Caffe中的卷积神经网络(CNN)介绍与实践
发布时间: 2023-12-14 18:00:27 阅读量: 19 订阅数: 18 
# 1. Caffe简介与背景
## 1.1 Caffe框架概述
Caffe(Convolutional Architecture for Fast Feature Embedding)是一个开源的深度学习框架,由贾扬清在伯克利加州大学开发。它主要用于图像分类、目标检测和语义分割等视觉任务。
Caffe框架的主要特点是模块化、灵活性和效率。通过定义网络结构,可以方便地构建、训练和部署卷积神经网络模型。
## 1.2 Caffe的历史与演进
Caffe最早于2013年发布,并迅速成为深度学习领域的热门框架。随着时间的推移,Caffe不断演进,添加了更多的功能和支持,以满足不断增长的需求。
在Caffe的演进过程中,一些重要的版本发布包括Caffe2、Caffe on Spark和Caffe-NVIDIA等。这些版本在提供更高的性能和更大的扩展性方面做出了重要贡献。
## 1.3 Caffe的优势与应用领域
Caffe在深度学习领域有许多优势和应用领域:
- **高效性**:Caffe通过使用C++编码、并行计算和GPU加速等技术,实现了高效的模型训练和推理。
- **模块化**:Caffe的模块化设计使得用户可以灵活地构建网络结构,并且可以重用和组合不同的层和模型。
- **丰富的模型库**:Caffe内置了许多经典的卷积神经网络模型,如LeNet、AlexNet、VGG和GoogLeNet等,方便用户进行快速的模型开发和迁移学习。
- **应用广泛**:Caffe广泛应用于图像分类、目标检测、人脸识别、自然语言处理等视觉和语音任务,并在学术界和工业界都取得了很多成果。
总的来说,Caffe是一个功能强大、灵活易用的深度学习框架,可以帮助研究人员和开发者快速构建和训练卷积神经网络模型。在接下来的章节中,我们将深入探讨Caffe中的卷积神经网络基础知识以及具体的模型定义与训练方法。
# 2. 卷积神经网络基础
在这一章节中,我们将会详细介绍卷积神经网络(Convolutional Neural Network, CNN)的基础知识,包括其原理和构成要素。了解卷积神经网络的基础概念对于理解Caffe框架以及模型训练和调试都至关重要。
#### 2.1 神经网络基本概念回顾
在介绍卷积神经网络之前,我们先回顾一下神经网络的基本概念。神经网络是一种模仿人脑神经系统结构和功能的数学模型,其最基本的组成单位是神经元(Neuron)。神经网络通过将多个神经元进行连接构建而成,实现对输入数据的处理和信息提取。
在传统的神经网络模型中,通常采用全连接层(Fully Connected Layer)来实现神经元之间的连接。全连接层中的每个神经元都连接到前一层的所有神经元,这种结构使得神经网络参数量巨大,难以训练和调优。而卷积神经网络通过引入卷积层(Convolutional Layer)来减少参数量,提高模型的训练效率和泛化能力。
#### 2.2 卷积神经网络原理与构成要素
卷积神经网络是一种由多个卷积层和池化层(Pooling Layer)交替组成的网络结构。卷积层和池化层的组合实现了对输入数据的层次化抽象,从而提取出更高级别的特征表达。
**2.2.1 卷积层**
卷积层是卷积神经网络的核心部分,用于提取输入数据的特征。卷积层通过对输入数据应用卷积操作实现特定方向、尺度和模式等特征的提取。
卷积操作是一种窗口滑动的操作,它通过对输入数据和卷积核(Filter)进行逐元素的乘积和求和得到输出特征图。每一个卷积核都包含多个权重和一个偏置项,通过不同的卷积核可以提取出不同的特征。
卷积层的输出特征图可以通过以下公式计算得到:
其中,输入特征图为X,卷积核为W,输出特征图为Y,使用步长(stride)来控制窗口的滑动步长,使用填充(padding)来控制输入特征图边缘的填充方式。
**2.2.2 池化层**
池化层用于对卷积层的特征图进行下采样,减少特征图的尺寸并保留关键特征。常用的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)两种。
最大池化操作会选择输入区域中的最大值作为池化结果。最大池化可以简化特征图并保留最显著的特征。
平均池化操作则是取输入区域的平均值作为池化结果。平均池化可以平滑特征图并保留整体统计信息。
池化层的输出特征图可以通过以下公式计算得到:
其中,输入特征图为X,池化结果为Y,使用窗口大小(pool size)和步长(stride)来控制池化操作的尺寸和步长。
#### 2.3 卷积层、池化层和激活函数的作用与实现
卷积层、池化层和激活函数是构成卷积神经网络的基本要素,它们的作用分别是特征提取、特征压缩和非线性激活。
- 卷积层通过卷积操作对输入数据进行特征提取,提取出输入数据的局部特征。
- 池化层通过下采样操作对卷积层的特征图进行压缩,减少特征图的尺寸。
- 激活函数通过对卷积和池化层的输出进行非线性映射,增加网络的表达能力。
常用的激活函数有sigmoid函数、ReLU函数和tanh函数等,它们可以提供不同非线性映射特性。
以上就是卷积神经网络的基础知识介绍,下一章节中我们将会讲解Caffe中如何定义和训练CNN模型。
# 3. Caffe中的CNN模型定义与训练
在本章中,我们将介绍如何在Caffe中定义和训练卷积神经网络模型。我们将从网络参数配置开始,然后讨论如何定义模型的结构,以及如何进行数据预处理和输入层设置。最后,我们将探讨一些Caffe模型训练的优化技巧。
#### 3.1 Caffe中的网络参数配置
在使用Caffe进行模型定义和训练之前,我们首先需要进行网络参数的配置。Caffe使用一个Protobuf文件来定义网络的参数,其中包含了模型的结构、训练参数以及其他相关配置。
Protobuf文件是一种数据序列化的格式,它可以用来定义结构化数据的消息类型,并将其编码为二进制格式,使其可以在不同的系统之间进行传输和解析。
以下是一个简单的Protobuf文件示例,用于配置Caffe网络参数:
```protobuf
name: "MyCNNModel"
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 32
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Caffe是一个流行的深度学习框架,广泛应用于图像处理、语音识别和自然语言处理等领域。本专栏将系统地介绍Caffe的工作原理和基本概念,以及其在多个应用领域中的实际应用。文章中包含有关Caffe的卷积神经网络(CNN)、循环神经网络(RNN)和深度强化学习等主题的详细介绍与实践案例。此外,本专栏还涵盖了使用Caffe进行图像分类、物体检测、目标定位、语义分割、人脸识别等任务的方法和技巧。此外,还会介绍Caffe中的模型优化与加速技术、参数调优和训练技巧,以及模型压缩和模型量化技术。读者将通过阅读本专栏,了解Caffe的全面功能,并掌握在实际应用中使用Caffe进行各种深度学习任务的方法和技巧。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】通过强化学习优化能源管理系统实战
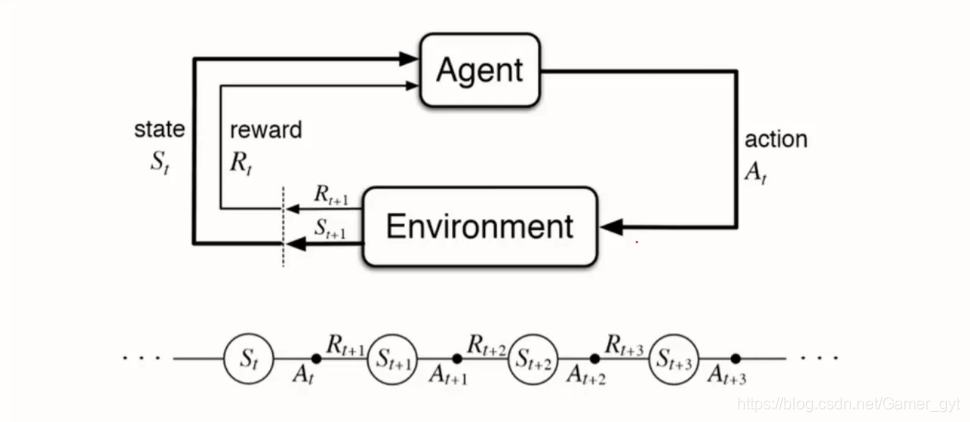
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】使用Docker与Kubernetes进行容器化管理
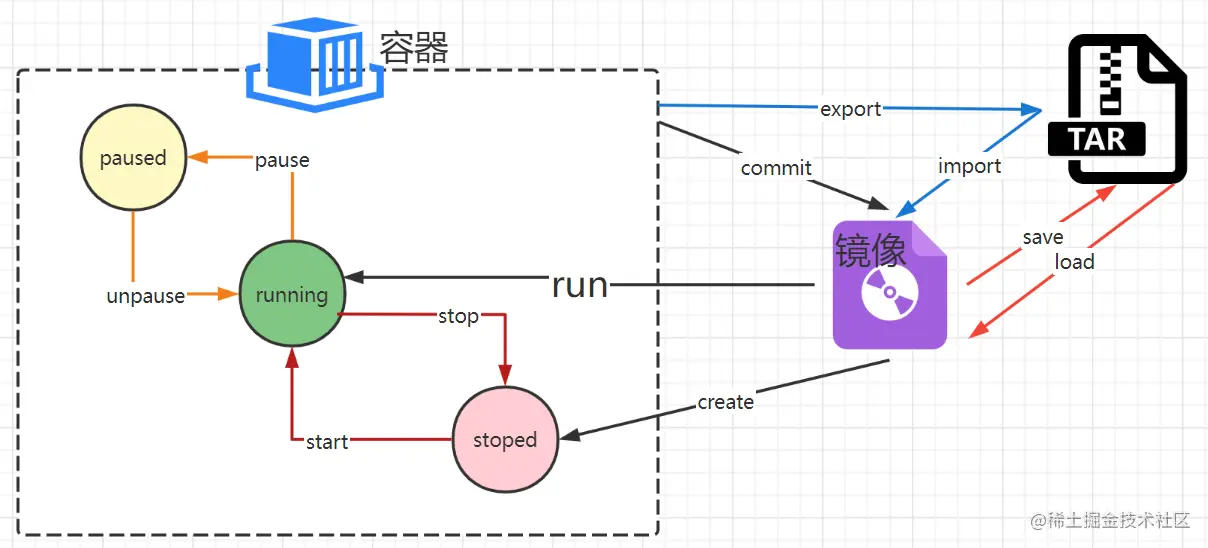
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】python云数据库部署:从选择到实施
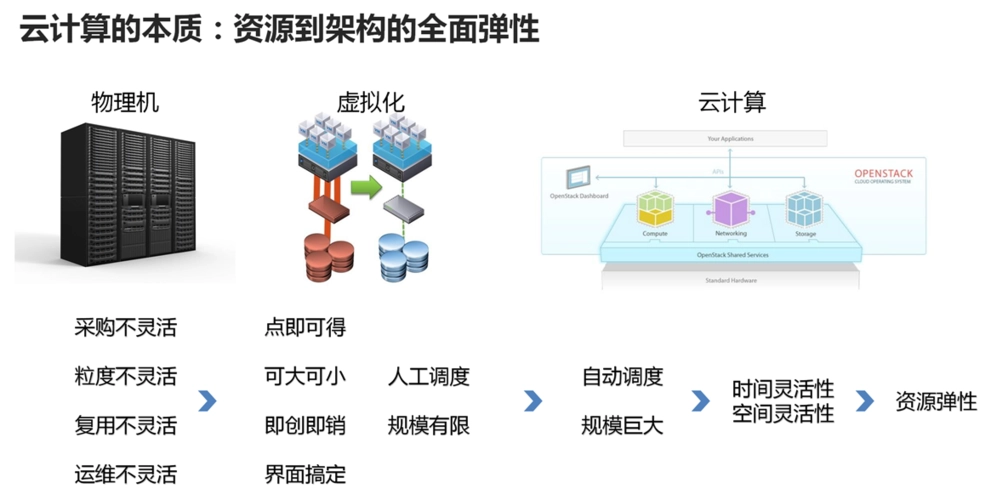
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )