Spring Cloud监控与运维:Prometheus与Grafana的最佳实践
发布时间: 2023-12-20 05:46:30 阅读量: 44 订阅数: 40 
# 1. Spring Cloud监控与运维简介
## 1.1 Spring Cloud的监控需求
随着微服务架构的流行,Spring Cloud已经成为了创建和管理分布式系统的首选框架。然而,随着微服务系统规模的不断扩大,我们也面临着越来越多的挑战,如运维、监控和故障排查等。因此,我们需要一种有效的方式来监控和运维我们的Spring Cloud应用,以确保系统的可靠性和稳定性。
## 1.2 监控与运维的重要性
监控与运维是微服务架构中不可忽视的部分,它们可以帮助我们实时了解系统的运行情况,及时发现并解决问题,从而保证系统的稳定性和可靠性。监控可以提供关键指标和性能数据,以便我们进行性能优化和容量规划。运维则关注系统的整体健康状况,确保系统稳定运行,并对故障进行快速排查和修复。
## 1.3 Prometheus与Grafana的概述
Prometheus是一套开源的监控系统,它采用基于时间序列的数据模型,提供了强大的查询语言和灵活的告警机制。Prometheus能够通过定时抓取、服务发现等方式收集监控数据,并存储在本地数据库中。Grafana则是一款功能强大的可视化平台,可以与Prometheus进行集成,提供丰富的数据展示和报表功能,帮助我们直观地了解系统的运行情况。
下面我们将详细介绍Prometheus和Grafana的安装与配置,以及如何将其应用于Spring Cloud监控与运维。
# 2. Prometheus的安装与配置
Prometheus作为一款开源的监控报警系统和时间序列数据库,为用户提供了丰富的监控数据采集和存储能力。本章将介绍Prometheus的安装与配置过程,帮助读者快速上手并使用Prometheus进行监控与运维工作。
### 2.1 Prometheus的特点与优势
Prometheus具有多维数据模型、灵活的查询语言和强大的图表展示能力,适用于大规模的分布式系统监控。它能够高效地存储时间序列数据,并且支持灵活的标签查询和聚合操作,为用户提供了全面的监控数据分析能力。
### 2.2 安装Prometheus服务器
在本节中,我们将介绍如何安装Prometheus服务器,以便开始监控Spring Cloud应用的各项指标数据。
首先,我们需要下载最新的Prometheus安装包:
```bash
$ wget https://github.com/prometheus/prometheus/releases/download/v2.33.1/prometheus-2.33.1.linux-amd64.tar.gz
$ tar -xvf prometheus-2.33.1.linux-amd64.tar.gz
```
解压后,进入目录并创建存储数据的文件夹:
```bash
$ cd prometheus-2.33.1.linux-amd64
$ mkdir data
```
接下来,创建一个简单的配置文件`prometheus.yml`,用于指定数据采集的目标和规则:
```yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'spring-cloud-app'
static_configs:
- targets: ['localhost:8080'] # 这里填写Spring Cloud应用的地址和端口
```
最后,启动Prometheus服务器:
```bash
$ ./prometheus --config.file=prometheus.yml
```
至此,我们成功安装并配置了Prometheus服务器,可以通过访问`http://localhost:9090`来访问Prometheus的Web界面,并开始查看监控指标数据了。
### 2.3 配置Prometheus的数据采集与存储
在本节中,我们将详细说明如何配置Prometheus进行数据采集和存储。
首先,在`prometheus.yml`配置文件中,我们可以设置不同的`job`来指定不同的数据采集目标,例如:
```yaml
scrape_configs:
- job_name: 'spring-cloud-app'
static_configs:
- targets: ['localhost:8080'] # 这里填写Spring Cloud应用的地址和端口
- job_name: 'node-exporter'
static_configs:
- targets: ['localhost:9100'] # 这里填写Node Exporter的地址和端口
```
除此之外,Prometheus还支持通过`relabel_configs`对数据进行重标记、去除和转换。我们可以根据实际的监控需求,对数据进行灵活的处理和过滤。
其次,Prometheus默认将数据存储在本地的`data/`目录下,用户可以根据实际情况进行数据的定期备份和清理工作,以确保数据的安全和有效性。
通过以上配置,我们可以有效地对Spring Cloud应用以及其他监控目标进行数据采集和存储,为后续的监控与运维工作打下良好的基础。
# 3. Grafana的安装与配置
### 3.1 Grafana的特点与优势
Grafana是一个功能强大的开源数据可视化工具,主要用于展示和分析监控指标。它支持多种数据源,包括Prometheus、InfluxDB、Elasticsearch等,可以轻松地创建仪表盘和报表,并提供丰富的图表和面板,使监控数据更加直观和易于理解。
Grafana的特点和优势包括但不限于:
- 容易安装和配置,支持主流的操作系统;
- 提供用户友好的Web界面,方便用户进行配置和操作;
- 支持多种数据源,可以集成各种监控工具和数据库;
- 提供丰富的图表和面板,可以根据需求进行自定义;
- 具备强大的查询和过滤功能,可以快速定位和分析问题;
- 支持告警功能,可以及时发现和处理异常情况;
- 提供插件机制,可以扩展功能和集成第三方工具。
### 3.2 安装Grafana服务器
Grafana的安装过程相对简单,下面以在CentOS 7系统上安装Grafana为例进行说明:
Step 1: 添加Grafana的YUM源
```shell
sudo vi /etc/yum.repos.d/grafana.repo
```
在文件中添加以下内容:
```
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
```
Step 2: 安装Grafana
```shell
sudo yum install grafana -y
```
Step 3: 启动Grafana服务
```shell
sudo systemctl enable --now grafana-server
```
### 3.3 配置Grafana的数据展示与报表
安装完成后,可以通过浏览器访问Grafana的Web界面,默认端口为3000。第一次登录时,需要设置一个新的管理员账号和密码。
登录后,可以按照以下步骤配置Grafana的数据源和仪表盘:
Step 1: 添加数据源
点击左侧菜单栏的"Configuration" -> "Data Sources",然后点击"Add data source"按钮,选择要添加的数据源类型,并填写相应的配置信息。以Prometheus为例,配置项包括URL、Access、HTTP Auth等。
Step 2: 创建仪表盘
点击左侧菜单栏的"+",
然后选择"Dashboard" -> "New Dashboard",点击"Add new panel"按钮,选择要展示的数据源和指标,并设置图表的样式和参数。
Step 3: 导入和导出仪表盘
Grafana提供了导入和导出仪表盘的功能,可以方便地分享和备份配置。在仪表盘编辑页面点击"Save As"按钮,即可导出当前仪表盘的JSON配置文件。导入仪表盘时,点击"Dashboard" -> "Import",选择导入的JSON文件,即可恢复仪表盘配置。
Grafana的配置和使用方法还有很多,可以根据实际需求进行更详细的设置和定制。
# 4. Spring Cloud应用的监控数据采集
在本章中,我们将讨论如何对Spring Cloud应用进行监控数据的采集,并将其展示在Prometheus和Grafana中。具体包括集成Prometheus客户端、定制监控指标以及数据可视化与报表展示。
#### 4.1 集成Prometheus客户端
在Spring Cloud应用中集成Prometheus客户端是收集监控数据的第一步。我们可以使用`micrometer-registry-prometheus`库来实现这一步骤。以下是一个简单的Spring Boot示例代码,展示了如何在应用中集成Prometheus客户端:
```java
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.binder.jvm.ClassLoaderMetrics;
import io.micrometer.core.instrument.binder.jvm.JvmGcMetrics;
import io.micrometer.core.instrument.binder.jvm.JvmMemoryMetrics;
import org.springframework.boot.actuate.autoconfigure.metrics.MeterRegistryCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MonitoringConfig {
@Bean
public MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags("application", "spring-cloud-app");
}
@Bean
public ClassLoaderMetrics classLoaderMetrics() {
return new ClassLoaderMetrics();
}
@Bean
public JvmMemoryMetrics jvmMemoryMetrics() {
return new JvmMemoryMetrics();
}
@Bean
public JvmGcMetrics jvmGcMetrics() {
return new JvmGcMetrics();
}
}
```
通过以上代码,我们成功集成了Prometheus客户端,并对一些JVM相关的指标进行了监控数据的采集。在实际应用中,我们还可以根据具体业务需求,采集自定义的监控指标。
#### 4.2 定制监控指标
除了默认的监控指标外,我们还可以定义和采集自定义的监控指标。以下是一个简单的示例,展示了如何定义和使用自定义的监控指标:
```java
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class CustomMetricsController {
private final Counter customCounter;
@Autowired
public CustomMetricsController(MeterRegistry registry) {
customCounter = Counter.builder("custom_counter")
.description("A custom counter")
.register(registry);
}
@GetMapping("/custom-metrics")
public String recordCustomMetric() {
customCounter.increment();
return "Custom metric recorded";
}
}
```
通过以上代码,我们定义了一个名为`custom_counter`的自定义计数器,并在接口中进行了自增操作。这样的自定义监控指标能够帮助我们更好地理解应用的运行状态。
#### 4.3 数据可视化与报表展示
通过以上步骤,我们已经成功地在Spring Cloud应用中集成了Prometheus客户端并定义了监控指标。接下来,我们可以利用Grafana来对这些数据进行可视化展示,生成丰富多样的监控报表。在Grafana中配置Prometheus数据源,并创建Dashboard,即可轻松实现监控数据的可视化展示。
通过本章的学习,我们了解了如何在Spring Cloud应用中实现监控数据的采集与展示,包括集成Prometheus客户端、定制监控指标以及数据可视化与报表展示。这些步骤将帮助我们更好地进行应用的监控与运维工作。
# 5. 运维与告警处理
运维与告警处理是Spring Cloud监控与运维的重要环节,通过对监控数据的分析与处理,可以提前发现潜在的问题并及时采取措施进行修复或优化。本章将介绍如何进行运维与告警处理,并提供相应的配置和流程示例。
#### 5.1 基于监控数据的应用运维
在监控数据采集与展示的基础上,我们可以利用这些数据进行应用运维。通过对监控指标的分析,我们可以了解应用的运行状态、性能瓶颈、资源利用情况等信息。下面是一些常见的应用运维操作:
- **性能优化**:根据监控指标的分析结果,找出应用的性能瓶颈,并采取相应的优化策略,如调整配置参数、修改代码逻辑等。
- **资源调度**:根据监控指标了解应用的资源利用情况,合理分配资源,避免资源浪费或不足。
- **故障排查**:通过监控指标的变化,定位并解决应用出现的故障问题,如内存泄漏、死锁等。
- **容量规划**:根据监控指标预测应用的容量需求,提前做好容量规划,保证应用的可用性和扩展性。
#### 5.2 告警规则的配置
为了及时发现应用故障或问题,我们需要配置告警规则。告警规则可以基于监控数据的阈值设定,当监控指标超过或低于设定的阈值时,系统会触发相应的告警动作,如发送邮件、短信或调用其他系统接口。下面是一个示例的告警规则配置:
```yaml
groups:
- name: example
interval: 1m
rules:
- alert: HighCpuUsage
expr: sum(rate(process_cpu_usage_seconds_total[5m])) / count(process_cpu_usage_seconds_total) > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: High CPU Usage
description: The average CPU usage is above 80% for the last 5 minutes.
- alert: OutOfMemory
expr: process_memory_usage_bytes > 70e6
for: 10m
labels:
severity: critical
annotations:
summary: Out of Memory
description: The memory usage is above 70MB for the last 10 minutes.
```
上述配置定义了两个告警规则,第一个规则用于检测CPU使用率高于80%的情况,第二个规则用于检测内存使用量超过70MB的情况。当这两个条件满足时,系统会触发相应的告警动作。
#### 5.3 告警通知与处理流程
在配置好告警规则后,就需要定义告警通知的方式和处理流程。通常情况下,我们会通过邮件、短信或其他方式将告警信息发送给相关的运维人员,并触发相应的处理流程。下面是一个示例的告警通知与处理流程:
1. 系统监测到告警条件满足后,触发告警动作。
2. 系统根据配置的告警通知方式,将告警信息发送给指定的运维人员。
3. 运维人员收到告警信息后,根据告警级别和紧急程度,进行相应的处理。
4. 处理流程可能包括调整资源配置、修改代码逻辑、重启应用等操作。
5. 运维人员根据处理结果,更新告警状态,并记录处理过程和结果。
通过建立完善的告警通知与处理流程,可以及时响应告警信息,提高应对故障和问题的效率。
本章介绍了运维与告警处理的重要性,并提供了配置告警规则和定义告警通知与处理流程的示例。通过合理配置和使用监控工具,可以有效提升应用的稳定性和可维护性。在下一章中,我们将分享实际的Prometheus与Grafana配置案例,并总结监控与运维的最佳实践经验。
# 6. 最佳实践与案例分析
在本章中,将通过实际案例来展示Spring Cloud监控与运维的最佳实践。我们将深入研究如何配置Prometheus与Grafana,并提供一些经验分享与未来趋势的展望。
### 6.1 实际应用中的Prometheus与Grafana配置案例
在这个案例中,假设我们正在开发一个基于Spring Cloud的微服务架构,并希望使用Prometheus和Grafana来监控和管理这些微服务。以下是配置流程的步骤:
1. 首先,我们需要在每个微服务中集成Prometheus客户端。我们可以使用Micrometer库来实现这一点。
2. 在每个微服务的配置文件中,我们需要添加Prometheus相关的配置,如指标的名称、标签等。
3. 启动Prometheus服务器,并配置数据采集的目标。我们需要指定每个微服务的端点地址,并定义采集规则。
4. 安装并配置Grafana服务器。在配置中,我们需要添加Prometheus作为数据源。
5. 创建自定义仪表板并配置图表。我们可以选择从Grafana的模板库中导入一些预定义的仪表板,然后根据需要进行调整和定制。
### 6.2 监控与运维的最佳实践经验分享
在这个章节中,我们将分享一些监控与运维的最佳实践经验,帮助您更好地利用Prometheus与Grafana。
1. 定期检查监控指标:定期检查Prometheus的指标数据,确保数据的准确性和完整性。如果出现异常情况,及时排查和解决问题。
2. 设置告警规则:根据业务需求,设置合适的告警规则。例如,设置CPU使用率超过一定阈值时触发告警,以及服务不可用时触发报警等。
3. 进行容量规划:根据监控数据分析,进行容量规划与性能优化,提前预测和处理潜在的容量问题。
4. 使用仪表板定制化:根据实际需求,定制化您的Grafana仪表板。展示您关心的指标和图表,以帮助您更好地监控和运维系统。
### 6.3 Spring Cloud监控与运维的未来趋势
随着微服务架构的广泛应用,Spring Cloud监控与运维也在不断演进和改进。以下是一些未来趋势:
1. 自动化监控:自动化监控工具的出现,将更大程度地简化和加速监控配置的过程。
2. 基于AI的运维:利用人工智能和机器学习技术,实现智能化的运维决策和自动化的故障处理。
3. 多维度监控:除了传统的系统指标和业务指标,将更多维度的监控指标纳入监控范畴,如用户行为、性能指标等。
4. 分布式跟踪与诊断:随着微服务架构的复杂性增加,分布式系统的跟踪和故障诊断将成为监控与运维的重要方向。
总结:
通过本章的案例分析和最佳实践经验分享,您可以更好地理解和应用Prometheus与Grafana来进行Spring Cloud的监控与运维。未来,随着技术的不断发展和需求的变化,监控与运维领域也将不断创新和改进。相信在不久的将来,我们将迎来更智能化、自动化和多维度的监控与运维解决方案。
参考链接:
- [Prometheus官方网站](https://prometheus.io/)
- [Grafana官方网站](https://grafana.com/)
- [Spring Cloud官方网站](https://spring.io/projects/spring-cloud)

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏旨在帮助读者领略和理解Spring Cloud微服务架构的核心概念和实践技术。从入门指南开始,详细介绍了微服务架构的基础知识和概述。接着,深入解析了Eureka服务注册与发现、Ribbon负载均衡、Zuul网关技术等核心组件。专栏还详细介绍了Spring Cloud Config的配置中心原理和实现、Feign的使用和原理解析、分布式链路追踪、消息驱动微服务等实践指南。此外,还涉及到Hystrix的熔断与降级策略、分布式系统安全架构、与Docker和Kubernetes的集成、API网关设计与应用、分布式锁实现与应用等多个主题。专栏以各个专题解析的方式,满足读者对Spring Cloud的全面了解和实战指导的需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【音频同步与编辑】:为延时作品添加完美音乐与声效的终极技巧
# 摘要
音频同步与编辑是多媒体制作中不可或缺的环节,对于提供高质量的视听体验至关重要。本论文首先介绍了音频同步与编辑的基础知识,然后详细探讨了专业音频编辑软件的选择、配置和操作流程,以及音频格式和质量的设置。接着,深入讲解了音频同步的理论基础、时间码同步方法和时间管理技巧。文章进一步聚焦于音效的添加与编辑、音乐的混合与平衡,以及音频后期处理技术。最后,通过实际项目案例分析,展示了音频同步与编辑在不同项目中的应用,并讨论了项目完成后的质量评估和版权问题。本文旨在为音频技术人员提供系统性的理论知识和实践指南,增强他们对音频同步与编辑的理解和应用能力。
# 关键字
音频同步;音频编辑;软件配置;
【软件使用说明书的可读性提升】:易理解性测试与改进的全面指南
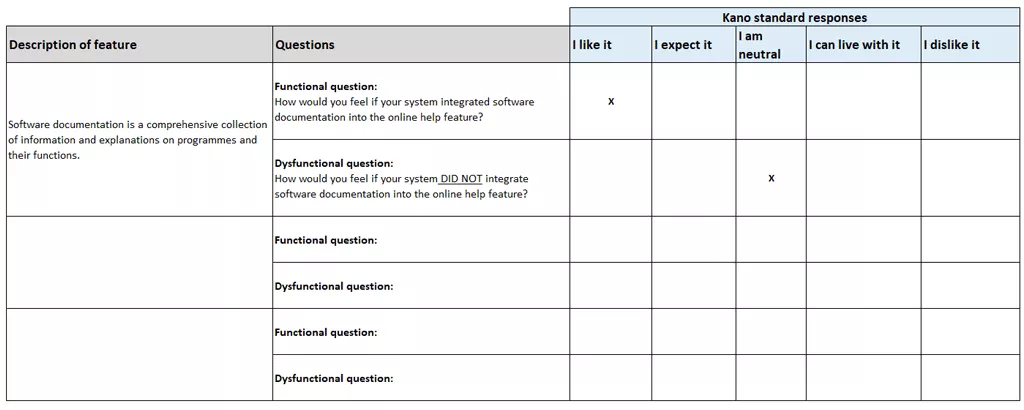
# 摘要
软件使用说明书作为用户与软件交互的重要桥梁,其重要性不言而喻。然而,如何确保说明书的易理解性和高效传达信息,是一项挑战。本文深入探讨了易理解性测试的理论基础,并提出了提升使用说明书可读性的实践方法。同时,本文也分析了基于用户反馈的迭代优化策略,以及如何进行软件使用说明书的国际化与本地化。通过对成功案例的研究与分析,本文展望了未来软件使用说明书设
PLC系统故障预防攻略:预测性维护减少停机时间的策略

# 摘要
本文深入探讨了PLC系统的故障现状与挑战,并着重分析了预测性维护的理论基础和实施策略。预测性维护作为减少故障发生和提高系统可靠性的关键手段,本文不仅探讨了故障诊断的理论与方法,如故障模式与影响分析(FMEA)、数据驱动的故障诊断技术,以及基于模型的故障预测,还论述了其数据分析技术,包括统计学与机器学习方法、时间序列分析以及数据整合与
多模手机伴侣高级功能揭秘:用户手册中的隐藏技巧
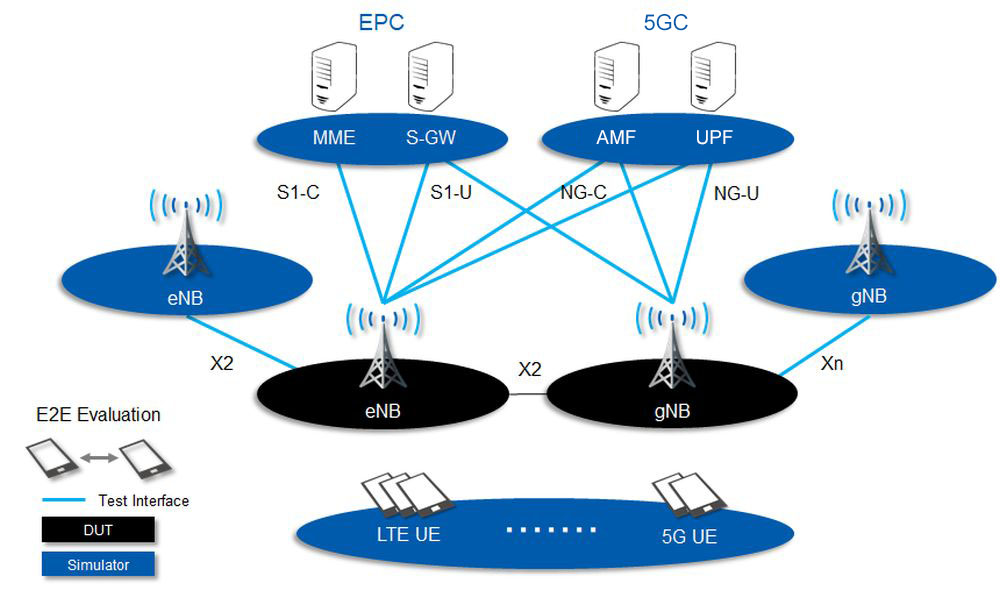
# 摘要
多模手机伴侣是一款集创新功能于一身的应用程序,旨在提供全面的连接与通信解决方案,支持多种连接方式和数据同步。该程序不仅提供高级安全特性,包括加密通信和隐私保护,还支持个性化定制,如主题界面和自动化脚本。实践操作指南涵盖了设备连接、文件管理以及扩展功能的使用。用户可利用进阶技巧进行高级数据备份、自定义脚本编写和性能优化。安全与隐私保护章节深入解释了数据保护机制和隐私管理。本文展望
数据挖掘在医疗健康的应用:疾病预测与治疗效果分析(如何通过数据挖掘改善医疗决策)

# 摘要
数据挖掘技术在医疗健康领域中的应用正逐渐展现出其巨大潜力,特别是在疾病预测和治疗效果分析方面。本文探讨了数据挖掘的基础知识及其与医疗健康领域的结合,并详细分析了数据挖掘技术在疾病预测中的实际应用,包括模型构建、预处理、特征选择、验证和优化策略。同时,文章还研究了治疗效果分析的目标、方法和影响因素,并探讨了数据隐私和伦理问题,
【实战技巧揭秘】:WIN10LTSC2021输入法BUG引发的CPU占用过高问题解决全记录

# 摘要
本文对Win10 LTSC 2021版本中出现的输入法BUG进行了详尽的分析与解决策略探讨。首先概述了BUG现象,然后通过系统资源监控工具和故障排除技术,对CPU占用过高问题进行了深入分析,并初步诊断了输入法BUG。在此基础上,本文详细介绍了通过系统更新
【大规模部署的智能语音挑战】:V2.X SDM在大规模部署中的经验与对策

# 摘要
随着智能语音技术的快速发展,它在多个行业得到了广泛应用,同时也面临着众多挑战。本文首先回顾了智能语音技术的兴起背景,随后详细介绍了V2.X SDM平台的架构、核心模块、技术特点、部署策略、性能优化及监控。在此基础上,本文探讨了智能语音技术在银行业和医疗领域的特定应用挑战,重点分析了安全性和复杂场景下的应用需求。文章最后展望了智能语音和V2.X SDM
飞腾X100+D2000启动阶段电源管理:平衡节能与性能
# 摘要
本文旨在全面探讨飞腾X100+D2000架构的电源管理策略和技术实践。第一章对飞腾X100+D2000架构进行了概述,为读者提供了研究背景。第二章从基础理论出发,详细分析了电源管理的目的、原则、技术分类及标准与规范。第三章深入探讨了在飞腾X100+D2000架构中应用的节能技术,包括硬件与软件层面的节能技术,以及面临的挑战和应对策略。第四章重点介绍了启动阶
【故障诊断与恢复】:R-Studio技术解决RAID 5数据挑战

# 摘要
RAID 5技术广泛应用于数据存储领域,提供了容错性和数据冗余,尽管如此,故障和数据丢失的风险依然存在。本文综合探讨了RAID 5的工作原理、常见故障类型、数据恢复的挑战以及R-Studio工具在数据恢复中的应用和高级功能。通过对RAID 5故障风险的分析和R-Studio使用案例的深入解析,本文旨在提供针对RAID 5数据恢复的实用知识和最佳实践,同时强调数据保护和预防措施的重要性,以增强系统稳定性并提升数据恢复效率。
【脚本与宏命令增强术】:用脚本和宏命令提升PLC与打印机交互功能(交互功能强化手册)
# 摘要
本文探讨了脚本和宏命令的基础知识、理论基础、高级应用以及在实际案例中的应用。首先概述了脚本与宏命令的基本概念、语言构成及特点,并将其与编译型语言进行了对比。接着深入分析了PLC与打印机交互的脚本实现,包括交互脚本的设计和测试优化。此外,本文还探讨了脚本与宏命令在数据库集成、多设备通信和异常处理方面的高级应用。最后,通过工业
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )