【MT7981B多核心编程秘技】:提升并发性能的高级编程策略
发布时间: 2024-12-16 13:50:34 阅读量: 1 订阅数: 3 

MT7981B-Datasheet,mt7981b芯片规格书
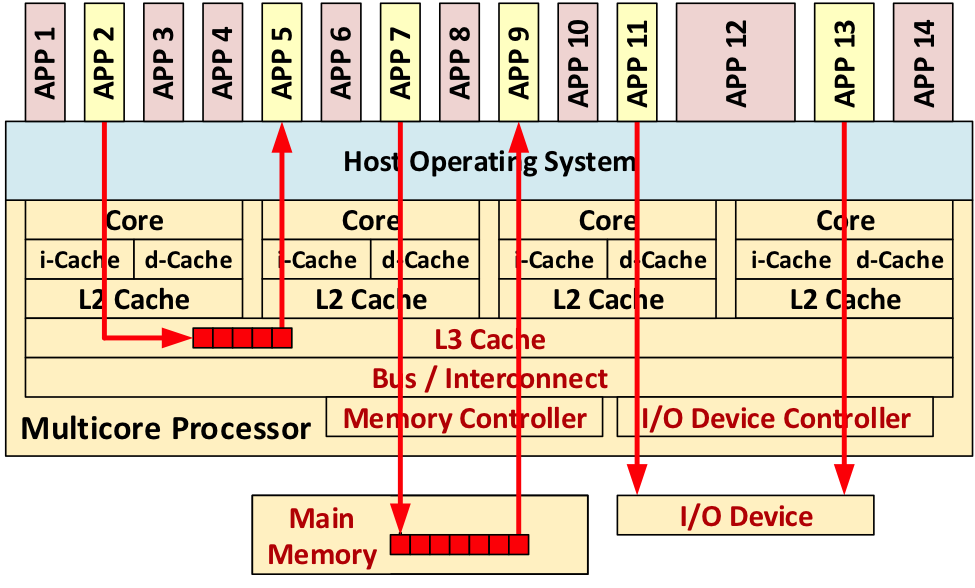
参考资源链接:[MT7981B芯片规格书Datasheet详细说明](https://wenku.csdn.net/doc/12ihmq7i4x?spm=1055.2635.3001.10343)
# 1. 多核心编程基础
在现代计算机系统中,多核心处理器是提高性能和响应速度的关键技术。本章节旨在为读者介绍多核心编程的基础知识,为后续章节的深入探讨打下坚实基础。
## 1.1 多核心技术概述
多核心技术指的是在一个单一封装内集成两个或多个独立处理器核心的技术。这种技术的出现,意味着软件开发者需要重新思考软件设计,以便充分利用硬件的并行计算能力。
## 1.2 并发编程简介
并发编程允许计算机同时或近似同时执行多个任务。它通过合理调度多个任务,使得它们共享CPU资源,从而提高整体效率。并发编程是多核心编程中必不可少的一部分,其涉及的线程管理和同步机制将在第二章深入讨论。
## 1.3 多核心编程的挑战
随着核心数量的增加,如何有效地管理并行任务变得越来越复杂。编程模型需要能够处理数据一致性、同步机制以及避免资源冲突等问题。这些挑战将在后续章节中通过实例和最佳实践进行详尽阐述。
在多核心编程中,了解其基础概念是至关重要的。本章节为读者提供了多核心技术的概览,以及并发编程的初步介绍,为接下来的章节奠定了基础。随着章节的深入,读者将逐步掌握多核心编程的复杂性和应用中的精髓。
# 2. 并发编程理论精讲
### 2.1 并发与并行的基本概念
并发和并行是多核心编程的基石。尽管这两个术语经常被互换使用,但在计算机科学中,它们有着明确的区别,并涉及到不同的应用场景和理论模型。
#### 2.1.1 并发和并行的区别
并发是指两个或多个事件在同一时间段内发生。在计算机系统中,这意味着多个进程或线程可以在同一时刻处于活动状态,但它们可能并不同时执行。并发是通过任务调度在时间上交错执行来实现的。例如,一个单核处理器可以在同一时间处理多个任务,但由于其只有一个核心,所以它通过快速切换来在这些任务之间进行并发处理。
并行,另一方面,指的是在同一时刻同时进行的操作。在多核心处理器中,可以同时执行多个线程,因为每个核心可以独立处理任务。并行处理要求硬件能够真正地同时执行操作,而不是简单地快速交替。
#### 2.1.2 并发模型的分类
为了实现并发,计算机科学中发展了多种并发模型:
1. **基于线程的并发模型**:这是最常见的并发模型,操作系统通过线程调度器来管理线程的执行。线程作为程序执行流的最小单位,可以在多个核心之间分配。
2. **基于事件的并发模型**:在这种模型下,系统响应事件(如用户输入、网络请求等),并为每个事件触发一个处理函数。这种模型通常用于事件驱动的编程,如Web服务器和图形用户界面。
3. **基于数据流的并发模型**:数据流并发模型使用特定的数据依赖图来定义任务。任务在输入数据可用时自动执行,这种模型适用于高度并行的数据处理应用。
4. **基于actor的并发模型**:在这种模型中,actor是并发实体的抽象。每个actor维护自己的私有状态,并通过消息传递与其他actor通信。这种模型减少了共享资源的使用,从而简化了并发编程的复杂性。
### 2.2 线程和进程的管理
在并发编程中,管理好线程和进程是确保程序高效运行的关键。
#### 2.2.1 线程的创建和销毁
线程创建和销毁是并发编程中经常涉及的操作,需要根据不同的编程语言和平台使用特定的API。
在C语言中,可以使用`pthread`库来创建和管理线程:
```c
#include <pthread.h>
void* run_thread(void *arg) {
// Thread function implementation
return NULL;
}
int main() {
pthread_t thread_id;
int result = pthread_create(&thread_id, NULL, run_thread, NULL);
if (result != 0) {
// Error handling
}
// Wait for thread completion
pthread_join(thread_id, NULL);
return 0;
}
```
这段代码首先包含了`pthread.h`头文件,然后定义了一个线程运行的函数`run_thread`。`main`函数中使用`pthread_create`创建了一个线程,并通过`pthread_join`等待线程执行完成。在这个例子中,我们创建的线程运行完毕后会自动销毁。
#### 2.2.2 进程间通信(Inter-Process Communication, IPC)
进程间通信是允许运行在不同地址空间的多个进程之间共享数据和资源的技术。IPC的方式有很多种:
- **管道(Pipes)**:是最简单的IPC机制,允许一个进程和另一个进程之间进行单向通信。
- **消息队列**:允许一个或多个进程向它写入消息,并由另一个或多个进程读取。
- **共享内存**:允许两个或多个进程访问同一块内存空间。这是最快的IPC方式,但需要同步机制来避免冲突。
- **信号量(Semaphores)**:是一种同步机制,用于控制对共享资源的访问。
- **套接字(Sockets)**:可以在本地或者网络上的进程之间建立连接进行通信。
使用`mkfifo`命令创建一个管道:
```bash
mkfifo mypipe
```
这创建了一个名为`mypipe`的FIFO文件,可以通过这个管道进行进程间通信。
### 2.3 同步和互斥机制
在多线程或多进程环境中,同步和互斥机制是保障数据一致性和防止资源竞争的关键。
#### 2.3.1 互斥锁(Mutex)的原理和应用
互斥锁(Mutex)是一种常用的同步机制,用于防止多个线程同时访问共享资源。当一个线程获取了互斥锁时,其他线程将无法进入临界区,直到该线程释放锁。
互斥锁的典型用法如下:
```c
#include <pthread.h>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void critical_section() {
pthread_mutex_lock(&lock);
// Critical section - only one thread can execute this at a time
pthread_mutex_unlock(&lock);
}
int main() {
// Thread code here
}
```
在这个例子中,`critical_section`函数中的代码在执行时会获取一个互斥锁,以确保一次只有一个线程可以执行该段代码。
#### 2.3.2 条件变量(Condition Variables)的作用
条件变量允许线程在某些条件不满足时挂起执行,直到条件满足时由其他线程唤醒。它们通常与互斥锁一起使用,来控制线程之间的通信。
使用条件变量的例子:
```c
#include <pthread.h>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t condition = PTHREAD_COND_INITIALIZER;
void *thread_function(void *arg) {
pthread_mutex_lock(&lock);
// Wait for condition to become true
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ICM-20948数据手册深度剖析:掌握9轴运动传感器技术细节

参考资源链接:[ICM-20948:9轴MEMS运动追踪设备手册](https://wenku.csdn.net/doc/6412b724be7fbd1778d493ed?spm=1055.2635.3001.10343)
# 1. ICM-20948 9轴运动传感器概述
在当今的智能设备中,运动传感器已经成为不可或缺的一部分,
B-66284EN PICTURE图形化编程:2小时掌握提高效率的秘诀
参考资源链接:[FANUC PICTURE中文操作手册:安全与详尽指南](https://wenku.csdn.net/doc/103s4j8sbv?spm=1055.2635.3001.10343)
# 1. B-66284EN PICTURE图形化编程入门
## 1.1 B-66284EN PICTURE简介
B-66284EN PICTURE是一种图形化编程语言
GMW3172深度剖析:汽车材料与零件性能的终极要求
参考资源链接:[GMW3172_Handbook_Version_19.pdf](https://wenku.csdn.net/doc/6401acf0cce7214c316edb16?spm=1055.2635.3001.10343)
# 1. 汽车材料与零件性能的基本概念
汽车制造业是人类技术进步的重要体现,而材料与零件的性能则是确保汽车安全、效率与舒适性的基础。本章旨在介绍汽车材料与零件性能的基本概念,为后续章节关于性能分析、测试方法、影响因素以及优化策略的深入探讨奠定基础。
汽车材料通常指用于汽车制造的各种金属、合金、塑料、复合材料等,它们需满足特定的机械性能、物理性能和化学性能,
【VMware软件安装步骤详解】:新手也能轻松驾驭的安装向导

参考资源链接:[ThinkPad VMware:Intel VT-x禁用问题及解决步骤](https://wenku.csdn.net/doc/6uhie
【云计算终极指南】
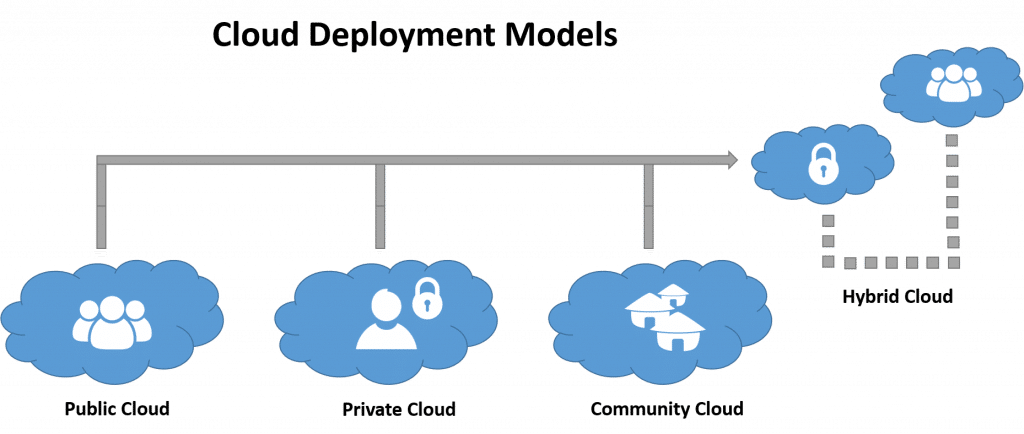
参考资源链接:[郑州十校2021-2022学年高二期中物理试题分析](https://wenku.csdn.net/doc/2pkvprcr8x?spm=1055.2635.3001.10343)
# 1. 云计算的概念与架构
云计算是一种基于互联网的计算模式,它通过互联网提供便捷、可配置的计算资源(如网络、服务器、存储、应用程序和资源)。这一模式使得计算资源能够
SoftMove云服务优化:云集成与性能调优的终极指南
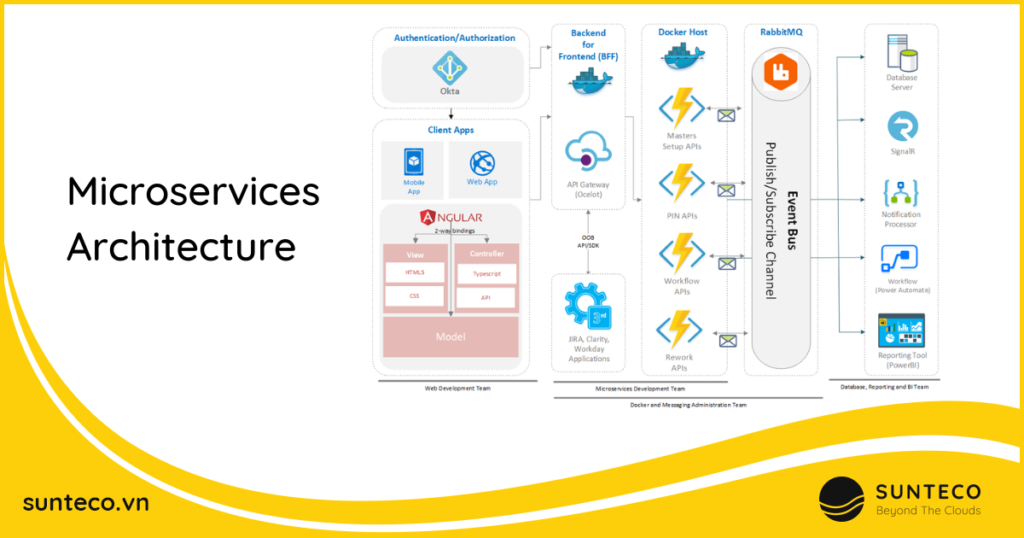
参考资源链接:[ABB机器人SoftMove中文应用手册](https://wenku.csdn.net/doc/1v1odu86mu?spm=1055.2635.3001.10343)
# 1. SoftMove云服务架构概述
## 1.1 云服务架构定义
SoftMove云服务架构是一个
揭秘VGA时序标准:从电子到图像的转换机制
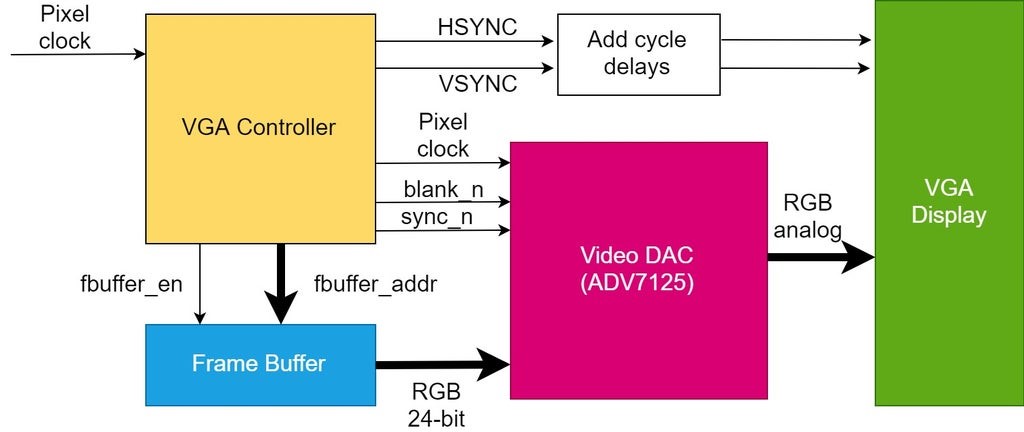
参考资源链接:[VESA全解析:VGA时序标准指南及行业常用显示参数](https://wenku.csdn.net/doc/1n5nv9qcym?spm=1055.2635.3001.10343)
# 1. VGA技术与图像显示基础
## 1.1 VGA技术简介
VGA(Video Graphics Array,视频图形阵列)是一种模拟电脑显示标准,于1987年由IBM公司推出。它的最大优势在于广泛的硬件兼容性和丰富的颜色表现。VGA支持最多256种颜色的图
【高斯分布到Isserlis' Theorem】:统计学关键链接的详细解读
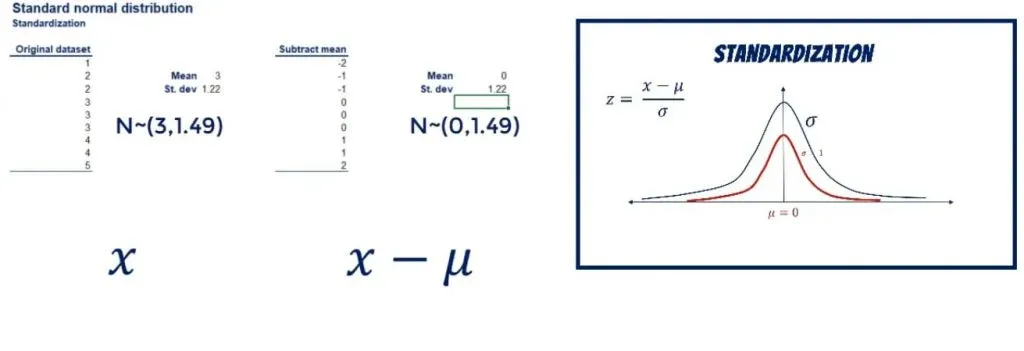
参考资源链接:[Isserlis定理:多元正态分布任意阶混合矩的通用公式证明](https://wenku.csdn.net/doc/6tpi5kvhfa?spm=1055.2635.3001.10343)
# 1. 高斯分布的数学基础
在统计学和概率论中,高斯分布,也被称为正态分布,是最为常见且广泛研究的连续概率分布。其数学基础在很大程度上
UCINET 6实战演练:社区检测技术的详尽解读

参考资源链接:[UCINET 6 for Windows中文手册:详解与资源指南](https://wenku.csdn.net/doc/7enj0faejo?spm=1055.2635.3001.10343)
# 1. UCINET 6简介与社区检测概述
社区检测是复杂网络分析的重要环节,其目标在于识别网络中的群体结构,这些群体内的节点相互连接紧密,而群体间连接相对稀疏。UCINET(University of Calif
深入浅出Gel-PRO ANALYZER:软件界面与功能详解

参考资源链接:[Gel-PRO ANALYZER软件:凝胶定量分析完全指南](https://wenku.csdn.net/doc/15xjsnno5m?spm=1055.2635.3001.10343)
# 1. Gel-PRO ANALYZER软件概述
Gel-PRO ANALYZER是一款专业的凝胶图像分析软件,广泛应用于分子生物学领域。它能对蛋白质、DNA、R
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )