1. Python基础知识巩固与扩展
发布时间: 2024-02-28 00:18:22 阅读量: 45 订阅数: 22 

1.python基础1
# 1. Python基础知识回顾
### 1.1 变量和数据类型
在Python中,我们可以使用变量来存储各种类型的数据,例如整数、浮点数、字符串等。变量在使用前无需声明类型,Python会根据赋给变量的值自动推断类型。
```python
# 定义整数变量
num = 10
# 定义浮点数变量
pi = 3.14
# 定义字符串变量
message = "Hello, World!"
# 打印变量的值
print(num) # 输出:10
print(pi) # 输出:3.14
print(message) # 输出:Hello, World!
```
总结:Python是一种动态类型的语言,变量的类型由赋给变量的值决定。
### 1.2 控制流程(条件语句与循环)
在Python中,我们可以使用条件语句(if-elif-else)和循环语句(for循环、while循环)来控制程序的流程。
```python
# 条件语句示例
x = 10
if x > 5:
print("x大于5")
elif x == 5:
print("x等于5")
else:
print("x小于5")
# for循环示例
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
# while循环示例
count = 0
while count < 3:
print(count)
count += 1
```
总结:条件语句和循环结构是控制程序流程的重要工具,在Python中使用简单直观。
### 1.3 函数与模块的使用
函数是Python中的重要概念,我们可以通过定义、调用函数来组织代码和实现复用。
```python
# 定义函数
def greet(name):
return "Hello, " + name
# 调用函数
message = greet("Alice")
print(message) # 输出:Hello, Alice
```
模块是Python中组织代码的方式,通过导入模块可以使用其中定义的函数、变量等。
```python
# 导入模块
import math
# 使用模块中的函数
print(math.sqrt(16)) # 输出:4.0
```
总结:函数能够封装一段特定的功能代码,模块能够组织多个函数和变量,提升代码的可维护性和复用性。
### 1.4 异常处理
在Python中,我们可以使用try-except语句来捕获和处理异常,保证程序在出错时能够正常运行或给出友好提示。
```python
# 异常处理示例
try:
result = 10 / 0
except ZeroDivisionError:
print("除数不能为0!")
```
总结:异常处理能够提高程序的健壮性,避免程序在遇到错误时崩溃。
通过本章节的学习,读者可以巩固Python基础知识,包括变量与数据类型、控制流程、函数与模块的使用,以及异常处理。在接下来的章节中,我们将进一步扩展和深化对Python编程的理解和应用。
# 2. 高级数据结构与算法
### 2.1 列表推导式
列表推导式是Python中非常方便和简洁的语法,可以通过一行代码快速创建一个列表。它的基本形式为`[expression for item in iterable if condition]`,其中expression为表达式,item为可迭代对象中的元素,condition为筛选条件。
```python
# 示例:创建一个包含1~10的偶数的列表
even_numbers = [x for x in range(1, 11) if x % 2 == 0]
print(even_numbers)
```
**代码总结:** 利用列表推导式可以简洁地生成新的列表,同时可以添加条件进行筛选。
**结果说明:** 运行以上代码将输出 `[2, 4, 6, 8, 10]` 表示生成的包含1~10的偶数的列表。
### 2.2 字典与集合的高级操作
字典和集合是Python中常用的数据结构,通过字典和集合的高级操作可以快速实现数据处理。
```python
# 示例:使用字典推导式创建一个字典,key为数字,value为数字的平方
square_dict = {x: x**2 for x in range(1, 6)}
print(square_dict)
# 示例:使用集合推导式创建一个集合,存储每个数字的平方
square_set = {x**2 for x in range(1, 6)}
print(square_set)
```
**代码总结:** 利用字典和集合推导式,可以快速创建字典和集合,使代码更简洁。
**结果说明:** 运行以上代码将输出 `{1: 1, 2: 4, 3: 9, 4: 16, 5: 25}` 和 `{1, 4, 9, 16, 25}` 分别表示创建的字典和集合。
### 2.3 排序算法的实现与性能分析
排序算法是计算机科学中的重要内容,Python中内置了`sorted()`函数用于对列表进行排序。
```python
# 示例:使用sorted()函数对列表进行排序
numbers = [5, 2, 8, 1, 3]
sorted_numbers = sorted(numbers)
print(sorted_numbers)
```
**代码总结:** Python中的`sorted()`函数可以对列表进行排序,返回一个新的已排序列表,不改变原列表。
**结果说明:** 运行以上代码将输出 `[1, 2, 3, 5, 8]` 表示对原始列表进行排序后的结果。
### 2.4 递归算法与动态规划的应用
递归算法是一种解决问题的有效方法,动态规划则是运用递归问题中重复计算的特点,通过空间换取时间来提高效率。
```python
# 示例:使用递归算法实现斐波那契数列
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(5))
```
**代码总结:** 递归算法在解决一些问题时可以非常简洁,但需要注意递归深度,避免栈溢出。
**结果说明:** 运行以上代码将输出 `5` 表示斐波那契数列第5个数字的值。
# 3. 面向对象编程进阶
在面向对象编程中,类和对象是核心概念。通过定义类和创建对象,我们可以更好地组织和管理代码,实现代码的复用和扩展。在本章中,我们将深入探讨面向对象编程的进阶内容,包括类的继承、多态的实现、特殊方法的应用以及魔术方法的定制。
#### 3.1 类与对象的定义
在Python中,可以使用关键字`class`来定义一个类,`__init__`方法用于初始化对象的属性。下面是一个简单的类的定义示例:
```python
class Animal:
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self):
print(f"{self.name} is speaking.")
# 创建对象
dog = Animal("Dog", 3)
print(dog.name) # 输出:Dog
dog.speak() # 输出:Dog is speaking.
```
#### 3.2 继承与多态的实现
继承是面向对象编程的重要特性,子类可以继承父类的属性和方法,并且可以重写或者扩展父类的方法。多态则能够通过不同的对象调用相同的方法而实现不同的行为。下面是一个简单的继承与多态示例:
```python
class Dog(Animal):
def speak(self):
print(f"{self.name} is barking.")
class Cat(Animal):
def speak(self):
print(f"{self.name} is meowing.")
# 多态示例
animals = [dog, Dog("Puppy", 1), Cat("Kitty", 2)]
for animal in animals:
animal.speak()
```
#### 3.3 类的特殊方法与属性
类的特殊方法(如`__str__`、`__repr__`、`__len__`等)可以实现对对象的特殊操作,增强了类的功能和灵活性。属性可以通过`@property`装饰器进行定义,实现对属性的访问控制与保护。
```python
class Circle:
def __init__(self, radius):
self.radius = radius
@property
def area(self):
return 3.14 * self.radius ** 2
def __str__(self):
return f"Circle with radius {self.radius}"
circle = Circle(5)
print(circle.area) # 输出:78.5
print(circle) # 输出:Circle with radius 5
```
#### 3.4 魔术方法的应用与定制
魔术方法(如`__eq__`、`__add__`、`__call__`等)可以实现对类的行为进行定制化,改变默认的操作方式。通过定制魔术方法,我们可以实现更加灵活和个性化的类。下面是一个简单的魔术方法示例:
```python
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
return Vector(self.x + other.x, self.y + other.y)
def __str__(self):
return f"Vector ({self.x}, {self.y})"
v1 = Vector(1, 2)
v2 = Vector(3, 4)
print(v1 + v2) # 输出:Vector (4, 6)
```
通过对类的继承、多态、特殊方法和魔术方法进行合理的应用与定制,我们可以更好地设计出符合实陵需求的面向对象程序,提高代码的可扩展性和可维护性。
# 4. 文件操作与数据持久化
在本章中,我们将深入探讨Python中的文件操作和数据持久化相关的内容。通过学习本章的内容,读者将能够掌握文件的读写操作、CSV和JSON数据的处理以及使用SQLite进行数据库操作等技能。
1. **4.1 文件读写操作**
在本节中,我们将学习如何使用Python进行文件的读写操作。我们将介绍如何打开文件、读取文件内容、写入文件内容以及文件的关闭操作。
```python
# 示例代码:文件读写操作
# 打开文件并写入内容
with open('myfile.txt', 'w') as f:
f.write('Hello, this is a text file.')
# 读取文件内容
with open('myfile.txt', 'r') as f:
content = f.read()
print(content)
```
代码总结:使用`open`函数以及`with`语句可以方便地进行文件的读写操作,而无需手动关闭文件。
结果说明:上述代码首先向文件`myfile.txt`中写入一段文本,然后再次打开文件并读取文件内容进行打印输出。
2. **4.2 CSV与JSON数据处理**
本节将介绍如何使用Python处理CSV和JSON格式的数据。我们将学习如何读取和写入CSV文件,以及如何使用Python内置的`json`模块处理JSON数据。
```python
# 示例代码:CSV与JSON数据处理
import csv
import json
# 读取CSV文件
with open('data.csv', 'r') as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
print(row)
# 写入JSON文件
data = {
'name': 'Alice',
'age': 25,
'city': 'New York'
}
with open('data.json', 'w') as jsonfile:
json.dump(data, jsonfile)
```
代码总结:Python内置的`csv`模块和`json`模块可以方便地处理CSV和JSON格式的数据,读取和写入操作都非常简单。
结果说明:上述代码首先读取名为`data.csv`的CSV文件并打印内容,然后将一个Python字典对象写入到名为`data.json`的JSON文件中。
3. **4.3 使用SQLite进行数据库操作**
在本节中,我们将学习如何使用Python内置的`sqlite3`模块进行SQLite数据库操作。我们将介绍如何创建数据库、创建表、插入数据、查询数据以及关闭数据库连接等操作。
```python
# 示例代码:使用SQLite进行数据库操作
import sqlite3
# 连接到SQLite数据库(如果不存在则会自动创建)
conn = sqlite3.connect('example.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS users
(id INTEGER PRIMARY KEY, name TEXT, age INTEGER)''')
# 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES ('Alice', 25)")
# 提交更改
conn.commit()
# 查询数据
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭数据库连接
conn.close()
```
代码总结:Python内置的`sqlite3`模块提供了简单易用的SQLite数据库操作接口,包括创建数据库、创建表、插入数据、查询数据和关闭数据库连接等功能。
结果说明:上述代码首先连接到一个名为`example.db`的SQLite数据库,并创建了一个名为`users`的表,然后插入一条数据并进行查询操作,最后关闭了数据库连接。
4. **4.4 数据的序列化与反序列化**
本节将介绍如何使用Python的`pickle`模块进行数据的序列化与反序列化操作。我们将学习如何将Python对象序列化为字节流并保存到文件中,以及如何从文件中读取字节流并反序列化为Python对象。
```python
# 示例代码:数据的序列化与反序列化
import pickle
# 将对象序列化并保存到文件
data = {'name': 'Bob', 'age': 30, 'city': 'Chicago'}
with open('data.pickle', 'wb') as f:
pickle.dump(data, f)
# 从文件中读取数据并进行反序列化
with open('data.pickle', 'rb') as f:
loaded_data = pickle.load(f)
print(loaded_data)
```
代码总结:Python的`pickle`模块可以方便地对Python对象进行序列化和反序列化操作,从而实现数据的持久化存储和恢复。
结果说明:上述代码首先将一个字典对象序列化并保存到名为`data.pickle`的文件中,然后从文件中读取数据并进行反序列化操作,并打印输出反序列化后的数据。
通过本章的学习,读者将掌握文件操作、CSV和JSON数据处理、SQLite数据库操作以及数据的序列化与反序列化等重要知识,为进一步深入学习和实践打下坚实的基础。
# 5. 函数式编程与生成器
函数式编程是一种编程范式,它将计算过程视为数学函数的求值。在Python中,函数式编程可以通过Lambda表达式、高阶函数、map、filter、reduce等工具来实现。同时,生成器是Python中一个强大的概念,可以帮助我们节省内存并提高程序性能。
#### 5.1 Lambda表达式与高阶函数
Lambda表达式是一种匿名函数的写法,可以简洁地表示一些简单的函数功能。高阶函数是指可以接受函数作为参数,或者返回函数的函数。下面是一个Lambda表达式与高阶函数的示例:
```python
# Lambda表达式示例
square = lambda x: x**2
print(square(5))
# 高阶函数示例
def apply_func(func, num):
return func(num)
result = apply_func(lambda x: x*2, 10)
print(result)
```
**代码总结:** Lambda表达式可以在需要函数作为参数的场景下提供便利的写法,高阶函数可以增加代码的灵活性和复用性。
**结果说明:** 打印出了Lambda表达式计算平方和高阶函数应用的结果。
#### 5.2 map、filter和reduce函数的应用
在Python中,map、filter和reduce是函数式编程中常用的三个高阶函数。它们可以分别对可迭代对象中的每个元素进行函数映射、筛选和聚合操作。
```python
# map函数示例
nums = [1, 2, 3, 4, 5]
squared_nums = list(map(lambda x: x**2, nums))
print(squared_nums)
# filter函数示例
even_nums = list(filter(lambda x: x % 2 == 0, nums))
print(even_nums)
# reduce函数示例
from functools import reduce
product = reduce(lambda x, y: x * y, nums)
print(product)
```
**代码总结:** map函数可以对可迭代对象中的每个元素进行映射计算,filter函数可以筛选符合条件的元素,reduce函数可以对序列中的元素进行累积操作。
**结果说明:** 分别打印出了map、filter和reduce函数的应用结果。
#### 5.3 生成器与迭代器的原理
生成器是一种特殊的迭代器,它可以在每次迭代中生成一个值并保持状态,而不会一次性生成所有值,从而节省内存空间。迭代器是一种可以被next()函数调用并逐个返回值的对象。
```python
# 生成器示例
def simple_generator():
yield 1
yield 2
yield 3
gen = simple_generator()
print(next(gen))
print(next(gen))
print(next(gen))
# 迭代器示例
nums = [1, 2, 3, 4, 5]
iter_nums = iter(nums)
print(next(iter_nums))
print(next(iter_nums))
print(next(iter_nums))
```
**代码总结:** 通过yield关键字定义生成器函数,生成器函数会返回一个生成器对象。迭代器可以通过iter()函数进行创建,并通过next()函数逐个获取元素。
**结果说明:** 分别打印出了生成器和迭代器的结果。
# 6. 项目实践与实例分析
在本章中,我们将通过实际项目示例和案例分析来帮助读者更好地应用所学的Python知识,加深对编程的理解和实践能力。
### 6.1 简单项目示例:文本词频统计
在这个项目中,我们将使用Python编程语言实现一个简单的文本词频统计程序。通过该项目,读者可以学习如何读取文本文件、对文本进行预处理、统计词频并可视化展示。
```python
# 导入所需的库
import re
from collections import Counter
import matplotlib.pyplot as plt
# 读取文本文件
with open('sample_text.txt', 'r') as file:
text = file.read()
# 文本预处理
text = text.lower() # 转换为小写
words = re.findall(r'\w+', text) # 分词
# 统计词频
word_freq = Counter(words)
# 可视化展示
top_words = word_freq.most_common(10) # 取词频最高的前10个词
words, freq = zip(*top_words)
plt.bar(words, freq)
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.title('Top 10 Words Frequency')
plt.show()
```
**代码总结:** 通过该项目,读者学会了如何读取文本文件,进行文本预处理、词频统计以及利用Matplotlib库进行简单的数据可视化展示。
**结果说明:** 通过运行上述代码,可以得到文本中词频最高的前10个词,并以条形图形式展示出来。
### 6.2 Web爬虫实战:爬取网页内容
这个项目将帮助读者了解如何使用Python编写简单的Web爬虫程序,从指定网页中爬取内容,对爬取的数据进行处理。
### 6.3 数据可视化应用:利用Matplotlib绘图
通过这个案例,读者将学习如何使用Matplotlib库绘制不同类型的图表,包括折线图、柱状图、饼图等,从而更好地展示数据特征和趋势。
### 6.4 性能优化与调试技巧
最后一个案例将引导读者了解如何通过性能优化和调试技巧,提升Python程序的执行效率和代码质量。通过分析程序的性能瓶颈和调试常见问题,读者可以更好地解决实际编程中的挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Python入门和案例实战"为主题,旨在帮助读者系统学习Python编程语言。从基础知识的巩固与扩展开始,逐步展开到实际案例的应用实践。读者将学习如何执行第一个Python脚本,掌握循环结构的实际运用,深入了解Dict字典的技巧,并通过从入门到进阶的练习提升技能。同时,专栏还涵盖了模块、文件数据处理、Excel读写、数据库操作、HTTP请求等实用技巧,以及数据可视化的基础案例。通过构建扑克牌游戏等综合实战案例,读者将在实践中不断提升自己的Python编程能力,同时掌握爬虫技巧和MySQL数据库操作等实用技能,从而全面提升工作效率和编程实力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
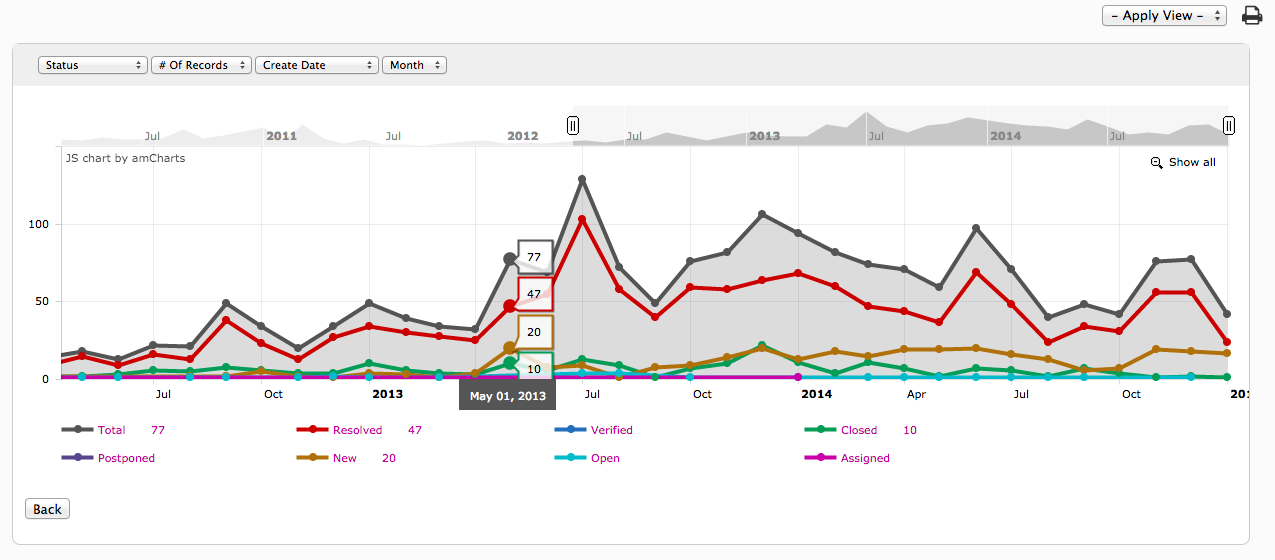
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
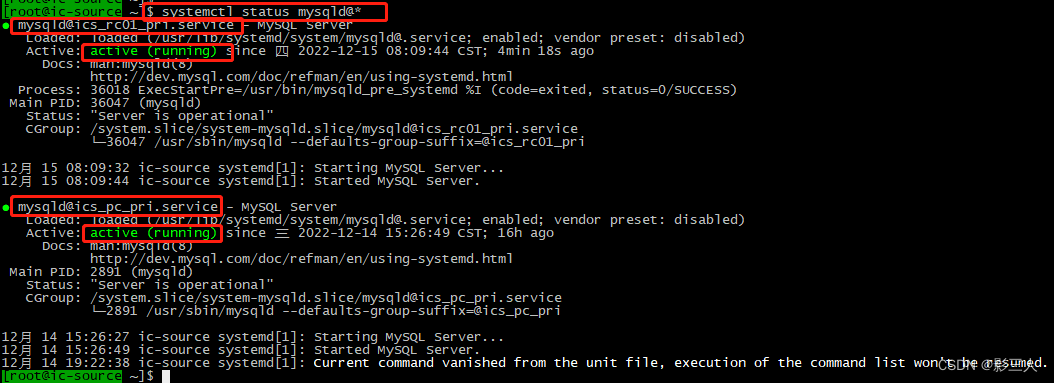
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
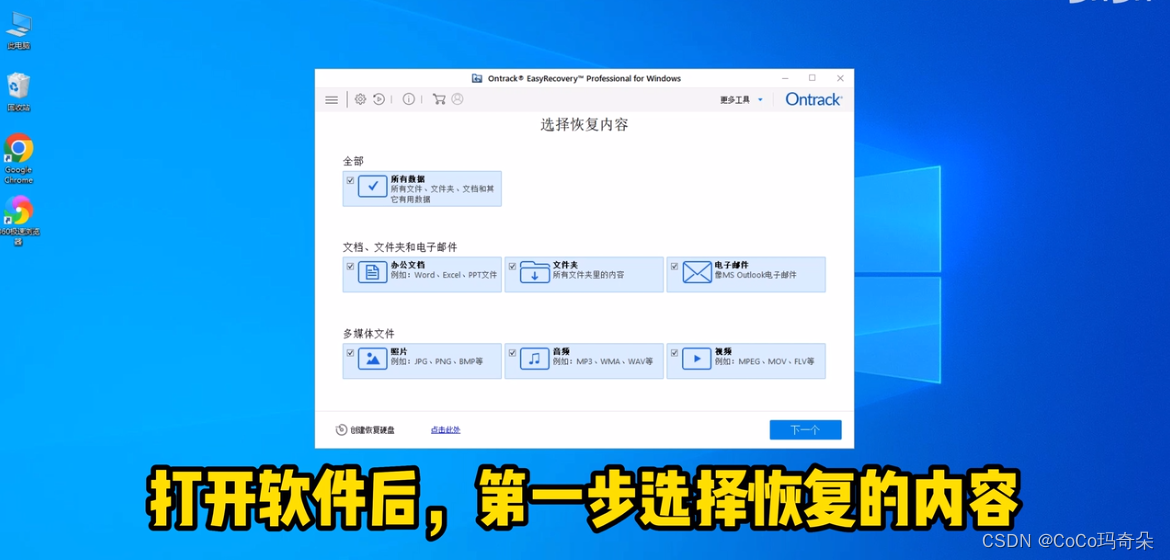
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
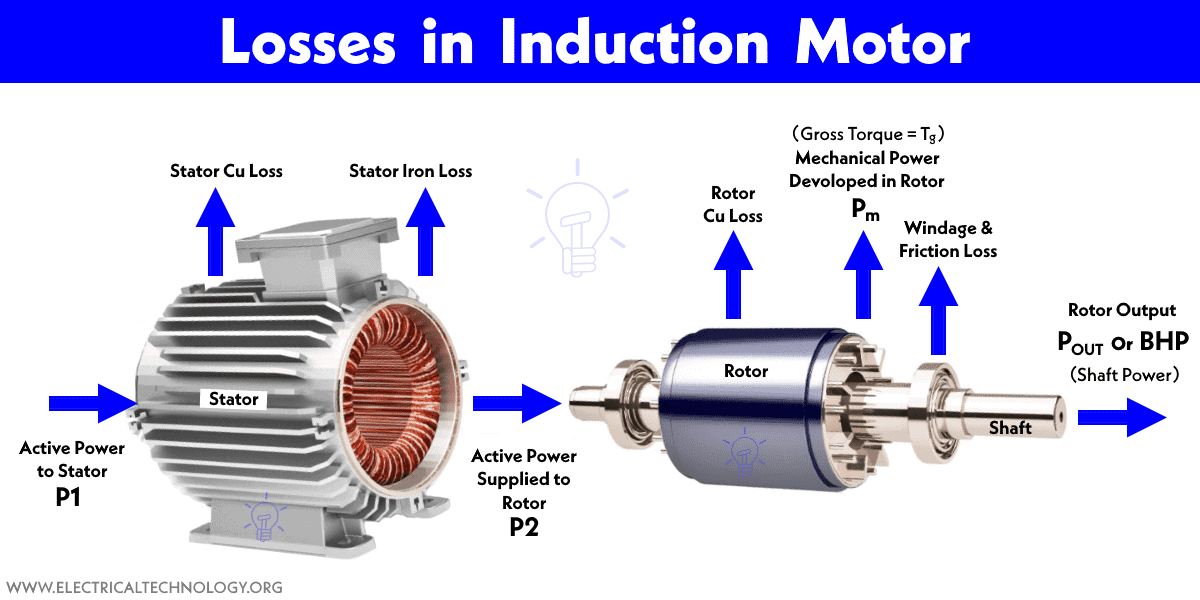
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )