深度强化学习的核心概念及其在游戏中的应用
发布时间: 2024-01-06 20:42:18 阅读量: 35 订阅数: 23 
# 1. 深度学习和强化学习的概述
## 1.1 机器学习的发展历程
机器学习是人工智能(AI)的一个重要分支,通过利用数据和概率统计的方法,让计算机能够从经验中学习和改进。随着计算机技术的飞速发展,机器学习也逐渐成为一个热门领域。
机器学习的发展历程可以追溯到上世纪50年代,那时科学家们开始研究如何用机器来模拟人类的学习过程。随着计算机硬件技术的进步,机器学习的应用范围也越来越广泛。从最初的符号主义到后来的统计学习、神经网络,再到近年来的深度学习,机器学习的发展经历了多个重要阶段。
## 1.2 深度学习和强化学习的基本概念
深度学习是机器学习的一个分支,主要利用神经网络进行模型的训练和预测。深度学习通过多层神经网络来模拟人脑的神经元连接,并使用大量的数据来训练模型,从而实现对复杂问题的学习和推理。
强化学习是一种机器学习的方法,通过智能体与环境的交互来学习最优的行为策略。在强化学习中,智能体通过试错的方式不断尝试不同的行动,并通过环境反馈的奖励信号来评估行动的好坏,从而学习出最优的策略。
## 1.3 深度强化学习的优势和特点
深度强化学习结合了深度学习和强化学习的优势,具有以下特点:
- **自主学习能力**:深度强化学习的智能体能够自主进行学习,通过不断与环境的交互来改进自己的行为策略。
- **适应复杂环境**:深度强化学习可以应对复杂环境下的问题,通过对大量数据的学习和模型的优化,能够处理高维状态和动作空间的情况。
- **泛化能力强**:深度强化学习具有较强的泛化能力,可以将在一个环境中学到的策略应用到其他类似的环境中。
- **强大的决策能力**:深度强化学习的智能体可以根据当前环境的状态,选择最优的行动策略,并在不断的试错中不断改进。
深度强化学习在游戏领域的应用有着巨大潜力,可以实现游戏智能体的自主学习和适应能力,提升游戏的趣味性和挑战性。
# 2. 深度强化学习的核心概念
深度强化学习是机器学习领域中的重要分支,它结合了深度学习和强化学习的优势,能够在复杂的环境中实现智能决策和行动。本章将介绍深度强化学习的核心概念,包括神经网络和深度学习模型、强化学习中的价值函数和策略,以及深度Q网络(DQN)的原理和应用。
### 2.1 神经网络和深度学习模型
神经网络是深度学习的基础,它模拟了人脑中神经元之间的连接和信息传递。神经网络由多个层次组成,每一层都包含多个神经元,神经元通过学习调整连接权重来实现对输入数据的特征提取和分类。深度学习模型是由多个层次的神经网络组成的复杂网络结构,可以用来解决更加复杂和抽象的问题。
### 2.2 强化学习中的价值函数和策略
在强化学习中,智能体通过与环境的交互来学习最优的决策策略。价值函数是衡量智能体在特定状态下行动的好坏的指标,它可以表示为对未来奖励的预测。策略则是智能体根据当前状态选择行动的规则。通过优化价值函数和策略,智能体可以逐步提升在环境中的表现。
### 2.3 深度Q网络(DQN)及其应用
深度Q网络(DQN)是深度强化学习中的重要算法,它能够将神经网络与Q-learning算法相结合,实现对离散动作空间的优化。DQN通过将当前状态作为输入,输出每个动作的对应Q值,通过选择具有最高Q值的动作来进行决策。DQN还利用经验回放和固定目标网络等技术来稳定训练过程。
深度Q网络在许多游戏中都有广泛的应用,比如在Atari游戏中,DQN可以通过观察屏幕像素来学习玩游戏的策略。DQN在某些游戏中已经超过了人类玩家的水平,并取得了显著的成果。除了游戏,DQN还可以在机器人控制、自动驾驶等领域发挥重要作用。
```python
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 创建DQN模型
model = DQN(state_dim, action_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练过程
for epoch in range(1000):
state = env.reset()
done = False
while not done:
# 选择动作
action = model(torch.tensor(state).float().unsqueeze(0))
action = torch.argmax(action, dim=1).item()
# 执行动作
next_state, reward, done, _ = env.step(action)
# 计算误差
Q_target = reward + 0.99 * torch.max(model(torch.tensor(next_state).float().unsqueeze(0)))
Q_pred = model(torch.tensor(state).float().unsqueeze(0)).gather(dim=1, index=torch.tensor([[action]]))
loss = F.mse_loss(Q_pred, Q_target.unsqueeze(1))
# 更新模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
# 每轮训练输出训练结果
if epoch % 10 == 0:
total_reward = 0
for _ in range(10):
state = env.reset()
done = False
while not done:
action = model(torch.tensor(state).float().unsqueeze(0))
action = torch.argmax(action, dim=1).item()
state, reward,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏以"深度学习原理详解及python代码实现"为主题,通过多篇文章深入阐述了深度学习的基础概念和基本原理,进一步介绍了Python在深度学习中的基本应用。其中,神经网络结构及其原理解析、前向传播算法、反向传播算法等章节详细介绍了深度学习中重要的算法和原理。此外,还深入讨论了常用的激活函数、优化算法、损失函数以及批量归一化技术等对模型训练的影响。卷积神经网络、循环神经网络、自编码器、序列到序列模型等各种深度学习结构的原理和应用也得到全面解析。此外还介绍了深度强化学习的核心概念和在游戏中的应用,最后,讨论了迁移学习在深度学习中的意义和实践。该专栏内容丰富、结构完整,旨在为读者提供深入理解深度学习原理以及实际应用的知识,同时通过Python代码实现的示例,帮助读者更好地掌握深度学习的技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘PUBG:罗技鼠标宏的性能与稳定性优化术

# 摘要
罗技鼠标宏作为提升游戏操作效率的工具,在《绝地求生》(PUBG)等游戏中广泛应用。本文首先介绍了罗技鼠标宏的基本概念及在PUBG中的应用和优势。随后探讨了宏与Pergamon软件交互机制及其潜在对游戏性能的影响。第三部分聚焦于宏性能优化实践,包括编写、调试、代码优化及环境影响分析。第四章提出了提升宏稳定性的策略,如异常处理机制和兼容性测试。第五章讨论了
【LS-DYNA高级用户手册】:材料模型调试与优化的终极指南
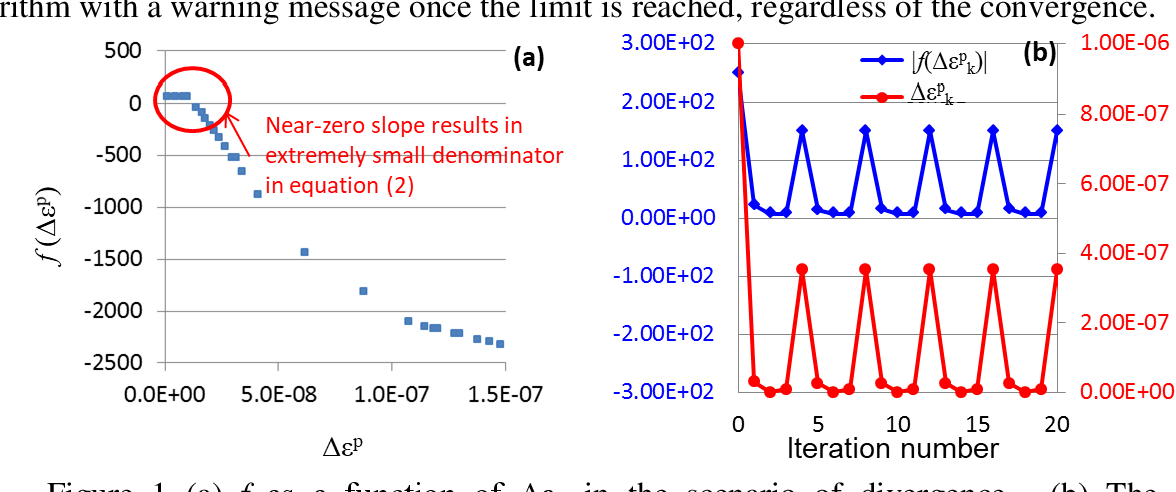
# 摘要
LS-DYNA作为一种先进的非线性动力分析软件,广泛应用于工程模拟。本文首先介绍了LS-DYNA中的材料模型及其重要性,随后深入探讨了材料模型的基础理论、关键参数以及调试和优化方法。通过对不同材料模型的种类和选择、参数的敏感性分析、实验数据对比验证等环节的详细解读,文章旨在提供一套系统的
【FPGA时序分析】:深入掌握Spartan-6的时间约束和优化技巧

# 摘要
本文深入探讨了Spartan-6 FPGA的时序分析和优化策略。首先,介绍了FPGA时序分析的基础知识,随后详细阐述了Spar
【节能关键】AG3335A芯片电源管理与高效率的秘密
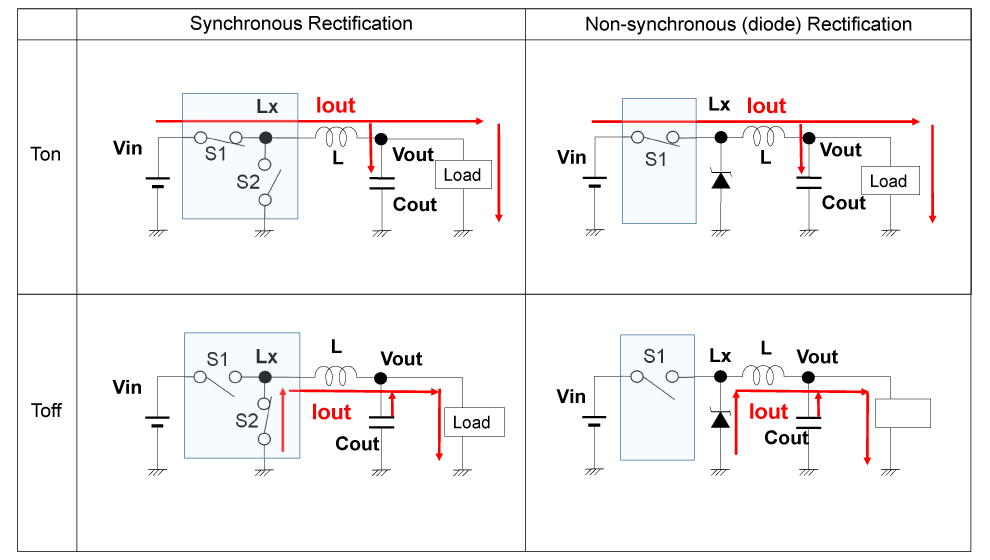
# 摘要
AG3335A芯片作为一款集成先进电源管理功能的微处理器,对电源管理的优化显得尤为重要。本文旨在概述AG3335A芯片,强调其电源管理的重要性,并深入探讨其电源管理原理、高效率实现以及节能技术的实践。通过对AG3335A芯片电源架构的分析,以及动态电压频率调整(DVFS)技术和电源门控技术等电源管理机制的探讨,本文揭示了降低静态和动态功耗的有效策略。同时,本文还介绍了高效率电源设计方案和电源管理
编译原理实战指南:陈意云教授的作业解答秘籍(掌握课后习题的10种方法)

# 摘要
本文回顾了编译原理的基础知识,通过详细的课后习题解读技巧、多种学习方法的分享以及实战案例的解析,旨在提高读者对编译过程各阶段的理解和应用能力。文章
Swatcup性能提升秘籍:专家级别的优化技巧
# 摘要
本文深入探讨了Swatcup这一性能优化工具,全面介绍了其系统架构、性能监控、配置管理、性能调优策略、扩展与定制以及安全加固等方面。文章首先概述了Swatcup的简要介绍和性能优化的重要性,随后详细分析了其系统架构及其组件功能和协同作用,性能监控工具及其关键性能指标的测量方法。接着,本文重点讲解了Swatcup在缓存机制、并发处理以及资源
PDM到PCM转换揭秘:提升音频处理效率的关键步骤

# 摘要
本文对PDM(脉冲密度调制)和PCM(脉冲编码调制)这两种音频格式进行了全面介绍和转换理论的深入分析。通过探讨音频信号的采样与量化,理解PCM的基础概念,并分析PDM
【大规模线性规划解决方案】:Lingo案例研究与处理策略
:quality(75)/arc-anglerfish-arc2-prod-elcomercio.s3.amazonaws.com/public/6JGOGXHVARACBOZCCYVIDUO5PE.jpg)
# 摘要
线性规划是运筹学中的一种核心方法,广泛应用于资源分配、生产调度等领域。本文首先介绍了线性规划的基础知识和实际应用场景,然后详细讨
【散热优化】:热管理策略提升双Boost型DC_DC变换器性能

# 摘要
本文详细阐述了散热优化的基础知识与热管理策略,探讨了双Boost型DC_DC变换器的工作原理及其散热需求,并分析了热失效机制和热损耗来源。基于散热理论和设计原则,文中还提供了散热优化的实践案例分析,其中包括热模拟、实验数据对比以及散热措施的实施和优化。最后,本文展望了散热优化技术的未来趋势,探讨了新兴散热技术的应用前景及散热优化面临的挑战与未来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )