Python自然语言处理:深入理解文本处理和语言模型,构建智能文本处理应用
发布时间: 2024-06-22 00:48:58 阅读量: 83 订阅数: 42 

Python文本分析与自然语言处理实战:技术、工具与实践

# 1. 自然语言处理基础**
自然语言处理(NLP)是一门计算机科学领域,它使计算机能够理解、解释和生成人类语言。NLP 的目标是让计算机能够与人类进行自然而有效的交流。
NLP 的核心任务包括:
- **文本处理:**对文本数据进行预处理、特征提取和相似度计算。
- **语言建模:**学习语言的统计规律,以生成类似人类的文本或预测单词序列。
- **自然语言理解:**理解文本的含义,提取事实和关系。
- **自然语言生成:**生成流畅、连贯的文本。
# 2. 文本处理技术
文本处理技术是自然语言处理的基础,它涉及对文本进行预处理、特征提取和相似度计算等操作。
### 2.1 文本预处理
文本预处理是文本处理的第一步,它将文本转换为一种适合后续处理的格式。
#### 2.1.1 分词和词性标注
分词是将文本分割成一个个词语的过程,而词性标注则是为每个词语标注其词性(如名词、动词、形容词等)。
```python
import nltk
text = "Natural language processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human (natural) languages."
# 分词
tokens = nltk.word_tokenize(text)
print(tokens)
# 词性标注
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)
```
**代码逻辑分析:**
* `nltk.word_tokenize()` 函数将文本分割成词语列表。
* `nltk.pos_tag()` 函数为每个词语标注词性。
**参数说明:**
* `text`: 输入文本。
#### 2.1.2 停用词处理
停用词是一些常见的、不具有实际意义的词语,如“the”、“and”、“of”等。在文本处理中,通常需要去除停用词,以提高处理效率和准确性。
```python
import nltk
# 停用词列表
stopwords = nltk.corpus.stopwords.words('english')
# 去除停用词
filtered_tokens = [token for token in tokens if token not in stopwords]
print(filtered_tokens)
```
**代码逻辑分析:**
* `nltk.corpus.stopwords.words('english')` 获取英语停用词列表。
* 列表解析式 `[token for token in tokens if token not in stopwords]` 遍历词语列表,并过滤掉停用词。
**参数说明:**
* `tokens`: 输入词语列表。
### 2.2 文本特征提取
文本特征提取是将文本转换为数字特征的过程,以便计算机能够理解和处理。
#### 2.2.1 词袋模型
词袋模型是最简单的文本特征提取方法,它将文本表示为一个词语计数向量。
```python
from sklearn.feature_extraction.text import CountVectorizer
# 创建词袋模型
vectorizer = CountVectorizer()
# 将文本转换为词袋模型
X = vectorizer.fit_transform([text])
# 获取特征名称
feature_names = vectorizer.get_feature_names_out()
# 打印词袋模型
print(X.toarray())
print(feature_names)
```
**代码逻辑分析:**
* `CountVectorizer()` 类创建词袋模型。
* `fit_transform()` 方法将文本转换为词袋模型。
* `get_feature_names_out()` 方法获取特征名称。
* `toarray()` 方法将词袋模型转换为 NumPy 数组。
**参数说明:**
* `text`: 输入文本。
#### 2.2.2 TF-IDF
TF-IDF(词频-逆文档频率)是一种改进的词袋模型,它考虑了词语在文本和文档集中的重要性。
```python
from sklearn.feature_extraction.text import TfidfTransformer
# 创建 TF-IDF 变换器
transformer = TfidfTransformer()
# 将词袋模型转换为 TF-IDF 模型
X_tfidf = transformer.fit_transform(X)
# 打印 TF-IDF 模型
print(X_tfidf.toarray())
```
**代码逻辑分析:**
* `TfidfTransformer()` 类创建 TF-IDF 变换器。
* `fit_transform()` 方法将词袋模型转换为 TF-IDF 模型。
* `toarray()` 方法将 TF-IDF 模型转换为 NumPy 数组。
**参数说明:**
* `X`: 输入词袋模型。
### 2.3 文本相似度计算
文本相似度计算是衡量两个文本相似程度的过程。
#### 2.3.1 余弦相似度
余弦相似度是一种基于向量夹角余弦值的相似度计算方法。
```python
from sklearn.metrics.pairwise import cosine_similarity
# 计算两个文本的余弦相似度
similarity = cosine_similarity(X_tfidf[0], X_tfidf[1])
# 打印余弦相似度
print(similarity)
```
**代码逻辑分析:**
* `cosine_similarity()` 函数计算两个向量的余弦相似度。
**参数说明:**
* `X_tfidf[0], X_tfidf[1]`: 输入的两个 TF-IDF 模型。
#### 2.3.2 欧氏距离
欧氏距离是一种基于两个向量之间距离的相似度计算方法。
```python
from sklearn.metrics.pairwise import euclidean_distances
# 计算两个文本的欧氏距离
distance = euclidean_distances(X_tfidf[0], X_tfidf[1])
# 打印欧氏距离
print(distance)
```
**代码逻辑分析:**
* `euclidean_distances()` 函数计算两个向量的欧氏距离。
**参数说明:**
* `X_tfidf[0], X_tfidf[1]`: 输入的两个 TF-IDF 模型。
# 3.1 概率语言模型
### 3.1.1 N-gram模型
N-gram模型是一种概率语言模型,它将文本序列划分为连续的N个单词的序列,并计算每个N-gram在文本中出现的概率。例如,对于文本序列"自然语言处理",一个3-gram模型将生成以下N-gram序列:
- 自然语言
- 语言处理
N-gram模型的概率分布可以表示为:
```
P(w_1, w_2, ..., w_n) = P(w_1) * P(w_2 | w_1) * ... * P(w_n | w_1, w_2, ..., w_{n-1})
```
其中,`w_i`表示第`i`个单词。
N-gram模型的优点在于其简单性和易于实现。然而,它也有一些缺点,例如:
- 数据稀疏性:随着N的增加,N-gram的组合数量呈指数增长,这可能导致数据稀疏性。
- 缺乏上下文信息:N-gram模型只考虑局部上下文信息,而忽略了更广泛的文本结构。
### 3.1.2 隐马尔可夫模型
隐马尔可夫模型(HMM)是一种概率图模型,它假设观测序列是由一个隐藏的马尔可夫链产生的。在NLP中,HMM被用于建模文本序列,其中观测序列是单词序列,而隐藏状态是词性或句法类别。
HMM的概率分布可以表示为:
```
P(O, S) = P(s_0) * \prod_{i=1}^n P(s_i | s_{i-1}) * P(o_i | s_i)
```
其中,`O`是观测序列,`S`是隐藏状态序列,`s_0`是初始状态,`o_i`是第`i`个观测值,`s_i`是第`i`个隐藏状态。
HMM的优点在于其能够捕获文本序列中的长期依赖关

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这篇专栏以“vscode设置python环境”为题,旨在指导读者如何为 Visual Studio Code(VSCode)设置 Python 开发环境。专栏中还包含了“VS Code Python插件推荐:10款必备工具,提升开发效率”一文,介绍了 10 款提升 Python 开发效率的 VSCode 插件。通过阅读这篇专栏,读者可以了解如何设置 VSCode Python 环境,并使用推荐的插件提高开发效率,从而提升 Python 开发体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
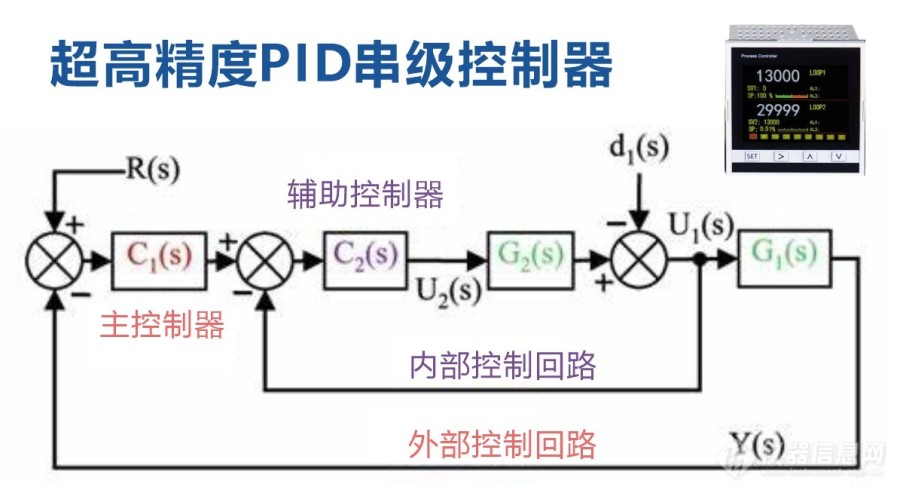
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
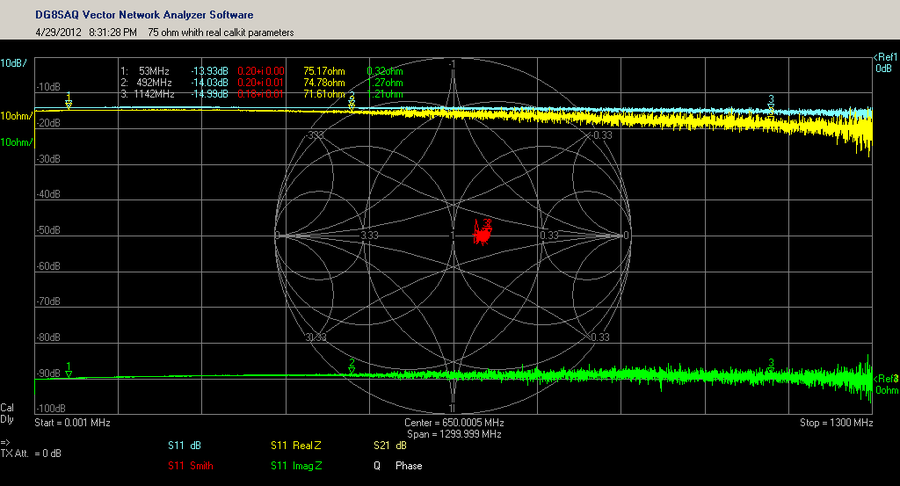
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )