软件架构中的模块化设计原则简介
发布时间: 2024-01-26 14:36:17 阅读量: 45 订阅数: 14 
# 1. 引言
## 软件模块化设计的定义
软件模块化设计是指将一个大型软件系统划分为若干功能独立、相互协作的模块,每个模块都具有明确定义的接口,并且模块之间的耦合度尽可能地低,以便实现高内聚、低耦合的软件架构。模块化设计可以使软件系统更易于维护、测试和扩展,提高了系统的灵活性和可重用性。
## 模块化设计在软件架构中的重要性和优势
软件模块化设计在软件架构中具有重要的地位和作用。通过模块化设计,可以将复杂的系统分解为相对独立的模块,降低系统的复杂度,提高系统的可理解性和可维护性。同时,模块化设计也有利于团队协作,不同成员可以专注于不同的模块开发,提高了开发效率。此外,模块化设计还能够提高软件系统的灵活性和可扩展性,减少系统的修改和部署成本,从而更好地适应需求变化和业务发展。
在接下来的章节中,我们将介绍软件模块化设计中的几项重要原则,以及它们在实际开发中的应用和实现方法。
# 2. 单一职责原则(SRP)
单一职责原则是面向对象设计中的一个重要原则,它强调一个类或模块应该有且只有一个职责。SRP原则的核心思想是将一个类的职责划分为多个独立的类,每个类只负责一个职责,这样可以使得类的设计更加灵活、易于维护和扩展。
### 2.1 SRP原则的概念和背景
SRP原则最早由罗伯特·C·马丁(Robert C. Martin)提出,并被广泛应用于软件开发领域。
在传统的编程思想中,一个类经常承担多个职责,这导致了类的耦合度高、复杂度增加、可维护性差等问题。而SRP原则的提出则解决了这些问题,通过将职责分解到不同的类中,使得每个类都可以专注于自己的职责,减少了类之间的依赖和耦合,提高了系统的灵活性和可维护性。
### 2.2 SRP原则在模块化设计中的应用
在模块化设计中,单一职责原则可以帮助我们划分模块的职责,使得每个模块只负责一个明确的功能或任务。这有助于提高代码的可读性、可维护性和可测试性。
以一个简单的日志记录模块为例,我们可以将其划分为两个模块:日志记录器和日志输出器。
```python
# 日志记录器模块
class Logger:
def __init__(self, output):
self.output = output
def log(self, message):
self.output.write(message)
# 日志输出器模块
class FileOutput:
def write(self, message):
# 将日志写入文件
class ConsoleOutput:
def write(self, message):
# 在控制台输出日志
```
上面的代码中,Logger类负责日志记录的具体实现,它将日志信息传递给一个输出器对象进行处理。而FileOutput和ConsoleOutput分别负责将日志信息写入文件和在控制台输出。这样,当需求变更时,我们只需要修改输出器模块而不影响日志记录器模块,符合了SRP原则。
### 2.3 如何实现SRP原则
要实现SRP原则,可以遵循以下几个步骤:
1. 理清类的职责:分析类的功能和任务,确保每个类只负责一个明确的职责。
2. 拆分类的职责:将不同职责拆分为独立的类或模块,通过组合或继承的方式实现职责的划分。
3. 保持职责的独立性:确保每个类只与其需要交互的类进行协作,减少耦合度和依赖关系。
通过遵循SRP原则,我们可以提高代码的可维护性和可扩展性,使得系统更加灵活和可靠。
# 3. 开放封闭原则(OCP)
开放封闭原则是面向对象设计中的一个重要原则,它要求软件中的对象(类、模块、函数等)应该对扩展开放,对修改封闭。简言之,对于程序的扩展是允许的,但是不允许修改程序的源代码。
#### OCP原则的概念和背景
开放封闭原则最早由勃兰特·迈尔(Bertrand Meyer)提出,是面向对象设计五个基本原则(SOLID原则)之一。这个原则在软件工程中非常重要,它可以使软件系统在面临需求变化时更加灵活和适应性更强。
#### OCP原则在模块化设计中的应用
在模块化设计中,OCP原则的应用意味着当需要添加新功能时,不应修改原有的模块,而是通过添加新的模块来扩展系统的功能。这样做的好处是,可以最大限度地减少对现有代码的修改,从而减少系统出错的可能性,并且更容易进行单元测试和维护。
#### 如何实现OCP原则
OCP原则的实现通常需要借助抽象和多态。通过定义抽象的接口或基类,来约束扩展,从而使得扩展是可预期的、无侵入性的。接下来以一个简单的示例来说明开放封闭原则的实现。
```java
// Shape.java
public interface Shape {
double area();
}
// Circle.java
public class Circle implements Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
public double area() {
return Math.PI * radius * radius;
}
}
// Rectangle.java
public class Rectangle implements Shape {
private double width;
private double height;
public Rectangle(double width, double height) {
this.width = width;
this.height = height;
}
public double area() {
return width * height;
}
}
// AreaCalculator.java
import java.util.List;
public class AreaCalculator {
public double totalArea(List<Shape> shapes) {
double totalArea = 0;
for (Shape shape : shapes) {
totalArea += shape.area();
}
return totalArea;
}
}
```
上述代码中,我们定义了一个抽象的`Shape`接口,然后通过`Circle`和`Rectangle`类来实现这个接口。`AreaCalculator`类接收一个`List<Shape>`作为参数,然后计算所有形状的总面积。现在如果需要添加新的形状,比如三角形,我们只需要创建一个新的实现`Shape`接口的类即可,而不需要修改`AreaCalculator`类。
#### 结论
开放封闭原则是软件设计中非常重要的一个原则,它可以使系统更加灵活、可扩展和可维护。通过合理地应用OCP原则,可以使系统更容易适应需求的变化,降低修改现有代码所带来的风险。
以上是对开放封闭原则在模块化设计中的应用说明,下一章节将介绍依赖倒置原则。
# 4. 依赖倒置原则(DIP)
### 4.1 DIP原则的概念和背景
依赖倒置原则(Dependency Inversion Principle, DIP)是面向对象设计中的一条重要原则,它由罗伯特·C·马丁(Robert C. Martin)提出。DIP原则主要强调高层模块不应该依赖低层模块的具体实现细节,而是应该依赖于抽象接口;抽象不应该依赖于具体实现,而是具体实现应该依赖于抽象。
传统的软件设计中,通常是由高层模块直接依赖于底层模块,而底层模块负责具体的实现。这样的设计模式会导致高层模块与底层模块之间产生强耦合,使得系统难以扩展和修改。而使用DIP原则能够将高层模块与底层模块解耦,提高系统的灵活性和可维护性。
### 4.2 DIP原则在模块化设计中的应用
在模块化设计中,DIP原则主要体现在依赖关系的设计上。高层模块应该依赖于抽象接口,而不是具体实现类。这样做的好处是,当底层模块发生变化时,不会影响到高层模块的使用。
举个例子来说,假设我们正在设计一个电商系统,其中包括商品模块和订单模块。传统的设计方式是订单模块直接依赖于商品模块的具体实现,例如:
```java
public class OrderService {
private ProductService productService = new ProductServiceImpl();
public void createOrder(Order order) {
// 调用商品模块的方法
productService.updateProductStock(order.getProduct(), order.getQuantity());
// ...
}
}
```
上述代码中,订单模块直接依赖具体的商品模块实现(ProductServiceImpl类),这样会导致订单模块与商品模块之间产生紧耦合。如果将来需要修改商品模块的实现,就需要修改订单模块的代码。
根据DIP原则,我们可以通过定义一个抽象接口来解耦依赖关系,改进如下:
```java
public interface ProductService {
void updateProductStock(Product product, int quantity);
}
public class OrderService {
private ProductService productService;
public OrderService(ProductService productService) {
this.productService = productService;
}
public void createOrder(Order order) {
// 调用商品模块的方法
productService.updateProductStock(order.getProduct(), order.getQuantity());
// ...
}
}
```
现在,订单模块依赖于抽象接口ProductService,而不再依赖具体的实现类。这样一来,当需要修改商品模块的实现时,只需要提供一个新的实现类,然后将其注入到订单模块中即可,而不需要修改订单模块的代码。
### 4.3 如何实现DIP原则
要实现DIP原则,主要有以下几个步骤:
1. 定义抽象接口:定义一个抽象接口,描述高层模块与底层模块之间的通信方式。
2. 实现接口:编写具体的实现类,实现抽象接口中定义的方法。
3. 高层模块依赖接口:高层模块依赖抽象接口,而不是具体的实现类。
4. 通过依赖注入将具体实现注入到高层模块:使用依赖注入的方式,将具体实现类注入到高层模块中,使其能够使用具体实现。
通过以上步骤,我们可以实现高层模块与底层模块之间的解耦,提高系统的可扩展性和可维护性。
总结一下,DIP原则强调高层模块不应该依赖低层模块,而是应该依赖于抽象接口;抽象不应该依赖于具体实现,而是具体实现应该依赖于抽象。在模块化设计中,通过使用DIP原则,我们能够实现模块之间的解耦,提高系统的灵活性和可维护性。
# 5. 接口隔离原则(ISP)
接口隔离原则(Interface Segregation Principle,简称ISP)是面向对象设计中的一个原则,提出“客户端不应该依赖于它不需要的接口”的观点。该原则旨在减少接口的复杂性,避免出现庞大臃肿的接口。
#### 5.1 ISP原则的概念和背景
ISP原则由罗伯特·C·马丁在《敏捷软件开发:原则、模式与实践》一书中提出。该原则强调了软件设计中接口的合理拆分和组织,以满足不同客户端的特定需要。
在传统的面向对象设计中,通常使用接口(Interface)来定义一组相关的方法。但是有时候一个接口中会包含一些某个特定客户端不需要的方法,这样就造成了接口的冗余和紧耦合。而ISP原则的出发点就是要解决这个问题,让接口更加精细化、可定制化,使得不同的客户端只依赖于它们需要的接口。
#### 5.2 ISP原则在模块化设计中的应用
在模块化设计中,ISP原则可以帮助我们将一个庞大的接口拆分为更小的、更具体的接口。这样做有以下几个好处:
1. 降低模块之间的耦合性:通过将一个庞大的接口拆分为多个小接口,模块之间的依赖性更明确,减少了模块之间的耦合,提高了代码的可维护性和可拓展性。
2. 提高代码的可复用性:通过根据不同的客户端需求定义不同的接口,可以使得代码更加灵活,不同的模块可以根据自己的需求选择性地实现和使用接口,提高了代码的可复用性。
3. 易于理解和维护:由于每个接口都是明确的、具体的,所以更容易理解和维护。开发人员可以更快地定位到自己需要的接口,不会被冗余的接口困扰。
#### 5.3 如何实现ISP原则
要实现ISP原则,我们需要考虑以下几点:
1. 定义清晰的接口:接口应该是模块所提供的一组相关操作的抽象。接口应该足够细分,避免出现冗余和不相关的方法。
2. 避免接口的臃肿:如果一个接口过于庞大,考虑将其拆分为多个更小的接口,每个接口只关注于特定功能点。
3. 根据不同客户端的需求定义不同的接口:考虑不同客户端的需求差异,设计和实现不同的接口,每个客户端只需要依赖于它需要的接口。
下面是一个使用Java实现ISP原则的示例代码:
```java
// 定义一个发送消息的接口
public interface MessageSender {
void sendMessage(String message);
}
// 实现邮件发送功能
public class EmailSender implements MessageSender {
@Override
public void sendMessage(String message) {
// 实现发送邮件的代码逻辑
}
}
// 实现短信发送功能
public class SmsSender implements MessageSender {
@Override
public void sendMessage(String message) {
// 实现发送短信的代码逻辑
}
}
// 实现微信发送功能
public class WeChatSender implements MessageSender {
@Override
public void sendMessage(String message) {
// 实现发送微信消息的代码逻辑
}
}
// 客户端代码
public class Client {
private MessageSender messageSender;
public Client(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendMessage(String message) {
messageSender.sendMessage(message);
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
MessageSender emailSender = new EmailSender();
MessageSender smsSender = new SmsSender();
Client client1 = new Client(emailSender); // 客户端只需要依赖邮件发送接口
Client client2 = new Client(smsSender); // 客户端只需要依赖短信发送接口
client1.sendMessage("Hello, Email!");
client2.sendMessage("Hello, SMS!");
}
}
```
代码解释和总结:
以上示例中,我们定义了一个消息发送的接口`MessageSender`,并分别实现了邮件发送、短信发送和微信发送的功能。每个实现都只关注于具体的发送方式,而不关心其他不相关的方法。客户端根据自己的需求选择性地依赖不同的发送接口,实现了ISP原则。
通过使用ISP原则,我们的代码变得更加可维护、可拓展,并且每个模块的职责更加明确和单一。这种模块化的设计思想可以在各种软件架构中得到应用,提高开发效率和代码质量。
# 6. 迪米特法则(LoD)
迪米特法则(Law of Demeter,简称LoD)也被称为最少知识原则(Least Knowledge Principle,LKP),它是一种软件设计原则,要求一个软件实体应尽可能少地与其他实体发生相互作用。该原则的目的是减少对象之间的耦合度,提高系统的灵活性和可维护性。
#### 6.1 LoD原则的概念和背景
迪米特法则于1987年被Ian Holland和Daniel Smith提出。它源自于一句有名的口号:“只与你的直接朋友交谈,不要跟‘陌生人’说话”。在软件设计中,类似的原则被应用到对象之间的交互上。迪米特法则强调了对象之间应该保持松散的耦合关系,一个对象应该尽可能少地了解其他对象的内部结构和实现细节。
#### 6.2 LoD原则在模块化设计中的应用
在模块化设计中,迪米特法则可以用于控制模块之间的依赖关系,避免模块之间耦合度过高。在实践中,可以通过以下方式应用迪米特法则:
- 模块之间的交互应该通过尽可能少的接口实现,即模块之间只暴露必要的接口,而不暴露过多的内部信息。
- 模块之间的通信应该通过中介者或者事件系统等方式进行,而不直接依赖其他模块的具体实现。
- 避免在模块内部直接访问其他模块的内部数据,而是通过接口和方法的调用进行间接访问。
#### 6.3 如何实现LoD原则
为了实现迪米特法则,我们可以采用以下方法:
- 分析模块之间的依赖关系,并尽量减少模块之间的直接依赖。
- 使用间接的方式进行模块之间的交互,比如通过接口、事件或者消息队列。
- 尽量避免在一个模块内部直接访问其他模块的内部数据,而是通过接口进行通信。
下面是一个示例代码,演示了如何实现迪米特法则:
```java
// 模块A
public class ModuleA {
public ModuleB moduleB;
public ModuleA(ModuleB moduleB) {
this.moduleB = moduleB;
}
public void doSomething() {
String data = moduleB.getData();
// 处理数据
}
}
// 模块B
public class ModuleB {
public String getData() {
// 获取数据
return "data";
}
}
// 主程序
public class Main {
public static void main(String[] args) {
ModuleB moduleB = new ModuleB();
ModuleA moduleA = new ModuleA(moduleB);
moduleA.doSomething();
}
}
```
在上面的代码中,模块A通过构造函数接收一个ModuleB的实例,并通过调用moduleB的方法来获取数据。模块A不直接访问moduleB的内部数据,而是通过接口和方法调用来实现间接访问。这样就符合了迪米特法则的要求。
通过遵循迪米特法则,我们可以提高模块之间的耦合度,使系统更加灵活和易于维护。
### 总结
迪米特法则是软件设计中一个重要的原则,它要求将对象之间的交互控制在最小范围内,以减少耦合度。通过应用迪米特法则,我们可以实现模块之间的解耦,提高系统的扩展性和可维护性。
在实际的软件架构中,我们应该遵循迪米特法则,并结合其他的模块化设计原则来构建可靠、灵活和可扩展的软件系统。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏以 "软件架构设计中的模块化设计原则" 为主题,展开讨论模块化设计在软件架构中的优势与挑战。通过深入探讨模块化设计的原则,读者将了解到模块化设计在软件开发中的重要性以及其带来的各种好处。专栏将探讨如何通过模块化设计来提高软件的可维护性、可复用性和可扩展性,从而使软件架构更加灵活、可靠和可持续。同时,专栏还将详细介绍面临的挑战,如模块间的接口设计、模块之间的依赖管理等,帮助读者克服在实践中遇到的困惑与问题。对软件开发人员、架构师和系统设计师而言,该专栏将提供宝贵的指导和经验,帮助他们设计出优秀的模块化软件架构。无论是初学者还是有一定经验的专业人士,都能从该专栏中获得有关模块化设计的有益知识和实用技巧。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python求和与信息安全:求和在信息安全中的应用与实践
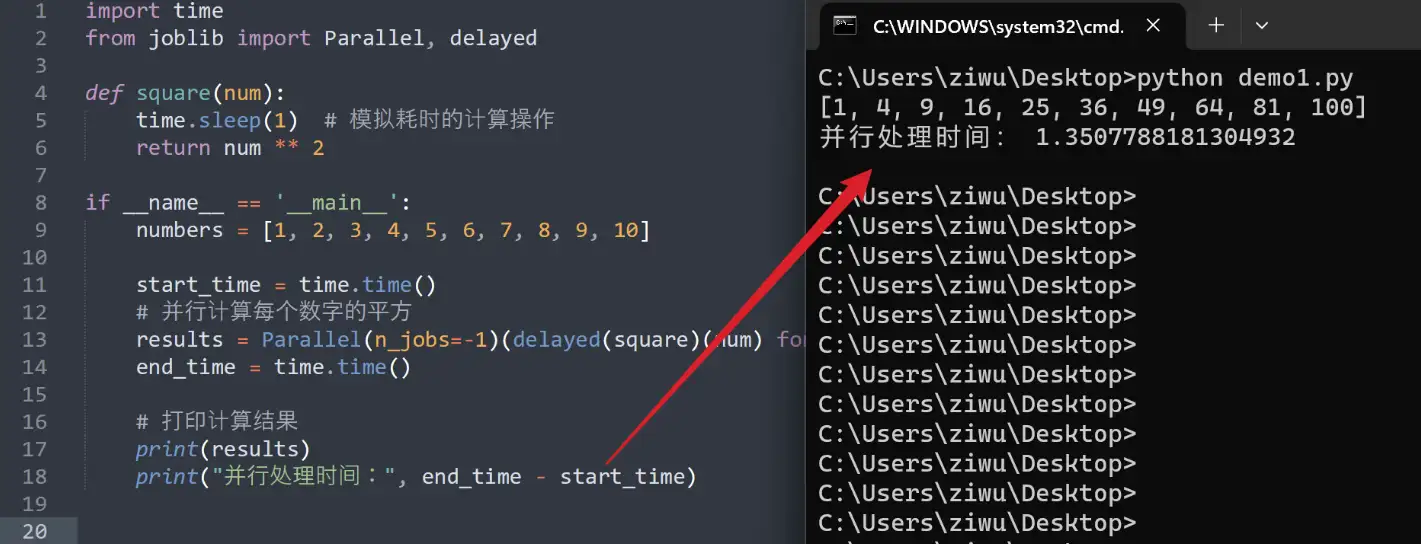
# 1. Python求和基础**
Python求和是一种强大的工具,用于将一系列数字相加。它可以通过使用内置的`sum()`函数或使用循环显式地求和来实现。
```python
# 使用 sum() 函数
numbers = [1, 2, 3, 4, 5]
total = sum(numbers) # total = 15
# 使用循环显式求和
total = 0
for n
【实战演练】使用PyQt开发一个简易的文件加密工具
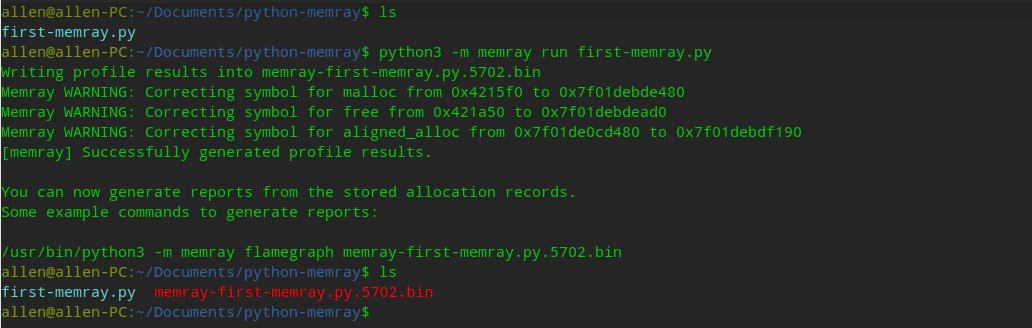
# 1. PyQt简介**
PyQt是一个跨平台的Python绑定库,用于开发图形用户界面(GUI)应用程序。它基于Qt框架,提供了一组丰富的控件和功能,使开发者能够轻松创建复杂的桌面应用程序。PyQt支持Windows、macOS、Linux和嵌入式系统等多种平台。
PyQt具有以下特点:
- 跨平台:可在多个平台上运行,包括Windows、macOS、Linux和嵌入式系统。
- 丰富的控件:提供
Python字符串字母个数统计与医疗保健:文本处理在医疗领域的价值

# 1. Python字符串处理基础**
Python字符串处理基础是医疗保健文本处理的基础。字符串是Python中表示文本数据的基本数据类型,了解如何有效地处理字符串对于从医疗保健文本中提取有意
Python break语句的开源项目:深入研究代码实现和最佳实践,解锁程序流程控制的奥秘

# 1. Python break 语句概述
break 语句是 Python 中一个强大的控制流语句,用于在循环或条件语句中提前终止执行。它允许程序员在特定条件满足时退出循环或条件块,从而实现更灵活的程序控制。break 语句的语法简单明了,仅需一个 break 关键字,即可在当前执行的循环或条件语句中终止执行,并继续执行后续代码。
# 2. br
Python index与sum:数据求和的便捷方式,快速计算数据总和
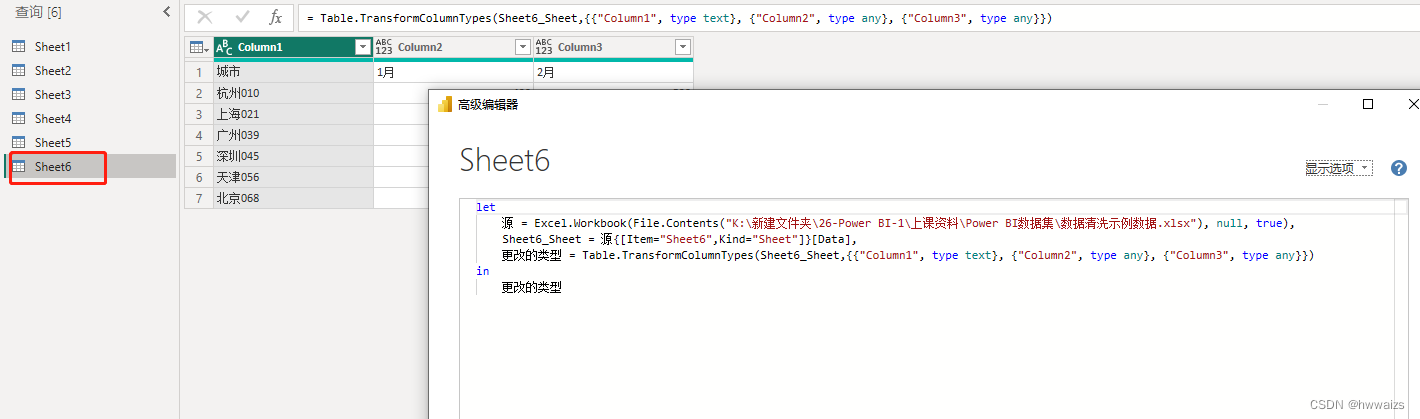
# 1. Python中的数据求和基础
在Python中,数据求和是一个常见且重要的操作。为了对数据进行求和,Python提供了多种方法,每种方法都有其独特的语法和应用场景。本章将介绍Python中数据求和的基础知识,为后续章节中更高级的求和技术奠定基础。
首先,Python中求和最简单的方法是使用内置的`+`运算符。该运算符可以对数字、字符串或列表等可迭代对象进行求和。例如:
`
Python开发Windows应用程序:云原生开发与容器化(拥抱云计算的未来)
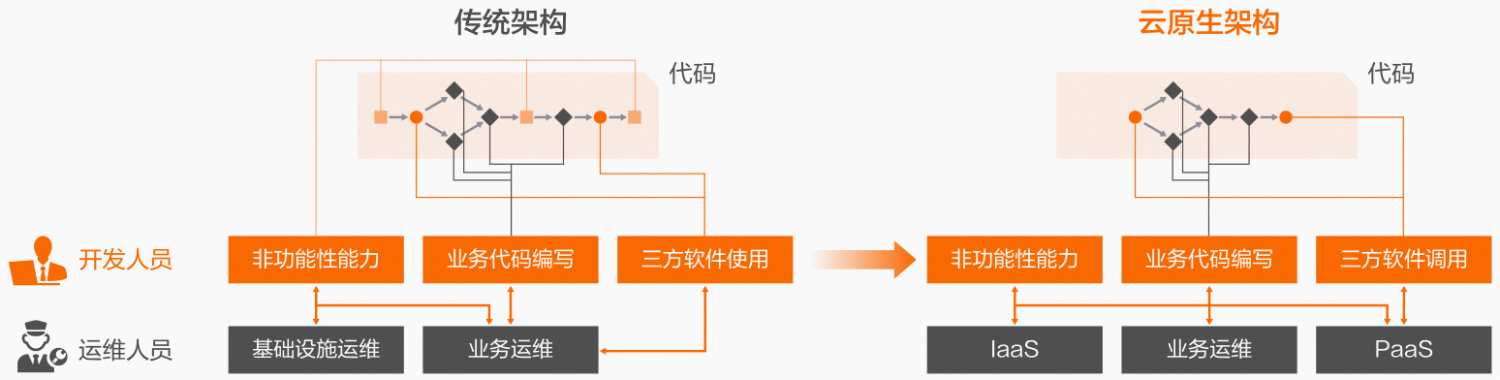
# 1. Python开发Windows应用程序概述
Python是一种流行的高级编程语言,其广泛用于各种应用程序开发,包括Windows应用程序。在本章中,我们将探讨使用Python开发Windows应用程序的概述,包括其优势、挑战和最佳实践。
### 优势
使用Python开发Windows应用程序具有以下优势:
- **跨平台兼
Python append函数在金融科技中的应用:高效处理金融数据
-Method.webp)
# 1. Python append 函数概述**
Python append 函数是一个内置函数,用于在列表末尾追加一个或多个元素。它接受一个列表和要追加的元素作为参数。append 函数返回 None,但会修改原始列表。
append 函数的语法如下:
```python
list.append(element)
```
其中,list 是要追加元
Python字符串与数据分析:利用字符串处理数据,提升数据分析效率,从海量数据中挖掘价值,辅助决策制定
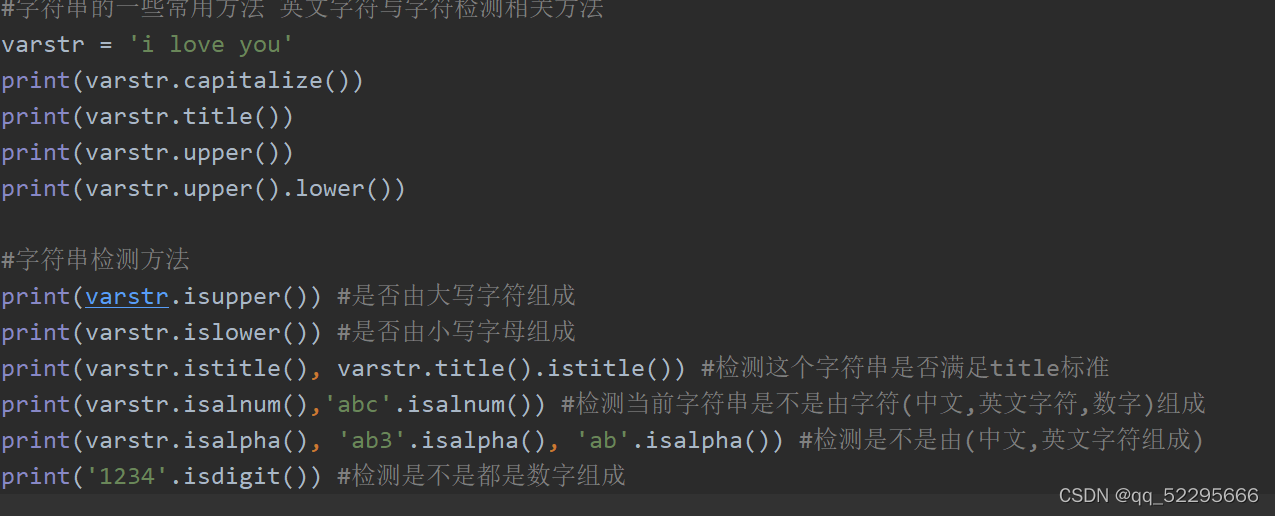
# 1. Python字符串基础
Python字符串是表示文本数据的不可变序列。它们提供了丰富的操作,使我们能够轻松处理和操作文本数据。本节将介绍Python字符串的基础知识,
numpy安装高级技巧:掌握pip高级用法,轻松安装

# 1. NumPy安装基础
NumPy是一个用于科学计算的Python库,提供了一个强大的N维数组对象和用于处理这些数组的高级数学函数。安装NumPy的过程很简单,可以通过以下步骤完成:
- 使用pip包管理器:`pip install numpy`
- 使用conda包管理器:`cond
KMeans聚类算法的并行化:利用多核计算加速数据聚类

# 1. KMeans聚类算法概述**
KMeans聚类算法是一种无监督机器学习算法,用于将数据点分组到称为簇的相似组中。它通过迭代地分配数据点到最近的簇中心并更新簇中心来工作。KMeans算法的目的是最小化簇内数据点的平方误差,从而形成紧凑且分离的簇。
KMeans算法的步骤如下:
1. **初始化:**选择K个数据点作为初始簇中心。
2. **分配:**将每个数据点分配到最近的簇中心。
3. **更新:**计算每个簇中数据点的平均值,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )