MySQL大规模数据处理秘籍:高效导入导出的技巧与工具
发布时间: 2024-12-06 17:11:24 阅读量: 7 订阅数: 14 

MySQL数据导入导出方法与工具mysqlimport.docx

# 1. MySQL数据处理的基础知识
在构建和维护现代数据库系统时,熟练掌握MySQL的数据处理技术是至关重要的。本章节将带你走进MySQL数据处理的世界,概述数据处理的核心概念,帮助你构建坚实的基础知识。我们将从数据类型、表结构设计开始,逐步过渡到事务处理、索引使用以及查询优化,为你打开数据库高效操作的大门。
## 1.1 MySQL的数据类型和表结构设计
在设计数据库表结构时,选择合适的数据类型是至关重要的。不同的数据类型将影响数据存储的空间效率和查询性能。例如,`INT`类型适合存储整数,而`VARCHAR`类型则用于存储可变长度的字符串数据。在设计阶段,应根据实际业务需求以及数据特征来决定数据类型和字段长度。
## 1.2 事务处理与一致性保障
事务是数据库管理系统执行过程中的一个逻辑单位,它由一系列操作组成。事务的特性包括原子性、一致性、隔离性和持久性(ACID属性)。MySQL通过InnoDB存储引擎提供了对事务的支持,确保了数据操作的可靠性和一致性。
## 1.3 索引的创建和使用
索引是数据库中的一个特殊结构,用于加快数据检索速度。创建合适的索引可以显著提升查询性能,但索引也会增加写操作的成本。因此,理解索引的工作原理以及如何合理使用索引对于优化MySQL数据库至关重要。常见的索引类型包括主键索引、唯一索引和复合索引。
在接下来的章节中,我们将深入探讨MySQL数据导入和导出的高效技巧,揭示如何在大规模数据处理中进行性能优化,并了解实际应用中各种数据处理工具的用法和优势。通过最佳实践和案例分析,你可以将这些知识应用到实际工作中,提升自己的专业技能。
# 2. 高效的数据导入技巧
在现代的IT环境中,数据导入不仅是数据库管理的基本任务,而且对于数据密集型应用程序来说至关重要。本章将详细介绍如何高效地导入MySQL数据,包括基础方法和大规模数据导入的性能优化。
## 2.1 MySQL数据导入的基本方法
### 2.1.1 使用LOAD DATA INFILE进行数据导入
`LOAD DATA INFILE` 是MySQL中用于快速导入数据的SQL命令。它比逐行插入数据的方式要高效得多,特别是对于大量数据。
```sql
LOAD DATA INFILE '/path/to/data.txt'
INTO TABLE table_name
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
```
#### 参数解释:
- `/path/to/data.txt`:数据文件的路径。
- `INTO TABLE table_name`:指明数据将被导入到哪个表。
- `FIELDS TERMINATED BY ','`:字段分隔符,根据数据文件的实际分隔符修改。
- `ENCLOSED BY '"'`:字段引用字符,如果有的话,确保与数据文件匹配。
- `LINES TERMINATED BY '\n'`:行终止符,根据操作系统调整。
- `IGNORE 1 ROWS`:跳过文件的第一行(通常包含列名)。
这个命令可以一次性加载整个文件,极大地加快了数据导入速度。务必确保数据文件格式与命令中指定的格式匹配。
### 2.1.2 利用外部工具如Mydumper进行高效导入
除了MySQL自带的工具,第三方工具Mydumper也非常受欢迎。它支持多线程导出和导入,可以显著提升大规模数据导入的速度。
```bash
mydumper -c -e -o /path/to/export_folder
```
#### 参数解释:
- `-c` 表示启用压缩导出。
- `-e` 表示启用导出过程中的错误检查。
- `-o` 指定输出的目录。
对于导入,你可以使用myloader:
```bash
myloader -d /path/to/export_folder -o -t 16
```
#### 参数解释:
- `-d` 指定导入的目录。
- `-o` 表示覆盖已存在的表。
- `-t` 指定并发导入的线程数。
Mydumper和Myloader结合使用可以实现高速、稳定的导入和导出,它们利用多线程处理,优化了锁的使用,减少了单线程导入时的性能瓶颈。
## 2.2 大规模数据导入的性能优化
### 2.2.1 优化服务器配置以提升导入速度
优化服务器配置对于大规模数据导入来说至关重要。以下是一些关键点:
- 增加MySQL的缓冲池(innodb_buffer_pool_size)大小,以减少磁盘I/O操作。
- 增加排序缓冲区(sort_buffer_size)和读缓冲区(read_buffer_size)可以优化排序和临时表操作。
- 使用`innodb_flush_log_at_trx_commit=0`或`2`以牺牲一点数据安全为代价来提升性能,具体取决于业务需求。
### 2.2.2 数据索引和存储引擎的选择对导入效率的影响
在数据导入之前,选择合适的索引和存储引擎可以显著影响性能:
- `InnoDB` 是通用的选择,支持事务,但是创建和维护索引需要时间。对于导入大量数据,可以考虑暂时禁用索引和外键约束。
- `MyISAM` 速度较快,但不支持事务。在数据导入完成后,可以考虑将数据表转换为 `InnoDB`。
### 2.2.3 采用分批导入减少锁表时间和空间消耗
分批导入是将数据分成小批次导入的一种策略,可以有效减少长时间持有锁的需要。以下是实现分批导入的一种方法:
```sql
SET @a=0;
LOAD DATA INFILE '/path/to/data.txt'
INTO TABLE table_name
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
WHERE @a:=@a+1 LIMIT 1000;
```
在这个例子中,使用了一个变量 `@a` 来跟踪导入的行数,并通过 `LIMIT` 限制每次导入的行数。这样可以避免长时间的锁表,并且可以在不影响性

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 在大数据环境中的应用,提供了全面的指南,帮助用户应对大数据带来的挑战。专栏涵盖了 MySQL 的 10 大应用秘籍,包括性能提升和优化策略。它揭示了 MySQL 大数据扩展技术,提供了应对大数据挑战的终极指南。专栏还介绍了大数据场景下的 MySQL 性能优化实践,阐述了 MySQL 集群架构在大数据环境下的升级,确保高可用性和可扩展性。此外,专栏还详解了 MySQL 大数据分片策略,分析了水平和垂直分片的权衡与应用。它探讨了云计算环境下 MySQL 的崛起,以及大数据服务的新趋势与实践。专栏还提供了 MySQL 数据安全全面策略,保障数据资产安全。它介绍了 MySQL 数据压缩技术,节省存储并加速数据处理。专栏深入分析了流处理中 MySQL 的威力,作为实时大数据分析的核心技术。它提供了大数据分析与 MySQL 的技巧,提升 SQL 优化和查询性能。专栏还分享了 MySQL 大规模数据处理秘籍,高效导入导出技巧和工具。最后,专栏探讨了大数据中的 MySQL 事务管理,在保证一致性的同时提升性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Fluent安装与配置全攻略】:第三章深入详解与最佳实践

参考资源链接:[Fluent 中文帮助文档(1-28章)完整版 精心整理](https://wenku.csdn.net/doc/6412b6cbbe7fbd1778d
【信号完整性与布线】:等长布线的原理与实践,专家级分析
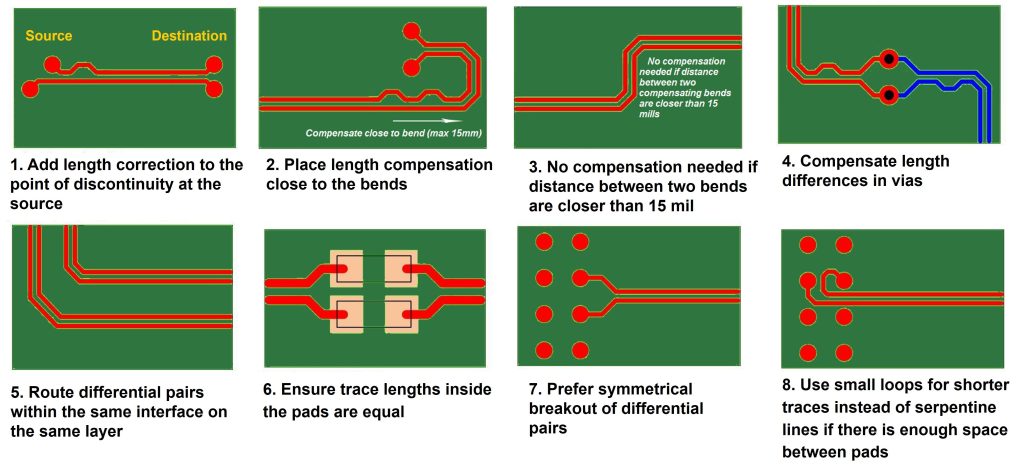
参考资源链接:[PCIe/SATA/USB布线规范:对内等长与延迟优化](https://wenku.csdn.net/doc/6412b727be7fbd1778d49479?spm=1055.2635.3001.10343)
# 1. 信号完整性与布线基础
## 1.1 信号完整性简介
在高速数
WinCC 7.2 Web发布与SCADA系统集成:实现工业自动化无缝对接

参考资源链接:[Wincc7.2Web发布操作介绍.docx](https://wenku.csdn.net/doc/6412b538be7fbd1778d425f9?spm=1055.2635.3001.10343)
# 1. WinCC 7.2 Web发布概述
随着工业4.0的推进,Web发布技术已成为连接企业与工业自动化系统的关键桥梁。WinCC 7.2作为一个工业自动化领域的强大工具,其Web发布功能为企业提供
【代码审查的艺术】:提升代码质量的有效方法

参考资源链接:[DeST学习指南:建筑模拟与操作详解](https://wenku.csdn.net/doc/1gim1dzxjt?spm=1055.2635.3001.10343)
# 1. 代码审查
【9899-202x并发编程革新】:内存模型与原子操作的全新视角
参考资源链接:[C语言标准ISO-IEC 9899-202x:编程规范与移植性指南](https://wenku.csdn.net/doc/4kmc3jauxr?spm=1055.2635.3001.10343)
# 1. 并发编程与内存模型基础
在现代计算机系统设计中,内存模型是构建高效并发程序不可或缺的基础。理解内存模型能帮助开发者编写出更加稳定、高效的并发代码。本章从基础层面探讨并发编程的基本概念,引入内存模型的概念,并简要介绍其在现代计算机系统中的重要性。
## 1.1 并发编程简介
并发编程是多线程或多进程环境下的一种编程范式。随着多核处理器的普及,合理利用并发技术已成为提升程序
【ITK-SNAP多模式应用】:不同类型图像抠图及Mask保存的策略(全面分析)
参考资源链接:[ITK-SNAP教程:图像背景去除与区域抠图实例](https://wenku.csdn.net/doc/64534cabea0840391e779498?spm=1055.2635.3001.10343)
# 1. ITK-SNAP简介及多模式图像处理基础
## 1.1 ITK-SNAP概述
ITK-SNAP是一个广泛应用于医学成像领域的开源软件,它集成了图像分割、3D注册、图像预处理等功能。其直观的用户界面和强大的算法支持,使得它在处理多模式图像时显得尤为出色。
## 1.2 多模式图像处理基础
在医学图像处理中,多模式图像指的是结合使用不同的成像技术得到的一系列图像,
【Windows 7 64位系统秘籍】:精通安装与优化SQL Server 2000的10大技巧

参考资源链接:[Windows7 64位环境下安装SQL Server 2000的步骤](https://wenku.csdn.net/doc/7du6ymw7ni?spm=1055.2635.3001.10343)
# 1
【永磁同步电机:20年经验的终极指南】:深入揭示电机性能与应用的关键

参考资源链接:[永磁同步电机电流与转速环带宽计算详解](https://wenku.csdn.net/doc/nood6mjd91?spm=1055.2635.3001.10343)
# 1. 永磁同步电机的理论基础
永磁同步电机(PMSM)以其高效率、高功率密度和优良的动态性能在现代电机技术中占据着重要地位。本章将对PMSM的基本原理和关键技术要素进行介绍,为后续章节中设计、
【Zynq-7000 SoC新手必读】:5分钟速览UG585,轻松入门Xilinx Zynq

参考资源链接:[ug585-Zynq-7000-TRM.pdf](https://wenku.csdn.net/doc/6401acf3cce7214c316edbe7?spm=1055.2635.3001.10343)
# 1. Zynq-7000 SoC概述
## Zynq-7000 SoC的架构简介
Zynq-700
【九齐单片机定时器_计数器应用】:NYIDE中高级计时技巧

参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐单片机定时器与计数器基础
## 定时器与计数器概述
九齐单片机(如常见的9series)是微电子
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )