HBase安装与配置详解
发布时间: 2024-02-16 14:01:36 阅读量: 85 订阅数: 43 

HBase的安装与配置
# 1. HBase简介与概述
## 1.1 HBase概述
HBase是一个分布式、面向列的开源数据库系统,构建在Hadoop文件系统(HDFS)之上。它提供了实时读写访问大型数据集的功能,并且具有高可靠性、高性能和线性可扩展性。
HBase的数据模型是稀疏的、持久的、多维的排序映射表,它适合存储大量结构化数据,可用于快速随机访问。HBase最初由Powerset公司开发,后来被Facebook采用,并成为Apache软件基金会的顶级项目之一。
## 1.2 HBase特点与优势
- **强一致性**:HBase提供强一致性和高可用性,支持跨行事务。
- **线性可扩展**:通过横向扩展节点,实现线性扩展存储性能。
- **自动分区和负载均衡**:HBase自动将表分成多个区域,并在Region Server之间实现负载均衡。
- **灵活的数据模型**:HBase使用稀疏、多维的分布式数据模型,适合于动态模式和半结构化数据。
- **快速随机读/写**:HBase能够在毫秒级别内处理海量数据的增删改查操作。
## 1.3 HBase在大数据应用中的地位和作用
HBase在大数据应用中扮演着重要角色,它通常与Hadoop生态系统的其他组件(如HDFS、MapReduce、ZooKeeper等)协同工作,用于实时分析、实时查询和在线存储大规模数据。在互联网、金融、物联网和企业数据分析等领域都有着广泛的应用。
以上是第一章的内容,接下来可以继续阅读第二章:准备工作与环境配置。
# 2. 准备工作与环境配置
### 2.1 检查系统要求与硬件配置
在安装HBase之前,我们需要确保系统满足一定的要求,同时对硬件进行相应的配置。具体的要求和配置如下:
- **系统要求**:
- 操作系统:推荐使用Linux操作系统(例如CentOS、Ubuntu等)
- 内核版本:建议使用3.10及以上版本
- 内存:推荐至少8GB以上
- 存储空间:至少50GB以上
- **硬件配置**:
- CPU:建议至少4核以上
- 网络:建议支持1Gbps以上的带宽
- 硬盘:建议使用SSD硬盘,提高读写性能
### 2.2 安装JDK
HBase是运行在JVM(Java虚拟机)上的,所以我们首先需要安装JDK(Java Development Kit)。以下是JDK的安装步骤:
1. 访问Oracle官方网站,下载最新版本的JDK安装包(例如JDK 8)。
2. 解压下载的安装包,并将解压后的文件夹放在指定目录(例如`/usr/local/java`)。
3. 配置环境变量:
- 打开终端,并编辑`.bashrc`文件:`vi ~/.bashrc`
- 在文件末尾添加以下内容:
```
export JAVA_HOME=/usr/local/java/jdk1.8.0_301
export PATH=$PATH:$JAVA_HOME/bin
```
- 保存并退出文件,然后执行以下命令使配置生效:`source ~/.bashrc`
4. 验证JDK安装是否成功:
- 打开终端,执行以下命令:`java -version`
- 如果成功安装,会显示Java的版本信息。
### 2.3 配置Hadoop环境
在安装HBase之前,通常需要先安装并配置Hadoop。如果已经安装并配置了Hadoop,可以跳过此步骤。以下是Hadoop的环境配置步骤:
1. 下载并解压Hadoop安装包,将解压后的文件夹放在指定目录(例如`/usr/local/hadoop`)。
2. 配置Hadoop环境变量:
- 打开终端,并编辑`.bashrc`文件:`vi ~/.bashrc`
- 在文件末尾添加以下内容:
```
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
```
- 保存并退出文件,然后执行以下命令使配置生效:`source ~/.bashrc`
3. 修改Hadoop配置文件:
- 打开`hadoop-env.sh`文件:`vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh`
- 将其中的`export JAVA_HOME`行的注释去掉,并将其值设置为JDK的安装路径,例如:`export JAVA_HOME=/usr/local/java/jdk1.8.0_301`
- 保存并退出文件。
4. 验证Hadoop配置是否正确:
- 打开终端,执行以下命令:`hadoop version`
- 如果成功配置,会显示Hadoop的版本信息。
至此,第二章的内容结束。接下来,我们将开始安装和部署HBase。
# 3. HBase安装与部署
### 3.1 下载和解压HBase安装包
首先,我们需要从HBase官方网站下载HBase的安装包。你可以在以下网址找到最新版本的HBase安装包:[HBase官方网站](https://hbase.apache.org/)
点击下载链接后,选择合适的版本下载,通常会选择二进制版本。
下载完成后,将安装包解压到指定目录:
```shell
$ tar -zxf hbase-x.x.x.tar.gz
```
### 3.2 配置HBase环境变量
在安装HBase之前,我们需要先配置HBase的环境变量。打开终端,编辑`~/.bashrc`文件,添加以下内容:
```shell
# Set HBase environment variables
export HBASE_HOME=/path/to/hbase
export PATH=$PATH:$HBASE_HOME/bin
```
将`/path/to/hbase`替换为你解压HBase安装包的目录。
保存并退出文件后,运行以下命令使环境变量生效:
```shell
$ source ~/.bashrc
```
### 3.3 启动HBase
完成环境变量配置后,我们可以启动HBase了。在终端中输入以下命令启动HBase:
```shell
$ start-hbase.sh
```
等待一段时间后,HBase会成功启动,并在终端中显示相关的信息。
至此,我们已经完成了HBase的安装和部署。接下来,我们可以进行HBase的配置和优化工作。
在下一章节中,我们将详细讲解HBase的配置文件,并介绍如何进行数据目录和日志目录的配置。
希望以上内容能够帮助你成功安装和部署HBase。
# 4. HBase配置与优化
在部署和运行HBase之前,我们需要对其进行一些配置和优化。本章将详细介绍HBase的配置文件以及如何进行数据目录和日志目录配置,还将介绍一些关于内存和磁盘的优化方法。
### 4.1 HBase配置文件详解
HBase的配置是通过修改`hbase-site.xml`文件来实现的。在HBase安装目录下的`conf`文件夹中,可以找到这个文件。
该文件包含了HBase的各种配置项,其中一些常见的配置项如下:
```xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.4</value>
</property>
```
这些配置项的具体含义和作用如下:
- `hbase.rootdir`:指定HBase在HDFS上的根目录,用于存储HBase的数据文件。
- `hbase.zookeeper.quorum`:指定ZooKeeper的地址,用于存储HBase的元数据。
- `hfile.block.cache.size`:指定HFile在内存中的缓存大小比例。默认值为0.4,即占用可用堆内存的40%。
### 4.2 数据目录与日志目录配置
HBase的数据目录和日志目录可以在`hbase-site.xml`文件中进行配置。
数据目录用于存储HBase的数据文件,可以通过修改以下配置项来指定数据目录:
```xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
```
在这个例子中,我们将数据目录指定为HDFS上的`/hbase`目录。
日志目录用于存储HBase的日志文件,可以通过修改以下配置项来指定日志目录:
```xml
<property>
<name>hbase.regionserver.log.dir</name>
<value>/path/to/logs</value>
</property>
```
在这个例子中,我们将日志目录指定为`/path/to/logs`目录。
### 4.3 内存与磁盘优化
为了提高HBase的性能,我们需要进行一些内存和磁盘的优化。
对于内存优化,可以通过修改以下配置项来设置HBase内存的大小:
```xml
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>67108864</value>
</property>
```
- `hbase.regionserver.global.memstore.size`:指定每个RegionServer节点上MemStore的占用比例。默认值为0.4,即占用可用堆内存的40%。
- `hbase.hregion.memstore.flush.size`:指定当MemStore达到一定大小时进行Flush的阈值。默认值为67108864字节(64MB)。
对于磁盘优化,可以通过修改以下配置项来设置HFile的压缩类型和块大小:
```xml
<property>
<name>hbase.hfile.compress</name>
<value>SNAPPY</value>
</property>
<property>
<name>hfile.block.size</name>
<value>65536</value>
</property>
```
- `hbase.hfile.compress`:指定HFile的压缩类型。常见的压缩类型有`NONE`、`GZ`、`LZO`和`SNAPPY`等。
- `hfile.block.size`:指定HFile的块大小。默认值为65536字节(64KB)。
以上是HBase的配置与优化的一些基本内容,根据实际需要可以进行更详细的配置和优化。在实际部署和运行中,可以根据系统资源和负载情况进行适当的调整和优化,以提高HBase的性能和稳定性。
希望本章的内容能够对你有所帮助,下一章我们将介绍HBase集群部署的相关内容。
# 5. HBase集群部署
在本章中,我们将学习如何进行HBase集群的部署。HBase的集群部署包括单机模式与伪分布式模式部署、集群模式部署以及配置HBase高可用性。下面我们将逐步介绍相关内容。
#### 5.1 单机模式与伪分布式模式部署
##### 单机模式部署
在单机模式下,HBase和Hadoop都运行在一台机器上,适合于开发和测试环境。
首先,确保已经安装并配置好Hadoop,然后按照以下步骤进行HBase单机模式部署:
1. 修改HBase配置文件`hbase-site.xml`,设置`hbase.rootdir`为HDFS上的目录,例如:
```xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<!-- 其他配置 -->
</configuration>
```
2. 启动HBase服务:
```bash
$ start-hbase.sh
```
##### 伪分布式模式部署
伪分布式模式下,HBase和Hadoop也运行在一台机器上,但是Hadoop会以伪分布式的方式运行。
具体步骤如下:
1. 修改HBase配置文件`hbase-site.xml`,设置`hbase.rootdir`为HDFS上的目录,例如:
```xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<!-- 其他配置 -->
</configuration>
```
2. 启动HBase服务:
```bash
$ start-hbase.sh
```
#### 5.2 集群模式部署
在集群模式下,HBase和Hadoop运行在一个分布式集群中,适合于生产环境。
集群模式的部署需要配置HBase的主从节点以及ZooKeeper,保证集群的高可用和负载均衡。
#### 5.3 配置HBase高可用性
在HBase集群部署中,保证HBase服务的高可用性非常重要。可以通过配置主从复制、ZooKeeper以及RegionServer的负载均衡等方式来实现高可用性。
以上就是HBase集群部署的简要介绍,接下来我们将详细介绍集群模式部署和高可用性配置的具体步骤。
# 6. HBase备份与恢复策略
在使用HBase时,备份与恢复数据是非常重要的,可以帮助我们应对各种意外情况,保护数据的完整性和可靠性。本章将介绍HBase的备份与恢复策略,并通过实际案例来演示操作步骤。
### 6.1 HBase备份策略
HBase的备份策略可以分为离线备份和在线备份两种方式。
#### 6.1.1 离线备份
离线备份是指对HBase表进行全量备份,备份期间需要停止对表的写入操作。
下面是一个使用Java API进行HBase离线备份的示例代码:
```java
// 导入相关的类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseBackupExample {
private static final String TABLE_NAME = "my_table";
private static final String BACKUP_PATH = "/backup/my_table";
public static void main(String[] args) {
try {
// 创建HBase配置对象
Configuration config = HBaseConfiguration.create();
// 创建HBase管理员对象
HBaseAdmin admin = new HBaseAdmin(config);
// 创建FileSystem对象
FileSystem fs = FileSystem.get(config);
// 判断备份路径是否存在,如果存在则删除
Path backupPath = new Path(BACKUP_PATH);
if (fs.exists(backupPath)) {
fs.delete(backupPath, true);
}
// 创建备份
admin.disableTable(TABLE_NAME);
admin.snapshot(TABLE_NAME, BACKUP_PATH);
admin.enableTable(TABLE_NAME);
// 输出备份成功信息
System.out.println("HBase table backup successful!");
// 关闭资源
admin.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
#### 6.1.2 在线备份
在线备份是指对HBase表进行增量备份,备份期间不会停止对表的写入操作。
下面是一个使用Python API进行HBase在线备份的示例代码:
```python
# 导入相关的库
import happybase
def hbase_backup(table_name, backup_path):
# 创建HBase连接
connection = happybase.Connection('localhost')
# 创建备份
connection.backup_enable(table_name, backup_path)
# 输出备份成功信息
print("HBase table backup successful!")
# 关闭连接
connection.close()
# 备份表名和路径
table_name = 'my_table'
backup_path = '/backup/my_table'
# 调用备份函数
hbase_backup(table_name, backup_path)
```
### 6.2 HBase恢复策略
对于备份过的HBase表,我们可以通过恢复策略将备份数据还原到原始表中。
下面是一个使用HBase Shell进行恢复操作的示例代码:
```shell
# 停止HBase服务
./bin/stop-hbase.sh
# 清空原始数据
rm -rf ./data
# 还原备份数据
./bin/hbase org.apache.hadoop.hbase.backup.RestoreClient \
-backup_root /backup/my_table \
-backup_id backup_20210101 \
-o ./
# 启动HBase服务
./bin/start-hbase.sh
# 输出恢复成功信息
echo "HBase table restore successful!"
```
### 6.3 实际案例分析与操作步骤
本节通过一个实际案例,演示如何使用HBase的备份与恢复功能。
1. 在本地运行HBase,并创建一个名为my_table的表。
2. 使用离线备份策略,将my_table表进行全量备份。
3. 停止HBase服务,清空原始数据。
4. 使用恢复策略,将备份数据还原到原始表中。
5. 启动HBase服务,并验证数据恢复是否成功。
通过以上步骤,我们可以实现HBase的数据备份与恢复操作。
以上是关于HBase备份与恢复策略的详细介绍,包括离线备份和在线备份两种方式,并提供了相应的示例代码和操作步骤。通过备份与恢复策略,我们可以保护和恢复HBase的数据,提高数据的可靠性和稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《HBase知识点详解》深入探讨了HBase数据库的基础概念、架构解析以及各项操作与配置。从HBase的安装与配置、数据的写入和读取操作、数据模型与表设计、数据存储与索引机制等方面进行了详细解析。同时,本专栏还探讨了HBase的数据一致性与事务处理、数据压缩与性能优化、数据备份与恢复策略、数据分区与负载均衡、数据访问控制与安全配置等重要知识点。此外,本专栏还涵盖了HBase与其他大数据技术的整合、数据局部性与缓存优化、数据合并与分裂机制、数据过滤与查询优化以及数据一致性模型与并发控制等内容。最后,本专栏还介绍了HBase的数据复制与跨数据中心同步策略,为读者提供了全面的HBase知识体系。无论您是初学者还是有一定经验的专业人士,本专栏都会为您提供实用的知识和实践经验,帮助您更好地理解和应用HBase数据库。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【GSEA基础入门】:掌握基因集富集分析的第一步

# 摘要
基因集富集分析(GSEA)是一种广泛应用于基因组学研究的生物信息学方法,其目的是识别在不同实验条件下显著改变的生物过程或通路。本文首先介绍了GSEA的理论基础,并与传统基因富集分析方法进行比较,突显了GSEA的核心优势。接着,文章详细叙述了GSEA的操作流程,包括软件安装配置、数据准备与预处理、以及分析步骤的讲解。通过实践案例分析,展示了GSEA在疾病相关基因集和药物作用机制研究中的应用,以及结果的
【ISO 14644标准的终极指南】:彻底解码洁净室国际标准
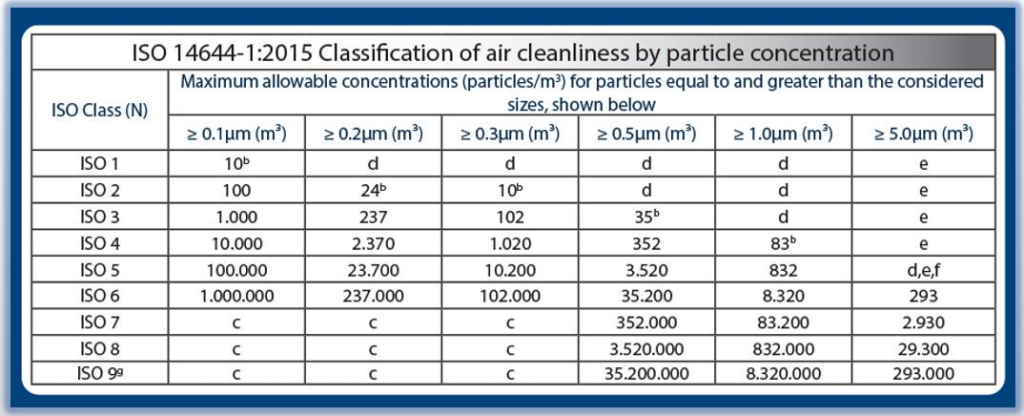
# 摘要
本文系统阐述了ISO 14644标准的各个方面,从洁净室的基础知识、分类、关键参数解析,到标准的详细解读、环境控制要求以及监测和维护。此外,文章通过实际案例探讨了ISO 14644标准在不同行业的实践应用,重点分析了洁净室设计、施工、运营和管理过程中的要点。文章还展望了洁净室技术的发展趋势,讨论了实施ISO 14644标准所
【从新手到专家】:精通测量误差统计分析的5大步骤

# 摘要
测量误差统计分析是确保数据质量的关键环节,在各行业测量领域中占有重要地位。本文首先介绍了测量误差的基本概念与理论基础,探讨了系统误差、随机误差、数据分布特性及误差来源对数据质量的影响。接着深入分析了误差统计分析方法,包括误差分布类型的确定、量化方法、假设检验以及回归分析和相关性评估。本文还探讨了使用专业软件工具进行误差分析的实践,以及自编程解决方案的实现步骤。此外,文章还介绍了测量误差统计分析的高级技巧,如误差传递、合
【C++11新特性详解】:现代C++编程的基石揭秘
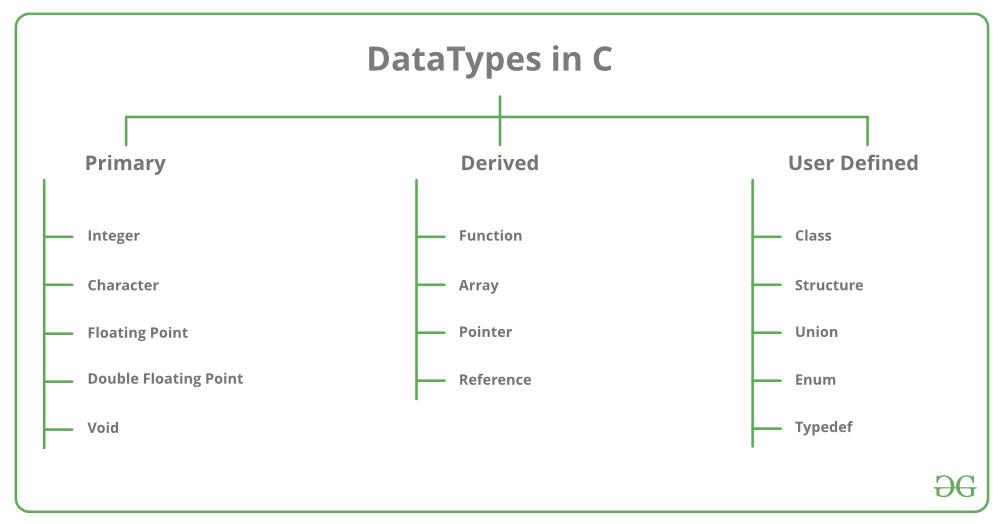
# 摘要
C++11作为一种现代编程语言,引入了大量增强特性和工具库,极大提升了C++语言的表达能力及开发效率。本文对C++11的核心特性进行系统性概览,包括类型推导、模板增强、Lambda表达式、并发编程改进、内存管理和资源获取以及实用工具和库的更新。通过对这些特性的深入分析,本文旨在探讨如何将C++11的技术优势应用于现代系统编程、跨平台开发,并展望C++11在未来
【PLC网络协议揭秘】:C#与S7-200 SMART握手全过程大公开
# 摘要
本文旨在详细探讨C#与S7-200 SMART PLC之间通信协议的应用,特别是握手协议的具体实现细节。首先介绍了PLC与网络协议的基础知识,随后深入分析了S7-200 SMART PLC的特点、网络配置以及PLC通信协议的概念和常见类型。文章进一步阐述了C#中网络编程的基础知识,为理解后续握手协议的实现提供了必要的背景。在第三章,作者详细解读了握手协议的理论基础和实现细节,包括数据封装与解析的规则和方法。第四章提供了一个实践案例,详述了开发环境的搭建、握手协议的完整实现,以及在实现过程中可能遇到的问题和解决方案。第五章进一步讨论了握手协议的高级应用,包括加密、安全握手、多设备通信等
电脑微信"附近的人"功能全解析:网络通信机制与安全隐私策略
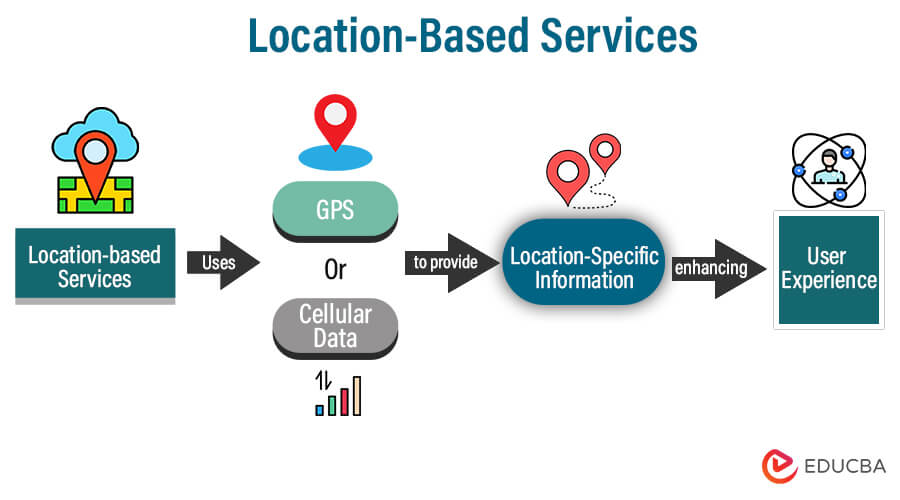
# 摘要
本文综述了电脑微信"附近的人"功能的架构和隐私安全问题。首先,概述了"附近的人"功能的基本工作原理及其网络通信机制,包括数据交互模式和安全传输协议。随后,详细分析了该功能的网络定位机制以及如何处理和保护定位数据。第三部分聚焦于隐私保护策略和安全漏洞,探讨了隐私设置、安全防护措施及用户反馈。第四章通过实际应用案例展示了"附近的人"功能在商业、社会和
Geomagic Studio逆向工程:扫描到模型的全攻略
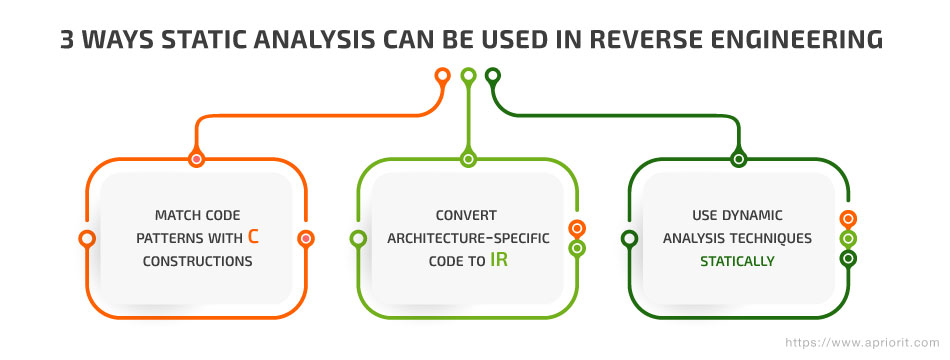
# 摘要
本文系统地介绍了Geomagic Studio在逆向工程领域的应用。从扫描数据的获取、预处理开始,详细阐述了如何进行扫描设备的选择、数据质量控制以及预处理技巧,强调了数据分辨率优化和噪声移除的重要性。随后,文章深入讨论了在Geomagic Studio中点云数据和网格模型的编辑、优化以及曲面模型的重建与质量改进。此外,逆向工程模型在不同行业中的应用实践和案例分析被详细探讨,包括模型分析、改进方法论以及逆向工程的实际应用。最后,本文探
大数据处理:使用Apache Spark进行分布式计算

# 摘要
Apache Spark是一个为高效数据处理而设计的开源分布式计算系统。本文首先介绍了Spark的基本概念及分布式计算的基础知识,然后深入探讨了Spark的架构和关键组件,包括核心功能、SQL数据处理能力以及运行模式。接着,本文通过实践导向的方式展示了Spark编程模型、高级特性以及流处理应用的实际操作。进一步,文章阐述了Spark MLlib机器学习库和Gr
【FPGA时序管理秘籍】:时钟与延迟控制保证系统稳定运行

# 摘要
随着数字电路设计的复杂性增加,FPGA时序管理成为保证系统性能和稳定性的关键技术。本文首先介绍了FPGA时序管理的基础知识,深入探讨了时钟域交叉问题及其对系统稳定性的潜在影响,并且分析了多种时钟域交叉处理技术,包括同步器、握手协议以及双触发器和时钟门控技术。在延迟控制策略方面,本文阐述了延
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )