ggseas包深度解读:24小时精通时间序列处理与可视化
发布时间: 2024-11-07 21:26:43 阅读量: 32 订阅数: 26 
# 1. 时间序列基础知识概述
时间序列分析是预测未来的重要手段,广泛应用于金融、经济、气象、工程等领域。它基于历史数据来识别数据随时间变化的模式,并用这些模式来预测未来趋势。时间序列的关键组成部分包括趋势(长期增长或下降)、季节性(周期性波动)和随机波动(不可预测的随机变化)。
在时间序列分析中,有几种常见的模型,如自回归模型(AR)、移动平均模型(MA)和自回归移动平均模型(ARMA)。在进入高级分析之前,理解和识别这些基本组成部分至关重要。接下来的章节中,我们将深入探讨如何使用ggseas包在R语言中操作时间序列数据,从而进行更高级的数据分析和可视化。
# 2. ggseas包的安装与基础使用
安装和加载一个包是使用任何R语言库的第一步。ggseas包是基于ggplot2扩展包的一系列函数,它提供了额外的时间序列数据处理和可视化方法。本章将详细介绍如何安装ggseas包,加载它,以及展示它的基础功能和应用场景。
## 2.1 ggseas包的安装和加载
### 2.1.1 ggseas包的安装方式
ggseas包可以通过CRAN(Comprehensive R Archive Network)进行安装,它是最稳定和最推荐的安装方式。安装包的R代码非常简单:
```R
install.packages("ggseas")
```
如果您需要安装开发版本,也可以直接从GitHub克隆:
```R
if (!requireNamespace("devtools", quietly = TRUE))
install.packages("devtools")
devtools::install_github("elliottshore/ggseas")
```
### 2.1.2 ggseas包的加载方法
安装完毕后,加载ggseas包以便使用:
```R
library(ggseas)
```
加载包之后,就可以访问ggseas的所有功能。加载包是通过`library`函数完成的,它使得包中所有的函数和数据集都可供当前R会话使用。
## 2.2 ggseas的基础功能和应用场景
### 2.2.1 ggseas包中的函数分类
ggseas包中的函数主要可以分为以下几个类别:
- 时间序列分解函数,比如`ggsdc()`,用于分解时间序列。
- 时序数据转换函数,如`ggseasonplot()`,用于绘制季节图。
- 描述统计函数,比如`ggAcf()`和`ggPacf()`,用于绘制自相关和偏自相关图。
- 数据绘图函数,如`ggsubseriesplot()`,用于绘制子序列图。
### 2.2.2 时间序列数据的基本处理方法
时间序列数据通常需要进行一些基本的处理,比如数据清洗、数据转换等。ggseas包提供了几个便利的函数来帮助用户轻松进行这些操作。例如,使用`ggsdc()`函数可以分解时间序列数据:
```R
# 假设df是一个包含时间序列数据的数据框
decomposed <- ggsdc(df, type = "additive", series = "y")
```
在这里,`type`参数指定了分解的类型(加法或乘法),`series`参数指定了数据框中哪一列是时间序列数据。
### 2.2.3 时间序列可视化的基本技巧
ggseas包极大地扩展了ggplot2在时间序列可视化方面的能力。通过ggseas,可以方便地创建季节性图表、子序列图表、自相关和偏自相关图等。例如,要创建一个季节性图表,可以使用以下命令:
```R
ggseasonplot(AirPassengers, year.labels=TRUE) +
theme(legend.position="none")
```
这里`AirPassengers`是一个内置的R数据集,`theme`函数用于去除图例。
### 2.2.4 ggseas应用案例
为了更深入地了解ggseas的应用,让我们通过一个案例来展示它的功能。我们将使用ggseas包中的函数来分析一个实际的时间序列数据集,并展示它的可视化技巧。
首先,读取一个CSV格式的时间序列数据文件:
```R
library(readr)
data <- read_csv("path_to_your_time_series_data.csv")
```
然后,进行数据的初步可视化:
```R
library(ggplot2)
library(ggseas)
ggplot(data, aes(x = time, y = value)) +
geom_line() +
ggseas::stat_subset(aes(subset = value > quantile(value, 0.75)),
fill = "red", alpha = 0.5)
```
以上代码中,`geom_line()`用于绘制时间序列的线图。`stat_subset()`是ggseas中的一个函数,用于在图中突出显示特定的子集,这里它被用来高亮显示高于第三个四分位数的时间序列值。
通过这个案例,我们可以看到ggseas包如何帮助我们进行时间序列数据的探索性分析和可视化。在后续章节中,我们将继续深入探讨ggseas在时间序列分析中的高级应用。
# 3. ggseas在时间序列分析中的应用
在第二章中,我们已经了解了如何安装和使用ggseas包,以及它在时间序列数据处理和基本可视化方面的能力。现在,我们将深入探讨ggseas在时间序列分析中的各种应用,包括数据的探索性分析、高级处理技术和与其他包的集成使用。
## 3.1 时间序列数据的探索性分析
### 3.1.1 数据分布的图形表示
探索性分析是数据分析中的第一步,它可以帮助我们了解数据的基本特征,如分布、趋势和季节性等。ggseas包中的函数可以生成多种图形,帮助我们直观地表示数据分布。
首先,我们可以使用`ggplot()`函数和`geom_histogram()`来创建直方图,以可视化数据的分布情况。
```r
library(ggplot2)
library(ggseas)
# 假设我们有一个名为time_series_data的时间序列数据集
ggplot(time_series_data, aes(x=value)) +
geom_histogram(binwidth=1, fill="blue", color="black") +
labs(title="数据分布直方图", x="值", y="频率")
```
在上述代码中,`binwidth`参数用于设置直方图的桶宽,`fill`和`color`参数用于设置直方图的颜色。直方图可以展示出数据在不同值区间的分布情况,帮助我们了解数据是否呈现某种特定的分布形态。
接下来,`ggdensity()`函数可以生成密度图,用于更平滑地表示数据的分布状态。
```r
ggdensity(time_series_data$value) +
labs(title="数据分布密度图", x="值", y="密度")
```
密度图通过平滑的方式展示数据的分布,有助于我们发现数据中的峰值和低谷,从而进一步推断数据的潜在分布特征。
### 3.1.2 时间序列的趋势和季节性分析
时间序列数据通常会表现出一定的趋势和季节性特征,识别这些特征对于预测未来走势至关重要。
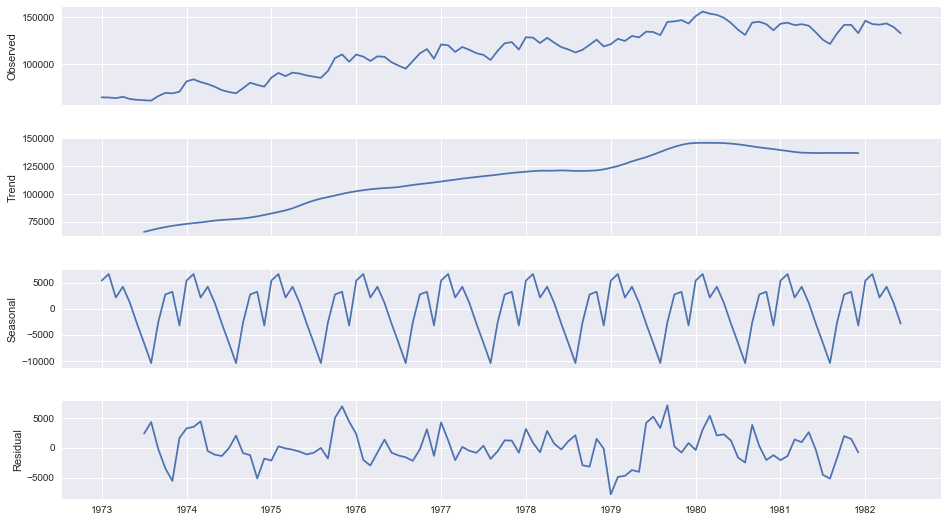
我们可以使用ggseas包中的`ggsdc()`函数来绘制季节性分解图。
```r
ggsdc(time_series_data, aes(x=时间, y=值)) +
labs(title="时间序列的季节性分解", x="时间", y="值")
```
上述代码中,`ggsdc()`函数将自动对时间序列数据进行季节性分解,并展示出趋势(Trend)、季节性(Seasonal)和随机性(Random)三个组成部分。这有助于我们理解数据中的周期性波动模式。
此外,通过分析这些组成部分,我们可以更准确地进行未来值的预测。
## 3.2 时间序列数据的高级处理技术
### 3.2.1 差分和转换处理
时间序列数据往往需要经过一些数学变换以变得平稳,差分(Differencing)和转换(Transformation)就是常见的处理技术。
差分操作通过计算当前数据点和前一个数据点之间的差异,来减少时间序列中的趋势成分。在R中,我们可以使用`diff()`函数对数据进行差分。
```r
# 一阶差分
time_series_data$diff1 <- diff(time_series_data$value)
# 二阶差分(如果需要)
time_series_data$diff2 <- diff(time_series_data$diff1)
# 绘制差分后的数据图表,以判断平稳性
ggplot(time_series_data, aes(x=时间, y=diff1)) +
geom_line(color="red") +
labs(title="时间序列的一阶差分图", x="时间", y="一阶差分值")
```
在上述代码中,`diff()`函数计算了数据的一阶差分和二阶差分,并将结果存储在新的数据列中。通过绘制差分后的图表,我们可以观察数据是否变得更加平稳。
### 3.2.2 平滑和预测方法
当时间序列数据包含随机波动时,使用平滑方法可以减少这种波动,使长期趋势更加明显。ggseas包提供了一系列的平滑和预测方法。
例如,简单的移动平均法(Moving Average)可以通过`movav()`函数实现。
```r
time_series_data$movav <- movav(time_series_data$value, n=3)
ggplot(time_series_data, aes(x=时间, y=value)) +
geom_line(color="blue") +
geom_line(aes(y=movav), color="red") +
labs(title="移动平均与原始数据对比图", x="时间", y="值")
```
在上述代码中,`movav()`函数计算了长度为3的移动平均值,通过与原始数据的对比,我们可以看到平滑效果。
此外,还可以使用指数平滑(Exponential Smoothing)等更高级的技术进行预测。这些技术通常涉及到模型的参数优化,可通过ggseas与其他统计包(如forecast)的集成使用来完成。
## 3.3 ggseas与其他包的集成使用
### 3.3.1 ggseas与xts包的结合
在时间序列分析中,xts包是非常流行的,因为它提供了灵活且强大的时间序列数据对象类型。ggseas包可以很容易地与xts对象一起工作。
首先,你需要安装并加载xts包:
```r
install.packages("xts")
library(xts)
```
接下来,你可以将一个普通的数据框(data.frame)转换为xts对象,然后使用ggseas包中的函数进行操作。
```r
# 假设time_series_data是ggseas包中的数据集
xts_data <- xts(x=time_series_data$value, order.by=time_series_data$时间)
# 使用ggplot2和ggseas的函数绘制xts对象的图表
ggplot(data.frame(xts_data), aes(x=index(xts_data), y=coredata(xts_data))) +
geom_line() +
labs(title="使用ggplot2和ggseas绘制xts对象的图表", x="时间", y="值")
```
在上述代码中,我们使用`xts_data`作为输入,`ggplot()`函数能够识别xts对象并绘制出时间序列图。
### 3.3.2 ggseas在金融数据分析中的应用
金融数据分析是一个特定领域,其中时间序列分析尤为关键。ggseas包在这一领域的应用包括但不限于绘制股票价格图表、收益率曲线和其他金融市场指标。
例如,我们可以使用ggseas包绘制股票价格的日K线图。
```r
# 假设我们有股票价格数据,包括开盘价(open)、最高价(high)、最低价(low)、收盘价(close)
stocks_data <- data.frame(
date=as.Date(1:100, origin="2020-01-01"),
open=runif(100, min=100, max=200),
high=runif(100, min=100, max=200),
low=runif(100, min=100, max=200),
close=runif(100, min=100, max=200)
)
# 将数据转换为xts对象
xts_stocks <- xts(x=stocks_data[,2:5], order.by=stocks_data$date)
# 绘制日K线图
candleChart(xts_stocks, type="candlesticks", theme='black.mono', up.col="green", dn.col="red", width=800, height=400)
```
在上述代码中,`candleChart()`函数专门用于绘制股票市场的日K线图。通过不同的颜色和数据点,我们可以清晰地看到不同交易日的开盘价、最高价、最低价和收盘价。
通过与xts包和其他分析工具的集成使用,ggseas包在金融数据分析领域提供了强大的功能,使分析师可以灵活地进行各种数据可视化和分析工作。
在本章节中,我们探讨了ggseas包在时间序列分析中的应用,包括数据的探索性分析、高级处理技术以及与其他包的集成使用。通过对ggseas包的深入实践,时间序列分析师可以更好地理解数据特征、进行数据转换和预测,以及与其他金融工具结合来增强分析能力。在下一章中,我们将进一步深入了解ggseas在时间序列可视化中的深入实践,包括创建个性化图表和交互式可视化探索,以进一步提升我们的时间序列数据可视化技能。
# 4. ggseas在时间序列可视化中的深入实践
## 4.1 个性化时间序列图表的创建
### 4.1.1 自定义图表主题和调色板
在数据可视化中,图表的主题和调色板对于传达信息和美化界面至关重要。ggseas包提供了丰富的函数来自定义图表的主题和调色板。通过这种方式,您可以根据个人喜好或者项目需求对图表进行个性化设计。
自定义主题可以通过修改图表的字体、颜色、背景等来实现。例如,使用 `theme()` 函数可以调整图表中的字体大小、颜色以及其他文本属性。而调色板的自定义,则是通过 `scale_color_manual()` 或者 `scale_fill_manual()` 等函数来进行。
以下代码示例展示了如何使用 `theme()` 和 `scale_color_manual()` 来自定义时间序列图表的主题和调色板:
```r
library(ggplot2)
library(ggseas)
# 假设已经有了一个名为ts_data的时间序列数据框
ts_data <- data.frame(
date = seq.Date(as.Date("2020-01-01"), by = "month", length.out = 12),
value = rnorm(12)
)
# 绘制时间序列图
p <- ggplot(ts_data, aes(x=date, y=value)) +
geom_line() +
theme_minimal() + # 使用一个简洁的主题
theme(text = element_text(family = "Times"),
plot.title = element_text(size = 16, color = "darkblue"),
axis.title = element_text(size = 14),
legend.position = "right")
# 使用scale_color_manual来自定义颜色
p + scale_color_manual(values = c("darkblue", "orange"))
```
在上述代码中,我们首先使用 `theme_minimal()` 函数应用了一个简洁主题,并通过 `theme()` 函数对字体、标题、轴标题和图例位置进行了调整。之后,`scale_color_manual()` 被用来设置线条的颜色。这样的自定义让图表更符合特定的风格要求。
### 4.1.2 图表元素的精细调整
除了主题和颜色的调整外,图表的每一个元素都可以进行精细的定制。这包括坐标轴的格式、图例的显示方式、网格线的有无和样式等。通过精细调整,可以使图表更加贴合分析目的和观众的需求。
ggplot2 提供了一系列函数来调整这些元素,例如 `scale_x_date()` 可以定制日期轴的显示格式,`guides()` 可以定制图例的显示方式。下面的代码展示了如何对图表的坐标轴和图例进行调整:
```r
# 继续使用之前的p图表对象
# 设置日期轴的显示格式
p + scale_x_date(date_breaks = "2 month", date_labels = "%b %y") +
# 调整图例显示
guides(color = guide_legend(title = "新标签"))
```
在这段代码中,`scale_x_date()` 函数设置了 x 轴的日期格式,其中 `date_breaks` 参数用于定义日期轴上刻度的间隔,而 `date_labels` 则定义了日期的显示格式。同时,`guides()` 函数被用来修改图例的标题,使其显示为“新标签”。
## 4.2 时间序列的交互式可视化探索
### 4.2.1 ggvis包的简介和安装
ggvis 是一个用于创建交互式图形的 R 包。它基于 Vega 和 Vega-Lite 视觉语法,并且可以轻松地与 R 的其他数据处理和可视化包(如 ggplot2 和 ggseas)结合使用。ggvis 通过提供一个声明式的语法,使得创建和自定义交互式图形变得简单直观。
安装 ggvis 包的命令如下:
```r
install.packages("ggvis")
```
使用 `library()` 函数加载 ggvis 包以开始使用:
```r
library(ggvis)
```
### 4.2.2 构建交互式时间序列图表
ggvis 通过其管道操作符 `%>%` 与 ggplot2 类似,允许用户将函数链接在一起以构建图形。下面是创建交互式时间序列图表的示例:
```r
# 使用ggvis创建交互式图表
ts_data %>%
ggvis(~date, ~value) %>%
layer_lines() %>%
scale_numeric("y", trans = "log") %>%
add_axis("x", title = "时间") %>%
add_axis("y", title = "数值", values = c(1, 10, 100), title_offset = 50) %>%
addLegend("bottom", fill = ~value)
```
在这段代码中,`ggvis()` 函数定义了数据和要映射的 x 和 y 变量。`layer_lines()` 创建了线条图层,`scale_numeric()` 函数用于应用 y 轴的对数转换。`add_axis()` 函数添加了自定义的 x 和 y 轴,并且 `addLegend()` 添加了一个图例。
### 4.2.3 交互式图表的扩展应用
交互式图表不仅限于显示,还可以扩展为提供额外的交互性,如过滤、缩放和多维度数据探索。ggvis 提供了各种控件,如滑块(slider)、按钮和选择器,这些控件可以通过与数据绑定来实现动态查询和更新图表。
例如,可以创建一个滑块来过滤特定时间范围内的数据:
```r
# 假设ts_data是带有时间序列信息的数据框
ts_data %>%
ggvis(~date, ~value) %>%
layer_lines() %>%
add_axis("x", title = "时间") %>%
add_axis("y", title = "数值") %>%
addSliderInput("dateRange", "选择日期范围", min = min(ts_data$date),
max = max(ts_data$date), value = range(ts_data$date))
```
在此代码中,`addSliderInput()` 创建了一个滑块控件,允许用户选择日期范围。这个控件可以与图表连接,以便只显示用户选定的日期范围内的数据。
通过这样的扩展应用,ggvis 提供了更加强大和灵活的方式来探索和展示时间序列数据,使得分析过程更加直观和互动。
# 5. ggseas的进阶技巧和最佳实践
随着数据分析需求的日益复杂化,ggseas包也提供了许多进阶技巧来帮助用户更高效地处理时间序列数据。本章将详细探讨如何使用ggseas进行高级绘图,如何将其与机器学习方法相结合,并讨论在大数据环境下使用ggseas的策略。
## 5.1 ggseas的高级绘图功能
在这一部分,我们将深入了解ggseas的高级绘图功能,特别是如何处理多变量分析和时间序列聚类。
### 5.1.1 使用ggseas进行多变量分析
多变量时间序列分析允许用户同时考虑多个相关时间序列。ggseas的某些函数可以帮助我们将这些序列整合到同一个图表中,以便于比较和分析。例如,`ggplot`结合`geom_line`可以绘制多个时间序列:
```R
library(ggseas)
library(ggplot2)
# 假设mtcars数据集已经被加载,并且我们想要绘制mpg和disp两个变量的时间序列
mtcars$car <- row.names(mtcars)
ggplot(mtcars, aes(x=car, y=mpg)) + geom_line() +
geom_line(aes(y=disp), color='red')
```
上述代码将绘制出两个时间序列,其中`mpg`为蓝色线条,`disp`为红色线条,可以直观地比较两个变量的变化趋势。
### 5.1.2 时间序列聚类和分割的可视化
在进行时间序列分析时,有时需要对序列进行聚类或分割。ggseas包中的`ggsdc`函数可以帮助我们对时间序列进行分割并可视化:
```R
data(EuStockMarkets)
# 对时间序列数据进行分割并绘图
ggsdc(EuStockMarkets, ~1, from = 1, to = 300, type = "line")
```
上面的代码通过`ggsdc`函数将`EuStockMarkets`数据集的时间序列分为300个子序列并分别绘制。这对于识别数据中的不同阶段特别有用。
## 5.2 时间序列数据的机器学习集成
在机器学习领域,预测模型如ARIMA、随机森林等常常被用于时间序列预测。ggseas可以与机器学习包如`caret`集成,以提高分析的准确性和效率。
### 5.2.1 使用caret包进行预测建模
首先安装并加载`caret`包,然后利用它来训练模型并进行预测:
```R
install.packages("caret")
library(caret)
# 示例中不详细说明数据集加载和预处理步骤
# 假设数据预处理已经完成并且已经有一个训练好的模型model
# 使用caret包进行预测
predictions <- predict(model, newdata = test_data)
```
### 5.2.2 集成ggseas与预测结果的可视化
预测结果需要被可视化以直观评估模型性能。ggseas可以帮助我们将实际观测值与预测值绘制在同一图表中:
```R
# 将预测结果和实际数据合并到一个新的数据框中
plot_data <- data.frame(
Date = test_data$date,
Actual = test_data$actual_values,
Predicted = predictions
)
# 绘制时间序列图
ggplot(plot_data, aes(x=Date)) +
geom_line(aes(y=Actual), color='blue') +
geom_line(aes(y=Predicted), color='red', linetype='dashed')
```
上述代码将绘制出一个包含实际值和预测值的时间序列图,其中实际值用蓝色线条表示,预测值用红色虚线表示。
## 5.3 ggseas在大数据环境下的应用
当处理大规模的时间序列数据时,性能和存储问题变得尤为重要。在这一部分,我们将探讨如何将高性能计算与ggseas结合使用,以及如何处理大规模数据。
### 5.3.1 高性能计算与ggseas的配合
使用`parallel`包中的函数可以将工作分配到多个处理器上,从而加速计算过程。例如:
```R
library(parallel)
# 创建集群
cl <- makeCluster(detectCores() - 1)
# 使用parLapply对数据集的每个部分应用函数
results <- parLapply(cl, split_data, function(x) {
# 这里可以放置时间序列分析或绘图的函数
})
stopCluster(cl)
```
### 5.3.2 处理大规模时间序列数据的策略
处理大规模时间序列数据时,可以考虑数据的分块处理或使用适合大数据处理的特殊格式,比如HDF5。此外,还可以将数据压缩或筛选以减少处理的数据量:
```R
# 使用HDF5包来处理大数据格式
install.packages("HDF5")
library(HDF5)
# 创建HDF5文件并写入数据
h5createFile("large_data.h5")
h5write(data, "large_data.h5", "dataset_name")
# 对HDF5文件中的数据进行读取和处理
h5data <- h5read("large_data.h5", "dataset_name")
```
此外,还可以使用R中的数据裁剪功能,如`dplyr`包的`filter`函数,来减少需要处理的数据量。
综上所述,ggseas包在时间序列分析的高级应用中显示了强大的功能。通过集成机器学习和高性能计算方法,以及采取大数据处理策略,ggseas可以帮助我们更有效地解决复杂的时间序列问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
欢迎来到 ggseas 专栏,您的 R 语言时间序列分析和可视化指南!
本专栏深入剖析了 ggseas 包,从基础到高级,涵盖了 24 小时精通时间序列处理、自定义美化图表、优化数据处理、集成 R 包、自定义功能包发布、金融数据分析、交互式可视化、项目管理、模块化分析、数据清洗、数据变换、可视化设计和高级统计分析应用。
无论您是 R 语言新手还是经验丰富的用户,本专栏都能为您提供宝贵的见解和实用技巧,帮助您充分利用 ggseas 包,提升您的时间序列分析和可视化能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WinRAR CVE-2023-38831漏洞快速修复解决方案

# 摘要
本文详细阐述了WinRAR CVE-2023-38831漏洞的技术细节、影响范围及利用原理,并探讨了系统安全防护理论,包括安全防护层次结构和防御策略。重点介绍了漏洞快速检测与响应方法,包括使用扫描工具、风险评估、优先级划分和建立应急响应流程。文章进一步提供了WinRAR漏洞快速修复的实践
【QWS数据集实战案例】:深入分析数据集在实际项目中的应用
# 摘要
数据集是数据科学项目的基石,它在项目中的基础角色和重要性不可小觑。本文首先讨论了数据集的选择标准和预处理技术,包括数据清洗、标准化、特征工程等,为数据分析打下坚实基础。通过对QWS数据集进行探索性数据分析,文章深入探讨了统计分析、模式挖掘和时间序列分析,揭示了数据集内在的统计特性、关联规则以及时间依赖性。随后,本文分析了QWS数据集在金融、医疗健康和网络安全等特定领域的应用案例,展现了其在现实世界问题中
【跨平台远程管理解决方案】:源码视角下的挑战与应对
# 摘要
随着信息技术的发展,跨平台远程管理成为企业维护系统、提升效率的重要手段。本文首先介绍了跨平台远程管理的基础概念,随后探讨了在实施过程中面临的技术挑战,包括网络协议的兼容性、安全性问题及跨平台兼容性。通过实际案例分析,文章阐述了部署远程管理的前期准备、最佳实践以及性能优化和故障排查的重要性。进阶技术章节涵盖自动化运维、集群管理与基于云服务的远程管理。最后
边缘检测技术大揭秘:成像轮廓识别的科学与艺术

# 摘要
边缘检测技术是图像处理和计算机视觉领域的重要分支,对于识别图像中的物体边界、特征点以及进行场景解析至关重要。本文旨在概述边缘检测技术的理论基础,包括其数学模型和图像处理相关概念,并对各种边缘检测方法进行分类与对比。通过对Sobel算法和Canny边缘检测器等经典技术的实战技巧进行分析,探讨在实际应用中如何选择合适的边缘检测算法。同时,本文还将关注边缘检测技术的
Odroid XU4性能基准测试

# 摘要
Odroid XU4作为一款性能强大且成本效益高的单板计算机,其性能基准测试成为开发者和用户关注的焦点。本文首先对Odroid XU4硬件规格和测试环境进行详细介绍,随后深入探讨了性能基准测试的方法论和工具。通过实践测试,本文对CPU、内存与存储性能进行了全面分析,并解读了测试
TriCore工具使用手册:链接器基本概念及应用的权威指南

# 摘要
本文深入探讨了TriCore工具与链接器的原理和应用。首先介绍了链接器的基本概念、作用以及其与编译器的区别,然后详细解析了链接器的输入输出、链接脚本的基础知识,以及链接过程中的符号解析和内存布局控制。接着,本文着重于TriCore链接器的配置、优化、高级链
【硬件性能革命】:揭秘液态金属冷却技术对硬件性能的提升

# 摘要
液态金属冷却技术作为一种高效的热管理方案,近年来受到了广泛关注。本文首先介绍了液态金属冷却的基本概念及其理论基础,包括热传导和热交换原理,并分析了其与传统冷却技术相比的优势。接着,探讨了硬件性能与冷却技术之间的关系,以及液态金属冷却技术在实践应用中的设计、实现、挑战和对策。最后,本文展望了液态金属冷却技术的未来,包括新型材料的研究和技术创新的
【企业级测试解决方案】:C# Selenium自动化框架的搭建与最佳实践
# 摘要
随着软件开发与测试需求的不断增长,企业级测试解决方案的需求也在逐步提升。本文首先概述了企业级测试解决方案的基本概念,随后深入介绍了C#与Selenium自动化测试框架的基础知识及搭建方法。第三章详细探讨了Selenium自动化测试框架的实践应用,包括测试用例设计、跨浏览器测试的实现以及测试数据的管理和参数化测试。第四章则聚焦于测试框架的进阶技术与优化,包括高级操作技巧、测试结果的分析与报告生成以及性能和负
三菱PLC-FX3U-4LC高级模块应用:详解与技巧

# 摘要
本论文全面介绍了三菱PLC-FX3U-4LC模块的技术细节与应用实践。首先概述了模块的基本组成和功能特点,接着详细解析了其硬件结构、接线技巧以及编程基础,包括端口功能、
【CAN总线通信协议】:构建高效能系统的5大关键要素

# 摘要
CAN总线作为一种高可靠性、抗干扰能力强的通信协议,在汽车、工业自动化、医疗设备等领域得到广泛应用。本文首先对CAN总线通信协议进行了概述,随后深入分析了CAN协议的理论基础,包括数据链路层与物理层的功能、CAN消息的传输机制及错误检测与处理机制。在实践应用方面,讨论了CAN网络的搭建、消息过滤策略及系统集成和实时性优化。同时,本文还探讨了CAN协议在不同行业的具体应用案例,及其在安全性和故障诊断方面的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )