数据分区与分片机制详解
发布时间: 2024-03-01 15:04:14 阅读量: 41 订阅数: 39 

数据库的分片
# 1. 数据分区与分片机制概述
## 1.1 什么是数据分区
数据分区指的是将数据库中的数据划分为不同的区域,每个区域可以独立管理和操作。数据分区可以基于不同的规则进行,比如按照范围、哈希值或者列表进行分区。通过数据分区,可以更好地管理数据,并且提高数据的访问效率和查询性能。
## 1.2 什么是分片机制
分片机制是指将数据分散存储在不同的节点上,以实现水平扩展和负载均衡的目的。通过分片机制,可以将数据集合分解为多个片段,每个片段可以存储在不同的物理节点上,从而提高数据的存储和访问效率。
## 1.3 数据分区与分片机制的作用和应用场景
数据分区与分片机制可以帮助解决单节点存储容量有限、单节点访问性能有限的问题,特别是在大数据场景下,可以更好地应对海量数据的存储和处理需求。在分布式存储和数据库系统中广泛应用,例如分布式文件系统、NoSQL数据库等都采用了数据分区与分片机制来支撑大规模数据存储和访问需求。
# 2. 数据分区策略
在分布式系统中,数据分区策略是至关重要的一环。不同的分区策略会直接影响系统的性能、扩展性和容错性。接下来我们将介绍几种常见的数据分区策略及其应用场景。
### 2.1 基于范围的分区策略
基于范围的分区策略是指根据数据的特定范围进行分区。例如,可以根据数据的时间戳范围、字母顺序范围等将数据分配到不同的分区中。这种策略适用于数据有序且范围明确的场景,能够使得相近的数据被分配到相同的分区,提高数据访问的效率。
```python
# 以时间戳范围为例的基于范围的数据分区示例代码
def range_partition(data, start_range, end_range, num_partitions):
partition_size = (end_range - start_range) / num_partitions
partitions = []
for i in range(num_partitions):
partitions.append([])
for item in data:
partition_index = int((item - start_range) / partition_size)
partitions[partition_index].append(item)
return partitions
```
**代码总结:** 上述代码演示了如何根据时间戳范围对数据进行分区,将数据分配到不同的分区中,从而实现基于范围的分区策略。
**结果说明:** 通过基于范围的分区策略,数据被按照时间顺序合理地划分到不同的分区中,提高了数据访问的效率。
### 2.2 基于哈希的分区策略
基于哈希的分区策略是通过对数据的哈希值进行计算,然后再对分区数取模来确定数据所属的分区。这种策略适用于数据分布均匀、随机访问的场景,能够有效避免数据倾斜。
```java
// 基于哈希的数据分区示例代码
public int hashPartition(Object key, int numPartitions) {
return key.hashCode() % numPartitions;
}
```
**代码总结:** 上述Java代码演示了如何通过哈希算法将数据根据哈希值分配到不同的分区,实现基于哈希的分区策略。
**结果说明:** 基于哈希的分区策略能够有效地避免数据倾斜,保证数据在分布式系统中均匀分布。
### 2.3 基于列表的分区策略
基于列表的分区策略是通过预先定义一个分区与数据之间的映射关系表,根据这个表将数据分配到指定的分区中。这种策略适用于需要精确控制数据分布的场景,可以根据业务需求灵活地指定数据所在的分区。
```javascript
// 基于列表的数据分区示例代码
const partitionMap = {
'A': 1,
'B': 2,
'C': 3
};
function listPartition(data) {
let partitions = {};
for (let item of data) {
let partition = partitionMap[item];
if (!partitions[partition]) partitions[partition] = [];
partitions[partition].push(item);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析深度解析】:15个关键技巧让你成为数据预测大师

# 摘要
时间序列分析是处理和预测按时间顺序排列的数据点的技术。本文
【Word文档处理技巧】:代码高亮与行号排版的终极完美结合指南
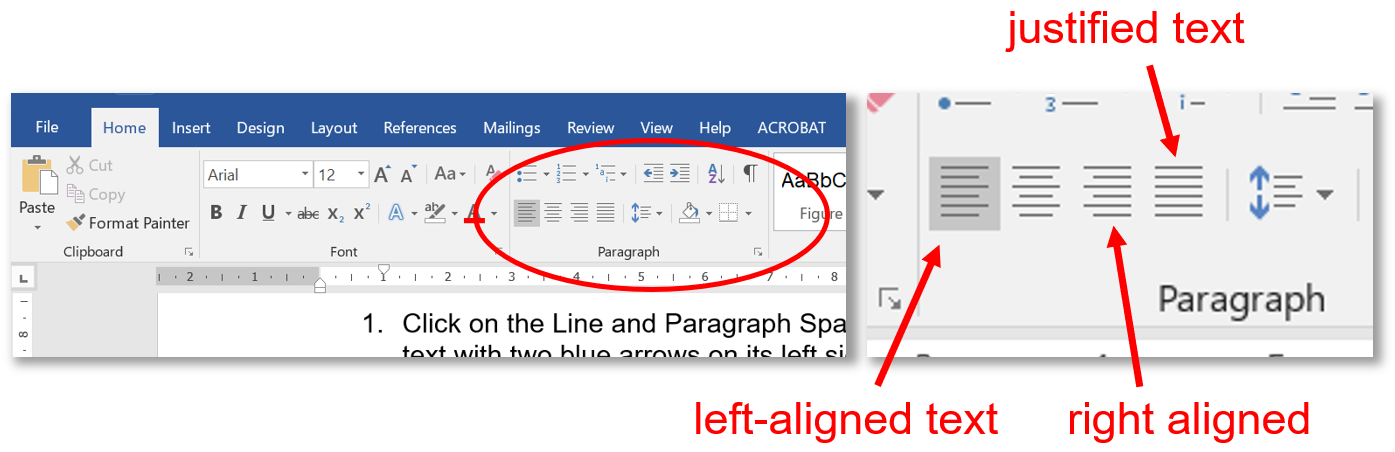
# 摘要
本文旨在为技术人员提供关于Word文档处理的深入指导,涵盖了从基础技巧到高级应用的一系列主题。首先介绍了Word文档处理的基本入门知识,然后着重讲解了代码高亮的实现方法,包括使用内置功能、自定义样式及第三方插件和宏。接着,文中详细探讨了行号排版的策略,涉及基础理解、在Word中的插入方法以及高级定制技巧。第四章讲述了如何将代码高亮与行号完美结
LabVIEW性能优化大师:图片按钮内存管理的黄金法则
# 摘要
本文围绕LabVIEW软件平台的内存管理进行深入探讨,特别关注图片按钮对象在内存中的使用原理、优化实践以及管理工具的使用。首先介绍LabVIEW内存管理的基础知识,然后详细分析图片按钮在LabVIEW中的内存使用原理,包括其数据结构、内存分配与释放机制、以及内存泄漏的诊断与预防。第三章着重于实践中的内存优化策略,包括图片按钮对象的复用、图片按钮数组与簇的内存管理技巧,以及在事件结构和循环结构中的内存控制。接着,本文讨论了LabVIEW内存分析工具的使用方法和性能测试的实施,最后提出了内存管理的最佳实践和未来发展趋势。通过本文的分析与讨论,开发者可以更好地理解LabVIEW内存管理,并
【CListCtrl行高设置深度解析】:算法调整与响应式设计的完美融合
# 摘要
CListCtrl是广泛使用的MFC组件,用于在应用程序中创建具有复杂数据的列表视图。本文首先概述了CListCtrl组件的基本使用方法,随后深入探讨了行高设置的理论基础,包括算法原理、性能影响和响应式设计等方面。接着,文章介绍了行高设置的实践技巧,包括编程实现自适应调整、性能优化以及实际应用案例分析。文章还探讨了行高设置的高级主题,如视觉辅助、动态效果实现和创新应用。最后,通过分享最佳实践与案例,本文为构建高效和响应式的列表界面提供了实用的指导和建议。本文为开发者提供了全面的CListCtrl行高设置知识,旨在提高界面的可用性和用户体验。
# 关键字
CListCtrl;行高设置
邮件排序与筛选秘籍:SMAIL背后逻辑大公开
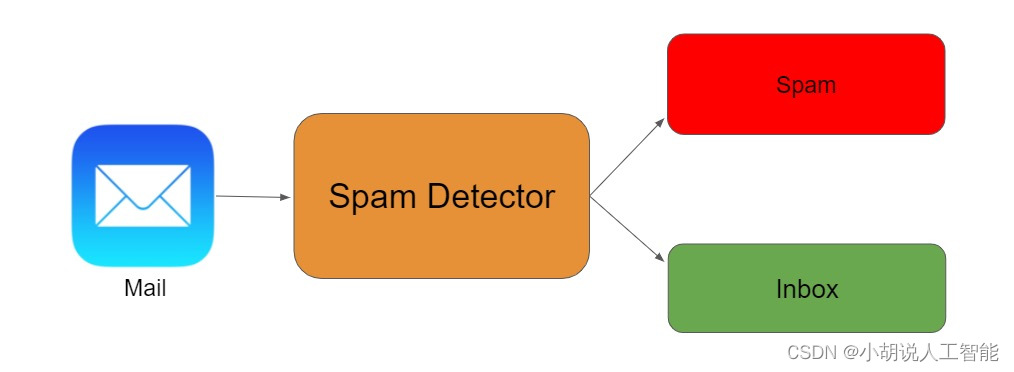
# 摘要
本文全面探讨了邮件系统的功能挑战和排序筛选技术。首先介绍了邮件系统的功能与面临的挑战,重点分析了SMAIL的排序算法,包括基本原理、核心机制和性能优化策略。随后,转向邮件筛选技术的深入讨论,包括筛选逻辑的基础构建、高级技巧和效率提升方法。文中还通过实际案例分析,展示了邮件排序与筛选在不同环境中的应用,以及个人和企业级的邮件管理策略。文章最后展望了SMAIL的未来发展趋势,包括新技术的融入和应对挑战的策
AXI-APB桥在SoC设计中的关键角色:微架构视角分析

# 摘要
本文对AXI-APB桥的技术背景、设计原则、微架构设计以及在SoC设计中的应用进行了全面的分析与探讨。首先介绍了AXI与APB协议的对比以及桥接技术的必要性和优势,随后详细解析了AXI-APB桥的微架构组件及其功能,并探讨了设计过程中面临的挑战和解决方案。在实践应用方面,本文阐述了AXI-APB桥在SoC集成、性能优化及复杂系统中的具体应用实例。此外,本文还展望了AXI-APB桥的高级功能扩展及其
CAPL脚本高级解读:技巧、最佳实践及案例应用
# 摘要
CAPL(CAN Access Programming Language)是一种专用于Vector CAN网络接口设备的编程语言,广泛应用于汽车电子、工业控制和测试领域。本文首先介绍了CAPL脚本的基础知识,然后详细探讨了其高级特性,包括数据类型、变量管理、脚本结构、错误处理和调试技巧。在实践应用方面,本文深入分析了如何通过CAPL脚本进行消息处理、状态机设计以
【适航审定的六大价值】:揭秘软件安全与可靠性对IT的深远影响
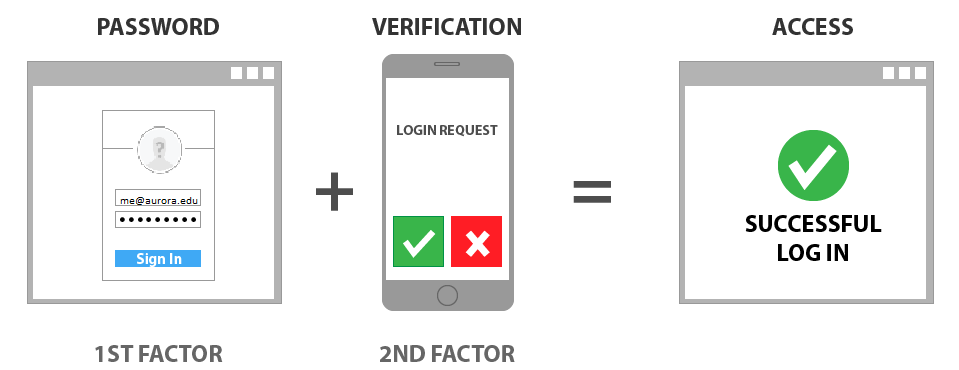
# 摘要
适航审定作为确保软件和IT系统符合特定安全和可靠性标准的过程,在IT行业中扮演着至关重要的角色。本文首先概述了适航审定的六大价值,随后深入探讨了软件安全性与可靠性的理论基础及其实践策略,通过案例分析,揭示了软件安全性与可靠性提升的成功要素和失败的教训。接着,本文分析了适航审定对软件开发和IT项目管理的影响,以及在遵循IT行业标准方面的作用。最后,展望了适航审定在
CCU6定时器功能详解:定时与计数操作的精确控制

# 摘要
CCU6定时器是工业自动化和嵌入式系统中常见的定时器组件,本文系统地介绍了CCU6定时器的基础理论、编程实践以及在实际项目中的应用。首先概述了CCU
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )