状态机设计进阶:std::variant的实用技巧与案例
发布时间: 2024-10-22 17:07:28 阅读量: 34 订阅数: 40 

c++ 17 ' std::variant ' for c++ 11/14/17
# 1. 状态机设计基础与std::variant简介
## 1.1 状态机设计基础
在软件开发中,状态机是一种强大的抽象,用于建模对象在其生命周期内的行为变化。状态机包含一组状态、触发状态转移的事件以及与状态相关的动作。它们广泛用于复杂系统中,如用户界面、游戏逻辑、设备控制等。状态机的设计基础包括理解其核心组件和运行时的管理逻辑。其中,状态的表示方法、事件的触发条件以及转移规则是设计时需重点考虑的方面。
## 1.2 std::variant简介
`std::variant` 是 C++17 引入的类型安全的联合体,它能够存储一个给定类型集合中的任意类型。不同于传统的 `union`,`std::variant` 通过模板参数列表明确定义了可以存储的类型集合,避免了类型安全问题。此外,它还提供了访问当前存储值的类型信息和对值进行操作的功能。`std::variant` 为状态机设计提供了类型安全的实现途径,简化了状态和事件的管理过程。
## 1.3 状态机与std::variant的关系
利用 `std::variant` 来设计和实现状态机,可以让状态管理更加清晰和安全。由于状态机的状态变化与 `std::variant` 的类型变化具有天然的对应关系,开发者可以利用 `std::variant` 来直接表示状态机中的状态。结合 `std::visit`,可以实现对状态机当前状态的统一处理逻辑,从而简化代码结构,提高可维护性和扩展性。
# 2. std::variant的核心特性与使用技巧
## 2.1 std::variant的数据模型
### 2.1.1 variant的定义与初始化
std::variant是C++17标准中引入的一个类型安全的联合体,它允许存储一个给定的类型集合中的任意一种类型。与传统的联合体不同,std::variant在编译时期就已经知道了所有可能存储的类型,并提供了类型安全的访问方式。这样的特性使得std::variant在实现状态机、处理不同类型数据等多种场景下非常有用。
在使用std::variant之前,需要包含头文件`<variant>`。接下来,我们定义一个简单的std::variant对象,存储int和std::string类型:
```cpp
#include <variant>
#include <string>
#include <iostream>
int main() {
std::variant<int, std::string> v; // 默认构造,不含有值
v = 12; // 模拟存储int类型值
// v = "Hello World"; // 模拟存储std::string类型值
}
```
需要注意的是,std::variant构造函数不可直接调用其内部类型的构造函数。其构造函数只能初始化variant对象本身,而不能为variant中的第一个有效类型初始化。初始化特定类型需要使用赋值操作。
### 2.1.2 variant的优势与限制
std::variant的优势在于其类型安全和类型擦除特性。它提供了多种访问成员的接口,比如`std::get`,`std::get_if`,以及访问所有类型成员的操作符重载等。因此,开发者可以非常方便地访问存储在variant中的类型,而无需进行类型转换或使用不安全的`union`特性。
然而,std::variant并非万能。它在使用时也有一些限制。首先,variant在初始化时不能指定其内部的类型,即不允许直接构造一个特定类型的variant对象。其次,如果存储在variant中的数据类型拥有异常安全性问题,那么在访问这些类型时可能会抛出异常。此外,一旦variant被指定存储一种类型,后续的赋值操作将只能在这个类型集合内进行。
## 2.2 std::variant与std::monostate的组合使用
### 2.2.1 空状态的实现与应用场景
std::monostate是C++17引入的类型,专门用于variant中表示“无值”的状态。通过将monostate作为variant的一个可能类型,我们可以为variant提供一个可以代表“空”的状态。这对于需要明确区分“有值”和“无值”状态的场景非常有用。
例如,当一个variant对象可能既不存储int类型,也不存储std::string类型时,可以使用monostate:
```cpp
#include <variant>
#include <string>
#include <iostream>
int main() {
std::variant<int, std::string, std::monostate> v(std::monostate{});
// 现在v是“空”的,可以被用来表示没有初始化或者无效的状态。
v = 42; // 存储int类型值
if (std::holds_alternative<int>(v)) {
std::cout << "v 存储了一个 int 类型: " << std::get<int>(v) << std::endl;
}
// 如果v现在是std::monostate,它将不会进入这个条件分支。
// 在一些情况下,我们可以使用空状态来简化状态机的实现。
}
```
### 2.2.2 安全类型转换的方法
在variant中转换类型时,需要安全且明确的方式。std::get是获取特定类型值的最直接方式,但是它在类型不匹配时会抛出std::bad_variant_access异常。为了安全地获取值,可以使用std::get_if,它会返回指向指定类型值的指针,如果没有找到对应类型,则返回nullptr。
下面是一个安全类型转换的示例:
```cpp
#include <iostream>
#include <variant>
#include <string>
int main() {
std::variant<int, std::string> v = 123;
// 使用std::get<int>转换,会抛出异常如果类型不匹配
try {
int i = std::get<int>(v);
std::cout << "转换为int: " << i << std::endl;
} catch(const std::bad_variant_access& e) {
std::cout << "类型不匹配错误: " << e.what() << std::endl;
}
// 使用std::get_if安全获取类型
int* ip = std::get_if<int>(&v);
if (ip) {
std::cout << "安全转换为int: " << *ip << std::endl;
} else {
std::cout << "没有存储int类型" << std::endl;
}
}
```
## 2.3 std::visit的高级应用
### 2.3.1 访问variant中的数据类型
std::visit是C++17标准中的一个函数模板,它允许访问std::variant中的当前活跃的类型。该功能特别有用,当variant对象存储了一个复杂类型集合,而我们需要访问其中存储的特定类型数据时。
假设我们有一个variant存储了多种类型,包括自定义类型:
```cpp
#include <iostream>
#include <variant>
#include <string>
struct Person {
std::string name;
int age;
};
int main() {
std::variant<std::string, int, Person> v = Person{"Alice", 25};
// 访问Person类型
if (std::holds_alternative<Person>(v)) {
Person& p = std::get<Person>(v);
std::cout << "访问Person类型中的名字: " << p.name << std::endl;
}
// 使用std::visit访问Person类型
std::visit([](auto&& arg) {
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, Person>) {
std::cout << "使用visit访问Person类型中的名字: " << arg.name << std::endl;
}
}, v);
}
```
### 2.3.2 高效处理variant类型的方法
使用std::visit时,可以结合lambda表达式或其他函数对象,以实现对variant中不同类型的有效处理。由于visit是模板函数,因此在编译时期就能够确定将要访问的类型,这使得编译器能够优化访问路径,提高处理variant的效率。
这里,我们展示使用std::visit来高效处理不同类型的示例:
```cpp
#include <iostream>
#include <variant>
#include <string>
int main() {
std::variant<int, std::string> v = 42;
// 访问int和string类型
std::visit([](const auto& arg) {
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, int>) {
std::cout << "variant存储了一个int: " << arg << std::endl;
} else if constexpr (std::is_same_v<T, std::string>) {
std::cout << "variant存储了一个string: " << arg << std::endl;
}
}, v);
}
```
通过这种方式,我们可以针对不同的存储类型,执行不同的操作,而无需对variant对象进行类型检查或运行时类型识别(RTTI)。std::visit不仅可以提高代码的清晰度,而且还可以避免运行时错误,是处理variant类型数据的高效方式。
# 3. 基于std::variant的状态机实现
## 3.1 状态机的设计原理
### 3.1.1 状态机的基本概念
状态机是一种计算模型,用于描述对象在它的生命周期内所经历的状态序列,以及对特定事件的响应。在软件工程中,状态机可以被用来设计可靠且易于理解的控制逻辑。
状态机通常由一系列的状态、事件、以及触发状态转移的规则组成。在每个状态中,系统可以响应一系列事件,并根据规则决定接下来转移到哪个状态。状态机可以是简单的确定性状态机,也可以是更为复杂的非确定性状态机。
### 3.1.2 状态机的类型与实现方式
状态机有多种类型,包括有限状态机(FSM)、状态图、并发状态机等。有限状态机在每个时刻仅有一个当前状态,并且在接收到事件后,会根据转移规则切换到下一个状态。
实现状态机的方式可以是面向对象的,使用类来表示状态和事件,或者使用函数式编程范式,通过状态和事件的映射来处理状态转换。在C++中,`std::variant`提供了一种新颖的方式来实现类型安全的状态机,特别是当状态和事件的类型在编译时未知或可能变化时。
## 3.2 使用std::variant实现状态机
### 3.2.1 定义状态机的状态与转换
利用`std::variant`可以存储多个不同类型的状态,并且允许在运行时改变类型。通过定义一个类型集合,它可以存储所有可能的状态,而`std::visit`可以用来访问当前存储的状态并执行相应的行为。
```cpp
#include <variant>
#include <vector>
#include <iostream>
// 定义状态
struct Idle {};
struct Running {};
struct Stopped {};
// 定义事件
struct Start {};
struct Stop {};
struct Pause {};
// 使用variant存储状态
using State = std::variant<Idle, Running, Stopped>;
int main() {
State currentState = Idle{}; // 初始状态为Idle
State nextState;
// 处理事件
auto processEvent = [&](auto event) {
switch (event.index()) {
case 0: // Start
if (std::holds_alternative<Idle>(currentState)) {
nextState = Running{};
}
break;
case 1: // Stop
if (std::holds_alternative<Running>(currentState)) {
nextState = Stopped{};
}
break;
case 2: // Pause
if (std::holds_alternative<Running>(currentState)) {
nextState = Stopped{};
}
break;
}
currentState = nextState;
};
// 示例事件处理序列
processEvent(Start{}); // 切换到Running状态
processEvent(Stop{}); // 切换到Stopped状态
// ...
}
```
### 3.2.2 状态机的事件驱动模型
事件驱动模型是状态机的核心,它根据输入事件来决定状态转换。事件可以是用户输入、超时、传感器读数等。在`std::variant`实现的状态机中,可以使用一个函数来处理事件,该函数根据当前状态和事件类型来更新状态。
```cpp
void handleEvent(State& currentState, const auto& event) {
State next = std::visit([&](auto&& state) -> State {
using S = std::decay_t<decltype(state)>;
if constexpr (std::is_same_v<S, Idle>) {
if (std::is_same_v<std::decay_t<decltype(event)>, St
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《C++ std::variant深入剖析》全面解析了C++17中引入的std::variant类型,从入门基础到高级应用,涵盖了其使用手册、最佳实践、与std::tuple的对比、性能优化、类型检查、自定义类型擦除、异常安全性、构造函数和赋值行为、内存布局、与std::visit的结合、事件处理系统、状态机设计、并发编程、局限性和替代方案、与std::expected的对比、使用禁忌和避免技巧、与旧版本兼容性,以及从std::monostate到std::variant的类型多态演进。通过深入剖析和丰富的示例,专栏旨在帮助读者掌握std::variant的各个方面,解锁变量类型的新选择,提升代码质量和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SID模型在现代电信管理中的应用
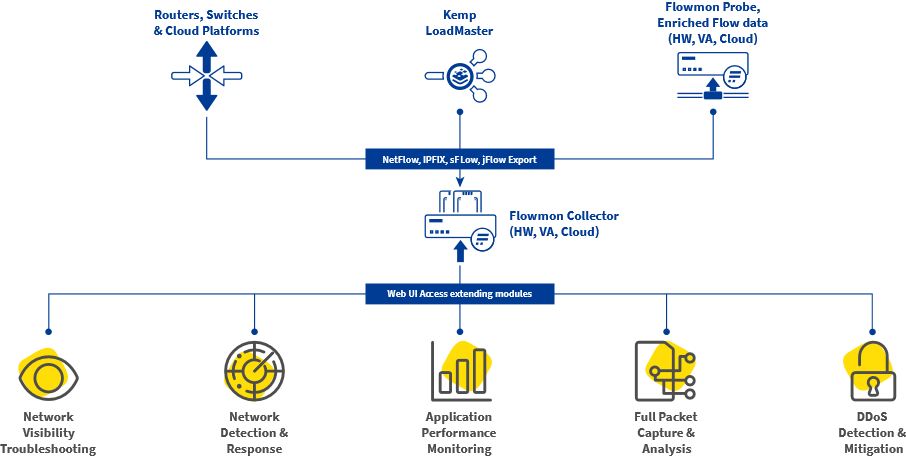
# 摘要
SID模型作为一种综合性的标识符管理方案,在网络架构、物联网和云计算等多个领域展现出强大的应用潜力和灵活性。本文首先概述了SID模型的基本概念和理论基础,包括其核心组成、层次结构、运作机制,以及在网络虚拟化和网络服务交付中的融合方式。随后,本文深入探讨了SID模型在5G网络、物联网和云计算中
Pycharm深度体验升级:Pytorch 1.11开发者必备的调试与性能优化指南

# 摘要
本文全面介绍了PyTorch 1.11的基础知识、环境搭建、项目调试技巧、性能优化方法以及Pycharm的深度使用技巧。首先,本文提供了PyTorch环境搭建的详细步骤和Pycharm集成的配置方法。接着,深入探讨了调试Pytorch程
IGBT双脉冲测试:关键要点与误区深度剖析

# 摘要
本文对IGBT双脉冲测试进行详尽的概述,探讨了测试的理论基础,包括IGBT器件的工作原理、双脉冲测试参数解析以及波形分析。进一步,本文介绍了双脉冲测试的实验操作流程、结果分析以及解读测试结果和常见误区。最后,文章展望了双脉冲测试的应用前景与技术发展趋势,分析了在研究与实践中的新挑战以及对行业标准的期待与建议。本文旨在为IGBT器件开发和性能优化提供科学的测试手段和策略,促进相
【MathCAD值域变量宝典】:实例解析与技巧分享,解锁妙用

# 摘要
本文对MathCAD的值域变量进行全面的概述和深入的分析,探讨了其理论基础与在数学计算、工程计算以及数据分析中的应用。通过实例解析,展示了值域变量在优化计算过程、提升公式可读性和维护性方面的关键作用。文章还介绍了高级应用技巧,包括递归计算、自定义函数以及与外部数据源的交互,并提出了有效的管理和调试值域变量的方法。最后,本文展望了MathCAD值域变量技术的未来
投资新产品的必修课:全面剖析制造成本控制与质量保障策略

# 摘要
制造成本控制与质量保障是企业竞争中的关键因素,直接影响着企业的经济效益与市场竞争力。本文旨在全面概述成本控制与质量保障的理论与实践,从理论基础到具体实施,再到案例分析,深入探讨如何在制造过程中实现有效成本控制和高质量保障。文中详细介绍了成本控制的基本概念、策略与方
ABB机器人故障不求人:5步快速诊断与解决指南
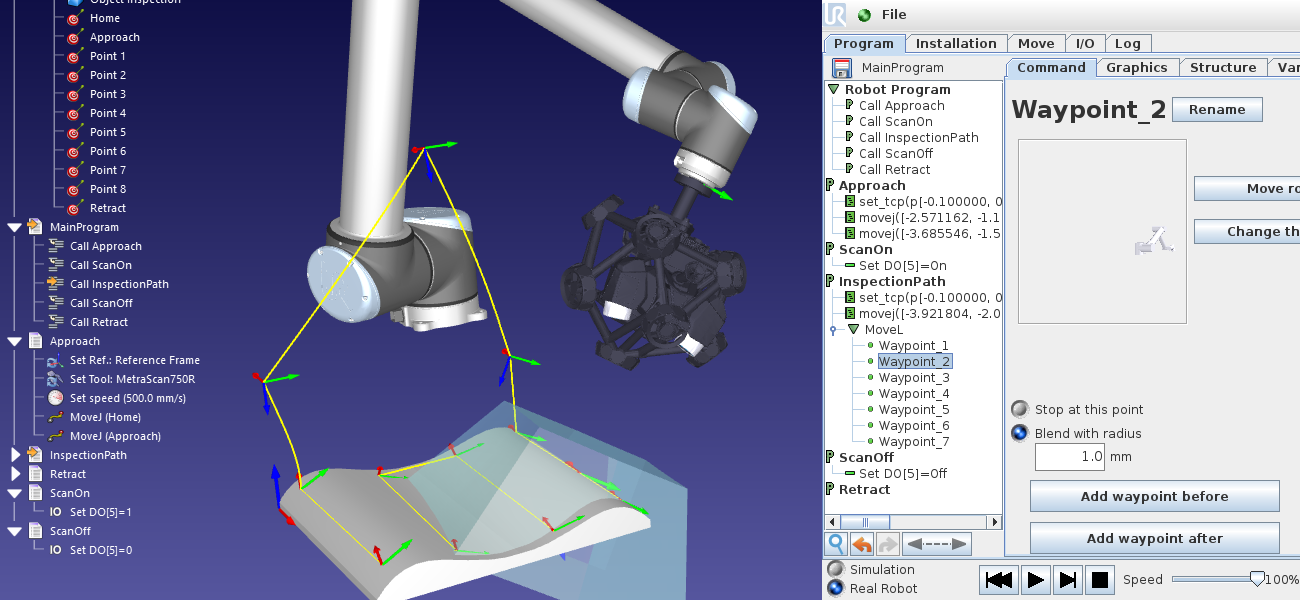
# 摘要
本文全面概述了ABB机器人的基础知识、故障诊断、解决策略、预防性维护和健康管理。首先介绍了ABB机器人的基础结构及其故障诊断的基本步骤和工具使用。其次,详细阐述了针对硬件和软件故障的修复策略,以及系统集成问题的解决方法。第三部分着重于制定和实施日常维护计划,探讨故障预防的策略和长期健康管理方案。最后一章通过实战案例分析和总结,提出了对常见故障的解决方案,以及从故障
AS5045架构与工作原理详解:掌握这5大核心,一网打尽
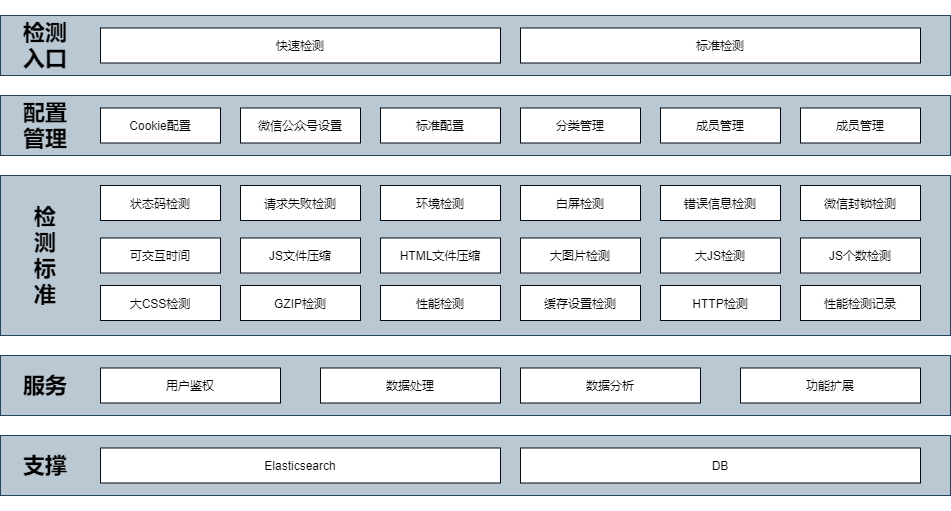
# 摘要
本文对AS5045传感器进行了全面的介绍,从其核心组件和工作原理,到编程配置,再到实际应用案例分析,最后探讨了性能优化与未来应用。AS5045传感器利用磁场检测技术和数字信号处理,实现了高精度的旋转位置测量。本文详细解释了传感器的关键功能,如数字滤波器的应用、电源管理、信号接口协议以及如何通过配置寄存器和数据处理来优化性能。此外,通过实际应用案例分析,本文探讨
【MSC.NASTRAN基础入门】:快速掌握结构分析与中文帮助文档

# 摘要
MSC.Nastran是一款强大的工程仿真分析软件,广泛应用于航空航天、汽车制造等领域。本文首先对MSC.Nastran进行了简介,详细介绍了其安装过程和基础理论,然后深入探讨了结构分析的基本理论和工作原理。在实际应用方面,本文提供了中文帮助文档的使用方法、实战演练案例分析和结构分析实战演练技巧。进阶技巧与高级应用章节,展示了非线性分析、模态分析等高级功能,并提供了一些自定义载荷
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )