Kafka消息分区与负载均衡策略解析
发布时间: 2024-02-16 10:56:55 阅读量: 45 订阅数: 24 

Kafka分区策略浅谈
# 1. Kafka消息分区基础
## 1.1 什么是Kafka消息分区
Kafka中的消息分区是指将消息分发到不同的物理存储节点上,每个分区对应一个文件夹,每个文件夹包含多个日志片段(segment)文件。消息被顺序追加到分区的日志末尾,这些日志片段文件按照一定的策略进行滚动和删除,从而实现消息的持久化和删除操作。
## 1.2 Kafka消息分区的作用和优势
消息分区可以实现水平扩展,提高Kafka集群的吞吐量和容量;同时,消息分区也可以提供消息的并行消费和负载均衡,帮助实现高性能的消息传输系统;此外,Kafka消息分区还可以保证消息的顺序性和可靠性,提供副本机制实现数据的备份和容错。
## 1.3 Kafka消息分区的工作原理
Kafka消息分区的工作原理是基于一定的分区策略,通过计算消息的key或者使用Round-robin等算法,将消息分发到不同的分区中,然后每个消费者根据分配的分区进行消息的消费和处理。在Kafka中,可以为主题指定分区数量,也可以自定义分区策略。
接下来,我们将分别介绍Kafka消息分区策略和负载均衡策略,帮助读者更好地理解Kafka消息分区与负载均衡的相关知识。
# 2. Kafka消息分区策略
在Kafka中,消息的生产者在将消息发送到topic时,需要确定消息被发送到哪个分区。Kafka提供了多种消息分区策略,可以根据业务需求选择合适的策略进行消息分区。
### 2.1 基于Key的分区策略
基于Key的分区策略是根据消息的Key来确定消息被发送到哪个分区。Kafka通过对Key进行hash或其他算法计算,将相同Key的消息发送到相同的分区,这样能确保具有相同Key的消息被顺序处理,保证了消息的顺序性。但是如果Key的分布不均匀,就会导致消息不均衡地分布到各个分区,进而影响负载均衡。
以下是基于Key的分区策略的Java示例代码:
```java
ProducerRecord<String, String> record = new ProducerRecord<>("topicName", "key", "value");
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.println("Sent record to partition " + metadata.partition());
}
}
});
```
**代码总结:** 通过指定消息的Key,可以将消息发送到指定的分区,保证具有相同Key的消息被发送到同一个分区。
**结果说明:** 使用基于Key的分区策略可以保证具有相同Key的消息被发送到同一个分区,从而保证了消息的顺序性。
### 2.2 基于Round-robin的分区策略
基于Round-robin的分区策略是简单均匀地轮流将消息发送到不同的分区,以达到负载均衡的目的。这种策略是Kafka默认的分区策略,适合于没有特殊需求的场景。
以下是基于Round-robin的分区策略的Python示例代码:
```python
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# 指定topic名称和消息内容
topic = 'topicName'
messages = [b'message1', b'message2', b'message3']
# 发送消息
for message in messages:
producer.send(topic, message)
producer.close()
```
**代码总结:** 使用KafkaProducer发送消息时,如果未指定分区策略,则默认采用基于Round-robin的分区策略,轮流将消息发送到不同的分区。
**结果说明:** 基于Round-robin的分区策略能够将消息均匀地发送到不同的分区,实现了负载均衡。
### 2.3 自定义分区策略
除了Kafka提供的默认分区策略外,用户还可以自定义分区策略,根据业务需求来确定消息被发送到哪个分区。自定义分区策略通常需要实现org.apache.kafka.clients.producer.Partitioner接口,重写partition方法来指定消息的分区。
以下是自定义分区策略的Java示例代码:
```java
public class CustomPartitioner implements org.apache.kafka.clients.producer.Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 根据业务逻辑计算分区号
int partition = ...;
return partition;
}
public void close() {}
public void configure(Map<String, ?> configs) {}
}
```
**代码总结:** 用户可以自定义实现Partitioner接口,根据业务需求来确定消息被发送到哪个分区。
**结果说明:** 自定义分区策

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《大数据工具Kafka详解》旨在帮助读者深入了解Kafka的基本概念、架构以及各种功能和应用。文章从入门指南开始,解释了Kafka的核心概念和架构,接着详细讲解了如何使用生产者发送和处理消息,以及如何使用消费者进行数据消费和偏移量管理。此外,本专栏还介绍了Kafka的消息存储与日志刷写机制、消息格式与压缩优化、消息分区与负载均衡策略等内容。此外,专栏还重点介绍了Kafka的连接器、监控与性能调优、数据流处理、管理工具以及其与大数据生态系统如Hadoop、Spark的集成,以及与容器化环境和微服务架构的结合。通过阅读本专栏,读者可以全面了解Kafka的原理和实践,为使用和管理Kafka集群提供了有价值的指导和参考。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
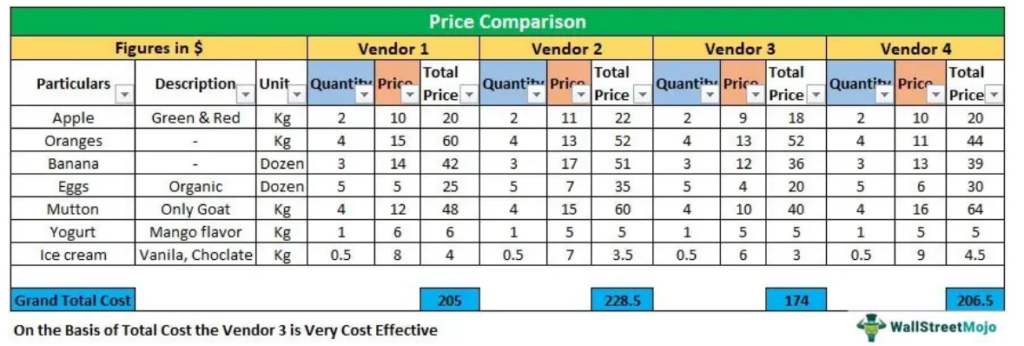
SAPSD定价策略深度剖析:成本加成与竞对分析,制胜关键解读
# 摘要
本文首先概述了SAPSD定价策略的基础概念,随后详细介绍了成本加成定价模型的理论和计算方法,包括成本构成分析、利润率设定及成本加成率的计算。文章进一步探讨了如何通过竞争对手分析来优化定价策略,并提出了基于市场定位的定价方法和应对竞争对手价格变化的策略。通过实战案例研究,本文分析了成本加成与市场适应性策略的实施效果,以及竞争对手分析在案例中的应用。最后,探
【指纹模组选型秘籍】:关键参数与性能指标深度解读
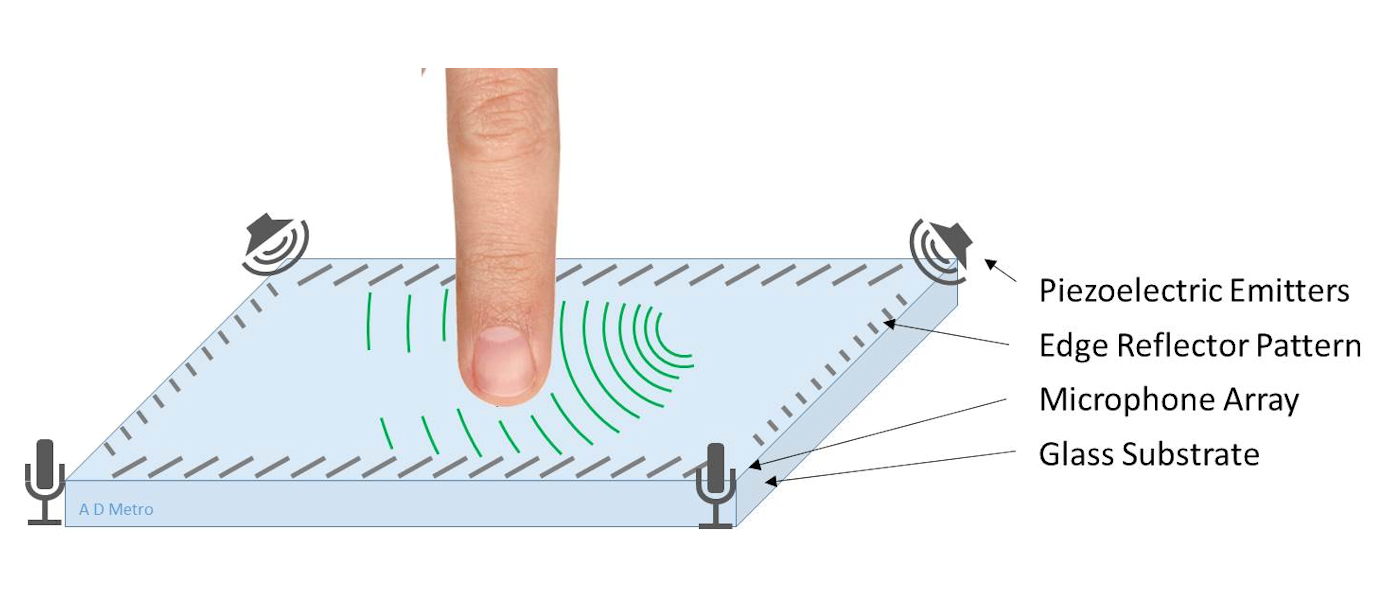
# 摘要
本文系统地介绍了指纹模组的基础知识、关键技术参数、性能测试评估方法,以及选型策略和市场趋势。首先,详细阐述了指纹模组的基本组成部分,如传感器技术参数、识别算法及其性能、电源与接口技术等。随后,文章深入探讨了指纹模组的性能测试流程、稳定性和耐用性测试方法,并对安全性标准和数据保护进行了评估。在选型实战指南部分,根据不同的应用场景和成本效益分析,提供了模组选择的实用指导。最后,
凌华PCI-Dask.dll全解析:掌握IO卡编程的核心秘籍(2023版)
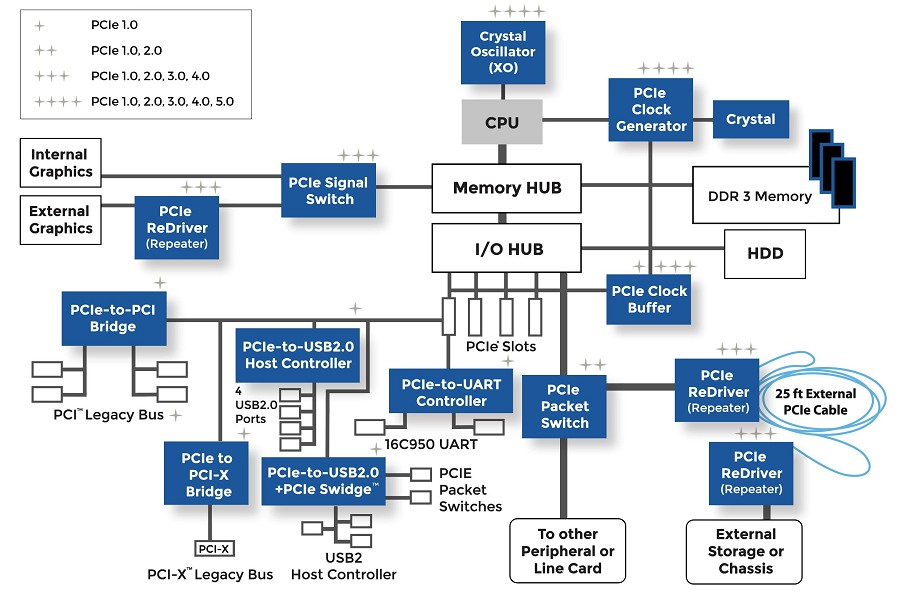
# 摘要
凌华PCI-Dask.dll是一个专门用于数据采集与硬件控制的动态链接库,它为开发者提供了一套丰富的API接口,以便于用户开发出高效、稳定的IO卡控制程序。本文详细介绍了PCI-Dask.dll的架构和工作原理,包括其模块划分、数据流缓冲机制、硬件抽象层、用户交互数据流程、中断处理与同步机制以及错误处理机制。在实践篇中,本文阐述了如何利用PCI-Dask.dll进行IO卡编程,包括AP
案例分析:MIPI RFFE在实际项目中的高效应用攻略

# 摘要
本文全面介绍了MIPI RFFE技术的概况、应用场景、深入协议解析以及在硬件设计、软件优化与实际项目中的应用。首先概述了MIPI RFFE技术及其应用场景,接着详细解析了协议的基本概念、通信架构以及数据包格式和传输机制。随后,本文探讨了硬件接口设计要点、驱动程序开发及芯片与传感器的集成应用,以及软件层面的协议栈优化、系统集成测试和性能监控。最后,文章通过多个项目案例,分析了MIPI RF
Geolog 6.7.1高级日志处理:专家级功能优化与案例研究
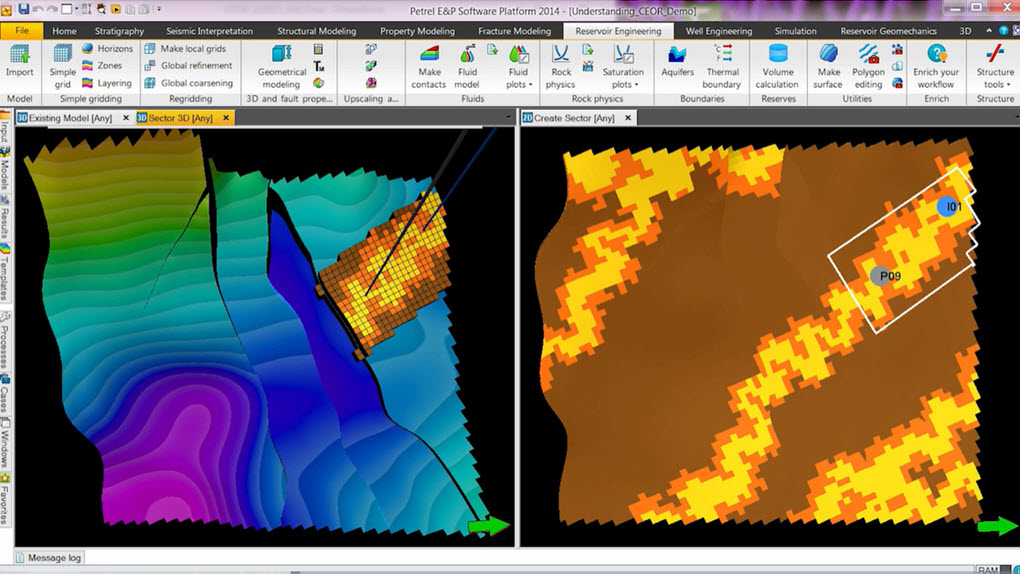
# 摘要
本文全面介绍了Geolog 6.7.1版本,首先提供了该软件的概览,接着深入探讨了其高级日志处理、专家级功能以及案例研究,强调了数据过滤、索引、搜索和数据分析等关键功能。文中分析了如何通过优化日志处理流程,解决日志管理问题,以及提升日志数据分析的价值。此外,还探讨了性能调优的策略和维护方法。最后,本文对Geolog的未来发展趋势进行了展望,包括新版本
ADS模型精确校准:掌握电感与变压器仿真技术的10个关键步骤

# 摘要
本文全面介绍了ADS模型精确校准的理论基础与实践应用。首先概述了ADS模型的概念及其校准的重要性,随后深入探讨了其与电感器和变压器仿真原理的基础理论,详细解释了相关仿真模型的构建方法。文章进一步阐述了ADS仿真软件的使用技巧,包括界面操作和仿真模型配置。通过对电感器和变压器模型参数校准的具体实践案例分析,本文展示了高级仿真技术在提高仿真准确性中的应用,并验证了仿真结果的准确性。最后
深入解析华为LTE功率控制:掌握理论与实践的完美融合

# 摘要
本文对LTE功率控制的技术基础、理论框架及华为在该领域的技术应用进行了全面的阐述和深入分析。首先介绍了LTE功率控制的基本概念及其重要性,随后详细探
【Linux故障处理攻略】:从新手到专家的Linux设备打开失败故障解决全攻略
# 摘要
本文系统介绍了Linux故障处理的基本概念,详细分析了Linux系统的启动过程,包括BIOS/UEFI的启动机制、内核加载、初始化进程、运行级和
PLC编程新手福音:入门到精通的10大实践指南

# 摘要
本文旨在为读者提供一份关于PLC(可编程逻辑控制器)编程的全面概览,从基础理论到进阶应用,涵盖了PLC的工作原理、编程语言、输入输出模块配置、编程环境和工具使用、项目实践以及未来趋势与挑战。通过详细介绍PLC的硬件结构、常用编程语言和指令集,文章为工程技术人员提供了理解和应用PLC编程的基础知识。此外,通过对PLC在自动化控制项目中的实践案例分析,本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )