基于爬虫的数据挖掘与应用
发布时间: 2024-01-14 08:40:15 阅读量: 32 订阅数: 42 

基于python的Web数据挖掘技术研究与实现
# 1. 理解爬虫技术
## 1.1 什么是爬虫技术
爬虫技术是一种通过模拟浏览器的行为,自动请求网页并提取网页中的数据的技术。通过编写程序,爬虫可以自动遍历互联网上的各个网页,并将所需的数据抓取下来进行提取和分析。
爬虫技术是大数据时代的重要工具之一,在实际应用中广泛用于数据挖掘、信息抓取、搜索引擎等领域。通过爬取海量数据,可以帮助企业和研究机构进行市场调研、舆情分析、商业决策等。
## 1.2 爬虫技术的工作原理
爬虫技术的工作原理可以简单概括为以下几个步骤:
1. 发送HTTP请求:爬虫通过发送HTTP请求来抓取网页。可以使用Python的Requests库、Java的HttpURLConnection等工具包来实现。
2. 获取网页内容:一旦发送了HTTP请求,就会收到网页服务器返回的响应。通过解析响应,可以获取网页的内容。
3. 解析网页内容:爬虫需要从网页中提取有用的信息,例如标题、正文、链接等。可以使用正则表达式、XPath、BeautifulSoup、PyQuery等库来解析网页。
4. 数据处理与存储:爬虫获取到的数据需要进行处理和存储。可以将数据保存到文本文件、数据库或者内存中,以便后续的分析和应用。
## 1.3 爬虫技术在数据挖掘中的作用
爬虫技术在数据挖掘中起着重要的作用。通过爬取大量的数据,可以获取到真实、全面的数据样本,为后续的数据挖掘和分析提供基础。
在数据挖掘中,爬虫技术可以用来:
- 收集数据:爬虫可以从各种网站上抓取数据,包括社交媒体、电商平台、新闻网站等。通过收集大量的数据,可以建立庞大的数据集,为数据挖掘算法的训练和验证提供支持。
- 数据预处理:爬虫获取的数据往往需要进行清洗和预处理。例如,去除重复数据、处理缺失值、进行文本分词等。这些预处理工作可以帮助提高后续的数据挖掘效果。
- 特征提取:爬虫获取的数据可以提取出特征用于后续的建模和分析。例如,从商品信息中提取出价格、销量等特征,并用于商品推荐和价格分析。
- 数据可视化:爬虫获取的数据可以通过数据可视化技术展示出来,便于用户对数据进行直观的理解和分析。例如,使用图表、地图等形式展示数据分布和趋势。
总结起来,爬虫技术在数据挖掘中扮演着数据收集、数据预处理和特征提取的重要角色,为后续的建模和分析提供数据基础。同时,数据挖掘也可以通过对爬取的数据进行分析,帮助优化爬虫的抓取策略和结果。爬虫技术与数据挖掘的结合,可以实现更精准、高效的数据挖掘和决策支持。
# 2. 爬虫数据抓取与处理
在本章中,我们将深入探讨爬虫数据抓取与处理的相关内容。我们将首先介绍数据抓取的流程,接着讨论数据清洗与预处理的重要性,最后探讨数据存储与管理的方法。
#### 2.1 数据抓取流程
数据抓取是爬虫技术的核心部分,其流程包括发送HTTP请求、解析HTML页面、提取数据等步骤。在实际操作中,我们可利用Python中的requests库发送HTTP请求,利用BeautifulSoup库解析HTML页面,从而实现数据的抓取。以下是一个简单的示例代码:
```python
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取页面标题
title = soup.title.string
print(title)
# 提取页面所有链接
for link in soup.find_all('a'):
print(link.get('href'))
```
以上代码中,我们通过发送HTTP请求获取了指定页面的HTML内容,并利用BeautifulSoup实现了对页面标题和链接的提取。
#### 2.2 数据清洗与预处理
爬虫抓取的数据往往包含大量的噪音和无效信息,因此在进行进一步分析前,需要对数据进行清洗和预处理。清洗步骤可能包括去除重复项、处理缺失值、纠正数据类型等操作。在Python中,pandas库提供了丰富的数据清洗工具,以下是一个简单的数据清洗示例:
```python
import pandas as pd
# 创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice'],
'Age': [25, 30, 35, None],
'Salary': [5000, 6000, None, 7000]}
df = pd.DataFrame(data)
# 去除重复行
df = df.drop_duplicates()
# 填充缺失值
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Salary'].fillna(df['Salary'].median(), inplac
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为Python网络爬虫带来一系列入门指南和技巧,旨在让读者全面掌握网络爬虫的基本原理和实践技巧。首先,我们将介绍Python网络爬虫的基础知识,包括HTML解析和使用Requests库发送HTTP请求。然后,我们将深入讲解URL的解析与构建,以及BeautifulSoup库的使用和网页解析的技巧。紧接着,我们将探讨正则表达式在Python网络爬虫中的应用,以及数据存储和处理的技巧。此外,我们还将介绍使用Selenium进行动态网页爬取,并学习Scrapy框架的入门和基本使用。我们还将讨论代理IP的使用和应对反爬虫技术的策略。最后,我们将介绍爬虫数据处理的重要技巧、爬虫与API的结合和应用、爬虫遵守Robots协议的规范以及如何实现爬虫自动化和定时执行。最后,我们将讨论分布式爬虫架构和设计、爬虫性能优化和提高爬取效率,以及基于爬虫的数据挖掘和应用。通过本专栏的学习,读者将能够全面了解Python网络爬虫的知识,并掌握相关的实践技巧和应用。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【JSON书源优化秘籍】:20年专家揭秘提升阅读体验的关键技术

参考资源链接:[1629个精品阅读书源,提升你的阅读体验](https://wenku.csdn.net/doc/6z9pjm3s9m?spm=1055.2635.3001.10343)
# 1. JSON书源技术概览
## 1.1 JSON书源的定义与重要性
JSON(JavaScript Object Notation)书源是一种轻量级的数据交换格式,广泛应用于网络数据交换
【Verdi系统新手必读】:5个步骤快速入门与精通
参考资源链接:[Verdi教程](https://wenku.csdn.net/doc/3rbt4txqyt?spm=1055.2635.3001.10343)
# 1. Verdi系统概览与安装
## Verdi系统简介
Verdi 是一款先进的信息管理系统,旨在为IT专业人员提供全面的数据分析和处理能力。它采用了最新的技术来增强用户的数据操作体验,使复杂的数据任务变得简单高效。系统支持多种
【MSP430遗留代码迁移至MSPM0】:代码适配与优化秘籍
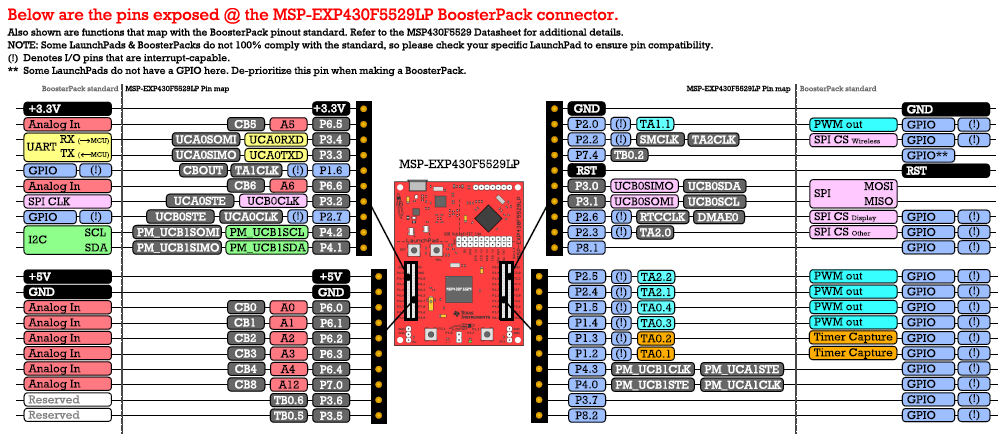
参考资源链接:[MSP430到MSPM0迁移指南:软件移植与硬件适应](https://wenku.csdn.net/doc/7zqx1hn3m8?spm=1055.2635.3001.10343)
# 1. MSP430与MSPM0概述
## MSP430与MSPM0的区别
MSP430与MSPM0都隶属于德州仪器(TI)的MSP微控制器
NC65开发新手必读:构建您的第一个API的5个秘密
参考资源链接:[NC65开发教程:新手API指南](https://wenku.csdn.net/doc/7y1y00utfs?spm=1055.2635.3001.10343)
# 1. NC65开发平台简介与API基础
在当今数字化转型的浪潮中,企业对于开发平台的依赖越来越深,而NC65开发平台作为一款综合性的企业管理软件,为企业提供了一个强大的应用开发环境。本章节将对NC65开发平台进行基础介绍,并深入探讨AP
【Fluent透明后处理问题快速诊断】:专家教你如何快速定位与解决渲染难题

参考资源链接:[fluent透明后处理](https://wenku.csdn.net/doc/6412b79cbe7fbd1778d4ae8f?spm=1055.2635.3001.10343)
# 1. Fluent透明后处理的基础知识
## 1.1 透明度与后处理的关系
在图形学和视觉艺术中,透明
版图验证时序问题:Cadence后端实验的中级解析与应对

参考资源链接:[Cadence Assura版图验证全面教程:DRC、LVS与RCX详解](https://wenku.csdn.net/doc/zjj4jvqsmz?spm=1055.2635.3001.10343)
# 1. 版图验证的时序问题概述
在当今电子工程设计领域,时序问题的识别与优化对于确保芯片设计的正确性和性能至关重要。本章将概述版图验证中所面临的时序挑战,并
从零开始搭建高效Activiti环境:达梦数据库版

参考资源链接:[Activiti二次开发:适配达梦数据库的详细教程](https://wenku.csdn.net/doc/6412b53fbe7fbd1778d42781?spm=1055.2635.3001.10343)
# 1. Activiti工作流引擎概述
工作流引擎是企业信息化建设中的核心组件之一,而Activiti作为一款轻量级的工作流引擎,以其灵活、高效和易于集成
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )