Ubuntu自动化运维:使用Ansible和Juju简化系统管理指南
发布时间: 2024-09-27 23:34:13 阅读量: 47 订阅数: 30 

使用自动化运维工具Ansible集中化管理服务器

# 1. Ubuntu自动化运维概述
随着信息技术的快速发展,自动化运维已经成为现代数据中心和云服务管理不可或缺的一环。在本章中,我们将简要介绍自动化运维的基本概念,特别是它如何在Ubuntu操作系统上实现。我们将从自动化运维的核心价值和它带来的好处开始讨论,逐渐深入到它在业务连续性和效率提升方面的重要作用。
## 1.1 自动化运维的基本概念
自动化运维是指利用计算机程序,减少或消除在信息科技基础设施、应用或服务的生命周期内进行手动操作的需求。这涵盖了从安装和配置服务器、部署应用程序到系统监控和管理的各个方面。
## 1.2 自动化运维的优势
自动化能够极大地减少人为错误,提高部署速度和可靠性。它还可以提供一致性和可重复性,确保无论何时何地部署系统或应用程序,都能获得相同的结果。
## 1.3 Ubuntu在自动化运维中的角色
Ubuntu因其广泛的应用和活跃的社区支持,在自动化运维领域得到了广泛的认可。Ubuntu不仅提供了丰富的自动化工具,而且其安全性、稳定性和可扩展性都是支持大规模自动化部署的理想选择。
通过本章的介绍,读者将对自动化运维有一个初步的认识,为后续深入了解Ansible和Juju等自动化工具打下坚实的基础。接下来的章节将详细介绍这些工具在Ubuntu系统中具体的应用和实践。
# 2. Ansible基础与配置管理
## 2.1 Ansible的安装与环境准备
### 2.1.1 Ansible的安装过程
在Ubuntu系统上安装Ansible相对直接。首先,确保你的系统是最新的,然后通过包管理器安装Ansible。以下是在基于Debian的系统(如Ubuntu)上安装Ansible的步骤:
```bash
# 更新本地包索引
sudo apt update
# 安装软件属性常用工具
sudo apt install software-properties-common
# 添加Ansible PPA仓库
sudo add-apt-repository --yes --update ppa:ansible/ansible
# 安装Ansible
sudo apt install ansible
```
为了验证安装是否成功,可以运行:
```bash
ansible --version
```
### 2.1.2 配置主机清单和连接
安装完Ansible之后,配置主机清单(inventory)文件是接下来的步骤。Inventory文件用于定义Ansible将管理的目标服务器。通常,这个文件被命名为`/etc/ansible/hosts`,并且是Ansible在执行任何任务前的默认清单文件。
一个典型的Inventory文件可能包含如下内容:
```ini
[webservers]
webserver1 ansible_host=***.***.*.*** ansible_user=root
webserver2 ansible_host=***.***.*.*** ansible_user=root
[dbservers]
dbserver1 ansible_host=***.***.*.*** ansible_user=root
```
在上面的示例中,我们定义了两组服务器:`webservers`和`dbservers`,它们分别拥有各自的IP地址和默认管理用户。接下来,通过运行ping模块测试连接:
```bash
ansible all -m ping
```
这将发送一个ping请求到所有在Inventory文件中定义的主机,以确认它们是否可被Ansible控制。
## 2.2 Ansible的核心概念和使用
### 2.2.1 Playbook的基本结构和语法
在Ansible中,Playbook是自动化任务的蓝图,它使用YAML格式来描述自动化的过程。每个Playbook包含了一个或多个“plays”,每个play描述了任务的执行角色和目标系统。
以下是一个简单的Playbook示例,用于安装并启动一个Nginx服务器:
```yaml
- name: Install and start Nginx
hosts: webservers
become: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: present
- name: Start Nginx
service:
name: nginx
state: started
enabled: yes
```
### 2.2.2 Task和Handlers的使用
在Ansible Playbook中,task是具体需要执行的操作步骤。Handler是一种特殊类型的task,它只有在被通知时才会执行。这通常用于触发服务重启等操作。
```yaml
- name: Configure Nginx
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify:
- restart Nginx
handlers:
- name: restart Nginx
service:
name: nginx
state: restarted
```
在这个例子中,任何触发`restart Nginx` handler的task都会导致Nginx服务被重启。
### 2.2.3 变量和模板的应用
变量在Ansible Playbook中用于存储可重用的信息,比如服务器的IP地址或者应用的配置文件名。一个简单的变量应用示例如下:
```yaml
vars:
app_port: 8080
tasks:
- name: Start my application
command: myapp.py {{ app_port }}
```
模板用于生成动态配置文件,使得配置文件能够根据不同的环境和角色有所变化。使用Jinja2模板引擎语法来创建模板文件,例如`nginx.conf.j2`。
```jinja
user {{ ansible_user }}; # 在此处使用变量
```
## 2.3 Ansible的高级特性
### 2.3.1 Role的创建和分发
在Ansible中,Role是一种组织Playbook的推荐方式,它将一个Playbook分解成可重用和可共享的多个部分。一个Role通常包含任务(tasks)、变量(variables)、模板(templates)、文件(files)、处理程序(handlers)和元数据(meta)。
创建一个Role的命令如下:
```bash
ansible-galaxy init myrole
```
这将创建一个包含目录结构的Role,如`tasks`、`handlers`、`files`等。然后可以在主Playbook中引用这个Role:
```yaml
- name: Playbook example
hosts: webservers
roles:
- myrole
```
### 2.3.2 条件语句和循环的应用
条件语句允许基于某些条件来决定任务是否运行。比如,仅当指定的包未安装时才安装它:
```yaml
tasks:
- name: Install package if not installed
apt:
name: "{{ item }}"
state: present
loop:
- package1
- package2
when: ansible_facts.packages['{{ item }}'] is not installed
```
循环允许对一个列表执行任务。上面的例子中,使用`loop`对`package1`和`package2`进行安装。
### 2.3.3 Ansible Galaxy的使用
Ansible Galaxy是一个社区驱动的网站,用于分享Ansible Roles。用户可以在Galaxy上查找、下载并使用其他用户创建的Roles,也可以发布自己的Roles供他人使用。
使用Galaxy的命令如下:
```bash
ansible-galaxy install <namespace>.<role-name>
```
这将安装指定的Role,并将其放在当前用户的角色路径中,之后就可以在Playbook中引用了。
在下一章节中,我们将深入了解Juju的安装、配置及其如何部署应用到不同的云环境中。通过比较Ansible和Juju,我们可以探索二者如何互补,为IT专业人员提供强大的工具集合。
# 3. Juju简介与部署应用
## 3.1 Juju的安装与配置
### 3.1.1 Juju的安装过程
Juju 是一个强大的云服务管理和多云应用部署工具,能够简化云服务的操作和应用的部署过程。首先,Juju 支持多种云平台,比如 AWS、Azure、OpenStack、Google Cloud Platform 等。安装 Juju 之前,确保您的系统已经安装了 Python 3 和 snapd(对于基于 snap 的安装包管理器)。
下面是安装 Juju 的步骤:
1. 安装 snapd(如果尚未安装):
```bash
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“Ubuntu版本”专栏深入探究Ubuntu操作系统的各个方面,从版本升级到服务器优化、包管理、文件系统管理、监控和日志管理,再到高可用集群搭建。专栏提供了一系列实用技巧和最佳实践,帮助读者充分利用Ubuntu的强大功能。涵盖的内容包括:
* Ubuntu版本升级的无缝过渡
* 提升Ubuntu服务器性能和效率的秘诀
* apt和snap包管理器的比较和选择指南
* EXT4和ZFS文件系统的选择和优化策略
* 确保系统稳定的监控和日志分析技术
* 保障业务连续性的高可用集群搭建实践
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
USB 3.0 vs USB 2.0:揭秘性能提升背后的10大数据真相

# 摘要
USB 3.0相较于USB 2.0在技术标准和理论性能上均有显著提升。本文首先对比了USB 3.0与USB 2.0的技术标准,接着深入分析了接口标准的演进、数据传输速率的理论极限和兼容性问题。硬件真相一章揭示了USB 3.0在硬件结构、数据传输协议优化方面的差异,并通过实测数据与案例展示了其在不同应用场景中的性能表现。最后一章探讨了US
定位算法革命:Chan氏算法与其他算法的全面比较研究
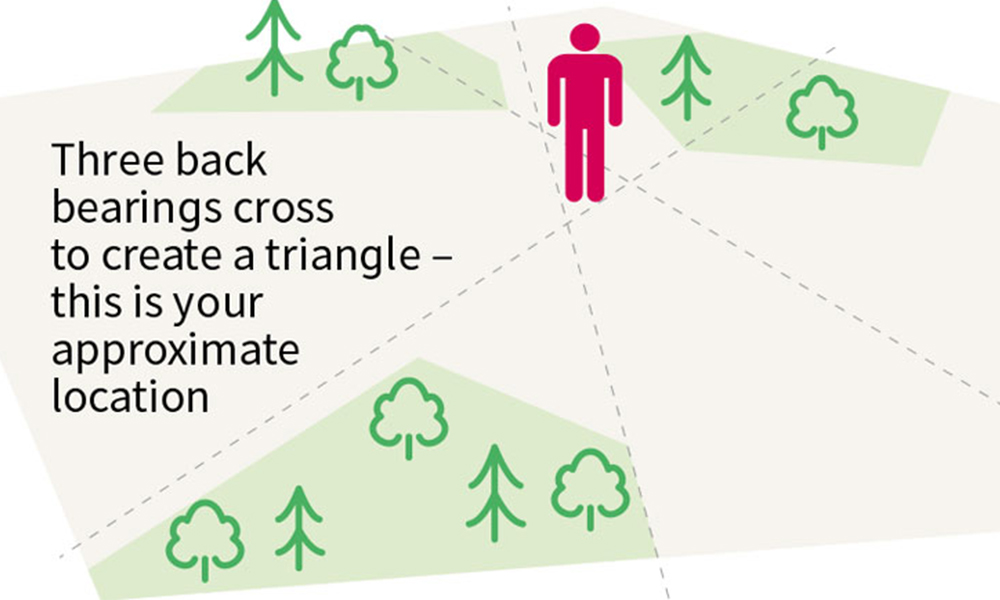
# 摘要
本文对定位算法进行了全面概述,特别强调了Chan氏算法的重要性、理论基础和实现。通过比较Chan氏算法与传统算法,本文分析了其在不同应用场景下的性能表现和适用性。在此基础上,进一步探讨了Chan氏算法的优化与扩展,包括现代改进方法及在新环境下的适应性。本文还通过实
【电力系统仿真实战手册】:ETAP软件的高级技巧与优化策略
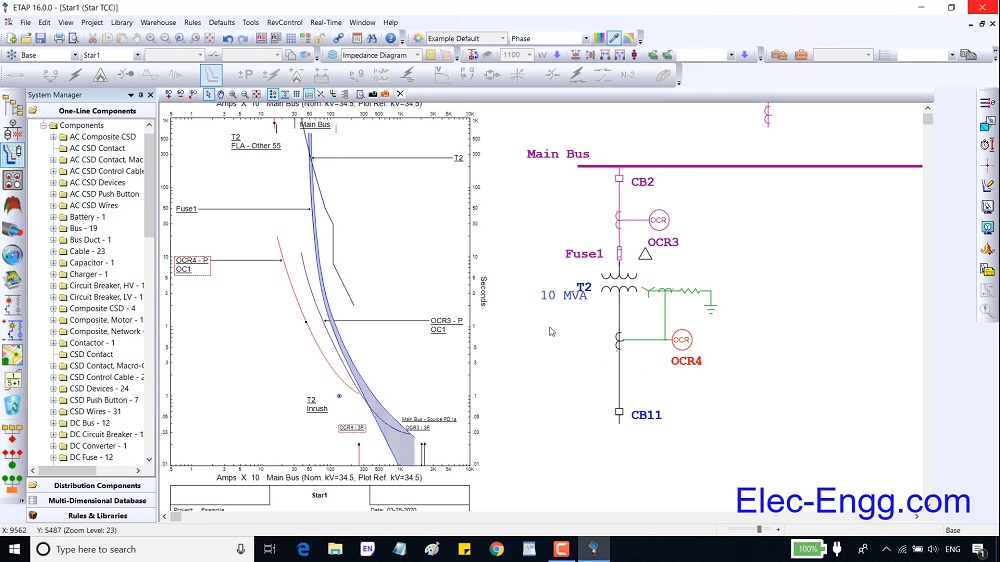
# 摘要
ETAP软件作为一种电力系统分析与设计工具,在现代电力工程中扮演着至关重要的角色。本文第一章对ETAP软件进行了概述,并介绍了其基础设置。第二章深入探讨了高级建模技巧,包括系统建模与分析的基础,复杂系统模型的创建,以及高级模拟技术的应用。第三章着重于ETAP软件的优化策略与性能提升,涵盖仿真参数优化,硬件加速与分布式计算,以及资源管理与仿真瓶颈分析。第四章
模拟精度的保障:GH Bladed 模型校准关键步骤全解析
# 摘要
GH Bladed模型校准是确保风力发电项目设计和运营效率的关键环节。本文首先概述了GH Bladed模型校准的概念及其在软件环境
故障不再怕:新代数控API接口故障诊断与排除宝典

# 摘要
本文针对数控API接口的开发、维护和故障诊断提供了一套全面的指导和实践技巧。在故障诊断理论部分,文章详细介绍了故障的定义、分类以及诊断的基本原则和分析方法,并强调了排除故障的策略。在实践技巧章节,文章着重于接口性能监控、日志分析以及具体的故障排除步骤。通过真实案例的剖析,文章展现了故障诊断过程的详细步骤,并分析了故障排除成功的关键因素。最后,本文还探讨了数控API接口的维护、升级、自动化测试以及安全合规性要求和防护措
Java商品入库批处理:代码效率提升的6个黄金法则

# 摘要
本文详细探讨了Java商品入库批处理中代码效率优化的理论与实践方法。首先阐述了Java批处理基础与代码效率提升的重要性,涉及代码优化理念、垃圾回收机制以及多线程与并发编程的基础知识。其次,实践部分着重介绍了集合框架的运用、I/O操作性能优化、SQL执行计划调优等实际技术。在高级性能优化章节中,本文进一步深入到JVM调优、框架与中间件的选择及集成,以及
QPSK调制解调误差控制:全面的分析与纠正策略
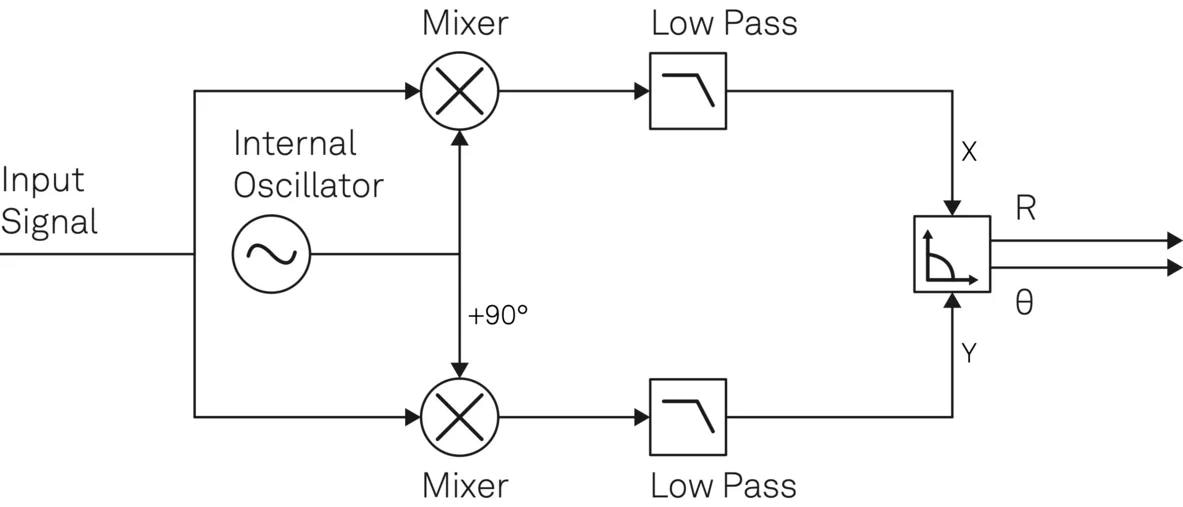
# 摘要
本文全面概述了QPSK(Quadrature Phase Shift Keying)调制解调技术,从基础理论到实践应用进行了详尽的探讨。首先,介绍了QPSK的基础理论和数学模型,探讨了影响其性能的关键因素,如噪声和信道失真,并深入分析了QPSK的误差理论。其次,通过实验环境的配置和误差的测量,对QPSK调制解调误差进行了实践分析
提升SiL性能:5大策略优化开源软件使用

# 摘要
本文针对SiL性能优化进行了系统性的研究和探讨。首先概述了SiL性能优化的重要性,并引入了性能分析与诊断的相关工具和技术。随后,文章深入到代码层面,探讨了算法优化、代码重构以及并发与异步处理的策略。在系统与环境优化方面,提出了资源管理和环境配置的调整方法,并探讨了硬件加速与扩展的实施策略。最后,本文介绍了性能监控与维护的最佳实践,包括持续监控、定期调优以及性能问题的预防和解决。通过这些方
透视与平行:Catia投影模式对比分析与最佳实践

# 摘要
本文对Catia软件中的投影模式进行了全面的探讨,首先概述了投影模式的基本概念及其在设计中的作用,其次通过比较透视与平行投影模式,分析了它们在Catia软件中的设置、应用和性能差异。文章还介绍了投影模式选择与应用的最佳实践技巧,以及高级投影技巧对设计效果的增强。最后,通过案例研究,深入分析了透视与平行投影模式在工业设计、建筑设计
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )