Working with Channels in Goroutines
发布时间: 2023-12-16 20:09:14 阅读量: 9 订阅数: 11 
## Chapter 1: Introduction to Goroutines and Channels
### 1.1 Understanding the Basics of Goroutines
Goroutines are lightweight concurrent threads in Go that allow us to execute functions or methods concurrently. They are managed by the Go runtime and can have numerous Goroutines running simultaneously without the need for explicit thread management. Goroutines are defined using the `go` keyword and are executed asynchronously, allowing us to perform concurrent operations efficiently.
```go
func main() {
go task1() // executing task1 in a Goroutine
task2() // executing task2 in the main Goroutine
}
func task1() {
// code for task1
}
func task2() {
// code for task2
}
```
### 1.2 Understanding the Purpose and Usage of Channels
Channels are communication constructs in Go that allow Goroutines to send and receive values, enabling synchronized communication between Goroutines. Channels are used to share data and facilitate the coordination of Goroutines. They provide a safe and efficient way to exchange information between concurrent Goroutines.
### 1.3 Relationship Between Goroutines and Channels
Goroutines and Channels work together to enable concurrent programming in Go. Goroutines execute functions concurrently, and Channels provide a safe means for Goroutines to communicate with each other. By using Channels, Goroutines can send and receive data, synchronize their execution, and avoid race conditions and data races.
```go
func main() {
ch := make(chan int) // creating an integer channel
go sendData(ch) // executing sendData in a Goroutine
go receiveData(ch) // executing receiveData in another Goroutine
time.Sleep(time.Second)
}
func sendData(ch chan<- int) {
ch <- 10 // sending data to the channel
}
func receiveData(ch <-chan int) {
data := <-ch // receiving data from the channel
fmt.Println(data)
}
```
In the above code, the `sendData` Goroutine sends data to the channel `ch`, and the `receiveData` Goroutine receives the data from the same channel.
This concludes the first chapter, where we introduced the concepts of Goroutines and Channels and discussed their relationship in concurrent programming.
### 章节二:创建和使用Channels
在本章中,我们将深入讨论如何创建和使用Channels来实现并发编程。首先,我们将学习如何创建一个Channel,然后讨论如何在Goroutines之间发送和接收数据。最后,我们将介绍如何关闭和删除Channels以及一些最佳实践。让我们开始吧!
# 章节三:并发编程和并行执行
并发编程和并行执行是Goroutines和Channels的核心概念之一。在本章节中,我们将探讨如何在Goroutines中应用并发编程,以及如何使用Channels实现并行执行。
## 3.1 如何在Goroutines中运用并发编程
Goroutines是Go语言中轻量级线程的实现,可以方便地实现并发编程。通过在函数或方法前加上关键字`go`,我们可以将其转变为一个Goroutine。
下面是一个简单的例子,展示了如何在Goroutines中运用并发编程:
```go
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("开始执行主函数")
go longRunningTask()
time.Sleep(2 * time.Second)
fmt.Println("主函数执行结束")
}
func longRunningTask() {
fmt.Println("开始执行长时间运行的任务")
time.Sleep(5 * time.Second)
fmt.Println("长时间运行的任务执行结束")
}
```
在上述代码中,我们通过`go`关键字在`longRunningTask`函数前创建了一个Goroutine。该函数会执行一个长时间运行的任务,然后在完成后打印相关信息。
在`main`函数中,我们打印了开始执行主函数的信息,然后创建了一个Goroutine来执行`longRunningTask`函数。接着,使用`time.Sleep`函数等待2秒钟,以便给`longRunningTask`足够的时间来执行。最后,我们打印了主函数执行结束的信息。
运行以上代码,你会发现主函数会在2秒钟之后打印执行结束的信息,而`longRunningTask`函数会在5秒钟之后打印执行结束的信息。这说明通过在Goroutines中运用并发编程,我们可以在主函数执行的同时执行其他任务。
## 3.2 利用Channels实现并行执行
Channels是Goroutines之间进行通信和同步的重要机制。通过在Goroutines之间传递数据,我们可以实现并行执行。
下面是一个简单的例子,演示了如何利用Channels实现并行执行:
```go
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("开始执行主函数")
ch := make(chan string)
go longRunningTask(ch)
fmt.Println(<-ch)
fmt.Println("主函数执行结束")
}
func longRunningTask(ch chan string) {
fmt.Println("开始执行长时间运行的任务")
time.Sleep(5 * time.Second)
fmt.Println("长时间运行的任务执行结束")
ch <- "任务完成"
}
```
在上述代码中,我们首先创建了一个字符串类型的Channel `ch`。然后,我们在`main`函数中创建了一个Goroutine来执行`longRunningTask`函数,并将`ch`作为参数传递给该函数。
在主函数中,我们通过`<-ch`语法从Channel中接收数据,并打印出来。这样,我们就等待`longRunningTask`函数执行完成,并接收到任务完成的信息。
运行以上代码,你会发现主函数会在5秒钟之后打印任务完成的信息,然后才打印执行结束的信息。这说明通过利用Channels实现并行执行,我们可以在主函数中等待并获取其他Goroutines执行任务的结果。
## 3.3 对比并发和并行的区别和优势
在并发编程中,我们常常听到并发和并行这两个词语。虽然它们有一些相似之处,但实际上它们有一些明显的区别和各自的优势。
并发是指两个或多个任务可以在重叠的时间段内执行,这些任务之间可能是交替执行的。通过并发编程,我们可以充分利用处理器资源,提高程序的性能和响应能力。
而并行是指两个或多个任务可以同时执行,每个任务都有自己的处理器或核心。通过并行执行,我们可以进一步提高程序的执行速度。
总结起来,对比并发和并行的区别和优势如下:
- 并发适用于解决任务之间的依赖关系,提高程序的性能和响应能力;
- 并行适用于利用多核心或多处理器资源,加速程序的执行速度。
在Goroutines和Channels中,我们可以灵活地应用并发和并行的概念,从而提升我们程序的性能和效率。在实际开发中,需要根据具体的需求选择合适的方案。
当然,以下是《Working with Channels in Goroutines》文章的第四章节的内容:
### 章节四:错误处理和超时机制
在并发编程中,正确处理错误和避免死锁是至关重要的。本章将介绍如何处理Channel中的错误以及使用超时机制来避免阻塞和死锁。
#### 4.1 处理Channel中的错误
在使用Channels进行通信时,我们需要考虑可能出现的错误情况。使用Go语言的`select`语句可以很方便地处理这些情况。下面是一个示例代码,演示了如何在使用Channel发送数据时处理错误:
```go
package main
import (
"fmt"
)
func main() {
ch := make(chan int)
// 发送数据到Channel
go func() {
err := send(ch, 10)
if err != nil {
fmt.Println("Error sending data:", err)
}
}()
// 接收数据,并处理错误
data, err := receive(ch)
if err != nil {
fmt.Println("Error receiving data:", err)
} else {
fmt.Println("Received data:", data)
}
}
// 向Channel发送数据,并处理可能出现的错误
func send(ch chan<- int, data int) error {
select {
case ch <- data:
return nil
default:
return fmt.Errorf("Channel is full, unable to send data")
}
}
// 从Channel接收数据,并处理可能出现的错误
func receive(ch <-chan int) (int, error) {
select {
case data := <-ch:
return data, nil
default:
return 0, fmt.Errorf("No data available in channel")
}
}
```
在上述示例中,我们通过`select`语句对发送和接收操作进行了处理,避免了因为Channel满或空而导致的阻塞。这样可以更加灵活地处理Channel中的数据操作,并及时发现可能出现的错误。
#### 4.2 使用超时机制避免阻塞和死锁
在并发编程中,常常会遇到因为Channel操作阻塞而导致程序无法继续执行的情况。为了避免这种情况,我们可以使用超时机制来限制等待时间,避免程序陷入死锁状态。下面是一个使用超时机制的示例代码:
```go
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
// 启动一个Goroutine来接收数据
go func() {
select {
case data := <-ch:
fmt.Println("Received data:", data)
case <-time.After(3 * time.Second):
fmt.Println("Timeout: No data received")
}
}()
// 3秒后向Channel发送数据
time.Sleep(3 * time.Second)
ch <- 10
}
```
在上述示例中,我们使用`time.After`函数来实现超时机制,限制了接收数据的等待时间。这样即使没有数据到达,程序也不会一直阻塞下去,而是在超时后继续执行其他操作。
#### 4.3 如何优雅地处理超时和错误
在实际开发中,我们需要考虑如何优雅地处理超时和错误。一个常见的做法是使用`context`包来实现超时控制,并且将错误信息传播到调用者。以下是一个简单的示例代码演示了如何使用`context`来处理超时和错误:
```go
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 使用context设置超时时间为2秒
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
// 启动一个Goroutine进行工作
go doWork(ctx)
// 阻塞等待工作完成或超时
select {
case <-ctx.Done():
fmt.Println("Work canceled due to timeout or error:", ctx.Err())
}
}
// 模拟一个可能耗时的工作
func doWork(ctx context.Context) {
select {
case <-time.After(3 * time.Second): // 假设这里有一个耗时的操作
fmt.Println("Work done")
case <-ctx.Done():
fmt.Println("Work canceled due to timeout or error:", ctx.Err())
}
}
```
在这个示例中,我们使用`context`包来设置超时时间,并通过`ctx.Done()`来判断工作是否完成或者超时。这样可以更加灵活地控制并发操作,避免因为超时或错误导致的程序崩溃。
### 5. 章节五:Goroutines和Channels的最佳实践
5.1 设计良好的并发模式
5.2 避免竞争条件和数据竞争
5.3 使用WaitGroups和Mutexes管理并发
## 6. 章节六:高级用法和扩展阅读
在本章中,我们将探讨一些关于Goroutines和Channels的高级用法和推荐的扩展阅读资源。这些技巧和技术可以帮助你更好地利用Goroutines和Channels来解决复杂的并发问题。
### 6.1 利用Select语句进行多路复用
在之前的章节中,我们已经看到了如何使用Channels来进行数据的发送和接收。然而,在一些情况下,我们可能需要同时监听多个Channel,以便在其中任何一个Channel有可用数据时进行相应的处理。这时候,就可以使用`select`语句来实现多路复用。
```go
package main
import (
"fmt"
"time"
)
func worker1(ch chan string) {
time.Sleep(2 * time.Second)
ch <- "worker1 done"
}
func worker2(ch chan string) {
time.Sleep(3 * time.Second)
ch <- "worker2 done"
}
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
go worker1(ch1)
go worker2(ch2)
select {
case result := <-ch1:
fmt.Println(result)
case result := <-ch2:
fmt.Println(result)
}
}
```
在上面的示例中,我们创建了两个Worker函数,分别向两个不同的Channel发送数据。在主函数中使用`select`语句来监听这两个Channel,一旦其中任何一个Channel有数据可用,就会执行相应的操作。
### 6.2 使用Buffered Channels提高性能
默认情况下,Channels是没有缓冲区的,这意味着发送方和接收方必须同时准备好才能进行通信。然而,在某些情况下,我们希望能够在发送方将数据发送到Channel后继续执行其他操作,而不需要等待接收方。这时候,可以使用缓冲区的Channel来提高性能。
```go
package main
import "fmt"
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(<-ch)
fmt.Println(<-ch)
fmt.Println(<-ch)
}
```
在上面的示例中,我们创建了一个有3个缓冲区的Channel,可以存储3个整数。然后依次向Channel发送3个数据,然后再从Channel中读取这3个数据。由于Channel有缓冲区,发送方可以先发送数据而无需等待接收方。
### 6.3 扩展阅读:深入学习Goroutines和Channels的更多资源
- "Concurrency in Go" - Katherine Cox-Buday
- "Go in Action" - William Kennedy, Brian Ketelsen, Erik St. Martin
- "The Go Programming Language" - Alan A.A. Donovan, Brian W. Kernighan
以上是一些值得深入学习和阅读的关于Goroutines和Channels的书籍,在这些资源中你可以找到更多关于并发编程的内容和实践经验。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
goroutines是一种在Go语言中实现并发编程的重要方式,本专栏围绕goroutines展开了一系列的文章,涵盖了从基础概念到高级应用的方方面面。首先,读者将通过《Understanding the Basics of Goroutines in Go》了解到goroutines的基本概念和使用方法。随后,文章《Working with Channels in Goroutines》深入探讨了goroutines中的通道使用。此外,还详细介绍了《Error Handling in Goroutines: Best Practices》、《Synchronization in Goroutines and the Use of Mutexes》、《Goroutines: Race Conditions and How to Avoid Them》等多篇文章,帮助读者更好地理解和应用goroutines。同时,专栏还涵盖了一些高级主题,如《Fine-Grained Parallelism with Goroutines》、《Goroutines: Working with Timers and Tickers》等,使读者能够深入了解goroutines的并发和并行特性。除此之外,《Goroutines: Handling Graceful Shutdowns》等文章还介绍了在goroutines中处理优雅关闭的方法。总之,本专栏内容丰富,涵盖了goroutines在Go语言中的各种应用场景,为读者提供了全面的学习和参考资料。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】通过强化学习优化能源管理系统实战
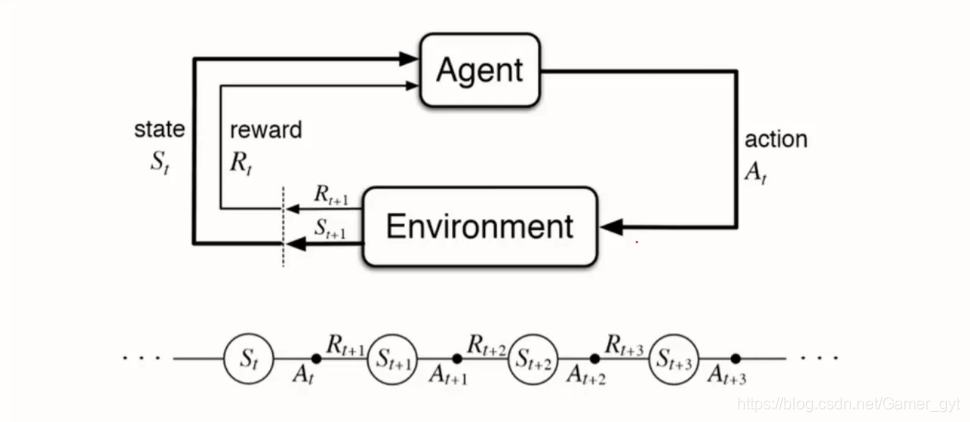
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】python云数据库部署:从选择到实施
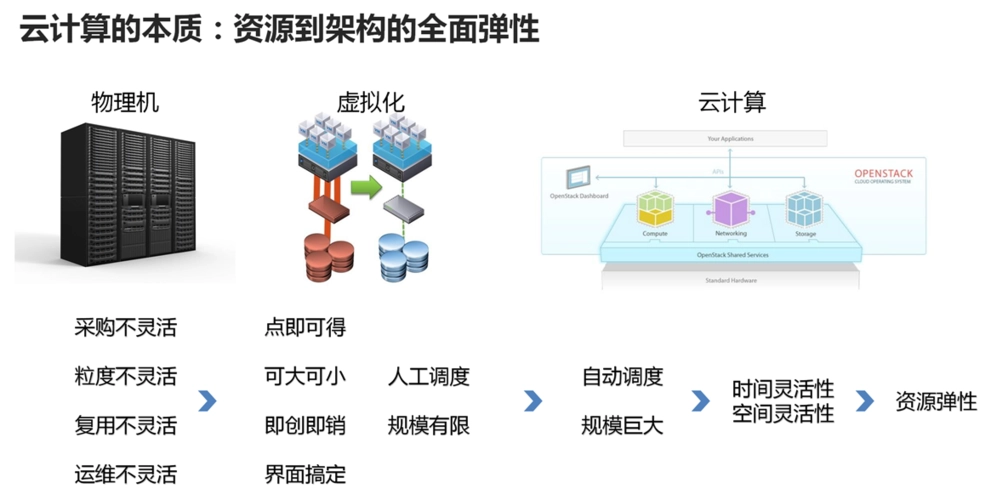
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】使用Docker与Kubernetes进行容器化管理
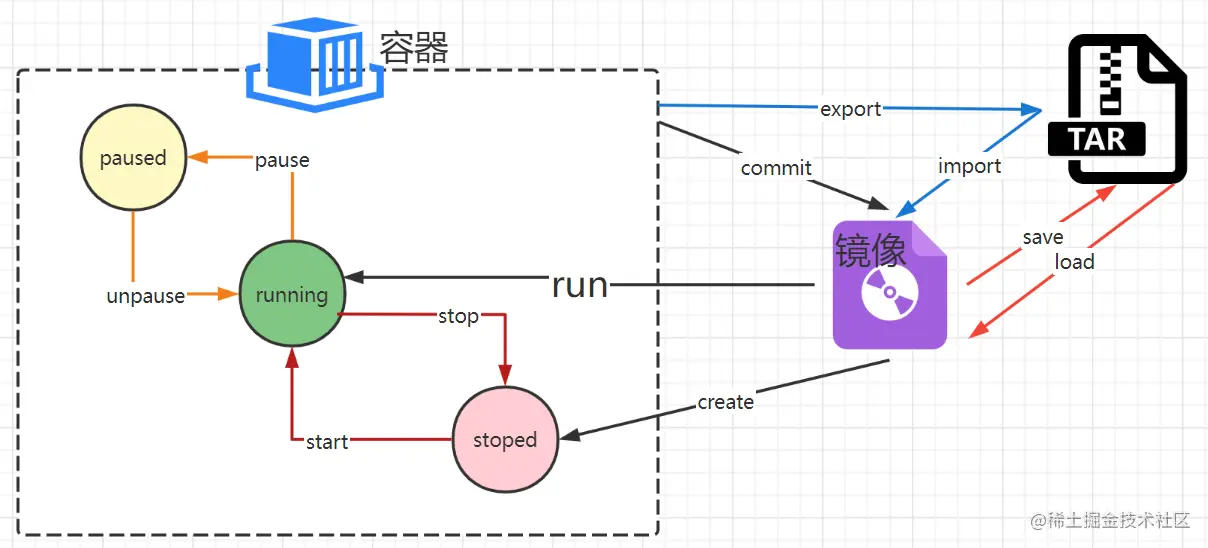
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )