()
# 进一步处理数据
else:
print("Failed to fetch data")
```
### 2.2 数据质量评估与筛选
在数据采集过程中,通常会遇到数据质量参差不齐的情况。因此,数据质量评估与筛选是必不可少的步骤。可以通过统计描述、可视化等手段对数据进行初步评估,进而筛选出高质量的数据样本。以下是一个简单的数据质量评估示例代码:
```python
import pandas as pd
data = pd.read_csv('data.csv')
print(data.head()) # 查看数据前几行
print(data.describe()) # 数据统计描述
print(data.isnull().sum()) # 统计缺失值数量
```
通过数据质量评估与筛选,可以确保后续数据预处理步骤的顺利进行,并且构建高质量的训练数据集。
# 3. 数据清洗
在数据预处理过程中,数据清洗是一个至关重要的步骤,主要包括处理缺失值、异常值、去重以及重复值等问题。
#### 3.1 缺失值处理
缺失值是指数据中某些字段的数值是缺失的情况,通常会影响数据分析的准确性。常见的处理方式包括删除缺失值、填充缺失值等。
**删除缺失值:**
```python
# 删除包含缺失值的行
df.dropna(inplace=True)
```
**填充缺失值:**
```python
# 使用均值填充缺失值
df['column'].fillna(df['column'].mean(), inplace=True)
```
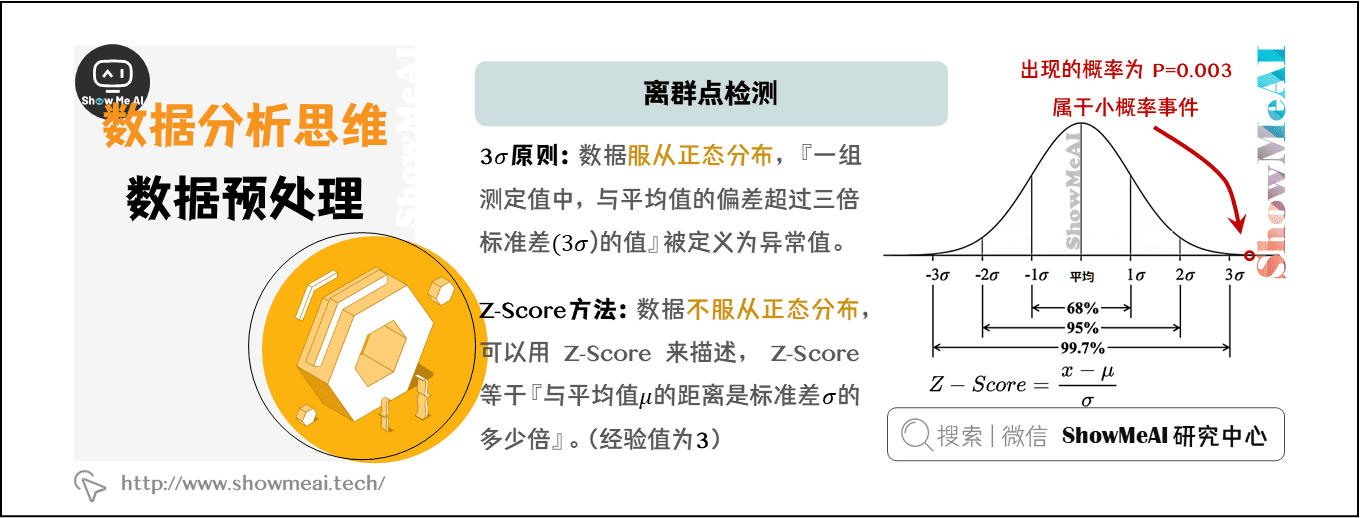
#### 3.2 异常值检测与处理
异常值是指与大部分数据明显不同的数值,可能会干扰模型的训练。常见的处理方式包括删除异常值、平滑处理等。
**删除异常值:**
```python
# 删除大于3倍标
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB数值计算高级技巧:求解偏微分方程和优化问题

# 1. MATLAB数值计算概述**
MATLAB是一种强大的数值计算环境,它提供了一系列用于解决各种科学和工程问题的函数和工具。MATLAB数值计算的主要优
MATLAB神经网络与物联网:赋能智能设备,实现万物互联

# 1. MATLAB神经网络简介**
MATLAB神经网络是一个强大的工具箱,用于开发和部署神经网络模型。它提供了一系列函数和工具,使研究人员和工程师能够轻松创建、训练和评估神经网络。
MATLAB神经网络工具箱包括各种神经网络类型,包括前馈网络、递归网络和卷积网络。它还提供了一系列学习算法,例如反向传播和共轭梯度法。
MATLAB神经网络工具箱在许多领域都有应用,包括
MATLAB求导在航空航天中的作用:助力航空航天设计,征服浩瀚星空

# 1. MATLAB求导基础**
MATLAB求导是计算函数或表达式导数的强大工具,广泛应用于科学、工程和数学领域。
在MATLAB中,求导可以使用`diff()`函数。`diff()`函数接受一个向量或矩阵作为输入,并返回其导数。对于向量,`diff()`计算相邻元素之间的差值;对于矩阵,`diff()`计算沿指定维度的差值。
例如,计算函数 `f(x) = x^2
MATLAB四舍五入在物联网中的应用:保证物联网数据传输准确性,提升数据可靠性
# 1. MATLAB四舍五入概述
MATLAB四舍五入是一种数学运算,它将数字舍入到最接近的整数或小数。四舍五入在各种应用中非常有用,包括数据分析、财务计算和物联网。
MATLAB提供了多种四舍五入函数,每个函数都有自己的特点和用途。最常
MATLAB常见问题解答:解决MATLAB使用中的常见问题

# 1. MATLAB常见问题概述**
MATLAB是一款功能强大的技术计算软件,广泛应用于工程、科学和金融等领域。然而,在使用MA
遵循MATLAB最佳实践:编码和开发的指南,提升代码质量
# 1. MATLAB最佳实践概述**
MATLAB是一种广泛用于技术计算和数据分析的高级编程语言。MATLAB最佳实践是一套准则,旨在提高MATLAB代码的质量、可读性和可维护性。遵循这些最佳实践可以帮助开发者编写更可靠、更有效的MATLAB程序。
MATLAB最佳实践涵盖了广泛的主题,包括编码规范、开发实践和高级编码技巧。通过遵循这些最佳实践,开发者可以提高代码的质量,
MATLAB面向对象编程:提升MATLAB代码可重用性和可维护性,打造可持续代码

# 1. 面向对象编程(OOP)简介**
面向对象编程(OOP)是一种编程范式,它将数据和操作封装在称为对象的概念中。对象代表现实世界中的实体,如汽车、银行账户或学生。OOP 的主要好处包括:
- **代码可重用性:** 对象可以根据需要创建和重复使用,从而节省开发时间和精力。
- **代码可维护性:** OOP 代码易于维护,因为对象将数据和操作封
直方图反转:图像处理中的特殊效果,创造独特视觉体验
# 1. 直方图反转简介**
直方图反转是一种图像处理技术,它通过反转图像的直方图来创造独特的视觉效果。直方图是表示图像中不同亮度值分布的图表。通过反转直方图,可以将图像中最亮的像素变为最暗的像素,反之亦然。
这种技术可以产生引人注目的效果,例如创建高对比度的图像、增强细节或创造艺术性的表达。直方图反转在图像处理中有着广泛的应用,包括图像增强、图像分割和艺术表达。
# 2. 直
MATLAB随机数科学计算中的应用:从物理建模到生物模拟

# 1. MATLAB随机数的基础**
**1.1 随机数的类型和生成方法**
MATLAB提供多种随机数生成器,每种生成器都产生具有特定分布的随机数。常见的随机数生成器包括:
- `rand`:生成均匀分布的随机数,范围为[0,1]。
- `randn`:生成标准正态分布的随机数,均值为0,标准差为1。
- `randsample`:从指定集合中随机抽取元素。
**1.2 随机数的分布和性质
MATLAB阶乘大数据分析秘籍:应对海量数据中的阶乘计算挑战,挖掘数据价值
# 1. MATLAB阶乘计算基础**
MATLAB阶乘函数(factorial)用于计算给定非负整数的阶乘。阶乘定义为一个正整数的所有正整数因子的乘积。例如,5的阶乘(5!)等于120,因为5! = 5 × 4 × 3 × 2 × 1。
MATLAB阶乘函数的语法如下:
```
y = factorial(x)
```
其中:
* `x`:要计算阶
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )