【MATLAB数据拟合指南】:从零基础到精通,掌握数据拟合的秘诀
发布时间: 2024-06-07 23:06:26 阅读量: 122 订阅数: 39 

《COMSOL顺层钻孔瓦斯抽采实践案例分析与技术探讨》,COMSOL模拟技术在顺层钻孔瓦斯抽采案例中的应用研究与实践,comsol顺层钻孔瓦斯抽采案例 ,comsol;顺层钻孔;瓦斯抽采;案例,COM

# 1. MATLAB数据拟合概述**
MATLAB数据拟合是一种利用MATLAB软件对数据进行建模和分析的技术,旨在找到一条或多条曲线来近似表示数据点。它广泛应用于科学、工程和金融等领域,用于预测、插值、滤波和可视化。
数据拟合的主要目的是减少数据中的噪声和异常值,并揭示数据的潜在趋势和模式。通过拟合一条曲线,我们可以对数据进行预测、插值和外推。此外,数据拟合还可以帮助我们识别数据中的异常值和错误,并对数据进行降噪和滤波。
# 2. MATLAB数据拟合理论基础
### 2.1 数据拟合的数学原理
#### 2.1.1 最小二乘法
最小二乘法是一种广泛用于数据拟合的数学方法,其目标是找到一组参数,使得拟合曲线与给定数据点的残差平方和最小。残差是实际数据点与拟合曲线之间垂直距离的平方。
**数学原理:**
给定一组数据点 $(x_i, y_i), i = 1, 2, ..., n$,最小二乘法拟合一条直线 $y = mx + c$,其中 $m$ 和 $c$ 为待定的参数。残差平方和为:
```
S = \sum_{i=1}^n (y_i - (mx_i + c))^2
```
最小二乘法通过求解以下方程组来找到 $m$ 和 $c$ 的最优值:
```
\frac{\partial S}{\partial m} = 0, \quad \frac{\partial S}{\partial c} = 0
```
求解方程组得到:
```
m = \frac{\sum_{i=1}^n x_i y_i - n\bar{x}\bar{y}}{\sum_{i=1}^n x_i^2 - n\bar{x}^2}, \quad c = \bar{y} - m\bar{x}
```
其中,$\bar{x}$ 和 $\bar{y}$ 分别为数据点的平均值。
#### 2.1.2 最大似然估计
最大似然估计是一种基于概率论的拟合方法,其目标是找到一组参数,使得拟合模型的似然函数最大。似然函数表示给定参数值下观察到数据的概率。
**数学原理:**
假设数据点服从正态分布,则似然函数为:
```
L(\theta) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - f(x_i, \theta))^2}{2\sigma^2}\right)
```
其中,$\theta$ 为拟合模型的参数,$\sigma^2$ 为方差。最大似然估计通过求解以下方程组来找到 $\theta$ 的最优值:
```
\frac{\partial L(\theta)}{\partial \theta_j} = 0, \quad j = 1, 2, ..., k
```
其中,$k$ 为 $\theta$ 的维数。
### 2.2 拟合模型的类型
#### 2.2.1 线性回归
线性回归是一种拟合线性模型 $y = mx + c$ 的方法,其中 $m$ 和 $c$ 为待定的参数。线性回归通常用于预测连续变量。
#### 2.2.2 多项式拟合
多项式拟合是一种拟合多项式模型 $y = a_0 + a_1x + a_2x^2 + ... + a_nx^n$ 的方法,其中 $a_i$ 为待定的参数。多项式拟合可以用于拟合复杂非线性数据。
#### 2.2.3 非线性拟合
非线性拟合是一种拟合非线性模型 $y = f(x, \theta)$ 的方法,其中 $f$ 为非线性函数,$\theta$ 为待定的参数。非线性拟合通常用于拟合复杂的数据,例如指数函数、对数函数和高斯函数。
# 3. MATLAB数据拟合实践
### 3.1 数据导入和预处理
#### 3.1.1 数据文件格式
MATLAB支持多种数据文件格式,包括:
- **MAT文件:**MATLAB的二进制数据文件格式,用于存储MATLAB变量。
- **CSV文件:**以逗号分隔值的文本文件,用于存储表格数据。
- **TXT文件:**以空格或制表符分隔值的文本文件,用于存储表格数据。
- **XLS/XLSX文件:**Microsoft Excel电子表格文件。
#### 3.1.2 数据清洗和转换
数据预处理是数据拟合的关键步骤,包括:
- **缺失值处理:**使用`isnan()`函数识别缺失值,并使用`fillmissing()`函数填充缺失值。
- **异常值处理:**使用`isoutlier()`函数识别异常值,并使用`rmoutliers()`函数删除异常值。
- **数据转换:**将数据转换为所需的格式,例如使用`str2num()`函数将字符串转换为数字。
### 3.2 模型选择和拟合
#### 3.2.1 拟合函数的选择
拟合函数的选择取决于数据的特征和拟合目的。MATLAB提供了多种拟合函数,包括:
- **线性回归:**`polyfit()`函数用于拟合线性函数。
- **多项式拟合:**`polyfit()`函数用于拟合多项式函数。
- **非线性拟合:**`fit()`函数用于拟合非线性函数,例如指数函数、高斯函数。
#### 3.2.2 拟合参数的优化
拟合参数是拟合函数中的未知系数。MATLAB使用非线性优化算法优化拟合参数,以最小化拟合误差。
**代码块:**
```matlab
% 数据
x = [1, 2, 3, 4, 5];
y = [2, 4, 6, 8, 10];
% 拟合线性函数
p = polyfit(x, y, 1);
% 拟合参数
a = p(1);
b = p(2);
% 拟合曲线
y_fit = a * x + b;
```
**代码逻辑分析:**
- `polyfit()`函数使用最小二乘法拟合线性函数。
- 拟合参数`a`和`b`分别表示斜率和截距。
- `y_fit`变量存储拟合曲线上的点。
### 3.3 拟合结果评估
#### 3.3.1 残差分析
残差是实际数据点和拟合曲线上的点之间的差值。残差分析可以评估拟合的准确性。
**代码块:**
```matlab
% 计算残差
residuals = y - y_fit;
% 绘制残差图
plot(x, residuals, 'o');
xlabel('x');
ylabel('Residuals');
title('Residuals Plot');
```
**代码逻辑分析:**
- `residuals`变量存储残差。
- 残差图显示残差随自变量的变化情况。
#### 3.3.2 拟合优度指标
拟合优度指标量化拟合的准确性,包括:
- **决定系数(R^2):**表示拟合曲线解释数据变异的程度。
- **均方根误差(RMSE):**表示拟合曲线和实际数据点之间的平均误差。
**代码块:**
```matlab
% 计算决定系数
R2 = 1 - sum(residuals.^2) / sum((y - mean(y)).^2);
% 计算均方根误差
RMSE = sqrt(mean(residuals.^2));
```
**代码逻辑分析:**
- `R2`变量存储决定系数。
- `RMSE`变量存储均方根误差。
# 4. MATLAB数据拟合高级应用
### 4.1 数据插值和外推
数据插值和外推是数据拟合中的重要技术,用于估计已知数据点之间的或超出已知数据范围的值。
**4.1.1 线性插值**
线性插值是最简单的插值方法,它假设数据点之间存在线性关系。给定两个已知数据点 `(x1, y1)` 和 `(x2, y2)`,则在 `x` 范围 `[x1, x2]` 内的插值值 `y` 为:
```
y = y1 + (y2 - y1) * (x - x1) / (x2 - x1)
```
**代码块:**
```matlab
% 已知数据点
x = [1, 2, 3, 4, 5];
y = [2, 4, 6, 8, 10];
% 要插值的数据点
x_interp = 2.5;
% 线性插值
y_interp = y(1) + (y(2) - y(1)) * (x_interp - x(1)) / (x(2) - x(1));
fprintf('插值值:%.2f\n', y_interp);
```
**逻辑分析:**
* 使用 `y(1)` 和 `y(2)` 表示已知数据点 `(x1, y1)` 和 `(x2, y2)`。
* 根据线性插值公式计算插值值 `y_interp`。
**4.1.2 样条插值**
样条插值是一种更复杂的插值方法,它假设数据点之间存在局部多项式关系。它比线性插值更准确,但计算成本也更高。
**代码块:**
```matlab
% 已知数据点
x = [1, 2, 3, 4, 5];
y = [2, 4, 6, 8, 10];
% 要插值的数据点
x_interp = 2.5;
% 样条插值
spline_interp = interp1(x, y, x_interp, 'spline');
fprintf('样条插值值:%.2f\n', spline_interp);
```
**逻辑分析:**
* 使用 `interp1` 函数进行样条插值,指定插值类型为 `'spline'`。
* `spline_interp` 存储插值值。
### 4.2 数据降噪和滤波
数据降噪和滤波是数据拟合中的另一个重要技术,用于去除数据中的噪声和异常值。
**4.2.1 平滑滤波**
平滑滤波是一种简单的降噪方法,它通过对数据进行平均来去除噪声。
**代码块:**
```matlab
% 原始数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20];
% 平滑滤波窗口大小
window_size = 3;
% 平滑滤波
smoothed_data = smoothdata(data, 'movmean', window_size);
% 绘制原始数据和滤波后数据
plot(data, 'b', 'LineWidth', 2);
hold on;
plot(smoothed_data, 'r', 'LineWidth', 2);
legend('原始数据', '滤波后数据');
```
**逻辑分析:**
* 使用 `smoothdata` 函数进行平滑滤波,指定滤波类型为 `'movmean'` 和窗口大小 `window_size`。
* `smoothed_data` 存储滤波后的数据。
**4.2.2 傅里叶变换滤波**
傅里叶变换滤波是一种更高级的降噪方法,它通过将数据转换为频域来去除噪声。
**代码块:**
```matlab
% 原始数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20];
% 傅里叶变换
fft_data = fft(data);
% 创建滤波器
filter_order = 5;
cutoff_frequency = 0.2;
filter = ones(1, filter_order);
filter(1:round(cutoff_frequency * filter_order)) = 0;
% 应用滤波器
filtered_fft_data = fft_data .* filter;
% 反傅里叶变换
filtered_data = ifft(filtered_fft_data);
% 绘制原始数据和滤波后数据
plot(data, 'b', 'LineWidth', 2);
hold on;
plot(filtered_data, 'r', 'LineWidth', 2);
legend('原始数据', '滤波后数据');
```
**逻辑分析:**
* 使用 `fft` 函数将数据转换为频域。
* 创建一个低通滤波器,通过将高频分量设置为 0 来去除噪声。
* 使用 `ifft` 函数将滤波后的频域数据转换为时域。
* `filtered_data` 存储滤波后的数据。
### 4.3 数据可视化
数据可视化是数据拟合中不可或缺的一部分,它可以帮助理解拟合结果和识别异常值。
**4.3.1 拟合曲线绘制**
拟合曲线绘制用于可视化拟合模型和原始数据之间的关系。
**代码块:**
```matlab
% 拟合模型
model = fitlm(x, y);
% 拟合曲线
fit_curve = predict(model, x);
% 绘制拟合曲线和原始数据
plot(x, y, 'bo');
hold on;
plot(x, fit_curve, 'r-', 'LineWidth', 2);
legend('原始数据', '拟合曲线');
```
**逻辑分析:**
* 使用 `fitlm` 函数拟合数据。
* 使用 `predict` 函数预测拟合曲线。
* 绘制拟合曲线和原始数据。
**4.3.2 残差图绘制**
残差图用于可视化拟合模型的残差,即实际值和拟合值之间的差值。
**代码块:**
```matlab
% 残差
residuals = y - fit_curve;
% 绘制残差图
plot(x, residuals, 'ro');
xlabel('x');
ylabel('残差');
title('残差图');
```
**逻辑分析:**
* 计算残差。
* 绘制残差图,x 轴表示数据点,y 轴表示残差。
# 5. MATLAB数据拟合实战案例**
**5.1 预测股票价格**
**5.1.1 数据收集和预处理**
1. 收集历史股票价格数据,包括开盘价、收盘价、最高价、最低价和成交量。
2. 将数据导入MATLAB工作区,并进行清洗和转换,包括:
- 删除异常值或缺失值。
- 将日期时间转换为数值格式。
- 标准化数据,使其具有相似的均值和方差。
**5.1.2 模型选择和拟合**
1. 选择合适的拟合模型,例如:
- 线性回归:用于预测股票价格的线性趋势。
- 多项式拟合:用于捕获更复杂的非线性趋势。
- ARIMA模型:用于预测时间序列数据的未来值。
2. 使用`fitlm`、`polyfit`或`arima`等MATLAB函数拟合模型。
3. 优化拟合参数,以最小化残差平方和。
**5.1.3 预测结果评估**
1. 使用交叉验证或留出集来评估模型的预测性能。
2. 计算拟合优度指标,例如:
- 均方根误差(RMSE)
- 决定系数(R^2)
3. 分析残差图,检查模型的拟合优度和是否存在异常值。
**5.2 拟合医学图像**
**5.2.1 图像预处理**
1. 导入医学图像,例如CT或MRI图像。
2. 应用图像处理技术,包括:
- 噪声去除
- 对比度增强
- 图像分割
**5.2.2 模型选择和拟合**
1. 选择合适的拟合模型,例如:
- 高斯分布:用于拟合图像中的噪声分布。
- 对数正态分布:用于拟合图像中的组织密度分布。
- 级联分类器:用于检测和分类图像中的特定特征。
2. 使用`fitgmdist`、`fitdist`或`fitcensemble`等MATLAB函数拟合模型。
**5.2.3 拟合结果应用**
1. 使用拟合模型进行图像分析,例如:
- 测量组织体积
- 检测病变
- 分割不同组织类型
2. 将拟合结果用于医学诊断、治疗计划或研究目的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MATLAB数据拟合指南》专栏深入探讨了MATLAB数据拟合的方方面面。从基础概念到高级技术,该专栏提供了全面且易于理解的指南,帮助读者掌握数据拟合的精髓。专栏涵盖了数学奥秘、疑难杂症解决、性能优化以及在各种领域的实际应用,包括深度学习、图像处理、金融建模、生物信息学、化学、工程学、社会科学、教育、商业和制造业。通过深入的分析和实用的示例,该专栏旨在帮助读者提升MATLAB数据拟合技能,并充分利用其在各个领域的强大价值。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
【编译原理实验报告解读】:燕山大学案例分析
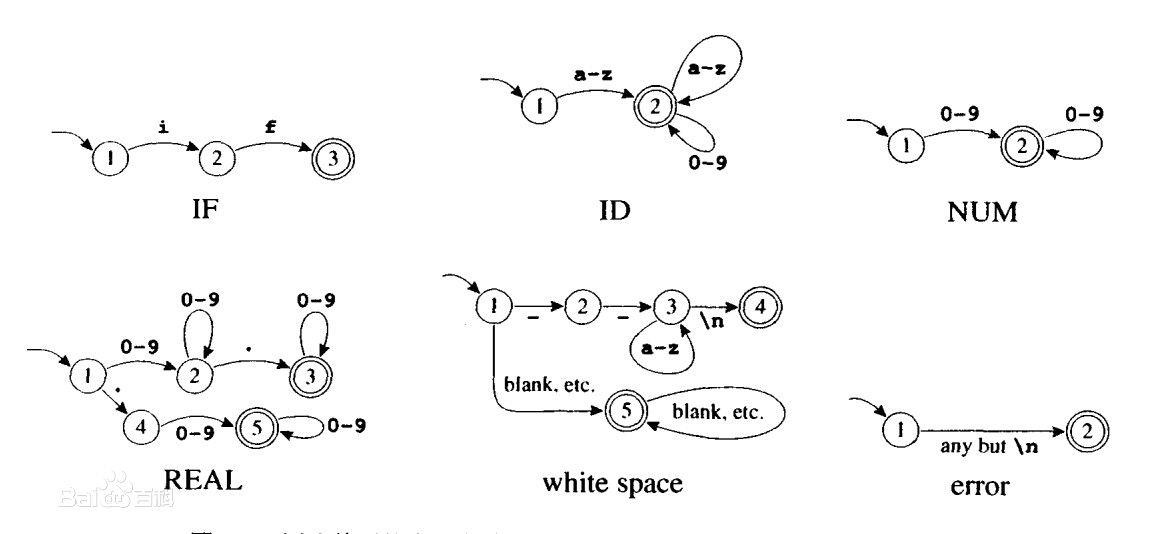
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )