【R语言数据包使用入门】:掌握数据操作与可视化,从零到英雄的7大技巧
发布时间: 2024-11-08 04:57:30 阅读量: 46 订阅数: 41 

# 1. R语言数据包概述
## 1.1 R语言简介
R是一种用于统计分析、图形表示和报告的编程语言和软件环境。它在数据科学领域具有广泛的应用,特别是在数据分析、数据挖掘和机器学习中。R语言的强项在于其灵活的图形能力,丰富且高质量的统计包。
## 1.2 R语言数据包的重要性
数据包是R语言中的模块化代码库,它包含了特定功能的函数和数据集。这些包极大地扩展了R的基础功能,使得用户能够执行更高级的数据操作、分析和可视化。为了有效地使用R,理解并熟练运用R语言数据包是必不可少的。
## 1.3 安装和管理数据包
要开始使用R语言数据包,第一步是安装它们。可以使用R的`install.packages()`函数来安装包。例如,安装`ggplot2`包的代码如下:
```r
install.packages("ggplot2")
```
安装完成后,可以使用`library()`或`require()`函数来加载并使用这些包中的函数。管理已安装的包可以通过R的包管理界面,或者使用命令行工具如`remove.packages()`来删除不再需要的包。
```r
library(ggplot2)
```
理解这些基本命令后,用户可以开始探索R语言丰富的生态系统,并利用数据包开展复杂的分析工作。在下一章中,我们将深入探讨R语言中的一些常用数据操作技巧。
# 2. R语言数据操作技巧
## 2.1 R语言数据结构与操作
### 2.1.1 向量、矩阵、数组和数据框的使用
在R语言中,数据结构是处理数据的基础。理解并掌握向量、矩阵、数组和数据框的使用是进行数据操作的第一步。
#### 向量(Vector)
向量是R中最基本的数据结构,用于存储数值型、字符型或逻辑型数据。创建向量的常用方法是使用`c()`函数。
```r
# 创建数值向量
num_vector <- c(1, 2, 3, 4, 5)
# 创建字符向量
char_vector <- c("Apple", "Banana", "Cherry")
```
#### 矩阵(Matrix)
矩阵是具有相同数据类型元素的二维数组,可以使用`matrix()`函数创建。
```r
# 创建一个3x3的矩阵
matrix_data <- matrix(1:9, nrow = 3, ncol = 3)
```
#### 数组(Array)
数组是多维的数据结构,可以使用`array()`函数创建。它与矩阵的主要区别在于可以有多个维度。
```r
# 创建一个3x3x2的数组
array_data <- array(1:18, dim = c(3, 3, 2))
```
#### 数据框(Data Frame)
数据框是R中最常用的数据结构,它可以存储不同类型的数据,且每列长度相同。数据框可以使用`data.frame()`函数创建。
```r
# 创建数据框
df <- data.frame(
ID = 1:4,
Name = c("Alice", "Bob", "Charlie", "David"),
Age = c(24, 27, 22, 25)
)
```
### 2.1.2 数据筛选和合并
数据操作经常涉及到数据的筛选和合并。R语言提供了丰富的函数和方法来实现这些操作。
#### 数据筛选
可以通过条件表达式来筛选数据框中的数据。
```r
# 筛选年龄大于23岁的个体
adults <- subset(df, Age > 23)
```
#### 数据合并
合并数据框通常使用`merge()`函数,通过指定一个或多个键值来匹配数据。
```r
# 合并两个数据框
merged_df <- merge(df1, df2, by = "ID")
```
### 2.2 R语言文本处理
#### 2.2.1 字符串操作
字符串操作是R语言文本处理中经常用到的技能。R中的`stringr`包提供了很多方便的函数。
```r
# 安装stringr包
install.packages("stringr")
# 加载stringr包
library(stringr)
# 字符串长度
str_length("Hello")
# 字符串替换
str_replace("Hello World", "World", "R")
```
#### 2.2.2 正则表达式在文本处理中的应用
正则表达式是处理文本的强大工具,R语言中通过`grep()`函数来匹配字符串。
```r
# 使用正则表达式搜索字符串
grep(pattern = "a", x = c("apple", "banana", "cherry"), value = TRUE)
```
### 2.3 R语言中的高级数据操作
#### 2.3.1 分组与聚合操作
使用`dplyr`包中的函数,可以方便地对数据进行分组和聚合操作。
```r
# 安装dplyr包
install.packages("dplyr")
# 加载dplyr包
library(dplyr)
# 数据框分组与聚合
grouped_df <- df %>%
group_by(Age) %>%
summarise(Count = n())
```
#### 2.3.2 数据透视表的实现
数据透视表可以用`tidyr`包中的`pivot_wider()`和`pivot_longer()`函数实现。
```r
# 安装tidyr包
install.packages("tidyr")
# 加载tidyr包
library(tidyr)
# 创建数据透视表
pivot_df <- pivot_wider(df, names_from = "Name", values_from = "Age")
```
以上代码块中的每个函数都有详细的逻辑分析和参数说明,通过这些内容,可以详细了解R语言在数据操作方面的强大功能。而通过本节的介绍,我们已经建立了对R语言数据操作技巧的初步了解,为后续深入学习奠定了坚实的基础。
# 3. R语言数据可视化基础
## 3.1 R语言绘图系统概览
### 3.1.1 基础图形绘制
R语言提供了一系列基础的图形绘制函数,这些函数能够帮助用户快速地将数据可视化。例如,使用`plot()`函数可以绘制散点图,`hist()`可以创建直方图来展示数据分布,`barplot()`用于生成条形图,`boxplot()`用于生成箱型图来观察数据的五数概括和异常值。
以绘制基础的散点图为例:
```r
# 示例数据
x <- 1:10
y <- rnorm(10)
# 绘制散点图
plot(x, y)
```
上述代码将生成一个简单的散点图。其中,`x`和`y`是两个向量,分别代表散点图中的横纵坐标。`plot()`函数是R语言的基础绘图函数,可以根据不同的参数绘制不同类型的图形。
### 3.1.2 图形参数的设置与调整
R语言的图形系统非常灵活,用户可以通过设置各种参数来调整图形的样式。比如颜色、标题、轴标签等。通过`par()`函数可以设置全局的图形参数,而`plot()`函数及其他绘图函数内部也提供了一些可以定制的参数。
为了更好地展示数据,我们可以添加标题和轴标签:
```r
# 绘制散点图并设置参数
plot(x, y, main = "基础散点图", xlab = "X轴标签", ylab = "Y轴标签", col = "blue")
```
在这段代码中,`main`参数用于添加图形的标题,`xlab`和`ylab`分别用于添加x轴和y轴的标签。`col`参数可以改变点的颜色,让图形更加美观。
## 3.2 R语言高级绘图包介绍
### 3.2.1 ggplot2的安装与基础使用
`ggplot2`是R语言中一个非常流行的绘图包,它基于“图形语法”的概念,能够创建复杂的图形,具有很强的灵活性和可扩展性。首先,我们需要安装并加载`ggplot2`包:
```r
install.packages("ggplot2")
library(ggplot2)
```
一旦加载了`ggplot2`,我们就可以开始绘制图形了。`ggplot()`是`ggplot2`包中创建图形的主要函数。下面是使用`ggplot()`绘制散点图的示例:
```r
# 准备数据
data <- data.frame(x = 1:10, y = rnorm(10))
# 使用ggplot绘制散点图
ggplot(data, aes(x = x, y = y)) + geom_point()
```
在这段代码中,`aes()`函数定义了数据中的变量如何映射到图形属性(如位置、颜色和形状)。`geom_point()`是一个几何对象层,表示我们要绘制点图。
### 3.2.2 创建复杂图形与图层控制
`ggplot2`的强大之处在于可以轻松地添加多个图层来构建复杂的图形。比如,可以同时在图上绘制线图和散点图,或者添加统计摘要层(如回归线)。
例如,为之前的散点图添加一个线性回归趋势线:
```r
# 添加回归线
ggplot(data, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)
```
在这段代码中,`geom_smooth()`函数被用来添加平滑层,`method`参数设置为"lm"表示使用线性模型来拟合数据。
## 3.3 R语言数据可视化技巧
### 3.3.1 自定义图形样式
在数据可视化中,自定义图形的样式是常有的需求。这包括改变图形的颜色主题、形状、大小、图例位置等。`ggplot2`的`theme()`函数可以用来调整图形的整体外观,而`scale_`系列函数则可以调整特定图形属性的外观。
例如,我们可以自定义散点的颜色和形状:
```r
ggplot(data, aes(x = x, y = y)) +
geom_point(aes(color = y, shape = y)) +
scale_color_gradient(low = "blue", high = "red") +
theme_minimal()
```
在这段代码中,`aes(color = y, shape = y)`设置了散点的颜色和形状由变量`y`的值来决定,`scale_color_gradient()`用于创建颜色渐变效果。
### 3.3.2 多图并排与图形整合
有时我们需要将多个图形并排展示,这时可以使用`patchwork`或`cowplot`包来实现。这两个包允许我们以简单的方式将不同的图形对象组合在一起。
安装并加载`patchwork`包:
```r
install.packages("patchwork")
library(patchwork)
```
并排展示两个图形的示例:
```r
# 创建两个图形对象
p1 <- ggplot(data, aes(x, y)) + geom_point()
p2 <- ggplot(data, aes(x, y)) + geom_smooth(method = "lm", se = FALSE)
# 使用patchwork将两个图形并排展示
p1 + p2
```
通过`+`操作符,`patchwork`包可以轻松地将`ggplot2`创建的图形对象进行组合。`patchwork`提供了一种简洁的语法和灵活的方式来组合图形。
这些数据可视化技巧可以显著提高你的图形质量和信息传递效率,使得分析结果更加生动和易于理解。
# 4. R语言数据包的高级应用
## 4.1 R语言中的数据库连接与操作
在处理复杂的数据分析任务时,从数据库获取数据往往是不可或缺的一个步骤。R语言提供了强大的数据库连接与操作功能,其中DBI包是一个统一的数据库接口,用于连接不同类型的数据库系统。
### 4.1.1 使用DBI包进行数据库连接
DBI包支持多种数据库,包括但不限于MySQL、PostgreSQL、SQLite等。以下是连接SQLite数据库的一个简单示例:
```r
# 安装和加载DBI包
install.packages("DBI")
library(DBI)
# 建立到SQLite数据库的连接
con <- dbConnect(RSQLite::SQLite(), dbname = "example.db")
# 列出数据库中的所有表格
dbListTables(con)
```
在这个例子中,首先通过`install.packages`安装DBI包并使用`library`函数加载它。然后,我们使用`dbConnect`函数来创建到SQLite数据库的连接。请注意替换`dbname`参数为实际数据库文件的路径。如果数据库存在且连接成功,`dbListTables`函数会列出数据库中所有的表格名称。
### 4.1.2 SQL查询在R中的实现
在连接数据库之后,我们可以使用SQL语句查询和操作数据库中的数据。DBI包同样提供执行SQL语句的函数`dbGetQuery`,以及执行SQL命令的函数`dbExecute`。
```r
# 执行SQL查询
result <- dbGetQuery(con, "SELECT * FROM iris")
# 执行SQL命令,如创建表
dbExecute(con, "CREATE TABLE IF NOT EXISTS iris_copy LIKE iris")
# 将查询结果插入到新表中
dbWriteTable(con, "iris_copy", result, append = TRUE)
```
这里,`dbGetQuery`函数用于查询数据并将结果作为一个数据框返回。`dbExecute`函数用于执行不返回结果集的SQL语句,如创建表。最后,`dbWriteTable`函数可以将一个数据框写入到指定的表中。
## 4.2 R语言中的时间序列分析
时间序列数据是按时间顺序排列的观测值的集合,常见于经济、金融、气象等领域。R语言提供了丰富的工具来进行时间序列数据的分析和预测。
### 4.2.1 时间序列数据结构与预处理
R语言使用ts对象来表示时间序列数据。我们可以使用`ts`函数创建时间序列,并进行基本的预处理。
```r
# 创建时间序列对象
ts_data <- ts(c(10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21),
start = c(2010, 1), frequency = 12)
# 进行时间序列的预处理
# 如平滑处理,这里使用移动平均法进行平滑
smoothed_ts <- filter(ts_data, filter = rep(1/3, 3), method = "convolution", sides = 2)
# 绘制原始和预处理后的时间序列图
plot(ts_data, col = "blue")
lines(smoothed_ts, col = "red")
```
在这段代码中,我们首先通过`ts`函数创建了一个时间序列对象`ts_data`,其中`start`参数定义了时间序列的起始时间,`frequency`定义了时间序列数据的频率。然后,我们使用`filter`函数对时间序列进行了平滑处理,并使用`plot`函数绘制了原始时间序列和处理后时间序列的图形。
### 4.2.2 时间序列模型的建立与预测
时间序列分析的一个重要步骤是建立预测模型,R语言的`forecast`包提供了自动的ARIMA模型拟合功能,可以快速建立预测模型。
```r
# 安装和加载forecast包
install.packages("forecast")
library(forecast)
# 使用ARIMA模型拟合时间序列
arima_model <- auto.arima(ts_data)
# 进行未来值的预测
forecasted_values <- forecast(arima_model, h = 5)
# 绘制预测值
plot(forecasted_values)
```
这里,我们首先安装并加载`forecast`包,然后使用`auto.arima`函数自动选择最优的ARIMA模型并拟合时间序列数据。`forecast`函数用于生成未来时间点的预测值。最后,使用`plot`函数绘制预测值的时间序列图。
## 4.3 R语言中的机器学习基础
机器学习是现代数据分析不可或缺的一部分,R语言不仅在统计分析领域有强大的功能,其在机器学习领域也有丰富的应用。
### 4.3.1 常用机器学习包介绍
R语言中有多个机器学习包,其中`caret`包因其功能强大且易用性高而受到广泛应用。此外,`randomForest`、`e1071`等包也是常用的机器学习包。
```r
# 安装和加载常用机器学习包
install.packages("caret")
install.packages("randomForest")
install.packages("e1071")
library(caret)
library(randomForest)
library(e1071)
# 使用randomForest包进行模型训练
rf_model <- randomForest(Species ~ ., data = iris, ntree = 100)
# 使用svm函数进行支持向量机模型训练
svm_model <- svm(Species ~ ., data = iris)
```
在这段代码中,我们安装并加载了`caret`、`randomForest`和`e1071`包。接着使用`randomForest`函数训练了一个随机森林模型,并使用`svm`函数训练了支持向量机模型。
### 4.3.2 简单的预测模型构建与评估
模型建立之后,评估模型的性能同样重要。我们可以使用`caret`包提供的`train`函数来构建模型,并使用交叉验证等技术来评估模型的准确性。
```r
# 使用caret包进行模型训练和交叉验证
fitControl <- trainControl(method = "cv", number = 10)
# 使用线性判别分析(LDA)进行模型训练
lda_model <- train(Species ~ ., data = iris,
method = "lda",
trControl = fitControl)
# 输出模型的性能评估
print(lda_model)
```
在此处,我们定义了一个交叉验证的控制参数`fitControl`,其中`method`设置为交叉验证(`cv`),`number`设置为10,表示每次训练时将数据分成10个子集进行验证。然后使用`train`函数应用线性判别分析方法(`lda`)进行模型训练,并通过打印`lda_model`对象来查看模型的性能评估结果。
通过上述章节内容的介绍,我们可以看到R语言在数据库操作、时间序列分析和机器学习方面的强大功能。这些工具和方法能够帮助数据科学家和分析师高效地处理数据、进行预测和挖掘数据中隐藏的模式和规律。
# 5. R语言实践案例分析
## 5.1 金融数据分析实例
### 5.1.1 数据导入与清洗
在金融数据分析中,准确高效地导入数据是至关重要的第一步。R语言提供了多种数据导入的方法,可以处理来自不同来源的数据,例如CSV、Excel表格、数据库以及Web数据。为了导入数据,我们可以使用 `read.csv()` 函数读取CSV文件,或者使用 `readxl` 包来处理Excel文件,甚至可以通过 `DBI` 包从数据库直接读取数据。
导入数据后,接下来需要进行数据清洗,以确保后续分析的准确性。数据清洗通常包括去除重复值、处理缺失值、数据类型转换、异常值检测和标准化处理等步骤。
```r
# 使用read.csv()函数导入数据
data <- read.csv('financial_data.csv', header=TRUE, sep=",", na.strings="NA")
# 查看数据的前几行
head(data)
# 去除重复行
data_unique <- unique(data)
# 处理缺失值,可以使用不同的方法填充或删除
data_filled <- na.omit(data_unique) # 删除含有缺失值的行
# 或者使用均值填充缺失值
data_filled <- data_unique
for(i in 1:ncol(data_filled)) {
if(is.numeric(data_filled[,i])) {
data_filled[is.na(data_filled[,i]), i] <- mean(data_filled[,i], na.rm = TRUE)
}
}
# 数据类型转换
data_filled$Date <- as.Date(data_filled$Date)
```
### 5.1.2 股票价格趋势分析与预测
在导入并清洗好数据后,我们可以进行股票价格趋势的分析和预测。这部分将结合时间序列分析和机器学习方法,来展示如何利用R语言对股票价格进行预测。
- **时间序列分析**:使用 `forecast` 包中的函数来创建时间序列模型,例如ARIMA模型。
- **机器学习**:通过训练集来构建预测模型,例如随机森林或支持向量机。
```r
# 安装并加载forecast包
if (!require(forecast)) install.packages("forecast")
library(forecast)
# 假设data_filled中有一个名为"ClosingPrice"的列,为股票收盘价
ts_data <- ts(data_filled$ClosingPrice, frequency=365) # 日数据
# 使用auto.arima进行ARIMA模型的自动选择和拟合
fit <- auto.arima(ts_data)
# 预测未来一段时间内的股票价格
forecast_result <- forecast(fit, h=30)
# 绘制预测结果的图形
plot(forecast_result)
```
## 5.2 生物信息学数据分析实例
### 5.2.1 基因表达数据的探索性分析
基因表达数据分析通常是生物信息学研究中的一个关键步骤。R语言广泛应用于基因表达数据分析,可以帮助研究者识别差异表达基因、进行聚类分析和功能富集分析等。
在探索性分析中,我们首先需要对数据进行预处理,比如数据标准化和批次效应校正。接着,我们可以使用各种统计检验方法,例如t检验或ANOVA,来识别显著差异表达的基因。
```r
# 假设gene_expression_data为基因表达矩阵,行代表基因,列代表样本
# 进行数据标准化
normalized_data <- t(apply(gene_expression_data, 1, scale))
# 使用limma包进行差异表达分析
if (!require(limma)) install.packages("limma")
library(limma)
# 设计矩阵
design <- model.matrix(~ group, data=sample_info) # group为样本分组变量,sample_info为样本信息数据框
# 差异表达分析
fit <- lmFit(normalized_data, design)
fit <- eBayes(fit)
# 查找差异表达基因
topTable(fit, coef="group1")
```
### 5.2.2 生物标志物筛选与验证
筛选生物标志物是生物信息学研究中的一个重要环节,它涉及到对差异表达基因的进一步分析和验证。通过统计分析和机器学习方法,可以筛选出与特定生物过程或疾病状态相关的标志物。
在筛选过程中,除了考虑差异表达的统计显著性,还需要考虑基因的生物学意义和已有的生物学知识。验证过程可能包括实验验证和临床验证。
```r
# 使用基于RVM(Relevance Vector Machine)的方法进行生物标志物的筛选
if (!require(svmrfe)) install.packages("svmrfe")
library(svmrfe)
# 构建特征矩阵和响应变量
feature_matrix <- as.matrix(normalized_data)
response_vector <- sample_info$response # response为样本的响应变量,如疾病状态
# 使用svmRFE算法进行特征选择
selected_features <- svmRFE(x=feature_matrix, y=response_vector, k=10)
# 输出筛选的特征
selected_features
```
## 5.3 社会科学研究数据分析实例
### 5.3.1 问卷数据的整理与分析
在社会科学研究中,问卷调查是收集数据的常用方法。R语言可以帮助研究者整理和分析问卷数据。数据整理包括数据清洗、数据类型转换等。数据分析则可能包括频率分布分析、交叉表分析、相关性分析等。
```r
# 假设questionnaire_data为问卷数据集
# 清洗数据
questionnaire_clean <- na.omit(questionnaire_data)
# 数据类型转换,例如将字符串类型的变量转换为因子类型
questionnaire_clean$Age <- as.factor(questionnaire_clean$Age)
# 使用table()函数制作交叉表
cross_table <- table(questionnaire_clean$Age, questionnaire_clean$Gender)
# 输出交叉表
cross_table
# 计算相关系数
correlation_matrix <- cor(questionnaire_clean[, c('Score1', 'Score2', 'Score3')])
```
### 5.3.2 结果的可视化展示与解释
数据分析的最终目的是将结果清晰地展示给他人,因此,可视化在数据分析中占有重要地位。使用 `ggplot2` 包可以制作高质量的图形,以便更好地展示分析结果。
```r
# 安装并加载ggplot2包
if (!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
# 绘制条形图展示某一个问题的响应分布
ggplot(questionnaire_clean, aes(x=Question1)) +
geom_bar() +
labs(title="Distribution of Responses to Question 1", x="Response", y="Count")
```
以上所述案例展示了如何使用R语言在不同领域的实际应用。这些案例从数据导入、清洗、分析到结果展示,涵盖了从基础到高级应用的全方位实践。在实际应用中,根据具体的数据特性和分析目标,还需要进行相应的调整和优化。
# 6. R语言的扩展与进阶
## 6.1 R语言包的开发与维护
### 6.1.1 包结构与函数编写
在R语言中开发一个包(Package)不仅能组织和共享代码,还能提高代码的复用性和可维护性。包的开发主要涉及创建包的文件结构、编写函数、撰写文档和测试。
首先,创建一个包的基本结构,这可以通过R的命令行工具`usethis`来完成:
```R
usethis::create_package("path/to/your/package")
```
在包的目录中,最起码需要包含以下三个文件:
- `DESCRIPTION`:包的描述文件,包括包的名称、版本、作者、依赖等。
- `NAMESPACE`:声明包的函数和外部函数的调用。
- `R/`:用于存放R函数的目录。
编写函数时,应该遵循命名规范和参数设计,如下示例:
```R
#' My custom function
#'
#' This function performs a simple operation.
#'
#' @param x An input parameter
#' @return The output of the operation
#' @export
#' @examples
#' my_function(2)
my_function <- function(x) {
x * 2
}
```
上述代码中的`@export`标签表示此函数将会在包被加载时对用户可见。而`@examples`标签允许你提供一个或多个使用函数的示例,这有助于用户了解如何使用你的函数。
### 6.1.2 文档编写与用户支持
文档是包的重要组成部分,它能让用户了解如何使用包中的函数。R包通常使用Roxygen2标签来编写文档,这些标签直接位于函数的源代码之上。Roxygen2会自动处理这些注释,并生成`man/`目录下的`.Rd`文件,R会使用这些文件来生成帮助文档。
一个典型的Roxygen2注释块如下所示:
```R
#' Add two numbers
#'
#' This function takes two numbers as arguments and returns their sum.
#'
#' @param x A number.
#' @param y A number.
#' @return A number.
#' @examples
#' add_two_numbers(1, 1)
#' @export
add_two_numbers <- function(x, y) {
x + y
}
```
为了提供用户支持,你可以创建`README.Rmd`文件,其中可以包含包的介绍、使用示例和任何其他的帮助信息。通过`pkgdown`包,可以将`README.Rmd`转换成一个功能齐全的网站,方便用户浏览和下载。
## 6.2 R语言性能优化
### 6.2.1 代码优化技巧
性能优化是任何数据科学项目的重要部分。R语言虽然方便快捷,但在处理大量数据或复杂模型时可能会变慢。以下是几种常见的代码优化技巧:
- 使用向量化操作代替循环,以利用R的矩阵和数组操作。
- 避免在循环内部多次调用函数,特别是涉及到查找和修改环境的操作。
- 使用`data.table`包来处理大型数据框,它比标准的`data.frame`更加高效。
- 用`apply`系列函数替代循环,特别是处理矩阵或数组时。
- 预分配内存给向量和列表,避免在循环中动态增长数据结构。
例如,使用`data.table`的性能改进对比:
```R
library(data.table)
# 假设dt是data.table对象,X和Y是列名
system.time(for (i in 1:10000) dt[, Z := sum(X, Y)])
# 使用data.table的聚合函数和特殊语法
system.time(dt[, Z := sum(X, Y), by = GroupingColumn])
```
### 6.2.2 多线程与并行计算在R中的应用
当处理大型数据集或复杂模型时,单线程可能成为性能瓶颈。R提供了多线程和并行计算的能力,可以显著加快计算速度。
- **多线程**:一些现代R包支持多线程,比如`parallel`包提供了多核计算的支持。`mclapply`函数可以并行执行任务,并返回结果列表。
```R
library(parallel)
results <- mclapply(1:100, function(i) { sqrt(i) }, mc.cores = 4)
```
- **并行计算**:对于需要大量计算的复杂问题,可以使用`foreach`包进行并行计算。它允许用户指定并行后端,并且可以与`doParallel`包一起使用。
```R
library(doParallel)
cl <- makeCluster(4)
registerDoParallel(cl)
results <- foreach(i = 1:100) %dopar% { sqrt(i) }
stopCluster(cl)
```
通过这些优化技巧和并行计算方法,R语言用户可以显著提升代码的执行效率,处理更大规模的数据集。
## 6.3 R语言与其他编程语言的交互
### 6.3.1 R与Python的交互
R和Python是当今数据科学领域最受欢迎的两种编程语言。它们各有优势,因此在某些情况下混合使用R和Python代码是有益的。
- **使用`reticulate`包**:R中有一个流行的包`reticulate`,可以创建一个与Python环境交互的桥接。它允许你直接在R代码中调用Python函数和使用Python对象。
```R
library(reticulate)
# 连接到Python
use_python("/usr/bin/python3")
# 在R中使用Python模块
np <- import("numpy")
result <- np$array(c(1, 2, 3))
```
- **使用R中的Python环境**:`reticulate`也支持使用特定版本的Python,甚至是在虚拟环境中。
### 6.3.2 R与C++的接口使用
在性能要求极高的情况下,R语言可以借助C++来编写某些关键性能部分的代码。这样做可以在R语言的易用性与C++的高效性之间取得平衡。
- **使用`Rcpp`包**:`Rcpp`是R与C++交互最常用的包之一。它允许你用C++编写代码,并通过简单的接口将其导出到R环境中。这通常带来显著的速度提升。
```cpp
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
NumericVector addTwoNumbers(NumericVector x, NumericVector y) {
return x + y;
}
```
然后使用Rcpp包的`sourceCpp()`函数来编译和加载C++代码。
通过掌握这些交互技术,R语言用户可以更加灵活地解决复杂的数据科学问题,同时利用其他编程语言的优势。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 R 语言数据包使用教程,涵盖入门到高级应用的各个方面。从数据操作和可视化基础到复杂数据集解析和自定义 R 包,本专栏将指导您掌握 R 语言数据包的强大功能。您将学习如何使用 Rcharts 创建动态图表,提升数据处理和分析效率,并解决实际问题。此外,本专栏还提供调试技巧、性能优化策略、安全性分析指南和社区互动建议,帮助您成为 R 语言数据包的熟练用户。无论您是数据分析新手还是经验丰富的专家,本专栏都能为您提供宝贵的见解和实用技巧,让您充分利用 R 语言数据包,提升您的数据处理和分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【西数硬盘维修WDR5.3固件与硬件修复】:掌握固件升级与硬件故障诊断

# 摘要
本文全面探讨了西数硬盘维修的相关知识和技能,从西数硬盘的市场地位及常见问题入手,阐述了固件的重要性和维修基础,深入解析了固件结构以及升级工具和步骤。接着,文章详细介绍了硬件故障的诊断方法、修复技术和测试验证。进阶维修技巧与策略部分,讨论了数据恢复技术和特殊情况下的维修策略,并强调了维修工具与资源的重要性。最后,通过案例分析与实战演练,展示了理论知识在实践中
电气工程知识转化秘籍:毕业设计中的创新解决方案

# 摘要
电气工程作为一门综合性强的技术学科,对于创新思维和理论实践应用提出了较高要求。本文首先回顾了电气工程的基础知识,随后深入探讨了毕业设计中创新思维的重要性,通过分析理论基础和实际问题的创新解决方案,揭示了电气工程创新的理论与实践路径。通过对智能电网、电力电子技术、变频技术以及可再生能源技术的案例分析,本文突出了电气工程实践应用的重要性和复杂性。同时,本文还讨论了电
继电保护系统设计:IT专家教你实现最佳实践

# 摘要
本文旨在全面探讨继电保护系统的理论与实践应用,涵盖从基本设计原则到软硬件实现的多个方面。首先,介绍了继电保护的基础理论、系统架构及其常见问题与解决方案。随后,深入分析了继电保护软件设计的理论基础、保护算法的实现,以及软件测试与质量保证的方法。进一步地,讨论了继电保护系统硬件的选择、配置、调试与维护。最后,通过具体案例分析,总结了最佳实践、问题解决方案及经验教训,为提高继电保护系统的可靠性、有效性和适应性提供
【网络启动与虚拟化结合】:快速部署虚拟环境的实战技巧
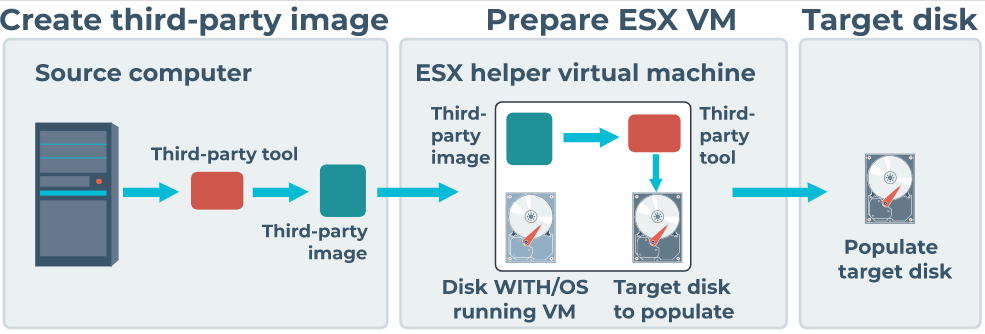
# 摘要
网络启动与虚拟化技术是现代计算环境中的关键技术,它们能够提升计算资源的灵活性、可扩展性及管理效率。本文从基础概念讲起,详细探讨了网络启动技术的工作原理、环境搭建以及其高级特性。同时,文中阐述了虚拟化技术的分类、平台配置、网络设置以及在实际环境中的应用和管理。此外,本文还提出了网络启动与虚拟化结合的实践案例,包括虚拟机的自动化部署和性能优化策略。在最后的章节中,面对潜
三菱PLC-FX3U-4LC指令集:掌握这些编程技巧,提升效率不是梦!
# 摘要
本文全面解析了三菱PLC-FX3U-4LC的基础概念、核心指令以及编程实践技巧,并探讨了如何通过高级编程技术提升编程效率和系统维护质量。文章从基础概念开始,详细解读了数据寄存器、定时器、计数器等常用基础指令和高级控制指令的应用。在编程实践章节,通过对实际工程项目指令的应用分析,进一步讨论了高效编程技巧和代码优化方法。文章还深入探讨了如何通过指令集的创新应用、软件工具的使用以及编程规范的维护,来提升PLC编程效率和质量。最后,文章展望了PLC技术的未来趋势,并为个人技能提升及职业发展提出建议。
# 关键字
PLC-FX3U-4LC;基础指令;高级控制指令;编程实践;编程效率;个人技能
【QWS数据集全面解析】:精通数据集结构、处理与应用

# 摘要
QWS数据集作为研究和实践中的关键资源,在数据科学领域发挥着重要作用。本文首先概述了QWS数据集的背景、结构组成以及来源和规模,提供了对该数据集基本认识的框架。随后,文章深入分析了数据集的结构,包括元数据的解读及其与数据质量的关系,内容的详细分类和统计特性,以及数据的组织、存
【物联网集成】:利用ModbusPoll构建智慧设备监控系统

# 摘要
物联网集成与智慧设备监控在现代化管理中变得越来越重要。本文首先概述了智慧设备监控的概念,随后深入探讨了Modbus协议的基本原理、技术细节以及通信模式,包括其RTU与TCP模式的差异。接着,文章介绍了ModbusPoll工具的安装、配置和在数据监控及系统集成中的应用。在实践应用部分,本文详细阐述了监控系统的架构设计和使用ModbusPoll进行数据采集
电子实验仿真提升秘籍:电路设计效率与质量的30个实用技巧

# 摘要
电子实验仿真在现代电子设计中扮演着至关重要的角色,它能够提前发现问题、优化设计并缩短研发周期。本文首先概述了电子实验仿真的重要性和理论基础,包括电路原理掌握、仿真软件选择与环境配置、电路设计前的准备工作。随后,详细探讨了仿真过程中的实践技巧,如仿真工具的使用、电路调试、数据分析及验证。文章进一步介绍了提升电路设计质量的方法,包括元件和布局优化、噪声抑制与电磁兼容性
汇编代码实践:雷军技术在现代项目中的5种应用方法
# 摘要
汇编语言作为一种低级编程语言,在系统级优化、安全领域的应用以及硬件接口编程等方面具有不可替代的作用。本文从汇编语言的基础与特性开始,探讨了其在现代项目整合中的应用,并着重分析了汇编在提升系统级应用性能、实现安全机制以及硬件接口编程中的具体实践。文章深入探讨了代码优化理论、安全机制理论以及硬件通信机制,并结合实际
【硬盘数据完整性】:确保Ghost克隆成功的关键技巧

# 摘要
硬盘数据完整性是保证数据安全与可靠性的关键因素。本文首先概述了硬盘数据完整性的概念,并详细探讨了硬盘克隆的基本原理和数据完整性的重要性。随后,文章深入分析了实现数据完整性的理论知识,包括数据存储原理、校验与恢复技术,以及Ghost克隆软件的使用原理。实践中,本文介绍了Ghost克隆操作的准备工作、执行过程以及验证与优化方法。高级技巧章节则探讨了数据校
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )