编译技术流程:编译程序的执行过程
发布时间: 2024-01-29 09:14:07 阅读量: 64 订阅数: 32 
# 1. 介绍编译技术
## 1.1 什么是编译技术
编译技术是指将高级语言编写的程序转换为计算机可以直接执行的机器语言代码的一种技术。它是将程序从一种形式转换为另一种形式的过程,通常包括词法分析、语法分析、语义分析、代码生成和优化等步骤。
## 1.2 编译技术的应用领域
编译技术广泛应用于编程语言的开发和编译器的构建,同时也在操作系统、数据库系统、网络系统等领域有着重要作用。它为软件开发和系统优化提供了重要的支持。
## 1.3 编译技术的重要性
编译技术的重要性体现在提高程序执行效率、简化程序设计、实现跨平台编程等方面。它对软件开发的效率和结果都有着深远的影响。
# 2. 编译程序的基本结构
编译程序是一种将高级语言代码转换为可执行代码的软件工具。它按照一定的流程处理输入的源代码,并输出可执行文件或其他形式的目标代码。编译程序的基本结构包括词法分析、语法分析、语义分析、代码生成和优化等步骤。
### 2.1 词法分析
词法分析是编译过程的第一步,其主要任务是将源代码分解成一系列称为“词法单元”的符号序列。词法单元可以是关键字、标识符、运算符、常量和分隔符等。词法分析器根据预定的词法规则,通过有限自动机或正则表达式匹配的方式,逐个识别出源代码中的词法单元。
词法分析的实现通常使用一种叫做“有限自动机”的数据结构,它可以描述一个正则语言中的所有可能的字符串。通过一个状态转换图,有限自动机能够根据当前的输入及其状态,决定下一步应该转移到哪个状态。在词法分析过程中,会遍历源代码的每个字符,并根据相应的规则进行识别和转换。
```java
// 以Java语言为例,展示一个简单的词法分析器的实现
import java.util.ArrayList;
import java.util.List;
public class LexicalAnalyzer {
private String sourceCode;
private List<Token> tokens;
public LexicalAnalyzer(String sourceCode) {
this.sourceCode = sourceCode;
this.tokens = new ArrayList<>();
}
public List<Token> analyze() {
int currentPosition = 0;
while (currentPosition < sourceCode.length()) {
char currentChar = sourceCode.charAt(currentPosition);
if (Character.isLetter(currentChar)) {
String identifier = "";
while (Character.isLetterOrDigit(currentChar)) {
identifier += currentChar;
currentPosition++;
if (currentPosition < sourceCode.length()) {
currentChar = sourceCode.charAt(currentPosition);
} else {
break;
}
}
tokens.add(new Token(TokenType.IDENTIFIER, identifier));
} else if (Character.isDigit(currentChar)) {
String number = "";
while (Character.isDigit(currentChar)) {
number += currentChar;
currentPosition++;
if (currentPosition < sourceCode.length()) {
currentChar = sourceCode.charAt(currentPosition);
} else {
break;
}
}
tokens.add(new Token(TokenType.NUMBER, number));
} else if (currentChar == '+') {
tokens.add(new Token(TokenType.PLUS, "+"));
currentPosition++;
} else if (currentChar == '-') {
tokens.add(new Token(TokenType.MINUS, "-"));
currentPosition++;
}
// 其他词法单元的识别规则...
currentPosition++;
}
return tokens;
}
}
class Token {
private TokenType type;
private String value;
public Token(TokenType type, String value) {
this.type = type;
this.value = value;
}
// Getter and Setter methods...
}
enum TokenType {
IDENTIFIER, NUMBER, PLUS, MINUS
// 其他词法单元的枚举值...
}
```
**代码说明:**
上述代码展示了一个简单的词法分析器的实现。它通过遍历源代码的每个字符,根据不同的识别规则构建相应的词法单元,并将其存储在一个列表中。
在这个例子中,词法分析器能够识别标识符(由字母组成的字符串)、数字、加号和减号,然后将它们分别转换为对应的词法单元。通过循环遍历和状态判断,词法分析器能够准确地将源代码分解成不同的词法单元。
### 2.2 语法分析
语法分析是编译过程的第二步,其主要任务是根据词法分析得到的词法单元序列,构建抽象语法树(Abstract Syntax Tree, AST)。抽象语法树是一种用来表示源代码语法结构的树形结构,其中每个节点表示一个语法结构单元。
语法分析器使用一种称为“上下文无关文法”的形式语言来描述语法规则,然后根据这些规则进行分析和推导。常用的语法分析算法包括递归下降分析、LL(1)分析和LR分析等。
```python
# 以Python语言为例,展示一个简单的语法分析器的实现
class SyntaxAnalyzer:
def __init__(self, tokens):
self.tokens = tokens
self.current_token_index = 0
def match(self, expected_type):
current_token = self.tokens[self.current_token_index]
if current_token.get_type() == expected_type:
self.current_token_index += 1
else:
raise SyntaxError(f"Expected token of type {expected_type}, but got {current_token.get_type()}.")
def parse(self):
self.expression()
def expression(self):
self.term()
while self.current_token_index < len(self.tokens):
current_token = self.tokens[self.current_token_index]
if current_token.get_type() == TokenType.PLUS:
self.match(TokenType.PLUS)
self.term()
elif current_token.get_type() == TokenType.MINUS:
self.match(TokenType.MINUS)
self.term()
else:
break
def term(self):
self.factor()
while self.current_token_index < len(self.tokens):
current_token = self.tokens[self.current_token_index]
if current_token.get_type() == TokenType.MULTIPLY:
self.match(TokenType.MULTIPLY)
self.factor()
elif current_token.get_type() == TokenType.DIVIDE:
self.match(TokenType.DIVIDE)
self.factor()
else:
break
def factor(self):
current_token = self.tokens[self.current_token_index]
if current_token.get_type() == TokenType.NUMBER:
self.match(TokenType.NUMBER)
elif current_token.get_type() == TokenType.LEFT_PAREN:
self.match(TokenType.LEFT_PAREN)
self.expression()
self.match(TokenType.RIGHT_PAREN)
else:
raise SyntaxError(f"Unexpected token: {current_token.get_type()}")
# 运行语法分析器进行解析
tokens = LexicalAnalyzer("2 + 3 * (4 - 1)").analyze()
syntax_analyzer = SyntaxAnalyzer(tokens)
try:
syntax_analyzer.parse()
print("Syntax analysis successful.")
except SyntaxError as e:
print(f"Syntax analysis failed: {str(e)}")
```
**代码说明:**
上述示例代码展示了一个简单的语法分析器的实现。它使用递归下降的方法根据语法规则解析词法单元序列,并构建相应的抽象语法树。
在这个例子中,语法分析器能够处理加法和乘法的运算表达式。它通过定义一系列的语法规则(如`expression`、`term`和`factor`)以及相应的处理逻辑,递归地向下推导和匹配词法单元,从而构建抽象语法树。
通过调用语法分析器的`parse`方法,可以开始对输入的词法单元序列进行语法分析。如果解析成功,将输出"Syntax analysis successful.";如果解析失败,将捕获并输出相应的语法错误信息。
# 3. 编译器前端的执行过程
编译器前端是编译器的核心部分之一,负责将源代码转化为中间表示,同时进行语法和语义分析。本章将详细介绍编译器前端的执行过程,包括词法分析、语法分析和语义分析的实现和作用。
### 3.1 词法分析的实现和作用
词法分析是编译器前端的第一步,主要负责将源代码分解为一个个单独的词素(token)。词素是语言中的一个基本单元,例如关键字、标识符、常量等。词法分析器会根据预定义的词法规则,扫描源代码,识别并生成词素流。
#### 实现
在词法分析的过程中,常用的实现方法是使用正则表达式和有限状态机。通过定义正则表达式规则来匹配不同的词素,并使用有限状态机进行词法分析的状态转移。
```python
# 举例:在Python中实现一个简单的词法分析器,识别整数和变量名
import re
def tokenize(source_code):
tokens = []
while source_code:
if re.match(r'^\d+', source_code): # 匹配整数
match = re.match(r'^\d+', source_code)
token_value = match.group(0)
token_type = 'INTEGER'
tokens.append((token_type, token_value))
source_code = source_code[len(token_value):]
elif re.match(r'^[a-zA-Z_]\w*', source_code): # 匹配变量名
match = re.match(r'^[a-zA-Z_]\w*', source_code)
token_value = match.group(0)
token_type = 'IDENTIFIER'
tokens.append((token_type, token_value))
source_code = source_code[len(token_value):]
else:
source_code = source_code[1:]
return tokens
```
#### 作用
词法分析的主要作用是将源代码划分为一系列词素,为后续的语法分析和语义分析做准备。词法分析器生成的词素流提供给语法分析器,用于构建语法树和进行后续的语义分析。
### 3.2 语法分析的实现和作用
语法分析是编译器前端的第二步,负责构建抽象语法树(AST)。抽象语法树是源代码语法结构的一种抽象表示,将源代码转化为一棵树状结构,便于后续的语义分析和代码生成。
#### 实现
常用的语法分析方法有递归下降分析法和LR分析法。递归下降分析法通过递归调用子程序来进行语法分析,每个子程序对应于一个非终结符。
```java
// 举例:在Java中使用递归下降分析法进行语法分析
public class Parser {
private List<Token> tokens;
private int currentTokenIndex;
public Parser(List<Token> tokens) {
this.tokens = tokens;
this.currentTokenIndex = 0;
}
public void parse() {
parseProgram();
}
private void parseProgram() {
while (currentTokenIndex < tokens.size()) {
parseStatement();
}
}
private void parseStatement() {
if (tokens.get(currentTokenIndex).getType() == TokenType.IDENTIFIER) {
parseAssignmentStatement();
} else if (tokens.get(currentTokenIndex).getType() == TokenType.PRINT) {
parsePrintStatement();
} else {
// 报错处理
}
}
// 其他语法规则的递归下降子程序...
}
```
#### 作用
语法分析的主要作用是使用抽象语法树表示源代码的语法结构,为后续的语义分析和代码生成提供基础。通过语法分析,编译器能够识别语法错误并进行相应的错误处理。
### 3.3 语义分析的实现和作用
语义分析是编译器前端的最后一步,负责对抽象语法树进行静态语义检查和语义处理。语义分析器会检查和推断源代码中的语义约束,并生成中间代码,为优化和代码生成做准备。
#### 实现
语义分析的实现方式因语言而异,具体的实现方法包括类型检查、作用域分析、符号表构建等。通常会在语法分析的基础上进行语义分析。
```javascript
// 举例:在JavaScript中进行语义分析,检查变量使用的作用域
function analyze(tree) {
let symbolTable = {};
function traverse(node) {
if (node.type === 'AssignmentStatement') {
let variable = node.left;
if (!symbolTable[variable]) {
// 错误处理:未定义的变量
}
}
node.children.forEach(traverse);
}
traverse(tree);
}
```
#### 作用
语义分析的主要作用是检查程序中的语义错误,例如变量使用前未定义、类型不匹配等。同时,语义分析还会进行类型推断和类型检查,为代码生成和优化提供基础。
# 4. 编译器后端的执行过程
编译器的后端执行过程包括代码生成和优化两个主要阶段。在代码生成阶段,编译器将中间表示形式(IR)转换为目标代码,而在优化阶段,编译器对生成的目标代码进行优化,以提高程序的性能和效率。
#### 4.1 代码生成的实现和作用
代码生成阶段是将经过前端处理的中间表示形式(IR)转换为目标机器的代码的过程。这个阶段的主要任务是生成高效且正确的目标代码,以便程序在目标机器上能够正确地运行。
##### 实现和作用
在代码生成阶段,编译器需要完成以下任务:
- 指令选择:根据目标机器的指令集架构,选择合适的指令来实现每条IR指令的功能。
- 寄存器分配:将IR中的变量和临时值分配到目标机器的寄存器或内存位置上。
- 异常处理:处理目标代码中的异常情况,如越界访问、空指针等。
- 目标代码生成:将经过指令选择和寄存器分配后的IR转换为目标机器的实际指令序列。
#### 4.2 优化的实现和作用
优化阶段是编译器的一个重要部分,通过对生成的目标代码进行优化,可以有效地提高程序的性能和效率,减少程序运行所需的时间和资源消耗。
##### 实现和作用
在优化阶段,编译器可以进行多种类型的优化,包括但不限于:
- 代码优化:对目标代码进行优化,如常量折叠、循环优化、内联等,以提高代码执行效率。
- 数据流分析:对程序中的数据流进行分析,找出潜在的性能优化点。
- 控制流优化:优化程序的控制流,减少条件判断和分支跳转等,以提高程序执行的效率。
- 内存优化:优化程序对内存的访问模式,减少内存访问的开销,提高程序的运行速度。
优化阶段的目标是使生成的目标代码在保持功能正确的前提下,尽可能地提高程序的性能和效率。
希望以上内容能够满足你的需求,如果需要更详细的讨论或其他内容,请随时告诉我。
# 5. 编译过程中的常见问题与解决方案
### 5.1 常见的编译错误类型
在编译过程中,经常会遇到一些常见的错误类型。了解这些错误类型及其原因,可以帮助开发者更好地调试和解决问题。
#### 5.1.1 语法错误
语法错误是最常见的编译错误之一。当程序中存在语法错误时,编译器无法正确解析代码的结构和语义,导致编译失败。常见的语法错误包括:
- 括号不匹配
- 缺少分号
- 关键字拼写错误
例子(使用Python语言示例):
```python
def hello_world
print("Hello, World!")
```
代码总结:
这段代码中缺少了函数定义后面的冒号,导致编译器无法正确解析代码结构。修复这个错误只需在函数定义后添加冒号即可。
#### 5.1.2 类型错误
类型错误是指在代码中使用了错误的数据类型。编译器检查到这种错误时会报告类型不匹配的问题。常见的类型错误包括:
- 整数与字符串相加
- 对不兼容的数据类型进行赋值
例子(使用Java语言示例):
```java
int a = 10;
String b = "Hello";
int c = a + b;
```
代码总结:
在这段代码中,a是一个整数,b是一个字符串。将整数和字符串直接相加会导致类型不匹配的错误。修复这个错误只需将整数转换为字符串,或将字符串转换为整数。
#### 5.1.3 未声明的变量
使用未声明的变量是另一个常见的编译错误。当编译器遇到一个未声明的变量时,它无法识别该变量的类型和作用域,导致编译失败。常见的未声明的变量错误包括:
- 拼写错误导致变量名错误
- 在使用变量之前忘记声明变量
例子(使用Go语言示例):
```go
fmt.Println(a)
```
代码总结:
在这段代码中,变量a未声明,导致编译器无法识别该变量。修复这个错误只需在使用变量之前声明它,或者检查变量名是否拼写正确。
### 5.2 调试编译器产生的问题
当编译器产生问题时,调试是解决问题的关键。以下是一些调试编译器产生的问题的常用方法:
1. 仔细阅读错误信息:当编译器遇到问题时,它会生成错误信息。仔细阅读错误信息可以定位问题的来源和原因。
2. 逐步调试:使用调试工具对编译器进行逐步调试。通过逐步执行代码并观察每个步骤的结果,可以找出问题所在。
3. 编写简化的示例代码:如果遇到一个复杂的编译问题,可以尝试编写一个简化的示例代码,以便更容易定位和修复问题。
4. 搜索错误信息:如果无法解决问题,可以在互联网上搜索相关的错误信息或类似的问题。可能有其他人已经遇到并解决了类似的问题。
### 5.3 优化技术应用中的挑战与解决方案
在编译过程中,优化是改进代码性能和效率的重要环节。然而,优化技术应用中常常会遇到一些挑战。以下是一些常见的挑战及解决方案:
1. 代码重构的挑战:在优化过程中,可能需要对代码进行重构。但是,代码重构可能会导致逻辑错误和不可预测的行为。解决这个问题的方法是在重构前编写详细的测试用例,并在重构后运行这些测试用例以验证代码的正确性。
2. 并行化的挑战:在优化过程中,常常会考虑将代码并行化以提高性能。然而,并行化可能会引入数据竞争和死锁等问题。为了解决这些问题,可以使用锁和同步机制来保护共享数据,或者使用无锁的数据结构来避免竞争。
3. 目标代码生成的挑战:优化后的代码必须正确地生成目标代码,以便在目标平台上执行。为了解决这个问题,需要对目标平台的指令集和内存模型有深入的了解,并生成与平台兼容的代码。
希望这些常见的问题和解决方案对你在编译过程中有所帮助。记住,在遇到问题时要仔细分析并尝试不同的解决方案。
# 6. 未来编译技术发展趋势展望
编译技术作为计算机科学领域的重要分支,不断在不同领域展现其巨大潜力。本章将探讨编译技术未来的发展趋势,并讨论新兴技术对编译技术的影响,以及编译技术对未来计算机行业的影响。
#### 6.1 编译技术的未来发展趋势
随着计算机体系结构的不断演化和新兴技术的崛起,编译技术也在不断发展和创新。以下是一些编译技术未来的发展趋势:
1. **并行编程支持**:随着多核处理器的普及,编译技术将更加注重并行编程的支持。编译器将优化程序以充分利用并行计算资源,提高程序性能和效率。
2. **自动向量化**:将循环等迭代结构转化为向量指令,以加速程序执行。自动向量化技术的发展将使得编译器能够有效利用SIMD指令集,提高程序性能。
3. **动态编译**:动态编译技术将源代码的编译和执行结合起来,可以根据程序的运行时信息进行优化。动态编译技术有望在性能和可移植性方面取得更好的平衡。
4. **领域特定编译器**:随着各个领域的需求不断增加,编译技术将更多地关注于开发领域特定的编译器。这些编译器将针对具体领域的特殊需求进行优化,提高程序的性能和可维护性。
#### 6.2 新兴技术对编译技术的影响
新兴技术对编译技术的发展和演进具有重要影响力。以下是一些新兴技术对编译技术的影响:
1. **人工智能和机器学习**:人工智能和机器学习的快速发展推动了编译技术的创新。编译器可以通过学习和优化算法,更好地优化程序以适应实时数据需求和不断变化的环境。
2. **量子计算**:量子计算是一项颠覆性的技术,对编译技术提出了许多挑战。编译器需要针对量子计算机的特殊需求进行优化,以提高量子算法的执行效率和精确性。
3. **边缘计算**:边缘计算的兴起将推动编译技术朝向更加分布式和灵活的方向发展。编译器需要能够自动化地将程序部署到边缘设备上,并充分利用边缘计算资源。
#### 6.3 编译技术对未来计算机行业的影响
编译技术在未来计算机行业中将发挥越来越重要的作用。
1. **提高计算机性能**:编译技术的不断发展将能够提供更高效的代码生成和优化策略,从而提高程序的执行效率和计算机的性能。
2. **降低开发成本**:编译技术的发展可以提供更好的自动化工具和优化方法,帮助开发人员降低开发成本和提高开发效率。
3. **保障程序安全**:编译技术可以通过对程序代码的优化和分析,提高程序的安全性,并减少潜在的安全漏洞。
总之,编译技术的未来发展将不仅仅局限于提高程序执行效率,还将涉及到更多领域特定的需求和新兴技术的应用。这些发展和创新将为计算机行业带来更加高效、安全和可靠的软件和系统。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏旨在介绍和探讨编译技术的基本概念、原理和实现方法。文章包括编译系统的基本概念、编译程序的原理和实现、编译程序的执行过程等内容。此外,还介绍了正则表达式的核心概念、正规式到NFA的转换过程、FIRST与FOLLOW集的生成过程、LL(1)分析法的原理和应用、算符优先分析方法的具体实现、LR语法分析法的基本原理以及NFA到DFA的转换实现。通过学习这些内容,读者将能够深入了解编译技术的思路、方法和应用,为他们在软件开发和编程领域中的实际应用提供支持和指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
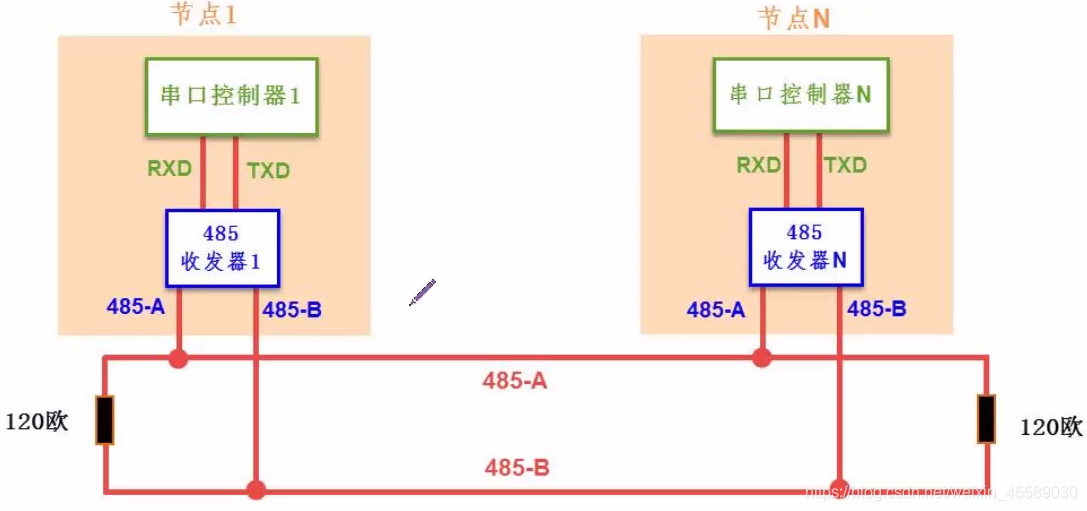
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )