使用Kafka进行实时数据处理
发布时间: 2024-01-10 19:48:55 阅读量: 46 订阅数: 23 

大数据之Kafka
# 1. Kafka简介与概述
Kafka作为一个分布式流处理平台,扮演了重要的角色,在实时数据处理领域发挥着不可替代的作用。本章将对Kafka进行基本介绍,包括其定义、特点、优势以及在实时数据处理中的作用。
## 1.1 什么是Kafka
Kafka是由LinkedIn开发的一个分布式的消息引擎,最初是用于LinkedIn的活动流(Activity Stream)和运营数据处理平台。它是一种高吞吐量的分布式发布订阅消息系统,具有持久性、可靠性、扩展性等特点。
## 1.2 Kafka的特点和优势
Kafka具有许多特点和优势,包括高性能、水平扩展、持久性、可靠性、容错性、流式处理等。这些特点使得Kafka成为流处理领域的瑞士军刀。
## 1.3 Kafka在实时数据处理中的作用
Kafka作为一个分布式流处理平台,在实时数据处理中发挥着重要作用。它可以用作消息队列、缓冲、分发、存储等多种用途,为实时数据处理提供了强大的支持。
接下来,我们将深入探讨Kafka的基础知识与架构。
# 2. Kafka基础知识与架构
Kafka是一个分布式事件流处理平台,具有高可靠性、高吞吐量的特点。在本章节中,我们将介绍Kafka的基础知识和架构,包括Kafka的基本概念和术语解释,Kafka的架构和组件,以及Kafka的工作原理和数据传输流程。
### 2.1 Kafka的基本概念和术语解释
在Kafka中,有一些基本概念和术语需要我们了解:
- **消息(Message)**:Kafka中的基本数据单元,以字节数组的形式存储。
- **主题(Topic)**:消息的分类,生产者将消息发送到主题,消费者从主题订阅消息。
- **分区(Partition)**:每个主题可以分割成多个分区,分区是消息的最小单元存储单位,可以并行处理。
- **偏移量(Offset)**:每个分区中的消息都有一个唯一的偏移量,用来标识消息在分区中的位置,消费者可以通过偏移量控制消息的消费位置。
- **生产者(Producer)**:负责向Kafka broker发送消息。
- **消费者(Consumer)**:从Kafka broker订阅和消费消息。
### 2.2 Kafka的架构和组件
Kafka的架构主要包括以下几个关键组件:
- **Broker**:Kafka集群中的每个节点称为Broker,负责消息的存储和转发。
- **ZooKeeper**:Kafka使用ZooKeeper来进行元数据(如主题、分区、消费者组等)的管理和协调。
- **生产者API**:允许应用程序发布消息到一个或多个主题。
- **消费者API**:允许应用程序订阅一个或多个主题,并处理其中的消息。
- **Connect API**:用于构建和运行可重用的生产者或消费者连接器,将Kafka连接到现有应用程序或数据系统。
### 2.3 Kafka的工作原理和数据传输流程
Kafka的工作原理主要包括生产者将消息发送到Kafka集群中的Topic,消息被划分到不同的分区,每个分区中的消息根据偏移量进行顺序存储。消费者可以以分区的形式订阅消息,并通过偏移量进行消息的消费。一旦消息被消费者消费,Kafka会记录消费者的偏移量。
Kafka的数据传输流程可以简述为:生产者发送消息到Topic,消息存储在分区中,消费者从分区订阅消息并进行消费,消费者偏移量随着消息的消费进行实时跟新。
在下一章节中,我们将学习如何搭建Kafka环境并进行配置。
# 3. 搭建Kafka环境与配置
在本章中,我们将详细介绍如何搭建Kafka环境并进行配置。
#### 3.1 Kafka的安装和部署
首先,我们需要下载Kafka的安装包并解压。
```bash
$ wget https://archive.apache.org/dist/kafka/2.8.0/kafka_2.13-2.8.0.tgz
$ tar -xzf kafka_2.13-2.8.0.tgz
$ cd kafka_2.13-2.8.0
```
接下来,我们需要进行一些配置。
在Kafka的安装目录下,可以找到`config`文件夹,其中有两个关键的配置文件需要注意:
- `server.properties`:Kafka的服务端配置文件,包含了Kafka的基本配置信息。
- `producer.properties`:Kafka的生产者配置文件,用于配置数据生产者相关的属性。
我们可以根据自己的需求修改这些配置文件,例如更改Kafka的监听端口、增加分区数等。
首先,编辑`server.properties`文件:
```bash
$ vi config/server.properties
```
找到以下配置项,并修改为合适的值:
```properties
# 监听地址和端口
listeners=PLAINTEXT://localhost:9092
# 日志目录
log.dirs=/tmp/kafka-logs
# 分区数
num.partitions=3
```
同样地,我们可以编辑`producer.properties`文件:
```bash
$ vi config/producer.properties
```
找到以下配置项,并修改为合适的值:
```properties
# Kafka服务地址和端口
bootstrap.servers=localhost:9092
# 等待所有副本节点应答的最大时间
acks=all
# 缓冲区大小
buffer.memory=33554432
# 批处理大小
batch.size=16384
```
#### 3.2 集群配置与优化
如果你想要搭建一个Kafka集群,可以按照以下步骤进行配置。
首先,每个Kafka节点的`server.properties`文件中需要保持一致的配置,例如`broker.id`、`log.dirs`等。
接下来,编辑`server.properties`文件,新增以下配置项:
```bash
$ vi config/server.properties
```
```properties
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入解析大数据处理中的关键技术之一:Kafka。首先从什么是Kafka以及其在大数据中的作用入手,详细介绍了Kafka的基本概念和架构,并深入探讨了使用Kafka进行简单消息传递的方法。随后,针对Kafka生产者和消费者的创建与配置展开讨论,掌握Kafka消息传递保证机制和实现消息批处理与分区的技巧,以及消息压缩和高级消息路由等高级应用。此外,还涵盖了Kafka的事务处理、幂等性、流处理、数据集成、数据复制、性能调优以及与其他大数据工具的集成等内容。最后,还讨论了在事件驱动架构和微服务架构中使用Kafka进行异步通信的实现方法。通过本专栏的学习,读者能够全面掌握Kafka的原理、应用和最佳实践,为大数据处理提供重要参考和指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java代码审计核心教程】:零基础快速入门与进阶策略
-Concept-in-Java.webp)
# 摘要
Java代码审计是保障软件安全性的重要手段。本文系统性地介绍了Java代码审计的基础概念、实践技巧、实战案例分析、进阶技能提升以及相关工具与资源。文中详细阐述了代码审计的各个阶段,包括准备、执行和报告撰写,并强调了审计工具的选择、环境搭建和结果整理的重要性。结合具体实战案例,文章
【Windows系统网络管理】:IT专家如何有效控制IP地址,3个实用技巧

# 摘要
本文主要探讨了Windows系统网络管理的关键组成部分,特别是IP地址管理的基础知识与高级策略。首先概述了Windows系统网络管理的基本概念,然后深入分析了IP地址的结构、分类、子网划分和地址分配机制。在实用技巧章节中,我们讨论了如何预防和解决IP地址冲突,以及IP地址池的管理方法和网络监控工具的使用。之后,文章转向了高级
【技术演进对比】:智能ODF架与传统ODF架性能大比拼

# 摘要
随着信息技术的快速发展,智能ODF架作为一种新型的光分配架,与传统ODF架相比,展现出诸多优势。本文首先概述了智能ODF架与传统ODF架的基本概念和技术架构,随后对比了两者在性能指标、实际应用案例、成本与效益以及市场趋势等方面的不同。智能ODF架通过集成智能管理系统,提高了数据传输的高效性和系统的可靠性,同时在安全性方面也有显著增强。通过对智能ODF架在不同部署场景中的优势展示和传统ODF架局限性的分析,本文还探讨
化工生产优化策略:工业催化原理的深入分析
# 摘要
本文综述了化工生产优化的关键要素,从工业催化的基本原理到优化策略,再到环境挑战的应对,以及未来发展趋势。首先,介绍了化工生产优化的基本概念和工业催化理论,包括催化剂的设计、选择、活性调控及其在工业应用中的重要性。其次,探讨了生产过程的模拟、流程调整控制、产品质量提升的策略和监控技术。接着,分析了环境法规对化工生产的影响,提出了能源管理和废物处理的环境友好型生产方法。通过案例分析,展示了优化策略在多相催化反应和精细化工产品生产中的实际应用。最后,本文展望了新型催化剂的开发、工业4.0与智能化技术的应用,以及可持续发展的未来方向,为化工生产优化提供了全面的视角和深入的见解。
# 关键字
MIPI D-PHY标准深度解析:掌握规范与应用的终极指南
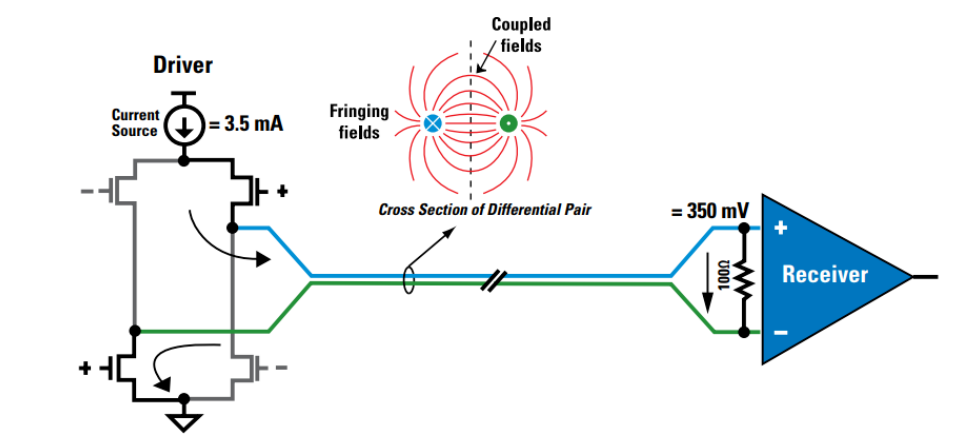
# 摘要
MIPI D-PHY作为一种高速、低功耗的物理层通信接口标准,广泛应用于移动和嵌入式系统。本文首先概述了MIPI D-PHY标准,并深入探讨了其物理层特性和协议基础,包括数据传输的速率、通道配置、差分信号设计以及传输模式和协议规范。接着,文章详细介绍了MIPI D-PHY在嵌入式系统中的硬件集成、软件驱动设计及实际应用案例,同时提出了性能测试与验
【SAP BASIS全面指南】:掌握基础知识与高级技能

# 摘要
SAP BASIS是企业资源规划(ERP)解决方案中重要的技术基础,涵盖了系统安装、配置、监控、备份、性能优化、安全管理以及自动化集成等多个方面。本文对SAP BASIS的基础配置进行了详细介绍,包括系统安装、用户管理、系统监控及备份策略。进一步探讨了高级管理技
【Talend新手必读】:5大组件深度解析,一步到位掌握数据集成
# 摘要
Talend是一款强大的数据集成工具,本文首先介绍了Talend的基本概念和安装配置方法。随后,详细解读了Talend的基础组件,包括Data Integration、Big Data和Cloud组件,并探讨了各自的核心功能和应用场景。进阶章节分析了Talend在实时数据集成、数据质量和合规性管理以及与其他工
网络安全新策略:Wireshark在抓包实践中的应用技巧

# 摘要
Wireshark作为一款强大的网络协议分析工具,广泛应用于网络安全、故障排除、网络性能优化等多个领域。本文首先介绍了Wireshark的基本概念和基础使用方法,然后深入探讨了其数据包捕获和分析技术,包括数据包结构解析和高级设置优化。文章重点分析了Wireshark在网络安全中的应用,包括网络协议分析、入侵检测与响应、网络取证与合规等。通过实
三角形问题边界测试用例的测试执行与监控:精确控制每一步

# 摘要
本文针对三角形问题的边界测试用例进行了深入研究,旨在提升测试用例的精确性和有效性。文章首先概述了三角形问题边界测试用例的基础理论,包括测试用例设计原则、边界值分析法及其应用和实践技巧。随后,文章详细探讨了三角形问题的定义、分类以及测试用例的创建、管理和执行过程。特别地,文章深入分析了如何控制测试环境与用例的精确性,并探讨了持续集成与边界测试整合的可能性。在测试结果分析与优化方面,本文提出了一系列故障分析方法和测试流程改进策略。最后,文章展望了边界
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )