Python在科学计算中的应用与实例
发布时间: 2024-01-14 00:48:55 阅读量: 93 订阅数: 31 

Python在科学计算中的应用
# 1. 简介
## 1.1 Python在科学计算中的地位和意义
随着科学技术的迅猛发展,科学计算在各个领域中扮演着愈发重要的角色。Python作为一种简洁、易学、功能强大的高级编程语言,逐渐成为科学计算领域中的瑰宝。Python语言不仅在通用软件开发中表现出色,同时也凭借其丰富的库和工具,在科学计算与数据分析领域大放异彩。Python作为一种通用编程语言,其优势包括灵活的应用范围、友好的学习曲线和强大的社区支持。在科学计算领域,Python更是因其丰富的库(如NumPy、Pandas、Matplotlib等)和强大的科学计算工具(如SciPy、SymPy等)而备受青睐。
## 1.2 Python在科学计算中的优势
Python在科学计算中具有诸多优势,其主要体现在以下几个方面:
- **丰富的库支持**:Python拥有大量专门为科学计算而设计的库,例如NumPy、Pandas、Matplotlib、Scikit-learn、TensorFlow等,这些库涵盖了数据处理、机器学习、可视化、深度学习等各个环节,为科学计算提供了强大的支持。
- **易学易用**:Python语法简洁清晰,易于上手和阅读,这使得科学研究人员能够更专注于问题的实质,而非编程细节。
- **开放性与灵活性**:Python是一种开源语言,拥有庞大的开发者社区与生态系统,用户可以方便地获得各种应用场景下的代码示例、解决方案和支持,从而提高工作效率。
总之,Python语言在科学计算中表现出色,其简单易用的特性以及丰富的库与工具支持,使其成为科学家、工程师和研究人员们的首选工具之一。
# 2. 数据处理与分析
数据处理与分析是科学计算中的重要部分,Python在这个领域有着丰富的库和工具,能够帮助科学家和工程师们处理和分析大量的数据。
#### 2.1 NumPy库的应用与实例
NumPy(Numerical Python)是Python科学计算的基础包。它是一个强大的N维数组对象,以及对数组进行运算的大量函数。NumPy并且提供了大量的数学函数库,用于对数组进行运算。
下面是一个使用NumPy库的简单例子,计算两个数组的和:
```python
import numpy as np
# 创建两个数组
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 计算数组的和
result = np.add(arr1, arr2)
print(result)
```
代码解释:
- 首先导入NumPy库,并使用`np`作为别名。
- 创建两个数组`arr1`和`arr2`。
- 使用`np.add`函数计算两个数组的和,并将结果打印出来。
运行以上代码,将得到输出结果`[5 7 9]`,即两个数组的对应元素相加的结果。
#### 2.2 Pandas库的应用与实例
Pandas是基于NumPy开发的一个数据处理和分析库,提供了高性能、易用的数据结构和数据分析工具。
下面是Pandas库的一个简单应用实例,读取CSV文件并展示数据:
```python
import pandas as pd
# 从CSV文件中加载数据
data = pd.read_csv('data.csv')
# 显示数据的前5行
print(data.head())
```
代码解释:
- 首先导入Pandas库,并使用`pd`作为别名。
- 使用`pd.read_csv`函数加载CSV文件中的数据。
- 使用`data.head()`方法显示数据的前5行。
以上代码将加载CSV文件中的数据,并输出前5行的数据。
#### 2.3 数据可视化库Matplotlib的使用案例
Matplotlib是Python中最常用的数据可视化库之一,用于绘制各种高质量的图表。
以下是一个简单的Matplotlib应用实例,绘制折线图:
```python
import matplotlib.pyplot as plt
# 准备数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 绘制折线图
plt.plot(x, y)
# 添加标题和标签
plt.title('Simple Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 显示图表
plt.show()
```
代码解释:
- 首先导入Matplotlib库,并使用`plt`作为别名。
- 准备数据`x`和`y`。
- 使用`plt.plot`方法绘制折线图。
- 添加标题和标签,并使用`plt.show()`显示图表。
以上代码将绘制出简单的折线图,并显示在屏幕上。
数据处理与分析是科学计算中的基础,NumPy、Pandas和Matplotlib等库为科学家和工程师们提供了强大的工具,帮助他们处理和分析数据。
# 3. 机器学习与人工智能
在科学计算中,机器学习和人工智能是热门的领域,Python提供了丰富的库和工具来支持这些应用。本章将介绍Python在机器学习和人工智能中的应用与实例。
#### 3.1 Scikit-learn库的应用与实例
Scikit-learn是一个使用Python语言开发的机器学习库,它建立在NumPy、SciPy和matplotlib之上,提供了丰富的机器学习算法和工具。下面是一个使用Scikit-learn库进行分类问题的示例代码:
```python
# 导入所需的库和模块
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载示例数据集
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型对象
model = KNeighborsClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集结果
y_pred = model.predict(X_test)
# 输出准确率
accuracy = (y_pred == y_test).mean()
print("准确率:", accuracy)
```
在上面的代码中,我们首先导入了所需的库和模块。然后,我们使用`datasets.load_digits()`加载了一个手写数字数据集,数据集包含了一系列手写数字的特征和对应的标签。接着,我们使用`train_test_split()`函数将数据集划分为训练集和测试集。然后,我们创建了一个`KNeighborsClassifier`模型对象,并使用`fit()`方法对模型进行训练。最后,我们使用训练好的模型对测试集进行预测,并计算准确率。
Scikit-learn提供了丰富的机器学习算法和模型评估方法,使得机器学习任务变得更加简单和高效。
#### 3.2 TensorFlow库在机器学习中的应用与实例
TensorFlow是一个开源的人工智能库,由Google开发,用于构建和训练各种机器学习模型。它具有强大的计算能力和灵活的架构,可以在各种硬件平台上高效地运行。下面是一个使用TensorFlow库构建一个简单神经网络的示例代码:
```python
# 导入所需的库和模块
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
# 加载示例数据集
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
# 数据预处理
X_train = X_train / 255.0
X_test = X_test / 255.0
# 划分验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
# 构建神经网络模型
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_val, y_val))
# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print('准确率:', test_acc)
```
在上面的代码中,我们首先导入了所需的库和模块。然后,我们使用`keras.datasets.mnist.load_data()`加载了一个手写数字数据集(MNIST数据集)。接下来,我们对图像数据进行预处理,将像素值缩放到0-1之间。然后,我们使用`train_test_split()`函数将训练集划分为训练集和验证集。接着,我们使用`keras.models.Sequential`类构建了一个简单的神经网络模型。模型包含了一个输入层(`Flatten`层),一个隐藏层(全连接层),和一个输出层(`Dense`层)。然后,我们使用`compile()`方法编译模型,指定优化器和损失函数。接下来,我们使用`fit()`方法对模型进行训练。最后,我们使用`evaluate()`方法评估模型在测试集上的性能。
TensorFlow不仅支持构建和训练神经网络模型,还提供了丰富的工具和库,用于各种机器学习和深度学习任务。
#### 3.3 Keras库在深度学习中的应用与实例
Keras是一个高级神经网络库,可以运行在TensorFlow、Theano和CNTK之上。它提供了简单而强大的API,用于构建和训练各种深度学习模型。下面是一个使用Keras库构建一个简单的卷积神经网络的示例代码:
```python
# 导入所需的库和模块
import numpy as np
from sklearn.model_selection import train_test_split
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 加载示例数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 数据预处理
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = np.squeeze(y_train)
y_test = np.squeeze(y_test)
# 划分训练集和验证集
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.1, random_state=42)
# 构建卷积神经网络模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu', padding='same'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu', padding='same'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val))
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print('准确率:', test_acc)
```
在上面的代码中,我们首先导入了所需的库和模块。然后,我们使用`cifar10.load_data()`加载了一个图片分类数据集(CIFAR-10数据集)。接下来,我们对图像数据进行预处理,将像素值缩放到0-1之间,并将标签数据进行调整。然后,我们使用`train_test_split()`函数将训练集划分为训练集和验证集。接着,我们使用`Sequential`类构建了一个简单的卷积神经网络模型。模型包含了多个卷积层、池化层、全连接层和输出层。然后,我们使用`compile()`方法编译模型,指定优化器和损失函数。接下来,我们使用`fit()`方法对模型进行训练。最后,我们使用`evaluate()`方法评估模型在测试集上的性能。
Keras提供了简洁而易用的API,使得深度学习模型的构建和训练变得更加简单和直观。
机器学习和人工智能正成为科学计算的重要组成部分,Python通过强大的库和工具提供了便捷的方式来实现这些应用,为科学计算提供了丰富的可能性。同时,随着技术的不断发展,Python在机器学习和人工智能领域的潜力和未来发展空间也将不断扩大。
以上是Python在机器学习与人工智能中的应用与实例。下一章将介绍Python在科学计算中的另一个重要应用领域--科学计算工具与库。
# 4. 科学计算工具与库
科学计算是复杂问题领域的关键部分,这就要求我们使用高效且功能强大的工具和库来进行计算和分析。Python提供了许多科学计算工具和库,使得科学计算变得更加简单和高效。本章将介绍几个常用的科学计算库和工具,并给出它们在实际应用中的示例。
### 4.1 SciPy库的功能介绍和应用案例
SciPy是一个开源的Python库,它建立在NumPy的基础上,提供了许多科学计算相关的功能和算法。下面是一些SciPy库的功能介绍和应用案例:
#### 4.1.1 最优化
SciPy的优化模块提供了许多优化算法,用于求解最小化或最大化问题。例如,我们可以使用SciPy库中的`minimize`函数来找到一个函数的最小值点。
```python
import numpy as np
from scipy.optimize import minimize
# 定义目标函数
def objective(x):
return x**2 + 10*np.sin(x)
# 使用minimize函数求解最小值点
result = minimize(objective, 0)
print(result.x) # 输出最小值点的值
```
#### 4.1.2 线性代数
SciPy提供了多种线性代数操作的函数,例如矩阵求逆、特征值分解、奇异值分解等。以下是一个求解线性方程组的例子:
```python
import numpy as np
from scipy.linalg import solve
# 定义系数矩阵
A = np.array([[3, 1], [1, 2]])
# 定义常数向量
b = np.array([9, 8])
# 求解线性方程组 Ax = b
x = solve(A, b)
print(x) # 输出解x
```
#### 4.1.3 数值积分
SciPy库中的积分模块提供了多种数值积分方法。以下是一个计算定积分的示例:
```python
from scipy.integrate import quad
# 定义被积函数
def integrand(x):
return x**2
# 计算定积分
result, error = quad(integrand, 0, 1)
print(result) # 输出定积分的结果
```
### 4.2 SymPy库在符号计算中的使用实例
SymPy是一个用于符号计算的Python库,它可以进行代数运算、微积分等符号计算操作。下面是SymPy库在符号计算中的一个使用实例:
```python
from sympy import Symbol, diff
# 定义符号变量x
x = Symbol('x')
# 求函数f(x) = x^2的导数
f_x = x**2
f_prime = diff(f_x, x)
print(f_prime) # 输出导数f'(x)
```
### 4.3 用Python进行高性能计算的工具集与优化技巧
Python虽然是一种动态解释型语言,但是我们仍然可以用一些技巧和工具来提高Python程序的性能。以下是一些用于高性能计算的工具和优化技巧:
- 使用NumPy库代替Python原生列表,因为NumPy库中的数组操作更高效。
- 使用Cython将Python代码转换为C语言,并使用Cython编译器编译,从而提高代码的执行速度。
- 使用并行计算库(如multiprocessing)来利用多核处理器进行并行计算,从而加速计算过程。
总结:本章介绍了几个常用的科学计算工具和库,在实际应用中起到了重要作用。通过使用这些工具和库,我们可以更加高效地进行科学计算和数据分析,从而加快问题解决的速度。此外,我们还介绍了一些用于高性能计算的工具和优化技巧,使得Python程序的运行速度更快。
# 5. 科学计算应用案例
科学计算在不同领域都有着广泛的应用,Python作为一种优秀的科学计算语言,也在各个领域展现出了强大的应用实例。下面将介绍Python在图像处理与计算机视觉、自然语言处理以及生物信息学中的具体应用案例。
#### 5.1 Python在图像处理与计算机视觉中的应用实例
图像处理与计算机视觉是科学计算领域中的重要应用方向,Python搭配着一系列优秀的库和工具,为图像处理和计算机视觉领域的研究和应用提供了便利。
以OpenCV库为例,我们来看一个简单的图像处理实例,将一张图片转换为灰度图并显示出来:
```python
import cv2
import matplotlib.pyplot as plt
# 读取图片
img = cv2.imread('example.jpg')
# 转换为灰度图
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示灰度图
plt.imshow(gray_img, cmap='gray')
plt.axis('off')
plt.show()
```
通过上述代码,我们成功将一张彩色图片转换为灰度图并显示出来。这展示了Python在图像处理方面的强大应用能力。
#### 5.2 Python在自然语言处理中的应用实例
自然语言处理是人工智能领域的重要分支之一,Python在自然语言处理领域也备受青睐,并且有着丰富的库和工具支持。例如,NLTK(Natural Language Toolkit)是Python中广泛使用的自然语言处理库之一。
下面是一个简单的使用NLTK库进行文本词频统计的示例:
```python
import nltk
from nltk import FreqDist
from nltk.corpus import gutenberg
# 从Gutenberg语料库中加载文本
emma = gutenberg.words('austen-emma.txt')
# 统计词频并按照频率降序排列
fdist = FreqDist(emma)
print(fdist.most_common(10))
```
通过以上代码,我们可以统计出《爱玛》这部小说中出现频率最高的前10个词汇,从而对文本进行简单的分析。这展示了Python在自然语言处理方面的丰富应用。
#### 5.3 Python在生物信息学中的应用实例
生物信息学是将计算机科学应用于生物学领域的交叉学科,Python在生物信息学中也有着广泛的应用。例如,Biopython是一个专门用于生物信息学的Python库,提供了丰富的工具和算法支持。
下面是一个简单的使用Biopython库进行序列比对的示例:
```python
from Bio import pairwise2
from Bio.Seq import Seq
# 定义两个DNA序列
seq1 = Seq("AGTACACTGG")
seq2 = Seq("AGTA")
# 进行全局序列比对
alignments = pairwise2.align.globalxx(seq1, seq2)
print(pairwise2.format_alignment(*alignments[0]))
```
通过以上代码,我们可以对两个DNA序列进行全局序列比对,并输出比对结果。这展示了Python在生物信息学领域的强大应用能力。
通过以上内容,我们可以看到Python在图像处理与计算机视觉、自然语言处理以及生物信息学等领域中的丰富应用案例,展现了其在科学计算领域中的广泛应用价值。
# 6. 结语
在科学计算领域,Python作为一门简单而强大的编程语言,拥有广泛的应用和丰富的库支持。本文介绍了Python在科学计算中的应用与实例,从数据处理与分析到机器学习与人工智能,再到科学计算工具与库以及实际应用案例,展示了Python在科学计算领域的强大能力。
6.1 Python在科学计算中的潜力与未来发展
Python在科学计算领域的潜力巨大。随着机器学习和人工智能的快速发展,Python在数据分析、模型训练等方面的优势得到了更多的认可。Python生态系统中涌现了众多强大的科学计算库和工具,为科学家和工程师提供了丰富的资源和支持。Python不仅在学术界得到了广泛应用,也在工业界得到了日益广泛的认可。
6.2 总结
本文提供了Python在科学计算中的应用与实例。从数据处理与分析到机器学习与人工智能,再到科学计算工具与库以及实际应用案例,展示了Python在科学计算领域的强大能力。Python的简洁易用、丰富的库支持和强大的社区共享精神使其成为科学计算的首选语言。随着Python生态系统的不断发展,Python在科学计算领域的前景将更加广阔。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《科学计算与数学模型构建》专栏涵盖了科学计算和数学模型构建领域的多个方面,旨在帮助读者掌握这一领域的基础知识和实践技能。从科学计算的基础入门,到Python和MATLAB在科学计算和数学模型构建中的应用与实例,再到数值计算方法、数据处理与分析技术,以及优化算法等内容,该专栏涵盖了广泛而深入的主题。此外,还包括了诸如机器学习算法、文本分析、图论、时间序列分析等领域的应用,展示了这些技术在数学模型构建中的重要性。无论是常微分方程数值解法,还是大规模数据集处理与并行计算技术,该专栏都力求为读者提供系统、全面的知识储备,同时注重实践应用和解决问题的能力培养。无论是科学研究者、工程师还是学生,都能从中受益,为科学计算和数学模型构建领域的发展贡献力量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
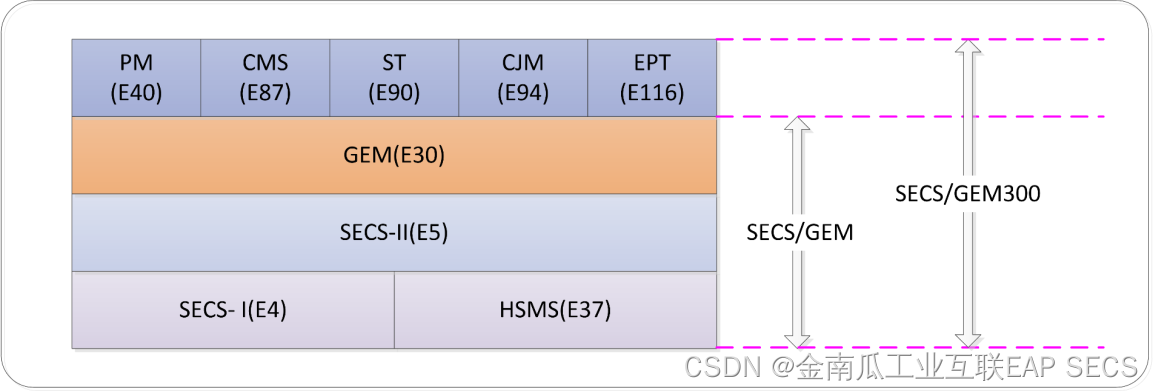
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )