Navicat连接Oracle数据库:PL_SQL脚本编写与调试,自动化你的数据库任务
发布时间: 2024-08-02 19:55:58 阅读量: 55 订阅数: 29 

navicat链接Oracle数据库工具

# 1. Navicat概述与Oracle数据库连接**
Navicat是一款功能强大的数据库管理工具,它支持多种数据库系统,包括Oracle、MySQL、SQL Server等。本节将介绍Navicat的基本概述以及如何连接到Oracle数据库。
### Navicat概述
Navicat是一款商业数据库管理工具,它提供了一个直观的用户界面,用于管理数据库对象、执行查询和管理数据库服务器。Navicat支持多种数据库系统,包括Oracle、MySQL、SQL Server、PostgreSQL、SQLite和MariaDB。
### 连接到Oracle数据库
要连接到Oracle数据库,需要在Navicat中创建新的数据库连接。在“连接”菜单中,选择“MySQL”并输入以下信息:
* **主机名或IP地址:**Oracle数据库服务器的地址
* **端口:**Oracle数据库服务器的端口号(默认值为1521)
* **用户名:**连接到数据库的用户名
* **密码:**连接到数据库的密码
* **服务名:**Oracle数据库的实例名(SID)
输入所有必要信息后,单击“连接”按钮。如果连接成功,Navicat将显示数据库对象列表。
# 2.1 PL/SQL语言结构和语法
### 2.1.1 PL/SQL代码块和变量
**PL/SQL代码块**
PL/SQL代码块是PL/SQL语言的基本执行单元,它由一系列语句组成,并以BEGIN和END关键字包围。例如:
```
BEGIN
-- PL/SQL语句
END;
```
**PL/SQL变量**
PL/SQL变量用于存储数据值,类似于其他编程语言中的变量。变量必须先声明,然后才能使用。变量声明的语法如下:
```
DECLARE variable_name datatype [DEFAULT default_value];
```
例如:
```
DECLARE
employee_id NUMBER;
employee_name VARCHAR2(50);
salary NUMBER(10,2);
BEGIN
-- PL/SQL语句
END;
```
### 2.1.2 PL/SQL数据类型和运算符
**PL/SQL数据类型**
PL/SQL支持多种数据类型,包括数字类型(NUMBER)、字符类型(VARCHAR2、CHAR)、日期类型(DATE、TIMESTAMP)和布尔类型(BOOLEAN)。
**PL/SQL运算符**
PL/SQL提供了各种运算符,用于执行算术、比较和逻辑操作。这些运算符与其他编程语言中的运算符类似。
| 运算符 | 描述 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取模 |
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| NOT | 逻辑非 |
# 3. PL/SQL脚本实践
### 3.1 数据操作语句
#### 3.1.1 SELECT语句
SELECT语句用于从数据库表中检索数据。其基本语法如下:
```sql
SELECT column_list
FROM table_name
WHERE condition;
```
**参数说明:**
* **column_list:**要检索的列名,可以使用星号(*)表示所有列。
* **table_name:**要查询的表名。
* **condition:**可选的过滤条件,用于限制检索的数据。
**代码示例:**
```sql
SELECT *
FROM employees
WHERE department_id = 10;
```
**逻辑分析:**
该代码从employees表中检索所有列,其中department_id等于10的记录。
#### 3.1.2 INSERT、UPDATE和DELETE语句
INSERT、UPDATE和DELETE语句用于对数据库表中的数据进行操作。
**INSERT语句**
INSERT语句用于向表中插入新记录。其基本语法如下:
```sql
INSERT INTO table_name (column_list)
VALUES (value_list);
```
**参数说明:**
* **table_name:**要插入记录的表名。
* **column_list:**要插入值的列名。
* **value_list:**要插入的值列表,与column_list中的列顺序对应。
**代码示例:**
```sql
INSERT INTO employees (employee_id, first_name, last_name, department_id)
VALUES (100, 'John', 'Doe', 10);
```
**逻辑分析:**
该代码向employees表中插入一条新记录,employee_id为100,first_name为John,last_name为Doe,department_id为10。
**UPDATE语句**
UPDATE语句用于更新表中现有记录。其基本语法如下:
```sql
UPDATE table_name
SET column_name = new_value
WHERE condition;
```
**参数说明:**
* **table_name:**要更新记录的表名。
* **column_name:**要更新的列名。
* **new_value:**要更新的新值。
* **condition:**可选的过滤条件,用于限制要更新的记录。
**代码示例:**
```sql
UPDATE employees
SET salary = salary * 1.10
WHERE department_id = 10;
```
**逻辑分析:**
该代码将department_id为10的员工的工资更新为其当前工资的110%。
**DELETE语句**
DELETE语句用于从表中删除记录。其基本语法如下:
```sql
DELETE FROM t
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到我们的专栏,我们将深入探讨 Navicat 连接 Oracle 数据库的方方面面。从入门指南到性能优化秘籍,再到安全配置指南,我们为您提供全面的指南,帮助您充分利用这一强大的数据库管理工具。
本专栏涵盖了广泛的主题,包括连接池配置、事务处理、数据备份和恢复、SQL 语句操作、PL_SQL 脚本编写、数据建模、数据库监控、与其他工具的集成以及面向开发者的实用技巧。通过深入浅出的讲解和丰富的案例研究,我们将帮助您掌握 Navicat 的强大功能,提升您的数据库管理技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WLC3504配置实战手册:无线安全与网络融合的终极指南

# 摘要
WLC3504无线控制器作为网络管理的核心设备,在保证网络安全、配置网络融合特性以及进行高级网络配置方面扮演着关键角色。本文首先概述了WLC3504无线控制器的基本功能,然后深入探讨了其无线安全配置的策略和高级安全特性,包括加密、认证、访问控制等。接着,文章分析了网络融合功能,解释了无线与有线网络融合的理论与配置方法,并讨论
【802.11协议深度解析】RTL8188EE无线网卡支持的协议细节大揭秘

# 摘要
无线通信技术是现代社会信息传输的重要基础设施,其中802.11协议作为无线局域网的主要技术标准,对于无线通信的发展起到了核心作用。本文从无线通信的基础知识出发,详细介绍了802.11协议的物理层和数据链路层技术细节,包括物理层传输媒介、标准和数据传输机制,以及数据链路层的MAC地址、帧格式、接入控制和安全协议。同时,文章还探讨了RTL8188EE无线网
Allegro 172版DFM规则深入学习:掌握DFA Package spacing的实施步骤
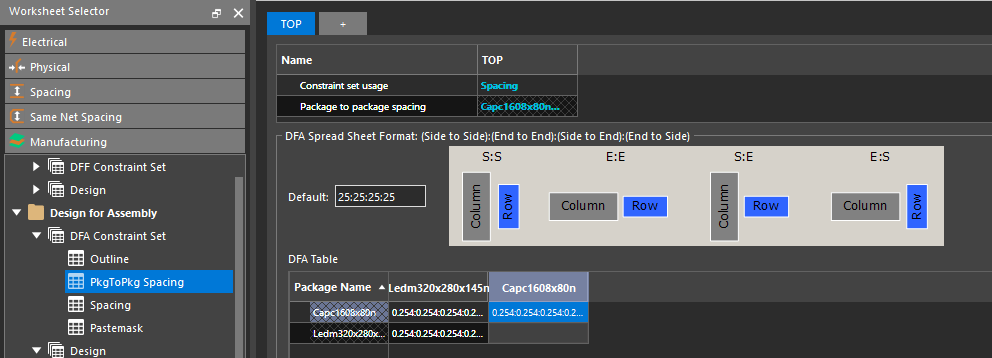
# 摘要
本文围绕Allegro PCB设计与DFM规则,重点介绍了DFA Package Spacing的概念、重要性、行业标准以及在Allegro软件中的实施方法。文章首先定义了DFA Packag
【AUTOSAR TPS深度解析】:掌握TPS在ARXML中的5大应用与技巧

# 摘要
本文系统地介绍了AUTOSAR TPS(测试和验证平台)的基础和进阶应用,尤其侧重于TPS在ARXML(AUTOSAR扩展标记语言)中的使用。首先概述了TPS的基本概念,接着详细探讨了TPS在ARXML中的结构和组成、配置方法、验证与测试
【低频数字频率计设计核心揭秘】:精通工作原理与优化设计要点

# 摘要
数字频率计作为一种精确测量信号频率的仪器,其工作原理涉及硬件设计与软件算法的紧密结合。本文首先概述了数字频率计的工作原理和测量基础理论,随后详细探讨了其硬件设计要点,包括时钟源选择、计数器和分频器的使用、高精度时钟同步技术以及用户界面和通信接口设计。在软件设计与算法优化方面,本文分析了不同的测量算法以
SAP用户管理精进课:批量创建技巧与权限安全的黄金平衡

# 摘要
随着企业信息化程度的加深,有效的SAP用户管理成为确保企业信息安全和运营效率的关键。本文详细阐述了SAP用户管理的各个方面,从批量创建用户的技术和方法,到用户权限分配的艺术,再到权限安全与合规性的要求。此外,还探讨了在云和移动环境下的用户管理高级策略,并通过案例研究来展示理论在实践中的应用。文章旨在为SAP系统管理员提供一套全面的用户管理解决方案,帮助他们优化管理流程,提
【引擎选择秘籍】《弹壳特攻队》挑选最适合你的游戏引擎指南

# 摘要
本文全面分析了游戏引擎的基本概念与分类,并深入探讨了游戏引擎技术核心,包括渲染技术、物理引擎和音效系统等关键技术组件。通过对《弹壳特攻队》游戏引擎实战案例的研究,本文揭示了游戏引擎选择和定制的过程,以及如何针对特定游戏需求进行优化和多平台适配。此外,本文提供了游戏引擎选择的标准与策略,强调了商业条款、功能特性以及对未来技术趋势的考量。通过案例分析,本
【指示灯识别的机器学习方法】:理论与实践结合
# 摘要
本文全面探讨了机器学习在指示灯识别中的应用,涵盖了基础理论、特征工程、机器学习模型及其优化策略。首先介绍了机器学习的基础和指示灯识别的重要性。随后,详细阐述了从图像处理到颜色空间分析的特征提取方法,以及特征选择和降维技术,结合实际案例分析和工具使用,展示了特征工程的实践过程。接着,讨论了传统和深度学习模
【卷积块高效实现】:代码优化与性能提升的秘密武器
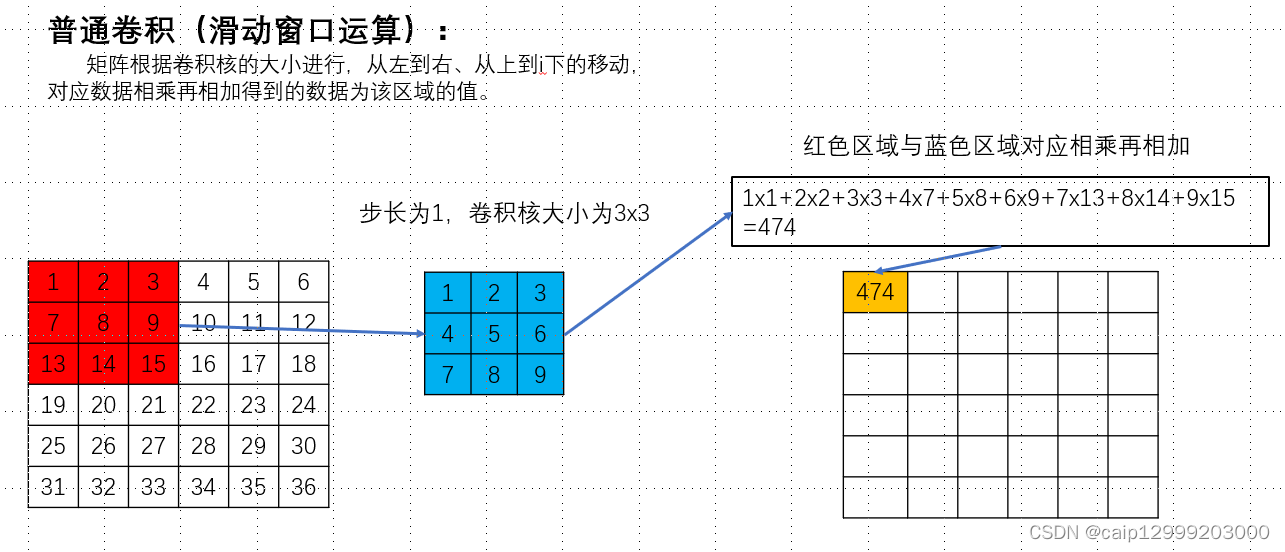
# 摘要
卷积神经网络(CNN)是深度学习领域的重要分支,在图像和视频识别、自然语言处理等方面取得了显著成果。本文从基础知识出发,深入探讨了卷积块的核心原理,包括其结构、数学模型、权重初始化及梯度问题。随后,详细介绍了卷积块的代码实现技巧,包括算法优化、编程框架选择和性能调优。性能测试与分析部分讨论了测试方法和实际应用中性能对比,以及优化策略的评估与选择。最后,展望了卷积块优化的未来趋势,包括新型架构、算法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )