Cognos数据管理:ETL工作流程与数据集成
发布时间: 2023-12-20 10:34:34 阅读量: 44 订阅数: 37 

面向数据集成的ETL技术研究
# 第一章:理解ETL的基础概念
## 1.1 ETL的定义和作用
在数据管理领域,ETL是指数据抽取(Extract)、数据转换(Transform)和数据加载(Load)三个过程的缩写。其主要作用是将不同数据来源的数据进行抽取、清洗、转换和加载,使之能够被目标系统所识别和利用。
## 1.2 ETL在数据管理中的重要性
ETL在数据管理中扮演着至关重要的角色。它通过将数据从源系统移动到目标系统的过程中,确保数据的完整性、一致性和可靠性,为企业决策和分析提供了高质量的数据基础。
## 1.3 ETL的基本工作原理
ETL的基本工作原理是将数据从源头抽取出来,经过清洗、加工和转换后,加载到目标存储中。这一过程需要借助专业的ETL工具或编程语言来实现,确保数据的准确性和完整性。
## 第二章:Cognos数据管理平台介绍
Cognos数据管理平台是一套强大的数据管理解决方案,为企业提供了完整的数据集成、转换和加载(ETL)功能。下面将介绍Cognos数据管理平台的概述、功能与特点,以及其在ETL工作流程中的应用案例分析。
### 2.1 Cognos数据管理的概述
Cognos数据管理平台是由IBM公司开发的一款企业级数据管理解决方案,旨在帮助用户从各种数据源中提取、转换和加载数据,实现数据集成和实时分析。该平台集成了业界领先的ETL功能,提供直观的用户界面和强大的数据处理能力,使得数据管理变得更加高效和可靠。
### 2.2 Cognos数据管理平台的功能与特点
Cognos数据管理平台具有以下主要功能和特点:
- **强大的数据连接能力**:支持多种数据源的连接和数据提取,包括关系型数据库、非关系型数据库、文件系统等。
- **灵活的数据转换功能**:提供丰富的数据转换和清洗功能,用户可以通过可视化界面轻松地进行数据清洗、格式化、转换和整合。
- **高效的数据加载机制**:支持高性能的数据加载,能够快速将处理后的数据加载到目标数据库中,保证数据的及时性和准确性。
- **可视化的工作流程设计**:提供直观的工作流程设计界面,用户可以轻松构建数据处理流程,并进行调度和监控。
- **全面的安全性和审计功能**:支持数据加密、权限管理和审计跟踪,确保数据的安全和合规性。
### 2.3 Cognos在ETL工作流程中的应用案例分析
以一个简单的数据抽取、转换、加载(ETL)为例,通过Cognos数据管理平台来实现从关系型数据库中提取数据,进行简单的转换处理,然后将处理后的数据加载到另一个数据库中。下面是一个基于Java的简单的案例代码:
```java
// 数据抽取
Connection sourceConn = DriverManager.getConnection(sourceUrl, username, password);
Statement sourceStmt = sourceConn.createStatement();
ResultSet rs = sourceStmt.executeQuery("SELECT * FROM SourceTable");
// 数据转换
List<DataObject> dataList = new ArrayList<>();
while (rs.next()) {
DataObject data = new DataObject();
data.setId(rs.getInt("id"));
data.setName(rs.getString("name"));
// 进行数据清洗、格式化等转换操作
// ...
dataList.add(data);
}
// 数据加载
Connection targetConn = DriverManager.getConnection(targetUrl, username, password);
PreparedStatement targetStmt = targetConn.prepareStatement("INSERT INTO TargetTable(id, name) VALUES(?, ?)");
for (DataObject data : dataList) {
targetStmt.setInt(1, data.getId());
targetStmt.setString(2, data.getName());
targetStmt.executeUpdate();
}
```
**代码说明**:上述代码演示了通过Java语言实现了简单的数据抽取、转换、加载过程,分别连接源数据库和目标数据库,进行数据的提取、转换和加载操作。
**代码总结**:Cognos数据管理平台作为功能强大的数据管理解决方案,能够帮助用户简化ETL工作流程,提高数据处理效率和质量。
**结果说明**:通过Cognos数据管理平台,用户可以通过可视化的界面来实现数据抽取、转换和加载,而无需编写复杂的代码,极大地提高了数据处理的效率和可靠性。
以上是Cognos数据管理平台在ETL工作流程中的简单应用案例分析和相关代码示例。
### 第三章:ETL工作流程详解
在数据管理中,ETL(Extract-Transform-Load)工作流程是非常重要的环节,它涉及数据从源系统抽取、进行清洗和转换,最终加载到目标数据库中。下面我们将详细解释ETL工作流程的每个步骤。
#### 3.1 数据抽取(Extract)
数据抽取是ETL过程中的第一步,它涉及从一个或多个数据源中提取数据,并将提取的数据保存在临时存储区域。数据抽取可以通过不同的方式进行,比如增量抽取、全量抽取等。在这个步骤中,我们需要考虑到数据源的类型(数据库、文件、API等)、数据体量以及抽取频率等因素。
下面是一个使用Python实现数据抽取的简单示例:
```python
import pandas as pd
import pymysql
# 连接到MySQL数据库
db = pymysql.connect("localhost", "user", "password", "database")
cursor = db.cursor()
# 执行数据查询
sql = "SELECT * FROM employee"
cursor.execute(sql)
# 读取数据到Pandas DataFrame
data = cursor.fetchall()
df = pd.DataFrame(data, columns=cursor.column_names)
# 关闭数据库连接
db.close()
# 将数据保存到CSV文件
df.to_csv('employee_data.csv', index=False)
```
上述代码通过Python连接到MySQL数据库,执行查询操作并将数据保存为CSV文件,这就是一个简单的数据抽取过程。
#### 3.2 数据转换(Transform)
数据抽取后,接下来是数据转换过程。在这个步骤中,我们对抽取的数据进行清洗、整合、转换等操作,以满足目标数据库的需求。数据转换需要考虑到数据质量、格式转换、数据聚合等方面。
下面是一个使用Java实现数据转换的简单示例:
```java
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class DataTransformation {
public static void main(String[] args) {
List<String> transformedData = new ArrayList<>();
try (BufferedReader br = new BufferedReader(new FileReader("employee_data.csv"))) {
String line;
while ((line = br.readLine()) != null) {
// 对数据进行清洗与转换
String[] values = line.split(",");
String transformed = values[0] + "," + values[1].toUpperCase() + "," + values[2];
transformedData.add(transformed);
}
} catch (IOException e) {
e.printStackTrace();
}
// 将转换后的数据写入新文件
try (FileWriter writer = new FileWriter("transformed_employee_data.csv")) {
for (String line : transformedData) {
writer.write(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
上述代码通过Java读取CSV文件,对数据进行转换(将姓名转换为大写),最后将转换后的数据写入新文件。
#### 3.3 数据加载(Load)
数据转换完成后,最后一个步骤是将处理后的数据加载到目标数据库中。在这个过程中,我们需要考虑数据加载的效率、事务处理、错误处理等问题。
下面是一个使用Go语言实现数据加载的简单示例:
```go
package main
import (
"database/sql"
"encoding/csv"
"fmt"
"os"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// 连接到MySQL数据库
db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/database")
if err != nil {
panic(err.Error())
}
defer db.Close()
// 打开CSV文件
file, err := os.Open("transformed_employee_data.csv")
if err != nil {
panic(err)
}
defer file.Close()
// 读取CSV文件数据并插入数据库
reader := csv.NewReader(file)
records, err := reader.ReadAll()
if err != nil {
panic(err)
}
for _, record := range records {
stmt, err := db.Prepare("INSERT INTO employee (id, name, salary) VALUES (?, ?, ?)")
if err != nil {
panic(err)
}
_, err = stmt.Exec(record[0], record[1], record[2])
if err != nil {
panic(err)
}
fmt.Println("Loaded data:", record)
}
}
```
上述代码使用Go语言连接到MySQL数据库,读取转换后的CSV文件并将数据加载到数据库中。
### 4. 第四章:Cognos数据集成的最佳实践
在数据管理领域,数据集成是一个至关重要的环节。Cognos数据管理平台作为一种强大的ETL工具,拥有丰富的功能和灵活的应用,能够帮助企业高效实现数据集成。本章将重点探讨Cognos数据集成的最佳实践,包括数据集成的挑战与解决方案、使用Cognos数据管理平台实现数据集成的优势,以及Cognos数据集成的最佳实践与案例分享。
#### 4.1 数据集成的挑战与解决方案
在实际的数据集成过程中,往往会面临诸多挑战,如数据格式不一致、数据质量低、数据量大等问题,这些都会影响数据集成的效率和质量。针对这些挑战,Cognos数据管理平台提出了一系列解决方案:
- **数据清洗与转换:** Cognos提供了丰富的数据转换工具,可以对数据进行清洗、格式转换、字段映射等操作,从而解决不同数据源格式不统一的问题。
- **数据质量控制:** Cognos集成了数据质量管理模块,能够对数据进行质量检查和评估,及时发现并解决数据质量问题。
- **增量更新与同步:** Cognos支持增量数据更新和实时数据同步,可以确保目标数据库中的数据与源数据保持同步。
#### 4.2 使用Cognos数据管理平台实现数据集成的优势
相比传统的数据集成方案,使用Cognos数据管理平台实现数据集成具有诸多优势:
- **快速搭建集成流程:** Cognos提供了友好的可视化界面,用户可以通过拖拽方式快速搭建数据集成流程,无需编写复杂的代码。
- **强大的数据连接能力:** Cognos支持各种数据源的连接,包括关系型数据库、NoSQL数据库、文件存储等,能够轻松实现不同数据源的数据集成。
- **灵活的调度与监控:** Cognos提供了完善的调度和监控机制,能够灵活设置数据集成流程的调度时间和频率,并实时监控数据集成的执行情况。
#### 4.3 Cognos数据集成的最佳实践与案例分享
在实际应用中,许多企业都通过Cognos数据管理平台实现了高效的数据集成。以某电商企业为例,他们利用Cognos平台对各个业务系统的数据进行集成和整合,使得销售、库存、物流等数据能够快速汇聚并进行实时分析,极大地提升了运营效率和决策能力。在具体实现过程中,他们充分利用Cognos提供的数据清洗、转换、质量管理等功能,构建了稳定高效的数据集成流程,并取得了显著的业务成效。
通过以上最佳实践案例的分享,可以看出Cognos数据管理平台在数据集成方面的强大能力和优势,对于企业实现高效数据集成具有重要意义。在实际应用中,企业可以根据自身的数据集成需求,充分发挥Cognos平台的功能和特点,实现定制化的数据集成解决方案。
### 5. 第五章:ETL工作流程中的常见问题与应对策略
在ETL工作流程中,常常会碰到一些挑战和问题,例如数据质量问题、性能优化、容错与数据恢复机制等。本章将详细讨论这些常见问题,并提出有效的应对策略。
#### 5.1 数据质量问题的识别与解决
数据质量是ETL工作中至关重要的一环,常见的数据质量问题包括缺失值、重复值、异常值、格式不正确等。这些问题可能导致数据分析和业务决策的不准确性,因此需要及时识别和解决。
```python
# 举例:使用Python Pandas库识别缺失值并进行处理
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 检测缺失值
missing_values = data.isnull().sum()
# 处理缺失值,例如填充或删除
cleaned_data = data.fillna(0) # 填充缺失值为0
```
**代码总结:** 以上代码使用Python的Pandas库实现了对数据中的缺失值进行识别和处理,可以根据实际情况选择合适的缺失值处理方法。
**结果说明:** 经过缺失值处理后,数据质量得到了提升,减少了对后续分析的影响。
#### 5.2 性能优化与提升
在大规模数据处理的场景下,ETL作业的性能优化至关重要。常见的性能优化策略包括合理设计数据处理流程、优化查询语句、合理使用索引等。
```java
// 举例:使用Java编写的ETL作业中的数据查询优化
// 使用合适的索引
CREATE INDEX idx_customer_id ON sales_data(customer_id);
// 设计高效的查询语句
SELECT * FROM sales_data WHERE order_date >= '2022-01-01' AND order_date <= '2022-12-31';
```
**代码总结:** 以上Java代码展示了在数据库中对索引和查询语句进行优化的示例。
**结果说明:** 经过性能优化后,ETL作业的执行效率得到了显著提升,加快了数据处理的速度。
#### 5.3 容错与数据恢复机制
在ETL工作中,由于网络、硬件故障等原因,可能会出现数据处理中断或数据丢失的情况,因此需要建立完善的容错与数据恢复机制,保障数据处理的稳定性和可靠性。
```javascript
// 举例:使用JavaScript编写的数据恢复机制代码示例
try {
// 执行数据加载操作
loadData();
} catch (error) {
// 出现异常时进行数据恢复操作
recoverData();
}
```
**代码总结:** 上述JavaScript代码展示了在数据加载过程中捕获异常并进行数据恢复的示例。
**结果说明:** 通过完善的容错与数据恢复机制,可以有效应对数据处理过程中可能出现的异常情况,确保数据的完整性和一致性。
以上是ETL工作流程中常见问题的应对策略,合理应对这些挑战可以保障ETL作业的顺利执行和数据质量的可靠性。
### 6. 第六章:未来发展趋势与思考
数据管理领域一直在不断发展和演进,ETL工作流程与数据集成作为其中重要的一环,也在持续地融合新技术、应用新理念。在未来的发展中,我们可以对以下方面进行思考和展望。
#### 6.1 新一代ETL工具的出现与发展
随着大数据、云计算、人工智能等新技术的快速发展,传统的ETL工具在面对日益复杂的数据处理需求时可能会遇到瓶颈。因此,未来新一代ETL工具可能会更加注重高性能、分布式计算、自动化运维等方面的发展,以更好地适应大数据时代的挑战。
#### 6.2 数据集成在人工智能和大数据背景下的应用
随着人工智能和大数据技术的不断成熟,数据集成将在更多的场景下得到应用。例如,在智能推荐系统中,数据集成可以帮助将用户行为数据、商品信息数据、推荐算法处理结果等进行高效地整合,为用户提供个性化的推荐服务。
#### 6.3 Cognos数据管理在数据集成领域的未来发展方向
Cognos作为业界知名的数据管理平台,未来在数据集成领域可能会持续加强与各种数据存储、处理、分析等系统的整合,提供更灵活、高效的数据集成解决方案。同时,结合人工智能技术,Cognos可能会在数据质量管理、数据变化识别等方面实现更智能化的数据集成流程。
未来,随着技术的进步和需求的变化,数据集成领域将会迎来更多挑战和机遇,我们期待Cognos数据管理平台能够在其中发挥越来越重要的作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏标题为"Cognos",该专栏以Cognos为基础,涵盖了各个方面的知识和技术。文章包括"Cognos报表技术基础:数据模型与报表设计"、"创建交互式仪表板:Cognos仪表板设计入门"、"Cognos数据管理:ETL工作流程与数据集成"、"Cognos高级报表设计技巧:参数与过滤器"等。此外还包括"Cognos Cube教程:多维数据分析入门"、"Cognos图表设计指南:数据可视化最佳实践"、"Cognos分析器高级功能:深入了解数据挖掘"等内容。专栏还包含"Cognos移动BI应用开发:在移动设备上展现数据洞察"、"基于Cognos的企业信息管理(EIM)解决方案"、"Cognos数据可视化:深度挖掘数据洞察"以及"Cognos报表优化技巧:性能调优与优化策略"等实用技巧。此外还探讨了"Cognos管理与监控:系统部署与维护指南"、"Cognos安全性管理:用户权限与数据保护"、"Cognos数据模型设计最佳实践"等内容。专栏还涉及"Cognos报表与分析嵌入式开发实践"、"Cognos与大数据集成:Hadoop、Spark与Cognos的结合应用"。无论是初学者还是有经验的用户,该专栏都提供了全面的知识和技术指导,帮助读者深入了解Cognos的应用和优化策略。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【HDMI全版本特性对比】:哪个版本最适合你的设备?

# 摘要
随着数字多媒体技术的快速发展,HDMI技术已成为家庭娱乐和专业显示设备中不可或缺的标准接口。本文首先概述了HDMI技术的发展历程及其在不同设备上的应用情况。随后,详细分析了HDMI从早期版本到最新2.1版本的特性及其性能进步,特别是对高刷新率、高分辨率支持和新增的动态HDR及eARC功能进行了探讨。同时,本文提供了针对不同设备需求的HDMI版本选择指南,以便用户根据设备支持和使用场景做出
电路设计精英特训:AD7490数据手册精读与信号完整性

# 摘要
本文详细探讨了AD7490数据手册的技术细节,并深入分析了其电气特性,包括输入输出特性、电源和电流要求以及精度和噪声性能。同时,
SAP采购订单自动化外发秘籍:4个最佳实践加速流程优化

# 摘要
本文全面概述了SAP采购订单自动化的过程,从基础的采购订单工作原理和关键组件的理解,到自动化工具与技术的选型,再到实施自动化采购流程的最佳实践案例分析。文章深入探讨了如何通过自动化提升审批流程效率、管理供应商和物料数据,以及与第三方系统的集成。此外,本文还强调了自动化部署与维护的重要性,并探讨了未来利用人工智能
【ZYNQ_MPSoc启动稳定性提升秘方】:驱动优化实践与维护策略

# 摘要
本文综合探讨了ZYNQ MPSoC的启动过程、启动稳定性及驱动优化实践,并提出了相应的维护策略和最佳实践。首先,概述了ZYNQ MPSoC的架构特点及其启动序列,分析了影响启动稳定性的关键因素,包括硬件故障和软件错误,并提出了诊断和解决方法。随后,文章重点讨论了驱动优化的各个方面,如环境搭建、功能测试、加载顺序调整以及内存和性能优化。此外,本文还探讨
STEP7 MicroWIN SMART V2.8 常见问题一站式解决指南:安装配置不再难
# 摘要
本文详细介绍了西门子STEP7 MicroWIN SMART V2.8软件的安装、配置、优化及常见问题诊断与解决方法。通过对软件概述的阐述,引导读者了解软件界面布局与操作流程。章节中提供了安装环境和系统要求的详细说明,包括硬件配置和操作系统兼容性,并深入到安装过程的每一步骤,同时对于卸载与重新安装提供了策略性建议。软件的配置与优化部分,涵盖了项目创建与管理的最佳实践,及性能提升的实用策略。针对实际应用,本文提供了一系列实践应用案例,并通过案例研究与分析,展示了如何在自动化控制系统构建中应用软件,并解决实际问题。最后,本文还探讨了进阶功能探索,包括编程技巧、集成外部硬件与系统的策略,以
信号完整性分析实战:理论与实践相结合的7步流程
# 摘要
本文综述了信号完整性(SI)的基本概念、问题分类、理论模型、分析工具与方法,并通过实战演练,展示了SI分析在高速电路设计中的应用和优化策略。文章首先概述了SI的基础知识,然后深入探讨了信号时序、串扰和反射等问题的理论基础,并介绍了相应的理论模型及其数学分析方法。第三章详细介绍了当前的信号完整性仿真工具、测试方法及诊断技巧。第四章通过两个实战案例分析了信号完
计算机体系结构中的并发控制:理论与实践
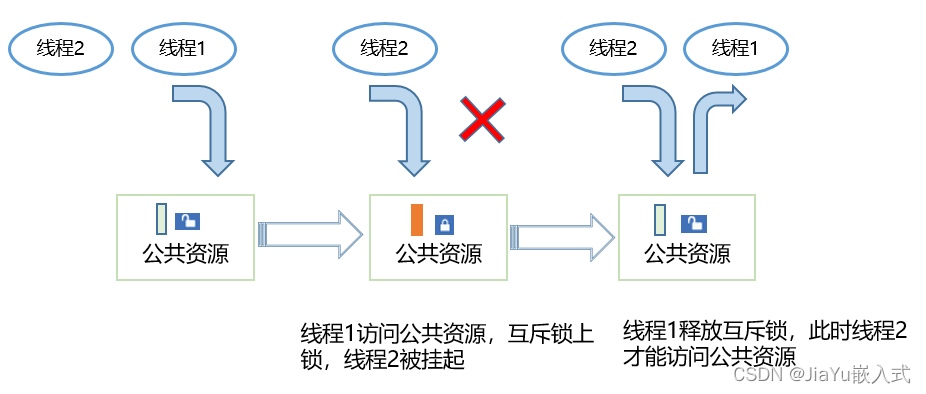
# 摘要
并发控制是计算机科学中确保多个计算过程正确运行的重要机制,对于保障数据一致性和系统性能具有关键作用。本文系统性地探讨了并发控制的基本概念、理论基础、技术实现以及优化策略,并通过实践案例分析,深入理解并发控制在数据库、分布式系统以及现代编程语言中的应用。同时,文章也展望了并发控制的未来发展趋势,特别是在新兴技术如量子计算和人工智能领域的影响,以及跨学科研究和开源社区的潜在贡献。通过对并发控制全面的分析和讨论,本文旨在为相关领
FA-M3 PLC项目管理秘籍:高效规划与执行的关键

# 摘要
本文以FA-M3 PLC项目为研究对象,系统地阐述了项目管理的理论基础及其在PLC项目中的具体应用。文中首先概述了项目管理的核心原则,包括项目范围、时间和成本的管理,随后详细讨论了组织结构和角色职责的安排,以及风险管理策略的制定。在此基础上,本文进一步深入
探索Saleae 16 的多通道同步功能:实现复杂系统的调试
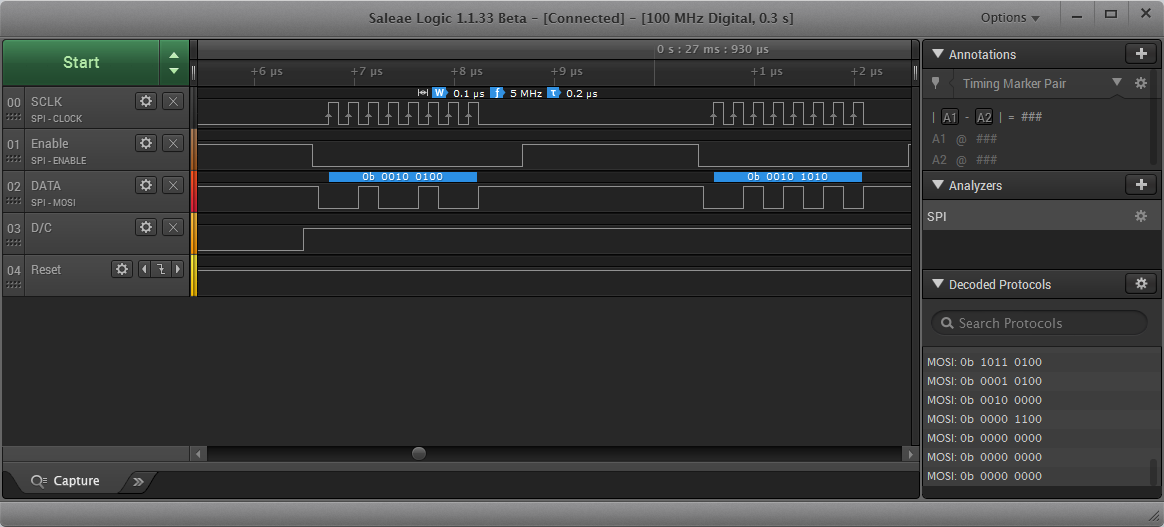
# 摘要
本文详细介绍了Saleae 16的同步功能及其在复杂系统调试中的应用。文章首先概述了Saleae 16的基本信息和同步功能,随后深入探讨了同步机制的理论基础和实际操作。文中详细分析了同步过程中的必要性、多通道同步原理、数据处理、以及设备连接和配置方法。第三章通过实际操作案例,讲解了同步捕获与数据解析的过程以及高级应用。第四章着重探讨了Saleae 16在复杂系统调试中的实际应用场景,包括系统级调试
【数据库性能提升大揭秘】:索引优化到查询调整的完整攻略
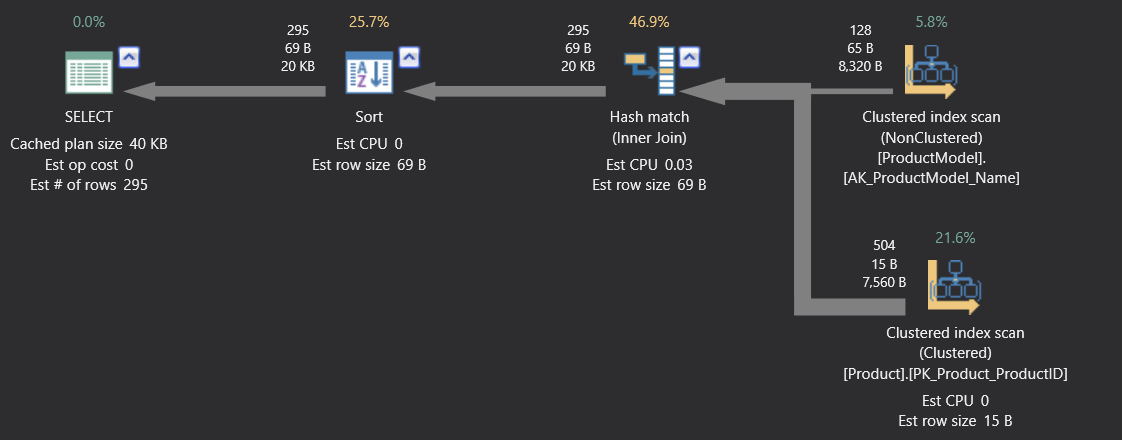
# 摘要
数据库性能问题是一个多维度的复杂问题,本论文从多个角度进行了深入分析,并提出了对应的优化策略。首先,文章分析了索引优化的核心理论与实践,探讨了索引的工作原理、类型选择、设计技巧以及维护监控。接着,对SQL查询语句进行了深度剖析与优化,包括查询计划解析、编写技巧和预处理语句应用。第四章详述了数据库参数调整与配置优化,以及高级配置选项。第五章讨论了数据模型与架构的性能优化,重点分析了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )