Java字符集转换全面教程:掌握Charset类的5大核心用法
发布时间: 2024-10-21 16:22:52 阅读量: 53 订阅数: 27 

id3-charset-converter:Java命令行应用程序,用于将id3标签的字符集隐式转换为UTF-8
# 1. Java字符集转换基础概念
## 1.1 字符集转换的概念
字符集转换是信息处理中的重要环节,它确保了不同系统、应用程序之间能够正确交换和显示文本信息。无论是在网络传输、文件处理还是数据库交互中,字符集转换都扮演着关键角色。
## 1.2 Java中的字符集转换需求
Java作为一种跨平台的编程语言,经常需要处理不同环境下的文本数据。因此,理解如何在Java中实现字符集转换,是开发中不可或缺的技能。Java通过`java.nio.charset.Charset`类支持字符集转换,提供了强大的API来简化这一过程。
## 1.3 基础知识准备
在深入探讨Java字符集转换之前,需要先对字符集和字符编码有一个基本的理解。字符集是字符的集合,字符编码则是字符集到字节序列的映射。通过了解这些基础知识,将有助于我们更好地掌握Java中的字符集转换机制。
# 2. 深入理解Charset类的原理与结构
## 2.1 字符集与字符编码的概念
### 2.1.1 字符集的定义和重要性
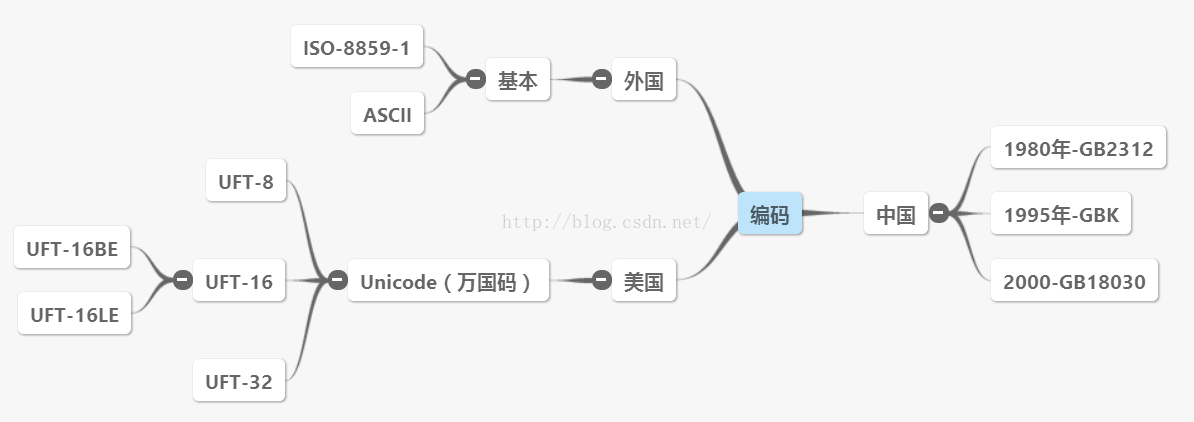
字符集(Character set)是用于字符编码的一组符号和数字的集合。每个符号或数字都与特定的字符对应,例如,ASCII字符集包含128个符号和数字,可以表示英文字母、数字、标点符号以及控制字符。字符集的重要性在于它提供了一个通用框架,让计算机能够存储、传输和处理文本信息。没有统一的字符集,不同系统间的数据交流会变得异常困难。
字符集的历史可以追溯到早期计算机系统,当时由于技术限制和对字符需求的不同,出现了多种字符集标准,比如ISO 8859系列、GB2312等,这些标准往往只能覆盖部分语言或特定字符集。随着全球信息化的发展,统一的国际标准字符集Unicode应运而生,为多语言文本处理提供了便捷。
### 2.1.2 字符编码方式概述
字符编码(Character encoding)是将字符集中的字符映射为计算机系统中使用的二进制代码的过程。最常用的编码方式有ASCII、UTF-8和UTF-16等。ASCII编码使用7位二进制数表示字符,支持128个字符。而UTF-8、UTF-16和UTF-32是Unicode的编码方式,它们支持表示几乎所有的语言的字符。例如,UTF-8编码是可变长度的,它可以根据字符所需的字节数来编码,这对于网络传输来说非常高效。
在实际应用中,字符集与字符编码紧密相关,但不完全相同。字符集定义了字符的集合,而字符编码是这个集合到二进制编码的映射方式。理解这一点对于掌握字符集转换非常重要,因为它能帮助我们正确处理不同环境下字符数据的正确显示。
## 2.2 Java中的Charset类入门
### 2.2.1 Charset类的作用和重要性
Java中的`Charset`类是处理字符集和字符编码的中心类,它提供了字符集相关的操作,包括字符集的注册、检索、编码和解码等。通过`Charset`类,Java程序能够处理各种字符编码的转换,这对于开发全球化的应用程序来说是不可或缺的。在进行国际化开发时,经常需要处理来自不同编码格式的文本数据,`Charset`类能够确保这些数据在Java平台上被正确地编码和解码,避免了乱码的问题。
### 2.2.2 创建Charset实例的方法
在Java中创建`Charset`实例有多种方法,最直接的是通过`Charset.forName(String charsetName)`方法。例如,如果要获取UTF-8字符集的`Charset`实例,可以使用以下代码:
```java
Charset utf8Charset = Charset.forName("UTF-8");
```
`forName`方法会根据提供的字符集名称,返回对应的`Charset`实例。如果提供的名称不支持,这个方法会抛出`IllegalCharsetNameException`异常。
除了通过字符集名称,Java还提供了`Charset.availableProviders()`方法来获取系统中可用的字符集提供者。这允许程序在运行时选择最适合的字符集实现,提高了程序的灵活性和适用性。
## 2.3 Java字符集转换的基本步骤
### 2.3.1 步骤一:获取Charset实例
进行字符集转换的第一步是获取两个`Charset`实例,分别对应源数据和目标数据的字符集。比如,源数据使用GB2312编码,而目标数据使用UTF-8编码,那么需要分别获取GB2312和UTF-8的`Charset`实例:
```java
Charset sourceCharset = Charset.forName("GB2312");
Charset targetCharset = Charset.forName("UTF-8");
```
### 2.3.2 步骤二:编码与解码操作
一旦有了两个`Charset`实例,就可以使用它们进行编码和解码操作。编码操作是从字符序列转换到字节序列,解码则是反向操作。Java中的`Charset`类提供了`encode`和`decode`方法,可以完成这两种操作。
例如,如果我们有一个字符串需要转换编码:
```java
String input = "中文字符";
Charset sourceCharset = Charset.forName("GB2312");
Charset targetCharset = Charset.forName("UTF-8");
ByteBuffer encoded = sourceCharset.encode(input);
CharBuffer decoded = targetCharset.decode(encoded);
```
在这个例子中,首先将字符串`"中文字符"`按照GB2312编码转换为字节序列,然后使用UTF-8解码回字符序列。注意在实际应用中,处理字符集转换可能需要考虑编码和解码时的错误处理策略,以及内存占用问题。这可以通过对`CharsetEncoder`和`CharsetDecoder`类的深入使用来进一步优化。
# 3. Charset类的五大核心用法
## 3.1 第一大用法:标准字符集的使用
### 3.1.1 如何选择标准字符集
在处理文本数据时,选择正确的字符集至关重要。标准字符集确保了跨平台和跨程序的一致性。Java语言提供了多种标准字符集,其中最常用的是UTF-8、UTF-16和US-ASCII。UTF-8因其支持所有字符并且编码效率高成为了互联网上的主导字符集。UTF-16则用于那些需要更高效处理Unicode代码点的操作中,而US-ASCII只支持基本的英文字符,适合纯英文环境。
要选择合适的字符集,开发者需要考虑数据的来源和目的地,以及可能使用的第三方库的字符集兼容性。一个实践中的建议是尽可能使用UTF-8,因为它几乎能兼容所有系统。
### 3.1.2 实践案例:UTF-8字符集的应用
在Java程序中使用UTF-8字符集是一个普遍的需求。以下是一个简单的示例代码,展示了如何读取一个使用UTF-8编码的文本文件,并将其内容转换为字符串。
```java
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.io.IOException;
public class ReadUTF8File {
public static void main(String[] args) {
try {
byte[] encoded = Files.readAllBytes(Paths.get("example.txt"));
String text = new String(encoded, StandardCharsets.UTF_8);
System.out.println(text);
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
这段代码首先指定了使用`StandardCharsets.UTF_8`作为字符集。如果文件是用UTF-8编码的,这个方法能正确地将文件内容转换为Java的`String`对象。如果有任何文件读取或编码转换错误,异常处理机制会捕获`IOException`并打印异常堆栈跟踪。
## 3.2 第二大用法:自定义字符集支持
### 3.2.1 自定义字符集的创建与注册
尽管Java支持广泛的字符集,但某些特殊应用可能需要使用非标准字符集。在这些情况下,Java允许开发者创建和注册自定义字符集。通过实现`CharsetProvider`接口,开发者可以提供自己的字符集实现。
创建自定义字符集的步骤如下:
1. 创建一个类实现`CharsetProvider`接口。
2. 提供`getCharsetByName`、`getCharsetForName`和`charsets`等方法的实现。
3. 编译这个类并将其打包为JAR文件。
4. 将JAR文件放置到Java的扩展目录下或通过`-Djava.ext.dirs`指定目录。
一旦自定义字符集注册成功,Java的`Charset`类将能识别并使用这个新字符集。
### 3.2.2 实践案例:支持老旧字符集的编码转换
假定我们需要处理一些老旧的系统数据,这些数据使用了ISO-2022-CN字符集。首先,我们需要创建一个自定义的字符集提供者来支持这个编码,然后使用它来解码数据。
```java
public class CustomCharsetProvider extends CharsetProvider {
@Override
public Charset getCharset(String charsetName) {
if (charsetName.equalsIgnoreCase("ISO-2022-CN")) {
return new ISO2022CNCharset();
}
return null;
}
// 其他必要的方法实现...
}
class ISO2022CNCharset extends Charset {
// ISO-2022-CN字符集的具体实现细节
// ...
}
// 注册自定义字符集
public class CharsetRegistration {
public static void main(String[] args) {
Charset.registerProvider(new CustomCharsetProvider());
}
}
```
上述代码展示了自定义字符集创建和注册的基本结构。在实际的应用中,开发者需要完成`ISO2022CNCharset`类中所有必要的实现,以确保字符集能正确工作。
## 3.3 第三大用法:字符集转换的异常处理
### 3.3.1 常见异常类型及原因
在进行字符集转换时,可能会遇到各种异常。了解常见的异常类型及其产生的原因是非常重要的。
常见的异常类型包括:
- `UnsupportedCharsetException`:请求的字符集不受支持。
- `MalformedURLException`:不正确的URL格式。
- `IOException`:包括读取文件或网络资源失败时的异常。
- `CharacterCodingException`:字符编码错误或不兼容。
了解这些异常的原因可以帮助我们编写健壮的代码来预防和处理这些情况。
### 3.3.2 异常处理策略和实践
异常处理策略对于保证程序的稳定性和用户体验至关重要。以下是一些处理异常的实践建议:
- 在读取或写入文件时,确保使用`try-catch`语句块来处理`IOException`。
- 当使用特定的字符集进行编码或解码时,捕捉`CharacterCodingException`。
- 通常,`UnsupportedCharsetException`和`MalformedURLException`可以预先检查避免,例如在文件或URL存在时再尝试读取或访问。
在Java中,异常处理通常使用`try`、`catch`、`finally`和`throws`关键字。例如,如果在解析来自网络的文本数据时使用了不支持的字符集,可以采用以下代码进行异常处理:
```java
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
import java.nio.charset.UnsupportedCharsetException;
import java.io.IOException;
public class EncodingExceptionHandling {
public static String decodeText(byte[] encodedText, String charsetName) {
Charset charset = Charset.forName(charsetName);
CharsetDecoder decoder = charset.newDecoder();
try {
return decoder.decode(ByteBuffer.wrap(encodedText)).toString();
} catch (CharacterCodingException e) {
System.err.println("CharacterCodingException occurred");
e.printStackTrace();
} catch (UnsupportedCharsetException e) {
System.err.println("UnsupportedCharsetException occurred");
e.printStackTrace();
}
return null;
}
}
```
在这个例子中,我们使用了`Charset`和`CharsetDecoder`来解码字节序列。如果在解码过程中遇到不支持的字符集或编码问题,异常会被捕获并打印错误信息。
## 3.4 第四大用法:转换流的高级应用
### 3.4.1 创建转换流的方式
转换流是Java I/O中非常强大的一个特性,它们将字节流转换为字符流,反之亦然。这对于字符集转换来说非常有用。`InputStreamReader`和`OutputStreamWriter`是Java中常用的转换流。
以下是创建转换流的几种方法:
- 使用`InputStreamReader`从字节流中读取字符,需要提供`Charset`参数。
- 使用`OutputStreamWriter`将字符写入到字节流,同样需要`Charset`参数。
### 3.4.2 输入输出流与Charset的结合使用
结合`InputStreamReader`和`OutputStreamWriter`,我们可以实现复杂的字符集转换逻辑。下面是一个示例,展示了如何将输入流中的数据从一种字符集转换为另一种字符集:
```java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
public class CharsetTransformationExample {
public static void main(String[] args) throws IOException {
String inputFilePath = "input.txt";
String outputFilePath = "output.txt";
String inputCharset = "ISO-8859-1";
String outputCharset = "UTF-8";
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(inputFilePath),
Charset.forName(inputCharset)));
PrintWriter writer = new PrintWriter(
new OutputStreamWriter(new FileOutputStream(outputFilePath),
Charset.forName(outputCharset)))) {
String line;
while ((line = reader.readLine()) != null) {
writer.println(line);
}
}
}
}
```
上述代码中,我们首先创建了一个`InputStreamReader`实例,用于读取ISO-8859-1编码的文件。然后,我们创建了一个`OutputStreamWriter`实例,将读取到的数据转换为UTF-8编码并写入到另一个文件。通过这种方式,我们能够在两个不同的字符集之间转换文本数据。
## 3.5 第五大用法:性能优化技巧
### 3.5.1 影响性能的因素分析
字符集转换性能可能受到多种因素的影响,包括:
- 字符集的选择:某些字符集的编码和解码过程比其他字符集更为复杂。
- 数据量大小:转换大量数据比小量数据需要更多时间和资源。
- 硬件和系统配置:硬件性能和配置(如CPU速度、内存大小)直接影响转换速度。
- 转换方法:手动优化的循环和算法可能比直接使用标准库更快。
了解这些因素有助于我们找到性能瓶颈并加以优化。
### 3.5.2 性能优化方法和最佳实践
性能优化是软件开发中的关键部分,特别是在字符集转换中。以下是一些提升性能的最佳实践:
- 使用最合适的字符集:避免使用过时或不必要的复杂字符集,这可以减少转换时的计算量。
- 减少转换次数:尽可能在数据处理链的最早阶段进行字符集转换,避免在处理过程中多次转换。
- 批量处理:当转换大量数据时,使用批处理方式可以减少I/O操作和循环开销。
- 使用缓冲:无论是读取还是写入,使用缓冲可以减少I/O操作次数,从而提高性能。
一个实际的性能优化示例是使用`StringBuffer`或`StringBuilder`来构建字符串,避免在每次循环中创建新的字符串实例:
```java
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.io.IOException;
public class PerformanceOptimization {
public static void main(String[] args) {
byte[] encodedData = null;
try {
encodedData = Files.readAllBytes(Paths.get("example.txt"));
} catch (IOException e) {
e.printStackTrace();
}
String decodedText = new String(encodedData, StandardCharsets.UTF_8);
StringBuffer buffer = new StringBuffer();
for (char c : decodedText.toCharArray()) {
buffer.append(c);
}
String finalString = buffer.toString();
}
}
```
在这个例子中,我们首先读取文件到一个字节数组,然后使用`String`构造函数将其解码为字符串。接着,我们使用`StringBuffer`来累积字符,避免了在循环中不断地创建新的`String`对象。这是一个简单的优化技巧,但可以显著提升处理大数据量时的性能。
# 4. Java字符集转换实战演练
## 4.1 文件编码转换实战
### 4.1.1 简单文件编码转换程序
文件编码转换是将一个文件从一种字符编码转换为另一种字符编码的过程,这在处理文本文件时尤为常见。在Java中,通过Charset类以及相关的转换流,我们可以方便地实现文件的编码转换。以下是一个简单的文件编码转换程序的示例代码,用于将文件从一个编码转换为UTF-8编码。
```java
import java.io.*;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
public class FileEncodingConverter {
public static void main(String[] args) {
String sourceFile = "example.txt"; // 原始文件路径
String targetFile = "converted.txt"; // 转换后的文件路径
Charset sourceCharset = StandardCharsets.ISO_8859_1; // 源文件的字符集
Charset targetCharset = StandardCharsets.UTF_8; // 目标字符集
try {
// 使用Files.readAllBytes读取文件内容
byte[] bytes = Files.readAllBytes(Paths.get(sourceFile));
// 将字节数据按照源字符集解码为字符串
String content = new String(bytes, sourceCharset);
// 将字符串按照目标字符集重新编码为字节数据
byte[] newBytes = content.getBytes(targetCharset);
// 使用Files.write将新的字节数据写入目标文件
Files.write(Paths.get(targetFile), newBytes);
System.out.println("文件编码转换成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
在上述代码中,我们首先定义了源文件和目标文件的路径,然后指定了源文件和目标文件的字符集。通过`Files.readAllBytes`方法读取源文件的所有字节,然后使用指定的源字符集对这些字节进行解码。解码后我们得到一个字符串,该字符串随后使用目标字符集进行编码,得到新的字节数组。最后,我们使用`Files.write`方法将新的字节数组写入目标文件。整个过程中,我们严格控制字符集的使用,确保编码和解码过程准确无误。
### 4.1.2 复杂文件编码转换程序
在处理复杂文件编码转换程序时,可能会遇到文件内容不是简单的文本信息,而是包含了多种编码混合或者需要考虑特定格式转换的情况。这种情况下,文件编码转换的策略和步骤需要更加细致和灵活。
一个复杂的文件编码转换程序通常涉及以下步骤:
1. 分析文件内容,识别不同的编码部分。
2. 根据内容的不同编码部分,逐块进行编码转换。
3. 处理文件中的特定格式(如HTML, XML等),需要定制转换逻辑以保持格式的正确性。
4. 使用转换流进行高效的编码转换。
5. 考虑内存和性能优化,可能需要使用缓冲区来分块处理大文件。
```java
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
public class AdvancedFileEncodingConverter {
public static void main(String[] args) {
String sourceFile = "complex_example.txt";
String targetFile = "advanced_converted.txt";
Charset sourceCharset = StandardCharsets.ISO_8859_1;
Charset targetCharset = StandardCharsets.UTF_8;
try (
ReadableByteChannel sourceChannel = Files.newByteChannel(Paths.get(sourceFile), StandardOpenOption.READ);
WritableByteChannel targetChannel = Files.newByteChannel(Paths.get(targetFile), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
) {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (sourceChannel.read(buffer) != -1) {
buffer.flip();
while (buffer.hasRemaining()) {
targetChannel.write(buffer);
}
buffer.clear();
}
System.out.println("复杂文件编码转换成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
在这个示例中,我们没有直接使用`Files.readAllBytes`和`Files.write`方法,而是使用了`ReadableByteChannel`和`WritableByteChannel`,这样我们可以更细致地控制读写过程。通过缓冲区`ByteBuffer`,我们可以逐块读取和写入数据,这对于处理大型文件尤其有用。通过循环读取每个字节块,并使用指定的源字符集进行解码,然后使用目标字符集进行编码,我们可以完成编码的转换工作。
这个复杂文件编码转换程序展示了如何处理大型文件,并且能够有效地利用系统资源。它也展示了如何灵活地使用Java NIO API进行高效的文件操作。需要注意的是,在实际应用中,我们可能还需要考虑错误处理、编码检测、字符映射等更复杂的场景。
## 4.2 网络数据传输中的字符集处理
### 4.2.1 网络编程中的字符集需求分析
在网络数据传输中,字符集的处理尤为重要,因为发送方和接收方可能使用不同的系统环境和编码配置。在构建网络应用时,需要分析应用对字符集的具体需求,并确保网络通信中数据的一致性和准确性。
通常,网络通信中的字符集需求分析需要考虑以下几个方面:
- **客户端与服务器的字符集差异**:客户端和服务器可能基于不同的操作系统或者配置了不同的字符集。
- **协议兼容性**:不同的通信协议对字符集的支持程度不一,例如HTTP协议会在头部信息中指定字符集。
- **国际化支持**:应用可能需要支持多语言,这意味着字符集转换的复杂性增加。
- **数据安全性**:在传输过程中,可能需要对数据进行编码,以防止数据被篡改或被窃听。
### 4.2.2 实现网络数据传输字符集转换的示例
为了在网络数据传输中正确处理字符集,我们可以使用Java的字符集转换功能来确保从客户端接收到的数据在服务器端能够被正确地解码。
以下是一个简单的例子,演示了如何在HTTP服务器端接收请求数据,并根据请求头中的字符集信息进行解码。
```java
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
public class HttpEncodingServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws IOException {
// 获取请求的字符集
String encoding = request.getCharacterEncoding();
if (encoding == null) {
encoding = "UTF-8"; // 默认使用UTF-8
}
// 读取请求流
BufferedReader reader = new BufferedReader(new InputStreamReader(request.getInputStream(), encoding));
String line;
while ((line = reader.readLine()) != null) {
// 处理每一行文本
}
reader.close();
}
}
```
在这个`HttpEncodingServlet`类中,我们重写了`doPost`方法来处理POST请求。首先,我们从`HttpServletRequest`获取请求的字符集信息,并且如果字符集为`null`(即未指定),则默认使用UTF-8编码。接着,我们使用获取到的字符集创建了一个`InputStreamReader`,用于从请求流中读取数据。这样,不管客户端发送的数据使用了哪种字符编码,服务器都能正确解码并处理这些数据。
通过这样的处理,我们可以确保网络数据传输中的字符集问题得到妥善解决,避免了乱码的出现,并为国际化应用提供了支持。
## 4.3 数据库字符集转换的考量
### 4.3.1 数据库字符集兼容性问题
数据库通常拥有自己的字符集设置,以便存储和检索文本数据。在Java应用中,处理不同数据库的字符集兼容性问题是一个重要的任务。数据库字符集兼容性问题主要体现在以下几个方面:
- **不同数据库的默认字符集**:比如MySQL默认使用`utf8mb4`字符集,而Oracle可能使用`AL32UTF8`。
- **数据迁移中的字符集转换**:在不同数据库平台间迁移数据时,可能需要进行字符集转换。
- **数据库连接字符集**:Java应用在连接数据库时,需要设置与数据库匹配的字符集,以避免乱码问题。
### 4.3.2 实现数据库字符集转换的策略
在实现数据库字符集转换时,我们需要考虑以下策略:
- **数据源配置**:在建立数据库连接时,通过连接字符串指定字符集,确保数据在传输过程中使用正确的字符编码。
- **查询时的字符集转换**:在执行SQL查询时,指定字符集,特别是在处理文本数据时,避免数据在查询时发生编码错误。
- **在Java应用中进行预处理**:在数据写入数据库前,进行必要的编码转换,确保数据以正确的格式存储在数据库中。
- **使用数据库提供的字符集转换功能**:对于支持字符集转换的数据库,可以直接使用数据库的内置功能进行转换。
以下是一个Java应用中处理数据库字符集转换的示例代码:
```java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class DatabaseEncodingConverter {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC";
String user = "root";
String password = "mysecret";
try (Connection connection = DriverManager.getConnection(url, user, password);
Statement statement = connection.createStatement()) {
// 指定使用UTF-8字符集执行SQL查询
String sql = "SELECT * FROM my_table WHERE name = '张三'";
statement.execute(sql);
// 处理查询结果
} catch (SQLException e) {
e.printStackTrace();
}
}
}
```
在这个示例中,我们构建了一个JDBC连接字符串,并通过`useUnicode`和`characterEncoding`参数指定了字符集为UTF-8。这样,在与数据库进行交互时,JDBC驱动会自动处理字符编码转换,确保数据的正确传输。此外,我们在SQL查询中指定了文本数据,确保了查询语句在执行时能够正确处理中文字符。通过这样的策略,我们可以有效解决数据库字符集兼容性问题,保证数据的一致性和准确性。
需要注意的是,不同数据库的连接字符串格式可能有所差异,因此需要根据实际使用的数据库进行相应的调整。同时,在处理大量数据或复杂数据结构时,还需要进行进一步的优化,比如使用批处理、分页查询等方法,提高数据处理的效率。
# 5. 字符集转换的常见问题与解决方案
## 5.1 乱码问题的诊断与解决
### 5.1.1 乱码产生的原因
在字符集转换过程中,乱码问题是最常见的困扰开发者的问题之一。乱码通常是因为编码方式不一致导致字符数据在转换过程中被错误解释。例如,一个文本文件如果是在Windows系统的记事本中以GBK编码保存的,但被操作系统或应用程序错误地当作UTF-8编码来解析,就会出现乱码。
乱码产生的具体原因包括但不限于以下几种:
- 编码方式不匹配:在文本编辑、文件保存、网络传输等过程中使用了不同的编码方式。
- 系统默认编码与实际编码不一致:操作系统或应用程序使用了错误的默认编码。
- 数据传输过程中的编码丢失:在数据传输过程中,没有明确指定或正确传输字符编码信息。
### 5.1.2 乱码问题的常见解决方案
解决乱码问题,首先要明确乱码的产生原因。以下是一些常见的解决乱码问题的策略:
1. **确定并统一编码**:确定文本文件或数据的实际编码方式,并在整个处理流程中使用相同的编码。
2. **文件头声明编码**:对于文本文件,可以在文件开头声明其编码方式,如使用UTF-8的BOM(Byte Order Mark)。
3. **使用支持多种编码的工具或库**:选择支持多种字符集编码的编辑器、库或框架来处理文本数据。
4. **转码处理**:遇到无法直接统一编码的情况,可以先将数据转换为一种中间编码格式,然后再转换为目标编码。这个过程中,需要确保中间格式支持从源编码到目标编码的转换。
5. **环境配置检查**:确保系统的默认编码设置正确,并且应用程序中使用的编码与之匹配。
接下来,我们将通过一个简单的Java代码示例来演示如何解决乱码问题。
```java
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
public class CodeConvertExample {
public static void main(String[] args) {
Charset utf8Charset = Charset.forName("UTF-8");
Charset gbkCharset = Charset.forName("GBK");
// 假设原始字符串是以GBK编码的
String originalString = "这是一段测试文本。";
ByteBuffer byteBuffer = gbkCharset.encode(originalString);
// 尝试用UTF-8解码,这里会产生乱码
CharBuffer charBuffer = utf8Charset.decode(byteBuffer);
System.out.println(charBuffer.toString());
// 使用正确的编码器进行解码
CharsetDecoder gbkDecoder = gbkCharset.newDecoder();
CharsetEncoder utf8Encoder = utf8Charset.newEncoder();
try {
charBuffer = gbkDecoder.decode(byteBuffer);
ByteBuffer outputByteBuffer = utf8Encoder.encode(charBuffer);
System.out.println(new String(outputByteBuffer.array(), utf8Charset));
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
上述代码首先将一段GBK编码的字符串转换为字节序列,然后错误地尝试用UTF-8解码,打印出乱码。随后,代码使用GBK的解码器解码字节序列,然后正确地用UTF-8编码器进行编码,从而解决了乱码问题。
## 5.2 平台与环境差异导致的字符集问题
### 5.2.1 不同操作系统间的字符集差异
不同操作系统在处理字符集和编码时可能有所差异,这主要表现在默认的编码设置上。例如,Windows系统历史上的默认编码是GBK或GB2312,而Unix/Linux系统通常默认使用UTF-8。这些差异在以下场景中可能会成为问题:
- 文件交换:在不同系统间交换文本文件时,如果不注意编码方式的差异,很容易出现乱码。
- 网络通信:网络协议如HTTP、FTP在头部信息中可能需要正确地声明字符集,否则可能会因为编码不一致导致信息错误。
- 跨平台应用开发:开发跨平台应用程序时,需要考虑编码的一致性,以确保应用在不同系统下均能正确显示文本。
### 5.2.2 跨平台应用程序的字符集处理策略
为了处理不同操作系统间的字符集差异,开发者可以采取以下策略:
1. **明确声明编码方式**:在文本文件、网络通信等场合明确声明所使用的字符编码。
2. **使用通用字符集**:优先使用跨平台兼容的字符集,如UTF-8,它在大多数操作系统中都有良好的支持。
3. **编写适应性代码**:编写能够根据运行环境自动选择字符集的代码,例如,判断操作系统类型来确定使用哪种编码。
4. **环境检测与配置**:在应用启动时检测运行环境,并据此配置字符集,或提示用户进行配置。
5. **使用抽象层**:利用抽象的字符集处理层,如Java的`Charset`类,可以有效地在代码中屏蔽不同操作系统的差异。
下面提供一个简单的Java代码示例,演示如何检测当前操作系统并根据其选择字符集:
```java
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
public class CrossPlatformEncodingExample {
public static void main(String[] args) {
// 检测当前操作系统类型
String osName = System.getProperty("os.name");
Charset encoding;
if (osName.startsWith("Windows")) {
// 对于Windows系统,通常使用GBK编码
encoding = Charset.forName("GBK");
} else if (osName.startsWith("Linux") || osName.startsWith("Mac")) {
// 对于Linux和Mac系统,通常使用UTF-8编码
encoding = Charset.forName("UTF-8");
} else {
// 对于其他未知系统,可以选择一个默认编码
encoding = Charset.defaultCharset();
}
// 使用指定编码来读取文件,以避免乱码
try (InputStreamReader isr = new InputStreamReader(new FileInputStream("example.txt"), encoding);
BufferedReader br = new BufferedReader(isr)) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
该代码段首先检测当前操作系统类型,根据操作系统类型选择合适的编码方式读取文件,从而有效地处理跨平台时的字符集差异问题。
# 6. 字符集转换的未来展望与最佳实践
在信息技术不断进步的今天,字符集转换作为一项基础但又极其重要的技术,其未来的发展趋势与最佳实践成为了值得探讨的话题。本章节将从字符集标准的发展趋势,以及如何实现高效字符集转换的最佳策略两个方面,为广大IT从业者提供深入的分析与指导。
## 6.1 字符集标准的发展趋势
随着全球化的不断深入,对字符集的需求也变得日益复杂和多样化。Unicode作为国际标准字符集,正在逐步成为全球统一的编码解决方案,而新兴字符集标准也在不断涌现,下面将进行详细分析。
### 6.1.1 Unicode的最新进展
Unicode是目前应用最广泛的字符集标准之一,旨在将全世界所有的字符系统地映射到一个单一的编码体系中。最新进展包括:
- **Unicode 13.0**:Unicode标准不断更新,其中13.0版本添加了诸多表情符号、符号、象形文字等新的字符。对于软件开发者来说,这意味着需要持续关注Unicode标准的更新,并及时更新应用中的字符集支持。
- **标准化格式**:随着Unicode的广泛应用,标准化的字符格式,如UTF-8、UTF-16等,已经成为了网络传输和文件存储的主流选择。
- **字符映射**:Unicode提供了一个全面的字符映射表,使得开发者可以更容易地处理来自不同文化背景的文本数据。
### 6.1.2 其他新兴字符集标准的介绍
除了Unicode之外,还有其他一些新兴的字符集标准也在被探讨和应用,主要包括:
- **GB18030**:这是中国国家标准的字符集编码,覆盖了几乎所有的常用汉字,以及中日韩统一表意文字扩展A区。随着中国在全球的影响力增强,GB18030在国际贸易和商务沟通中变得越来越重要。
- **其他多语言字符集**:如ISO/IEC 10646定义的统一字符集,以及针对特定语言的字符集标准,如阿拉伯语、希伯来语等特定书写系统的编码。
## 6.2 最佳实践指南
面对复杂多变的字符集转换需求,如何实现高效且无误的字符集转换显得至关重要。本节将探讨实现高效字符集转换的最佳策略,以及在实践过程中如何避免常见错误和陷阱。
### 6.2.1 实现高效字符集转换的最佳策略
要实现高效的字符集转换,以下策略是必须考虑的:
- **明确需求**:在转换之前,必须清晰了解源数据和目标数据的字符集类型。这不仅包括字符编码,还应该包括语言和地区信息。
- **使用现代API**:利用Java等编程语言提供的现代字符集API进行转换,如Java 8及以上版本推荐使用`java.nio.charset.Charset`和`java.util.stream.Collectors`等。
- **异常处理**:字符集转换过程中可能会遇到各种异常,有效的异常处理机制可以避免程序崩溃,并保留足够的错误信息用于后续的诊断和修复。
### 6.2.2 避免常见错误与陷阱的建议
- **避免直接操作字节流**:在字符集转换时,避免直接操作字节流,尤其是在处理文本文件时。字节流的直接操作很容易造成字符编码错误,从而导致乱码。
- **文档记录**:详细记录字符集转换的每个步骤,包括使用到的字符集编码、转换过程中的任何特殊处理以及遇到的问题和解决方案。这将有利于未来的维护和问题排查。
- **持续更新知识库**:字符集标准不断演进,因此开发者需要持续关注最新的标准更新,更新开发工具和库,以支持新的字符集和编码方案。
字符集转换是软件国际化和本地化过程中的一个基础环节。通过了解和掌握字符集标准的发展趋势,以及实施最佳实践策略,开发者可以提高软件的全球可用性,为用户提供更加丰富的跨文化体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Java Charset类专栏是一份全面的指南,深入探讨了Java中Charset类的各个方面。它提供了10个实用技巧和性能优化,涵盖了字符集转换、乱码解决、安全防御、I/O流协同、多语言支持、源码剖析、数据安全、选择策略、系统兼容性、自动化测试、正则表达式应用、常见问题解答、字符串转换、文件读写、网络编程、内存操作优化,以及编码器和解码器机制。通过深入的分析和示例,该专栏旨在帮助开发人员掌握Charset类的功能,解决字符集处理中的常见问题,并优化其Java应用程序的字符集处理性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S7-1200 1500 SCL编程实践:构建实际应用案例分析

# 摘要
本文全面介绍了S7-1200/1500可编程逻辑控制器(PLC)的SCL(Structured Control Language)编程技术。从基础理论出发,详细解析了SCL的语法、关键字、数据类型、程序结构、内存管理等基础要素,并探讨了编程实践中的高效编程方法、实时数据处理、调试和性能优化技巧。文章通过实际应用案例分析,展
深入理解93K:体系架构与工作原理,技术大佬带你深入浅出

# 摘要
本文全面介绍了93K技术的架构、应用和进阶学习资源。首先概述了93K的技术概览和理论基础,
KST Ethernet KRL 22中文版:高级功能解锁,案例解析助你深入应用
# 摘要
本文全面介绍了KST Ethernet KRL 22中文版的概览、核心功能及其理论基础,并深入探讨了其在高级数据处理与分析、网络通信以及设备控制方面的应用。文章首先概述了KRL语言的基本构成、语法特点及与标准编程语言的差异,然后详细阐述了KST Ethernet KRL 2
农业决策革命:揭秘模糊优化技术在作物种植中的强大应用
# 摘要
模糊优化技术作为处理不确定性问题的有效工具,在作物种植领域展现出了巨大的应用潜力。本文首先概述了模糊优化技术的基本理论,并将其基础与传统作物种植决策模型进行对比。随后,深入探讨了模糊逻辑在作物种植条件评估、模糊优化算法在种植计划和资源配置中的具体应用。通过案例分析,文章进一步揭示了模糊神经网络和遗传算法等高级技术在提升作物种植决策质量中的作用。最后,本文讨论了模糊优化技术面临
泛微E9流程与移动端整合:打造随时随地的办公体验

# 摘要
随着信息技术的不断进步,泛微E9流程管理系统与移动端整合变得日益重要,本文首先概述了泛微E9流程管理系统的核心架构及其重要性,然后详细探讨了移动端整合的理论基础和技术路线。在实践章节中,文章对移动端界面设计、用户体验、流程自动化适配及安全性与权限管理进行了深入分析。此外,本文还提供了企业信息门户和智能表单的高级应用案例,并对移动办公的未来趋势进行了展望。通过分析不同行业案例
FANUC-0i-MC参数高级应用大揭秘:提升机床性能与可靠性
# 摘要
本论文全面探讨了FANUC-0i-MC数控系统中参数的基础知识、设置方法、调整技巧以及在提升机床性能方面的应用。首先概述了参数的分类、作用及其基础配置,进而深入分析了参数的调整前准备、监控和故障诊断策略。接着,本文着重阐述了通过参数优化切削工艺、伺服系统控制以及提高机床可靠性的具体应用实例。此外,介绍了参数编程实践、复杂加工应用案例和高级参数应用的创新思路。最后,针对新技术适应性、安全合规性以及参数技术的未来发展进行了展望,为实现智能制造和工业4.0环境下的高效生产提供了参考。
# 关键字
FANUC-0i-MC数控系统;参数设置;故障诊断;切削参数优化;伺服系统控制;智能化控制
Masm32函数使用全攻略:深入理解汇编中的函数应用
# 摘要
本文从入门到高级应用全面介绍了Masm32函数的使用,涵盖了从基础理论到实践技巧,再到高级优化和具体项目中的应用案例。首先,对Masm32函数的声明、定义、参数传递以及返回值处理进行了详细的阐述。随后,深入探讨了函数的进阶应用,如局部变量管理、递归函数和内联汇编技巧。文章接着展示了宏定义、代码优化策略和错误处理的高级技巧。最后,通过操作系统底层开发、游戏开发和安全领域中的应用案例,将Masm32函数的实际应用能力展现得淋漓尽致。本文旨在为开发者提供全面的Masm32函数知识框架,帮助他们在实际项目中实现更高效和优化的编程。
# 关键字
Masm32函数;函数声明定义;参数传递;递归
ABAP流水号管理最佳实践:流水中断与恢复,确保业务连续性

# 摘要
ABAP流水号管理是确保业务流程连续性和数据一致性的关键机制。本文首先概述了流水号的基本概念及其在业务连续性中的重要性,并深入探讨了流水号生成的不同策略,包括常规方法和高级技术,以及如何保证其唯一性和序列性。接着,文章分析了流水中断的常见原因,并提出了相应的预防措施和异常处理流程。对于流水中断后如何恢复,本文提供了理论分析和实践步骤,并通过案例研究总结了经验教训。进
金融服务领域的TLS 1.2应用指南:合规性、性能与安全的完美结合

# 摘要
随着金融服务数字化转型的加速,数据传输的安全性变得愈发重要。本文详细探讨了TLS 1.2协议在金融服务领域的应用,包括其核心原理、合规性要求、实践操作、性能优化和高级应用。TLS 1.2作为当前主流的安全协议,其核心概念与工作原理,特别是加密技术与密钥交换机制,是确保金融信息安全的基础。文章还分析了合规性标准和信息安全威胁模型,并提供了一系列部署和性能调优的建议。高级应用部
约束优化案例研究:分析成功与失败,提炼最佳实践
# 摘要
约束优化是数学规划中的一个重要分支,它在工程、经济和社会科学领域有着广泛的应用。本文首先回顾了约束优化的基础理论,然后通过实际应用案例深入分析了约束优化在实际中的成功与失败因素。通过对案例的详细解析,本文揭示了在实施约束优化过程中应该注意的关键成功因素,以及失败案例中的教训。此外,本文还探讨了约束优化在实践中常用策略与技巧,以及目前最先进的工具和技术。文章最终对约束优化的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )