使用Spark进行大规模数据的Diffusion分析
发布时间: 2024-02-24 00:26:11 阅读量: 27 订阅数: 28 

基于Spark的矢量大数据处理与分析项目
# 1. 简介
## 1.1 Diffusion分析的背景和意义
Diffusion分析是指研究信息、技术、产品等在社交网络或其他传播渠道中的传播过程和影响范围的分析方法。在当今信息爆炸的时代,了解和分析信息传播的规律对于市场营销、舆情分析、社交网络分析等领域具有重要意义。
## 1.2 Spark在大数据处理中的应用
Apache Spark是一种开源的大数据处理框架,具有高效的内存计算和容错机制,适用于大规模数据的处理和分析。Spark支持分布式计算,可以快速处理PB级别的数据,并通过优化的运行引擎实现高性能的数据处理。
## 1.3 本文的研究目的和方法
本文旨在探讨使用Spark进行大规模数据的Diffusion分析,结合Spark强大的计算能力和并行处理优势,实现对信息传播过程的深入分析。通过案例实践和实验验证,探讨Spark在Diffusion分析中的优势和挑战,为大规模数据处理和社交网络分析提供参考。
# 2. Spark简介和基础知识
Apache Spark 是一个开源的分布式计算系统,旨在提高大规模数据处理的速度和效率。它提供了丰富的API,支持多种编程语言,如Scala、Java、Python和R。Spark 的核心是基于内存的计算,可以在内存中快速对数据进行处理,从而加快计算速度。以下是关于 Spark 的一些基础知识:
### 2.1 Spark的特点和优势
- **快速性**:Spark 利用内存计算和弹性分布式数据集(RDD)的特性,在大规模数据处理任务中表现出色。
- **易用性**:Spark 提供简洁的API,支持多种语言,易于学习和使用。
- **灵活性**:Spark 支持多种数据处理模式,如批处理、流处理和机器学习,适用于各种场景。
- **扩展性**:Spark 可以方便地扩展到多个节点,实现分布式计算,处理大规模数据。
### 2.2 Spark的基本概念和架构
- **RDD(Resilient Distributed Dataset)**:弹性分布式数据集,是 Spark 中数据处理的基本单位,具有容错性和分布式特性。
- **Transformation(转换操作)**:基于现有数据集创建新的 RDD 的操作,如 map、filter、reduce 等。
- **Action(动作操作)**:触发实际计算并返回结果给驱动程序的操作,如 collect、count、saveAsTextFile 等。
- **Spark Core**:Spark 的核心模块,提供了 RDD 的 API 和基本功能。
- **Spark SQL**:用于处理结构化数据的模块,支持 SQL 查询和DataFrame API。
- **Spark Streaming**:用于实时流处理的模块,可以对实时数据流进行处理和分析。
- **Spark MLlib**:机器学习库,提供了常见的机器学习算法和工具。
### 2.3 Spark在大规模数据处理中的应用场景
- **批处理**:对大规模数据集进行批量处理和分析,如数据清洗、特征提取等。
- **实时流处理**:处理实时数据流,如日志分析、实时推荐等。
- **机器学习**:利用 Spark MLlib 进行机器学习模型的训练和预测。
- **图计算**:使用 GraphX 进行大规模图数据的处理和分析。
Spark 的强大功能和灵活性使其成为大规模数据处理的首选工具之一,为企业解决数据处理和分析难题提供了便利和效率。
# 3. 大规模数据的Diffusion分析方法
在大规模数据环境下进行Diffusion分析是一个复杂而重要的任务。本章将介绍Diffusion分析的基本概念,探讨Spark

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Diffusion技术"为主题,涵盖了多个与Diffusion相关的文章。其中包括使用R语言进行Diffusion模型建立与分析、扩散性传染病模型与Diffusion技术应用、利用Matlab进行多维Diffusion数据分析等内容。此外,还探讨了Diffusion技术在人工智能领域的前沿应用,以及使用Hadoop进行分布式Diffusion数据处理。最后,文章深入实用案例,分析了Diffusion技术在推荐系统中的应用。通过本专栏,读者将深入了解Diffusion技术的理论与实践应用,从而对该领域具有更深入的认识,并了解其在不同领域的广泛应用。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微信小程序HTTPS配置强化:nginx优化技巧与安全策略
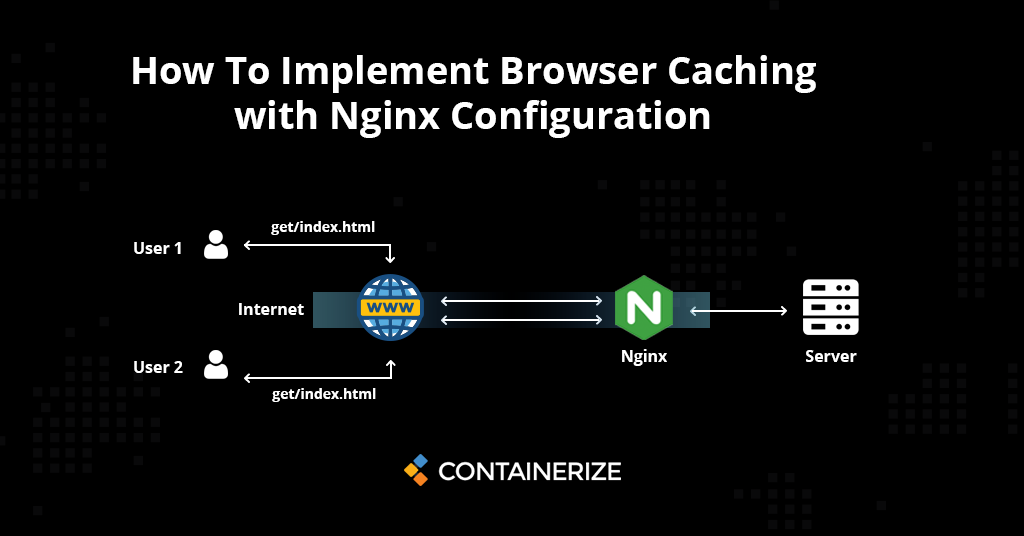
# 摘要
HTTPS协议在微信小程序中的应用是构建安全通信渠道的关键,本文详细介绍了如何在nginx服务器上配置HTTPS以及如何将这些配置与微信小程序结合。文章首先回顾了HTTPS与微信小程序安全性的基础知识,
FEKO5.5教程升级版

# 摘要
本文全面介绍了FEKO 5.5电磁仿真软件的各个方面,包括软件概览、基础操作、高级功能、特定领域的应用、案例研究与实践,以及对软件未来展望
【Catia轴线与对称设计】:4个案例揭秘对称性原理与实践

# 摘要
本文详细探讨了在Catia软件中轴线与对称设计的理论基础和实际应用。首先介绍了轴线的基本概念及其在对称设计中的重要性,随后阐述了几何对称与物理对称的差异以及对称性的数学表示方法。文章重点讨论了对称设计的原则与技巧,通过具体案例分析,展示了简单与复杂模型的对称设计过程。案例研究部分深入分析了轴对称的机械零件设计、汽车部件设
开阳AMT630H性能大揭秘:测试报告与深度评估
# 摘要
开阳AMT630H是一款先进的工业级自动测试设备,本文首先对其硬件架构及性能参数进行了介绍。通过理论性能参数与实际运行性能测试的对比,详细分析了其在不同工作负载下的性能表现以及能效比和热管理情况。此外,本文探讨了该设备在工业控制和智能家居系统的深度应用,并对用户体验与案例研究进行了评估。文章还展望了AMT630H的未来技术发展,并针对当前市场的挑战提出了评测总结和建议,包括性能评估、用户购买指南和
SSH密钥管理艺术:全面指南助你安全生成、分发和维护
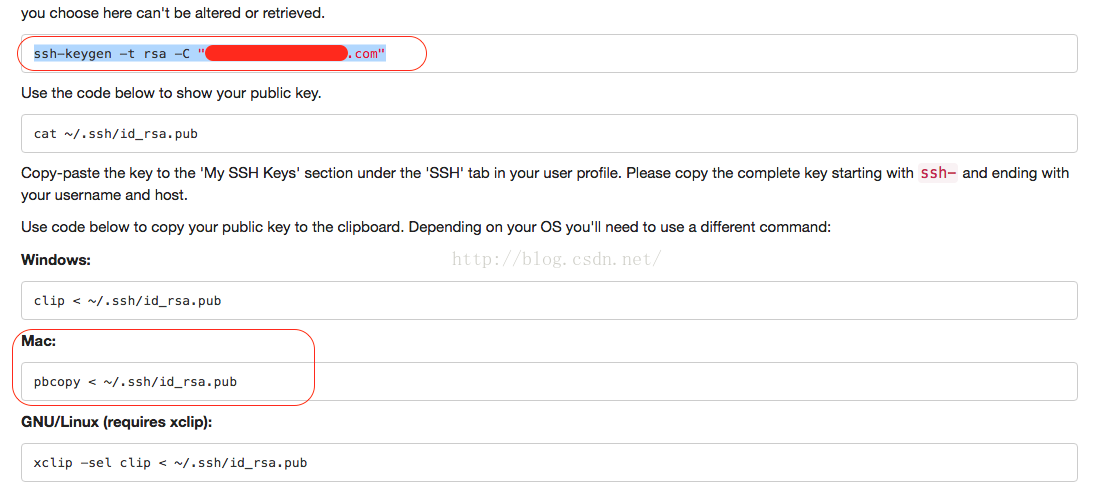
# 摘要
本文全面探讨了SSH密钥管理的各个方面,从基础概念到高级应用,深入解析了密钥生成的艺术、分发与使用、以及密钥的生命周期管理。文章强调了安全传输密钥的重要性,介绍了密钥管理自动化和集成密钥管理至CI/CD
【STM32F407 RTC防抖动与低功耗设计】:高级应用的必备技巧

# 摘要
本文全面探讨了STM32F407微控制器的实时时钟(RTC)功能及其在防抖动机制和低功耗设计中的应用。文章首先概述了RTC的基本功能和重要性,随后深入分析了防抖动设计的理论基础和实践案例。本研究涵盖了从硬件到软件的不同防抖动策略,以及优化RTC性能和可靠性的具体方法。同时,本文还着重介绍了低功耗设
【Excel VBA案例精讲】:中文转拼音功能在数据录入中的实战应用

# 摘要
本文以Excel VBA为工具,探讨了中文转拼音功能的实现及高级应用。首先介绍了VBA的基础知识和拼音转换的理论基础,随后详述了如何在Excel中实现该功能,包括用户界面设计、核心代码编写和代码整合。文章还探讨了如何通过VBA结合数据验证提升数据录入效率,并通过案例分析讲解了功能的实践应用。最后,文章讨论
【ODrive_v3.5散热问题】:驱动器效能的关键在于散热
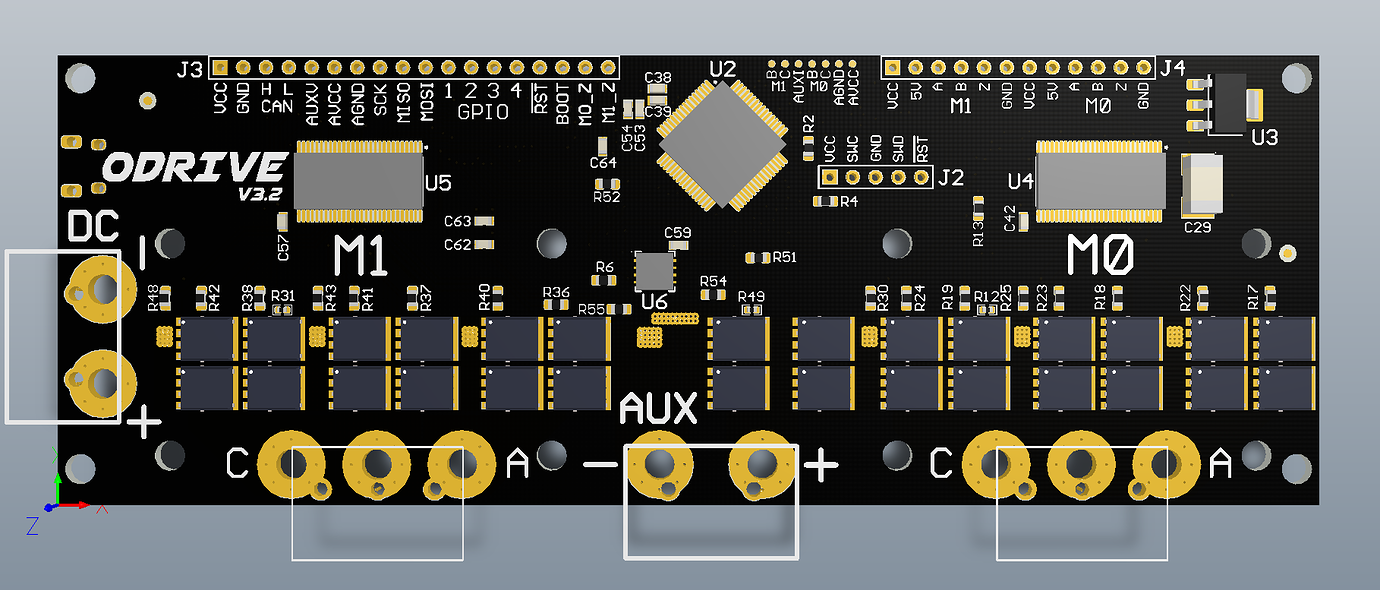
# 摘要
ODrive_v3.5散热问题是影响设备稳定运行的重要因素之一。本文首先概述了ODrive_v3.5散热问题的现状,然后详细介绍了散热的理论基础,包括热传递原理、散热器类型及散热系统设计原则。通过实践分析,本文探讨了散热问题的识别、测试以及解决方案的实际应用,并通过案例研究
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )