【Spring文件处理秘籍】:掌握org.springframework.util.FileCopyUtils的10大高级技巧
发布时间: 2024-09-27 04:19:49 阅读量: 155 订阅数: 36 
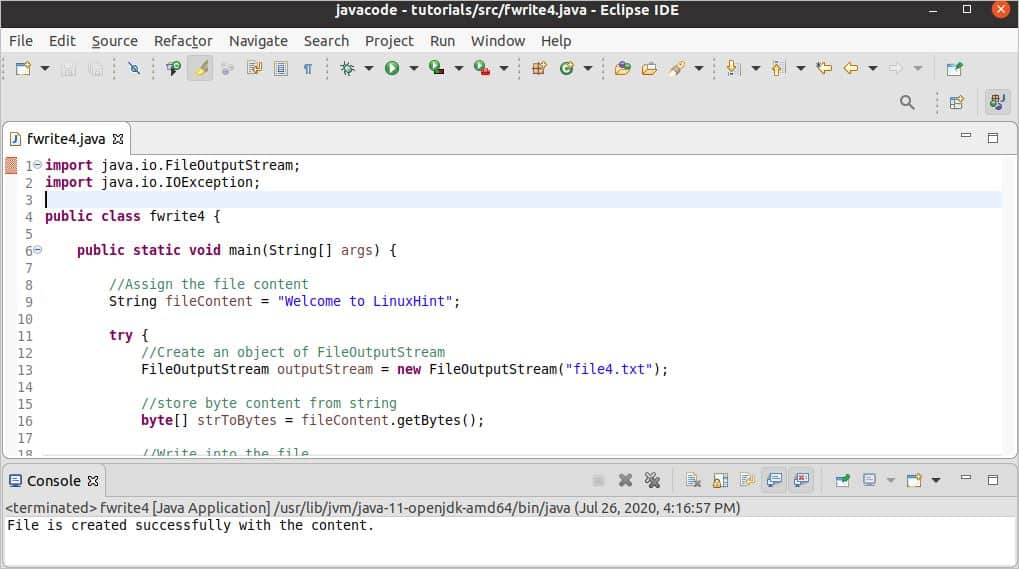
# 1. Spring框架中的文件处理概述
在现代企业级应用开发中,文件处理是一项基本而重要的功能。Spring框架作为Java开发中不可或缺的一部分,通过其丰富的生态支持,提供了一系列工具和模块来简化文件操作。Spring Framework的文件处理功能覆盖了从简单的文件读写到复杂的文件传输、批处理等场景,其核心组件FileCopyUtils就是这些功能的典型代表。本章旨在简要介绍Spring框架中文件处理的基础知识,为深入探索FileCopyUtils打下基础。接下来的章节将详细讨论FileCopyUtils的使用技巧、高级功能以及实际应用案例。让我们从概述开始,逐步深入Spring框架中的文件处理世界。
# 2. FileCopyUtils的基础使用技巧
在上一章中,我们对Spring框架中的文件处理有了一个大致的了解。接下来,我们将深入探讨FileCopyUtils这个强大的工具,它在文件操作中扮演着非常重要的角色。我们将从其基本功能与优势开始,逐步深入了解文件复制、移动与重命名的高级应用。
## 2.1 FileCopyUtils的基本功能与优势
### 2.1.1 理解FileCopyUtils的角色
`FileCopyUtils` 是一个在Spring框架中广泛使用的类,用于简化文件的复制操作。它提供了一种高级抽象,可以隐藏底层流处理的复杂性,使开发者能以声明式的方式进行文件操作。利用 `FileCopyUtils`,可以轻松地将输入流复制到输出流,或者复制一个文件到另一个文件。
该工具的引入主要是为了提升代码的可读性和易用性,它封装了许多处理文件流的细节,比如流的打开、关闭以及异常处理,从而降低了文件处理的难度。
### 2.1.2 FileCopyUtils与传统IO的对比
传统的文件操作通常涉及繁琐的 `InputStream` 和 `OutputStream` 使用,包括正确管理这些资源的开启与关闭。这种模式容易造成资源泄露,且代码不易阅读和维护。下面是使用传统IO与使用 `FileCopyUtils` 的对比示例:
**传统IO的文件复制代码:**
```java
try (InputStream inputStream = new FileInputStream(sourceFile);
OutputStream outputStream = new FileOutputStream(targetFile)) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
```
**使用FileCopyUtils的文件复制代码:**
```java
FileCopyUtils.copy(new FileInputStream(sourceFile), new FileOutputStream(targetFile));
```
通过对比,我们可以看出 `FileCopyUtils` 的简洁性。它将复制操作简化为一个方法调用,内部自动处理了缓冲区的分配和资源的关闭,极大提高了编码效率和代码的可维护性。
## 2.2 文件复制的基本操作
### 2.2.1 单文件复制的实践方法
为了更深入理解 `FileCopyUtils` 如何使用,我们可以先从单个文件的复制操作开始。`FileCopyUtils` 提供了一个 `copy` 静态方法,接受一个输入流并将其内容复制到输出流。下面的代码展示了如何复制一个文件到另一个位置:
```java
import org.springframework.util.FileCopyUtils;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyExample {
public static void copyFile(String sourcePath, String targetPath) {
FileCopyUtils.copy(new FileInputStream(sourcePath), new FileOutputStream(targetPath));
}
}
```
上述代码中,`FileCopyUtils.copy` 接受两个参数:一个是源文件的 `InputStream`,另一个是目标文件的 `OutputStream`。`FileCopyUtils` 自动处理了流的关闭,因此不需要再显式调用 `close` 方法。
### 2.2.2 多文件复制与批处理技巧
`FileCopyUtils` 同样支持复制多个文件的场景。在这种情况下,可能需要执行批处理操作,以提高处理的效率。以下是一个批量复制文件的方法,该方法接受源文件夹路径和目标文件夹路径作为参数:
```java
public static void copyFilesBatch(String sourceDirectory, String targetDirectory) {
File sourceDir = new File(sourceDirectory);
File targetDir = new File(targetDirectory);
// 确保目标目录存在
targetDir.mkdirs();
// 复制文件
File[] files = sourceDir.listFiles();
for (File source*** {
if (sourceFile.isFile()) {
String targetFilePath = targetDir + File.separator + sourceFile.getName();
copyFile(sourceFile.getAbsolutePath(), targetFilePath);
}
}
}
```
在上述方法中,我们使用 `File.list()` 方法遍历源文件夹中的所有文件,并逐个进行复制。这样我们就可以利用 `FileCopyUtils.copy` 方法的简洁性,简化批量文件复制的操作。
## 2.3 文件移动与重命名的高级应用
### 2.3.1 文件重命名的策略与实现
文件重命名是文件系统操作中常见的需求,可以通过 `File.renameTo()` 方法实现,但有时候需要在重命名之前进行一系列检查以确保操作的可行性。借助 `FileCopyUtils`,我们可以更便捷地实现复杂的重命名逻辑。
以下是一个简单的重命名方法示例,该方法检查目标文件名是否存在,并执行重命名操作:
```java
public static boolean renameFile(String originalPath, String newPath) {
File originalFile = new File(originalPath);
File newFile = new File(newPath);
// 检查目标文件是否存在
if (newFile.exists()) {
// 如果目标文件已存在,则不执行重命名操作
return false;
}
return originalFile.renameTo(newFile);
}
```
### 2.3.2 文件移动的最佳实践
文件移动通常涉及到文件的删除和重命名操作。在使用 `FileCopyUtils` 时,我们可以通过结合文件复制和文件删除来实现文件移动。以下是一个移动文件的方法:
```java
public static void moveFile(String sourcePath, String targetPath) {
File sourceFile = new File(sourcePath);
File targetFile = new File(targetPath);
if (sourceFile.renameTo(targetFile)) {
System.out.println("File moved successfully!");
} else {
System.out.println("File move failed!");
}
}
```
在上述代码中,我们调用了 `File.renameTo()` 方法尝试直接移动文件。如果文件无法直接移动(例如,目标路径位于不同的文件系统),则可能需要通过复制和删除原文件的方式实现移动。
至此,我们已经对 `FileCopyUtils` 的基本使用技巧有了一定的了解。在下一章中,我们将深入探索其高级功能,包括资源流的处理和转换、文件操作的并发处理以及实用工具方法。
# 3. 深入探索FileCopyUtils的高级功能
## 3.1 资源流的处理和转换
在文件处理和管理中,流(Stream)是一种重要的抽象,它允许程序以顺序的方式读取或写入数据到目标源。Spring的`FileCopyUtils`提供了处理流的高级功能,能够简化复制和转换操作。
### 3.1.1 流的复制与转换
使用`FileCopyUtils`进行流的复制与转换是一种高效的数据处理方式,尤其在处理大文件时。它内部实现了`InputStream`到`OutputStream`的复制机制,并允许开发者在此基础上进行数据格式转换。
```java
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
import org.springframework.util.FileCopyUtils;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class StreamCopyExample {
public static void main(String[] args) {
try {
Resource sourceResource = new UrlResource("***");
Resource targetResource = new UrlResource("***");
try (InputStream input = sourceResource.getInputStream();
OutputStream output = targetResource.getOutputStream()) {
FileCopyUtils.copy(input, output);
System.out.println("Stream copied successfully.");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
在上述代码中,我们使用了`FileCopyUtils.copy`方法,将一个资源的输入流复制到另一个资源的输出流。该方法支持基本的数据复制,并且可以扩展以支持数据转换,只需提供自定义的转换器(`Transformer`)即可。
### 3.1.2 资源管理与异常处理
`FileCopyUtils`在处理流时,会进行资源管理,确保输入输出流在操作完成后被正确关闭,即使在发生异常的情况下。这可以通过在`try`语句块中使用资源关闭机制来实现,如上面的示例所示。另外,`FileCopyUtils`还提供了异常处理机制,能够捕获并处理`IOException`,进一步提高代码的健壮性。
```java
import org.springframework.util.FileCopyUtils;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class StreamCopyExceptionHandling {
public static void main(String[] args) {
try {
InputStream input = null;
OutputStream output = null;
try {
// Initialize your input and output streams
// ...
FileCopyUtils.copy(input, output);
} finally {
// Ensure both streams are closed to prevent resource leaks
FileCopyUtils.closeQuietly(input);
FileCopyUtils.closeQuietly(output);
}
} catch (IOException e) {
// Handle exceptions related to input or output streams
e.printStackTrace();
}
}
}
```
### 3.2 文件操作的并发处理
并发处理是高级文件操作中的一个重要方面,尤其是在服务器和云服务环境中,文件复制、移动等操作经常需要在后台进行,以便不影响前台用户的体验。
### 3.2.1 并发文件复制的性能优势
当需要复制大量文件时,传统的单线程复制方式可能会导致性能瓶颈。使用并发处理可以显著提升文件操作的效率。
```java
import org.springframework.util.FileCopyUtils;
import java.io.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ConcurrentFileCopyExample {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
File sourceDir = new File("/path/to/source");
File targetDir = new File("/path/to/target");
File[] files = sourceDir.listFiles();
if (files != null) {
for (File *** {
executorService.submit(() -> {
try {
File sourceFile = new File(sourceDir, file.getName());
File targetFile = new File(targetDir, file.getName());
FileCopyUtils.copy(sourceFile, targetFile);
System.out.println("Copied file: " + file.getName());
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
executorService.shutdown();
}
}
```
在这个示例中,我们创建了一个固定大小的线程池,并且为源目录中的每个文件创建了一个任务提交到线程池中执行。这样可以同时处理多个文件,提高了程序的性能。
### 3.2.2 线程安全与并发控制
并发文件操作虽然可以提高效率,但也带来了线程安全的问题。例如,如果两个线程同时尝试写入同一个文件,可能会导致数据损坏。为了确保线程安全,可能需要引入文件锁机制或其他同步机制来管理并发控制。
## 3.3 文件处理的实用工具方法
`FileCopyUtils`提供了一些实用的工具方法,用于检查文件存在性、类型、大小、内容摘要等,这些方法可以简化开发过程中对文件属性的检查工作。
### 3.3.1 检查文件存在性和类型的方法
通过`FileCopyUtils`中的工具方法,可以快速检查文件是否存在,以及文件的类型。这通常在准备文件操作之前需要进行的检查。
```java
import org.springframework.util.FileCopyUtils;
public class FileUtilsCheck {
public static void main(String[] args) {
File file = new File("/path/to/file.txt");
// 检查文件是否存在
if (FileCopyUtils.exists(file)) {
System.out.println("File exists.");
} else {
System.out.println("File does not exist.");
}
// 检查文件类型是否为文本
if (FileCopyUtils.isText(file)) {
System.out.println("File is of type text.");
} else {
System.out.println("File is not of type text.");
}
}
}
```
### 3.3.2 文件大小和内容摘要的获取
在某些应用中,如文件上传下载服务,需要预先获取文件的大小和内容摘要以进行验证或显示给用户。`FileCopyUtils`提供了快速获取这些信息的工具方法。
```java
import org.springframework.util.FileCopyUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Base64;
public class FileMetadataExample {
public static void main(String[] args) {
File file = new File("/path/to/file.txt");
try (FileInputStream input = new FileInputStream(file)) {
// 获取文件大小
long fileSize = FileCopyUtils.copyToByteArray(input).length;
System.out.println("File size in bytes: " + fileSize);
// 获取文件内容摘要(以Base64编码)
byte[] digest = ***puteChecksum(input);
String checksum = Base64.getEncoder().encodeToString(digest);
System.out.println("File checksum in Base64: " + checksum);
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
在该示例中,我们使用`***puteChecksum`方法来获取文件的摘要信息。这个方法会读取整个文件的内容,并返回一个字节数组,表示文件的摘要信息。然后我们使用`Base64`编码将摘要信息转换为字符串格式。
> **注意**:在处理大量文件或大型文件时,需要注意内存和性能问题。使用流式处理和分批处理可以有效减少内存消耗,并提升性能。在某些情况下,也可以考虑使用Spring的异步编程模型来进一步优化性能。
以上是对`FileCopyUtils`高级功能深入探索的介绍。这些功能能够帮助开发者以更有效的方式进行文件操作,无论是在Web应用还是在企业级应用中。在下一节中,我们将探讨`FileCopyUtils`在实际应用案例中的实践应用。
# 4. FileCopyUtils的实践应用案例
## 4.1 构建文件上传下载服务
### 4.1.1 文件上传的实现机制
构建一个文件上传服务是一个常见的Web应用需求,使用Spring框架的`MultipartFile`接口可以轻松地实现这一功能。以下是构建一个基本的文件上传服务的步骤和关键代码。
首先,需要在Spring Boot应用中创建一个控制器来处理文件上传请求。可以使用`@RestController`和`@PostMapping`注解来定义一个控制器方法,用于处理文件上传。
```java
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
@RestController
public class FileUploadController {
@PostMapping("/upload")
public String handleFileUpload(@RequestParam("file") MultipartFile file) {
if (file.isEmpty()) {
return "File is empty.";
}
try {
// Get the file name and store the file
String fileName = file.getOriginalFilename();
File uploadDir = new File("uploads/");
if (!uploadDir.exists()) {
uploadDir.mkdirs();
}
File uploadedFile = new File(uploadDir, fileName);
file.transferTo(uploadedFile);
} catch (IOException e) {
return "Could not save the file: " + e.getMessage();
}
return "File uploaded successfully: " + file.getOriginalFilename();
}
}
```
在这个例子中,`handleFileUpload`方法会检查上传的文件是否为空,然后创建必要的目录结构以存储文件,并最终将文件保存在服务器的`uploads`目录下。`MultipartFile`接口的`transferTo`方法用于将上传的文件移动到服务器上的指定位置。
### 4.1.2 文件下载的安全策略
文件下载服务需要考虑数据传输的安全性,特别是当传输敏感信息时。实现安全文件下载的一种常见做法是使用Spring Security来验证用户权限,并提供对文件的限制访问。
以下是一个基于Spring Security实现的文件下载服务的安全控制示例:
```java
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
@RestController
public class FileDownloadController {
@GetMapping("/download/{fileName:.+}")
public void downloadFile(@PathVariable String fileName, HttpServletResponse response) {
// Security check
if (!(SecurityContextHolder.getContext().getAuthentication().isAuthenticated())) {
throw new RuntimeException("You must be logged in to download a file.");
}
// Load the file
File file = new File("uploads/" + fileName);
if (!file.exists()) {
throw new RuntimeException("File does not exist.");
}
// Set content type header
response.setContentType("application/octet-stream");
response.setHeader("Content-Disposition", "attachment; filename=\"" + fileName + "\"");
// Write bytes of the file to the response output stream
try {
Files.copy(***ath(), response.getOutputStream());
response.flushBuffer();
} catch (IOException e) {
throw new RuntimeException("IO Error when reading file", e);
}
}
}
```
在这个控制器中,`downloadFile`方法首先进行了安全检查,确认用户已经通过Spring Security认证。如果用户认证成功,文件会被读取并写入到HTTP响应输出流中,浏览器会提示用户保存文件。
### 4.2 文件处理在缓存中的应用
#### 4.2.1 缓存文件的有效管理
缓存文件可以提高应用程序的性能,减少对原始数据存储的读取次数。Spring框架提供了一种方便的方式来集成和管理缓存,使用`@Cacheable`等注解可以轻松地实现方法级别的缓存。
以下是如何在服务层应用缓存管理的一个例子:
```java
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
@Service
public class FileCacheService {
@Cacheable("fileCache")
public byte[] getFileData(String fileName) {
// 模拟一个文件数据的获取,实际应用中是从文件系统或其他存储中读取
return new byte[0]; // 示例中返回空数组,实际应返回文件数据
}
}
```
在这个例子中,`getFileData`方法被`@Cacheable`注解标记,意味着该方法的返回值将被缓存起来,以`fileCache`为缓存名称。当再次调用此方法并传入相同的`fileName`时,Spring将返回缓存中的数据而不是重新调用方法。
#### 4.2.2 缓存与文件同步的问题解决
缓存文件数据时,需要确保文件的更新能够及时同步到缓存中。Spring框架的缓存抽象提供了`@CachePut`和`@CacheEvict`注解来更新和清除缓存。
```java
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.CacheEvict;
@Service
public class FileCacheService {
@CachePut(value = "fileCache", key = "#fileName")
public byte[] updateFileData(String fileName) {
// 更新文件数据的逻辑
return new byte[0]; // 示例中返回空数组,实际应返回新的文件数据
}
@CacheEvict(value = "fileCache", key = "#fileName")
public void deleteFileData(String fileName) {
// 删除文件数据的逻辑
}
}
```
在`updateFileData`方法上应用了`@CachePut`注解,这表示每次调用该方法都会更新缓存中的对应数据。而`deleteFileData`方法则使用了`@CacheEvict`注解,用于从缓存中删除指定的文件数据。
### 4.3 文件处理在日志系统中的应用
#### 4.3.1 日志文件的管理与归档
日志文件是任何系统都不可或缺的一部分,它们记录了系统运行时的详细信息。在Spring框架中,可以利用`logging.file.name`和`logging.file.path`属性来配置日志文件的位置。更高级的做法是实现日志轮转,以便自动归档旧的日志文件。
以下是一个使用Logback实现日志轮转的配置示例:
```xml
<configuration>
<property name="LOGS" value="./logs" />
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOGS}/application.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOGS}/archived/application.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="FILE" />
</root>
</configuration>
```
这个配置文件定义了一个文件日志记录器,它使用时间基于的滚动策略来自动归档旧的日志文件。`maxHistory`定义了保留多少天的历史日志文件,而`totalSizeCap`则限制了归档文件的总大小。
#### 4.3.2 日志文件的分析和优化
日志文件的分析是系统维护的重要部分。分析日志可以帮助识别性能瓶颈、错误和安全问题。可以使用专门的日志分析工具,如ELK Stack(Elasticsearch, Logstash, Kibana),对日志数据进行收集、分析和可视化。
为了收集日志数据,可以在Spring应用中集成Logstash,通过配置Logback或Log4j使用`FileAppender`来将日志写入一个文件,然后让Logstash来处理该文件。
以下是一个简单的Logback配置示例,用于输出日志到文件,并通过Logstash进行处理:
```xml
<configuration>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="FILE" />
</root>
</configuration>
```
接下来,配置Logstash以读取这个日志文件并输出到Elasticsearch,其配置文件`logstash.conf`可能如下所示:
```conf
input {
file {
path => "/path/to/logs/app.log"
type => "application_logs"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPachelog}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
```
这样配置之后,Logstash会定期检查`app.log`文件,将日志数据格式化并存储到Elasticsearch中,Kibana可以用来查询和展示这些数据。通过这些工具的组合使用,可以有效地监控和分析Spring应用的日志数据。
## 代码块与逻辑分析
### 日志文件管理与归档配置
```xml
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOGS}/application.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOGS}/archived/application.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
</appender>
```
- `<appender>`标签定义了一个新的日志输出器。
- `<file>`标签指定了日志文件的初始位置。
- `<rollingPolicy>`标签配置了日志滚动策略,基于时间进行。
- `<fileNamePattern>`标签定义了文件名格式,包括归档文件名。
- `<maxHistory>`标签指定了保留历史日志的天数。
- `<totalSizeCap>`限制了归档文件的总大小。
### 日志文件分析配置
```conf
input {
file {
path => "/path/to/logs/app.log"
type => "application_logs"
start_position => "beginning"
}
}
```
- `input.file.path`指定了需要Logstash读取的日志文件路径。
- `type`指定了日志的类型,用于在后续处理中引用。
- `start_position`设置为`beginning`表示从文件的开始位置读取日志。
### 文件上传控制器实现
```java
@PostMapping("/upload")
public String handleFileUpload(@RequestParam("file") MultipartFile file) {
// 代码逻辑省略...
}
```
- `@PostMapping("/upload")`定义了处理文件上传的端点。
- `@RequestParam("file")`注解用来绑定`MultipartFile`类型的参数,Spring自动处理上传的文件。
- `file.transferTo(uploadedFile)`方法把上传的文件复制到服务器文件系统上。
### 文件下载控制器实现
```java
@GetMapping("/download/{fileName:.+}")
public void downloadFile(@PathVariable String fileName, HttpServletResponse response) {
// 代码逻辑省略...
}
```
- `@GetMapping("/download/{fileName:.+}")`定义了处理文件下载的端点。
- `@PathVariable String fileName`注解用来绑定URL中指定的文件名。
- `response.setHeader`方法用来设置HTTP响应头,`Content-Disposition`表示这是个附件,`filename`定义了附件的文件名。
### 缓存控制器实现
```java
@Cacheable("fileCache")
public byte[] getFileData(String fileName) {
// 代码逻辑省略...
}
```
- `@Cacheable("fileCache")`注解表示该方法的返回值将被缓存,缓存名称为`fileCache`。
- 如果方法被多次调用,并且参数相同,则Spring将直接从缓存中返回值,而不是执行方法体内的逻辑。
通过这些配置和代码示例,我们展示了如何在Spring框架中实现文件上传下载服务、缓存管理和日志分析等应用场景。这些功能对于构建高效、可维护的应用系统至关重要。
# 5. FileCopyUtils性能优化与故障排除
## 5.1 性能调优技巧
### 5.1.1 缓冲区大小调整
当使用`FileCopyUtils`进行文件操作时,其性能会受到缓冲区大小的影响。合理地调整缓冲区大小可以显著提高文件复制和移动的效率。为了达到最佳性能,通常需要根据文件的大小和系统的I/O性能进行调整。
假设我们有如下一个场景,需要复制一个大小为1GB的文件,我们将探讨如何调整缓冲区大小来优化性能:
```java
public void copyFileWithBuffer(File sourceFile, File destFile, int bufferSize) throws IOException {
try (FileInputStream in = new FileInputStream(sourceFile);
FileOutputStream out = new FileOutputStream(destFile)) {
byte[] buffer = new byte[bufferSize];
int n;
while ((n = in.read(buffer)) > 0) {
out.write(buffer, 0, n);
}
}
}
```
在这个例子中,`bufferSize`是我们可以控制的参数。理论上,更大的缓冲区意味着更少的系统调用次数,因为单次读写操作涉及的数据量更大。但是,过大的缓冲区也可能导致内存使用不经济,特别是在处理多个大型文件时。因此,需要在测试的基础上找到一个平衡点。
### 5.1.2 异步处理与I/O性能
异步处理可以显著提高应用程序的响应性和吞吐量,尤其当涉及到文件操作时。异步I/O允许应用程序在等待I/O操作完成时继续执行其他任务,从而有效地利用系统资源。
在Java中,我们可以使用`CompletableFuture`来实现异步文件操作:
```java
public CompletableFuture<Void> asyncCopyFile(File sourceFile, File destFile) {
return CompletableFuture.runAsync(() -> {
try {
Files.copy(***ath(), ***ath(), StandardCopyOption.REPLACE_EXISTING);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
});
}
```
在这个例子中,`asyncCopyFile`方法将文件复制任务提交给一个异步执行器,并立即返回一个`CompletableFuture`对象。使用异步处理时,需要特别注意异常处理和资源管理,以避免资源泄漏。
## 5.2 常见问题诊断与解决方案
### 5.2.1 文件访问权限问题
在处理文件时,访问权限问题是一个常见问题。如果程序没有足够的权限去读写某个文件,这将导致运行时异常。
对于权限问题,首先需要检查运行程序的用户权限,确保其有对目标文件的操作权限。在Java中,我们可以捕获`AccessDeniedException`异常,并给出具体的权限提示:
```java
try {
Files.copy(***ath(), ***ath(), StandardCopyOption.REPLACE_EXISTING);
} catch (AccessDeniedException e) {
System.out.println("Access Denied: " + e.getMessage());
}
```
在调试权限问题时,可以使用操作系统提供的工具来检查和修改文件权限,例如在Linux系统中可以使用`chmod`和`chown`命令。
### 5.2.2 文件读写异常处理
文件读写操作过程中可能会遇到多种异常,包括但不限于`FileNotFoundException`、`IOException`等。因此,为这些操作提供健壮的异常处理机制是非常重要的。
在异常处理中,应当:
1. 捕获特定的异常而不是笼统地捕获`Exception`。
2. 提供有意义的错误信息,帮助用户或系统管理员定位问题。
3. 根据异常类型采取不同的处理策略,如重试、备份或记录日志。
一个简单的异常处理示例如下:
```java
try {
// 文件操作代码
} catch (FileNotFoundException e) {
System.out.println("File Not Found: " + e.getMessage());
// 可能的处理方式:记录日志、通知用户等
} catch (IOException e) {
System.out.println("I/O Error: " + e.getMessage());
// 可能的处理方式:尝试重试、清理资源等
}
```
异常处理是程序健壮性的关键部分,正确的异常处理能够显著提高系统的可靠性和用户体验。
以上就是关于`FileCopyUtils`性能优化与故障排除的深入探讨。通过对缓冲区大小的调整和异步处理的实施,可以有效地提升应用程序的文件操作性能。同时,对于常见的文件访问权限问题和文件读写异常,正确的诊断和处理策略是保证系统稳定运行的基础。接下来,我们将进入第六章,探索`FileCopyUtils`的未来展望和最佳实践。
# 6. FileCopyUtils的未来展望和最佳实践
随着Spring框架的不断更新与发展,FileCopyUtils作为其重要的组成部分也在不断地进化。本章节将带领大家一探FileCopyUtils未来的发展趋势,并提供一些文件处理的最佳实践。
## 6.1 探索Spring新版本中的文件处理改进
Spring框架的新版本总是会带来一些激动人心的改进。针对文件处理,Spring一直致力于简化操作,提升性能,并增强安全机制。
- **API的现代化**:随着Java语言的演进,FileCopyUtils也在不断地进行API的现代化,使代码更加简洁、易读。
- **性能优化**:新版本的Spring往往会引入更加高效的I/O处理方式,比如NIO2的支持,以减少不必要的资源消耗。
- **安全性增强**:为了保护文件操作的安全性,Spring可能会增加更多细粒度的访问控制和验证机制。
在实际使用中,开发者应保持对Spring更新的关注,并尝试将新版本中的改进应用到项目中,以获得最佳的开发体验和系统性能。
## 6.2 高级文件处理策略的设计与实现
在大规模的文件处理中,我们通常需要考虑如下高级策略:
- **分块处理**:当处理大文件时,采用分块处理可以有效减少内存的使用,并提升处理速度。Spring通过流式处理支持了这一策略,允许开发者在读写文件时逐块进行。
- **资源池技术**:为了提高资源利用率,可以使用资源池技术。Spring的`ResourceLoader`抽象允许开发者通过特定的协议来实现自定义的资源加载策略。
- **异步处理**:对于耗时的文件操作,使用异步处理可以显著提升应用的响应能力。Spring提供了`@Async`注解以及`AsyncTaskExecutor`接口来帮助开发者轻松实现异步文件处理。
## 6.3 文件处理的最佳实践指南
为了最大化FileCopyUtils的使用效果,以下是一些最佳实践建议:
- **合理的资源管理**:合理分配资源并进行有效的异常处理是提高文件处理效率的关键。应利用Spring提供的资源管理工具来确保资源正确关闭,避免资源泄漏。
- **并发控制**:在多线程环境下,使用合适的并发控制机制可以提高文件处理的效率。例如,使用`ReentrantLock`或`Semaphore`等来控制并发访问。
- **日志与监控**:实现文件处理的监控机制,并记录详细的操作日志,可以方便问题的追踪和性能的分析。
在操作层面,一些具体的实践步骤可能包括:
1. 对于大型文件的处理,考虑使用流式API来逐块读写文件。
2. 实现文件操作的缓存机制,以减少对磁盘的重复读写。
3. 对于涉及大量文件的操作,考虑使用批处理模式来优化性能。
4. 利用Spring的事务管理功能来保证文件操作的原子性。
通过这些实践,我们可以确保文件处理既高效又稳定。下面是一个使用FileCopyUtils进行文件处理的简单代码示例:
```java
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.util.FileCopyUtils;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class FileUtilExample {
public static void copyFile(String source, String destination) throws IOException {
Resource resource = new PathMatchingResourcePatternResolver().getResource(source);
try (InputStream inputStream = resource.getInputStream();
OutputStream outputStream = new java.io.FileOutputStream(destination)) {
FileCopyUtils.copy(inputStream, outputStream);
}
}
}
```
在这个例子中,我们使用了`PathMatchingResourcePatternResolver`来获取资源,并使用`FileCopyUtils`来执行文件的复制操作。通过这种方式,Spring框架为我们抽象了底层的资源访问和文件操作细节。
在下一章节,我们将探讨在Spring框架中使用文件压缩和解压缩的方法,以及如何处理各种文件格式和编码,为你的应用增加更多的灵活性和功能性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到专栏“org.springframework.util.FileCopyUtils介绍与使用”,该专栏将深入探讨Spring框架中用于文件处理的强大工具FileCopyUtils。通过一系列深入的文章,您将掌握FileCopyUtils的10大高级技巧,了解其在高性能文件操作中的关键作用,并发现如何使用它简化文件操作流程。专栏还将剖析FileCopyUtils的源码,揭示其性能优化技巧,并将其与其他工具进行对比分析。此外,您将深入了解FileCopyUtils在提高代码可读性、Spring框架中的核心地位和实际开发中的多样化应用方面的作用。本专栏适合所有希望提升其文件处理技能的Java开发人员,无论是Spring新手还是经验丰富的专业人士。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【高级工具手册】SIMCA-P 11.0版分析功能全掌握:一册在手,分析无忧
# 摘要
本文针对SIMCA-P 11.0版软件进行了全面的介绍与分析,涵盖了基础分析功能、高级分析技巧以及该软件在不同行业中的应用案例。文章首先概述了SIMCA-P 11.0的总体功能,然后详细阐释了其在数据导入、预处理、基本统计分析、假设检验等方面的详细操作。在高级分析技巧部分,本文重点讲解了多变量数据分析、聚类分析、预测模型构建等高级功能。此外,文章还探讨了SIMCA-P在化工质量控制与生物医
数据管理高手:使用Agilent 3070 BT-BASIC提升测试准确度

# 摘要
Agilent 3070 BT-BASIC测试系统是电子行业广泛使用的自动测试设备(ATE),它通过集成先进的测试理论和编程技术,实现高效率和高准确度的电路板测试。本文首先概述了Agilent 3070 BT-BASIC的测试原理和基本组件,随后深入分析其编程基础、测试准确度的关键理论以及提升测试效率的高级技巧。通过介绍实践应用和进阶技巧,本文意在为电子工程师提供一个全面的指导,以优化数据管理、构建自动化测
【Eclipse项目导入:终极解决方案】
# 摘要
Eclipse作为一个流行的集成开发环境(IDE),在项目导入过程中可能会遇到多种问题和挑战。本文旨在为用户提供一个全面的Eclipse项目导入指南,涵盖从理论基础到实际操作的各个方面。通过深入分析工作空间与项目结构、导入前的准备工作、以及导入流程中的关键步骤,本文详细介绍了如何高效地导入各种类型的项目,包括Maven和Gradle项目以及多模块依赖项目。同时,为提高项目导入效率,提供了自动化导入技巧、项目
掌握TetraMax脚本编写:简化测试流程的专业技巧揭秘

# 摘要
TetraMax脚本作为一种自动化测试工具,广泛应用于软件开发的测试阶段。本文从基础到高级应用逐步解析TetraMax脚本编写的核心概念、结构、语法、命令、变量、函数、数据结构以及测试技巧和优化方法。进一步探讨了脚本的实战技巧,包括测试环境搭建
【摄像头模组调试速成】:OV5640 MIPI接口故障快速诊断与解决指南
# 摘要
本文主要介绍了OV5640摄像头模组的技术细节、MIPI接口技术基础、常见故障分析与解决方法、以及高级调试技术。文章首先概述了OV5640摄像头模组,并详细解析了其MIPI接口技术,包括接口标准、DSI协议的深入理解以及调试工具和方法。接着,针对OV5640摄像头模组可能出现的故障类型进行了分析,并提出了故障诊断流程和解决实例。第四章通过介绍初始化、
反模糊化的商业策略:如何通过自动化提升企业效益
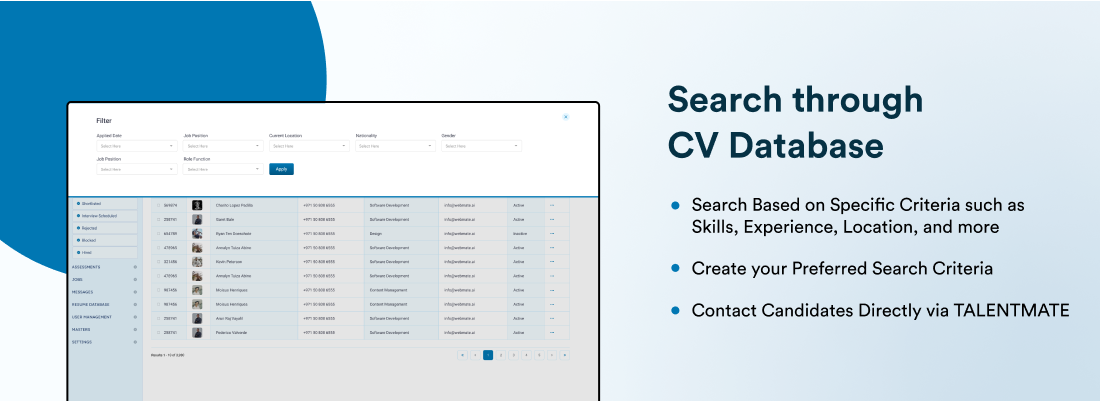
# 摘要
随着工业4.0的推进,自动化技术已成为企业提升效率、增强竞争力的关键战略。本文首先概述了自动化技术的定义、发展及其在商业中的角色和历史演变,随后探讨了软件与硬件自动化技术的分类、选择和关键组成要素,特别是在企业中的应用实践。第三章重点分析了自动化技术在生产流程、办公自动化系统以及客户服务中的具体应用和带来的效益。文章进一步从成本节约、效率提升、市场反应速度和企业创新等方面
【DisplayPort 1.4与HDMI 2.1对比分析】:技术规格与应用场景

# 摘要
DisplayPort 1.4与HDMI 2.1作为最新的显示接口技术,提供了更高的数据传输速率和带宽,支持更高的分辨率和刷新率,为高清视频播放、游戏、虚拟现实和专业显示设备应用提供了强大的支持。本文通过对比分析两种技术规格,探讨了它们在各种应用场景中的优势和性能表现,并提出针
揭秘WDR算法:从设计原理到高效部署
# 摘要
宽动态范围(WDR)算法作为改善图像捕捉在不同光照条件下的技术,已被广泛应用在视频监控、智能手机摄像头及智能驾驶辅助系统中。本文首先概述了WDR算法的设计原理,随后解析了其关键技术,包括动态范围扩张技术、信号处理与融合机制以及图像质量评估标准。通过案例分析,展示了WDR算法在实际应用中的集成和效果,同时探讨了算法的性能优化策略和维护部署。最后,本文展望了WDR算法与新兴技术的结合、行业趋势和研究伦理问题,指出了未来的发展方向和潜力。
# 关键字
宽动态范围;动态范围扩张;信号融合;图像质量评估;性能优化;技术应用案例
参考资源链接:[WDR算法详解与实现:解决动态范围匹配挑战](
【CTF密码学挑战全解析】:揭秘AES加密攻击的5大策略

# 摘要
本文综述了AES加密技术及其安全性分析,首先介绍了AES的基础概念和加密原理。随后,深入探讨了密码分析的基本理论,包括不同类型的攻击方法和它们的数学基础。在实践方法章节中,本研究详细分析了差分分析攻击、线性分析攻击和侧信道攻击的原理和实施步骤。通过分析AES攻击工具和经典案例研究,本文揭示了攻击者如何利用各种工具和技术实施有效攻击。最后,文章提出了提高AES加密安全性的一般建议和应对高级攻击的策略,强调了密钥管理、物理安全防护和系统级防
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )