QTableView添加Checkbox示例 C++语言 - 实现树形结构
发布时间: 2024-03-29 18:46:53 阅读量: 51 订阅数: 44 

树结构示例C++程序
# 1. 简介
在本章中,我们将介绍如何在QTableView中添加Checkbox以实现树形结构的功能。首先,我们将简要介绍QTableView和Checkbox的基本概念,然后解释为什么在QTableView中使用Checkbox可以帮助实现树形结构。让我们一起来深入了解这一主题。
# 2. 准备工作
在开始实现在QTableView中添加Checkbox以实现树形结构之前,我们需要进行一些准备工作。这包括设置开发环境,导入所需的库以及创建一个新的项目并配置QTableView。
### 提供所需的C++开发环境和Qt库
首先,确保您已经安装了适用于C++的开发环境,如Visual Studio、Eclipse或者使用命令行编译器。另外,您也需要安装Qt库,可以从Qt官方网站下载并安装。Qt库提供了丰富的GUI组件,包括用于创建表格视图的QTableView。
### 创建一个新项目并配置QTableView
在您的集成开发环境中,创建一个新的C++项目。确保在项目中包含Qt库,并将QTableView添加到您的主窗口或对话框中。设置QTableView以显示您的数据,并确保您可以在其单元格中添加复选框。
准备工作完成后,我们可以开始实现在QTableView中添加Checkbox以实现树形结构的功能。
# 3. 实现Checkbox功能
在本章节中,我们将详细讨论如何编写代码以在QTableView中显示Checkbox,并确保Checkbox可以响应用户操作。
首先,我们需要在QTableView的单元格中显示Checkbox,这可以通过自定义委托实现。下面是一个示例代码,演示如何创建一个带有Checkbox的委托:
```python
class CheckboxDelegate(QStyledItemDelegate):
def __init__(self, parent=None):
super(CheckboxDelegate, self).__init__(parent)
def paint(self, painter, option, index):
checked = index.data(Qt.CheckStateRole)
check_box_style = QStyleOptionButton()
check_box_style.state = QStyle.State_Enabled | QStyle.State_Active
if checked == Qt.Checked:
check_box_style.state |= QStyle.State_On
else:
check_box_style.state |= QStyle.State_Off
check_box_style.rect = self.calculate_checkbox_rect(option)
QApplication.style().drawControl(QStyle.CE_CheckBox, check_box_style, painter)
def editorEvent(self, event, model, option, index):
if event.type() == QEvent.MouseButtonRelease:
state = index.data(Qt.CheckStateRole)
model.setData(index, Qt.Unchecked if state == Qt.Checked
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"QTableView添加Checkbox示例 C++语言"为主题,从简介与基本概念开始,逐步介绍如何通过创建基本工程、配置运行环境、设计数据模型,生成QTableView,并实现数据与Checkbox的绑定。读者将学习如何实现多选与全选功能,使用自定义代理,实现反选功能,美化界面样式表,处理数据更新与刷新,以及优化大数据量的性能。进一步还将探讨如何与数据库交互,实现排序功能,拖拽与重排序,持久化数据保存,嵌入自定义Widget,最终实现树形结构。无论是初学者还是有经验的开发者,都能从中获得丰富的知识和技巧,提升对QTableView及Checkbox的应用与理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微积分基础在算法优化中的应用:揭秘微积分在提升算法效率中的关键角色

# 摘要
本文系统介绍了微积分在现代算法优化中的广泛应用,重点探讨了微分学和积分学在提升算法效率和解决优化问题中的核
VC++项目实战:权威指南教你从理论跃升到实践

# 摘要
本文详细介绍了VC++开发环境的搭建及基础配置,深入探讨了C++的核心编程理论与技巧,包括语法基础、面向对象编程以及标准模板库(STL)的应用。结合实战技巧与实践,文章还分析了Windows编程基础、MFC框架开发以及多线程编程等高级技术,旨在提高开发效率和软件性能。通过案例分析与实现章节,探讨了企业级应用
【MySQL表格创建秘籍】:3大技巧提升数据库设计效率

# 摘要
本论文主要探讨了MySQL数据库表格创建的理论和实践技巧,旨在提供一套完整的表格设计与优化方案。首先,本文回顾了表格创建的理论基础,并介绍了设计表格时的三大基础技巧:精确选择数据类型、优化索引策略以及理解和应用规范化规则。随后,文章深入探讨了表格创建的高级技巧,包括字段默认值与非空约束的应用、分区管理的好处以及触发器和存储过程的高效运用。进阶应用与优化章节分析
【硬件DIY指南】:用CH341A构建个性化电子工作台

# 摘要
本文全面介绍了硬件DIY的基础知识,并详细阐述了CH341A芯片的理论基础、编程原理及其在实际应用中的使用方法。首先概述了CH341A的功能特点和与计算机的通信机制,接着介绍了固件编程的基本原理、环境搭建和常见技术,以及驱动安装与调试的过程。文章第三章着重讲述了如何利用CH341A构建电子工作台,包括组件选择、工作台搭建、电路编程和
【T型与S型曲线规划】:从理论到实践的8个实用技巧
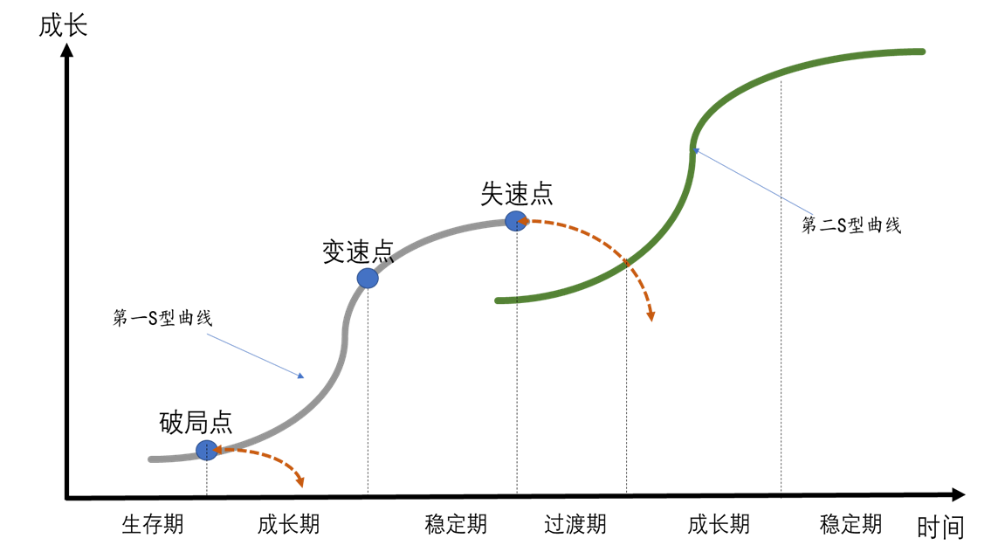
# 摘要
本文对T型与S型曲线规划进行了全面的概述与深入分析,首先介绍了T型与S型曲线规划的基本概念及历史背景,强调了它们在项目管理中的应用与重要性。随后,本文深入探讨了两种曲线的数学模型构建原理以及关键参数的计算,为曲线规划提供了坚实的理论基础。文章还详细阐述了T型与S型曲线规划在实际项目中的应用技巧,包括案例研究和风险评估。此外,本文介绍了当前曲线规划相关的工具与方法,并探讨了其在复杂项目
KS焊线机工作原理深度解析:精密焊接的科学与艺术
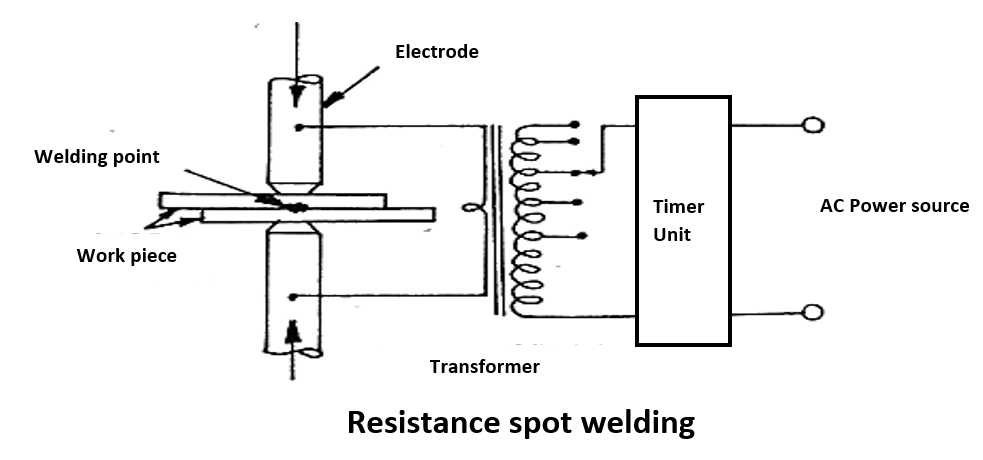
# 摘要
KS焊线机作为精密焊接技术的代表性设备,本文对其工作原理、硬件构成、核心技术、应用实践以及性能优化与故障排除进行了全面分析。首先概述了KS焊线机的工作原理和硬件构造,接着深入探讨了精密焊接技术的理论基础和核心工艺参数。文中还着重介绍了KS焊线机在电子制造业中的应用,以及针对不同焊接材料和条件的解决方案。此外,本文分析了KS焊线机性能优化的方法,包括
【Magisk青龙面板终极指南】:精通安装、配置与高级优化技巧

# 摘要
本文详细介绍了Magisk和青龙面板的安装、配置以及集成优化,提供了从基础设置到高级功能应用的全面指导。通过分析Magisk的安装与模块管理,以及青龙面板的设置、维护和高级功能,本文旨在帮助用户提升Android系统的可定制性和管理服务器任务的效率。文章还探讨了两者的集成优化,提出了性能监控和资源管理的策略,以及故障诊断和优化措施。案例研究部分展示了
PMC-33M-A Modbus通信实战指南:高效连接与数据交换技巧
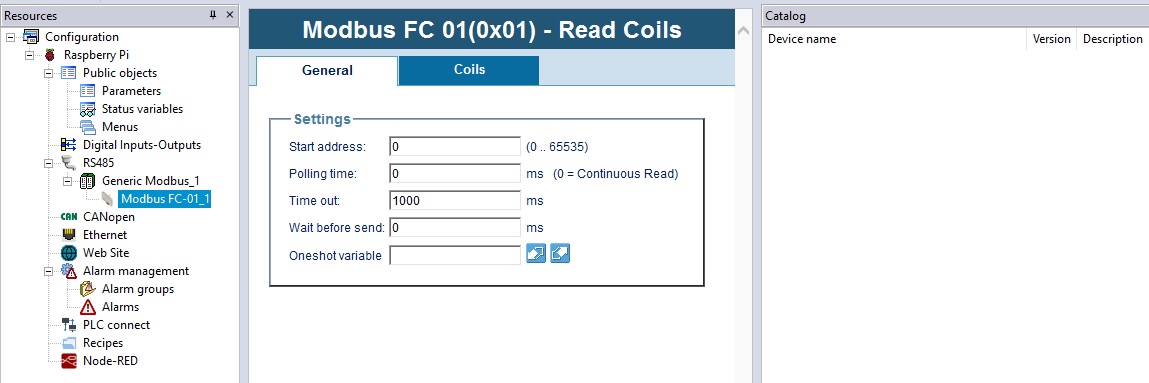
# 摘要
本文深入探讨了Modbus通信协议及其在PMC-33M-A硬件中的应用。首先概述了Modbus协议的基本概念,并对PMC-33M-A的硬件特性、连接指南以及软件配置进行了介绍。接着,本文详细分析了Modbus数据帧格式、功能码操作及数据交换的同步与异步模式。在实战应用技巧章节,文章提供了提高数据读写效率、实时监控数据处理和系统集成优化的技巧。最后,通过高级应用案例分析,
【Java加密演进之路】:从BCprov-jdk15on-1.70看安全性提升与实践案例

# 摘要
Java加密技术是现代网络安全领域的重要组成部分,其中BCprov-jdk15on-1.70加密库提供了丰富的加密和哈希算法,以及密钥管理和安全
【矿用本安电源元器件选择】:解读关键参数与应用指南
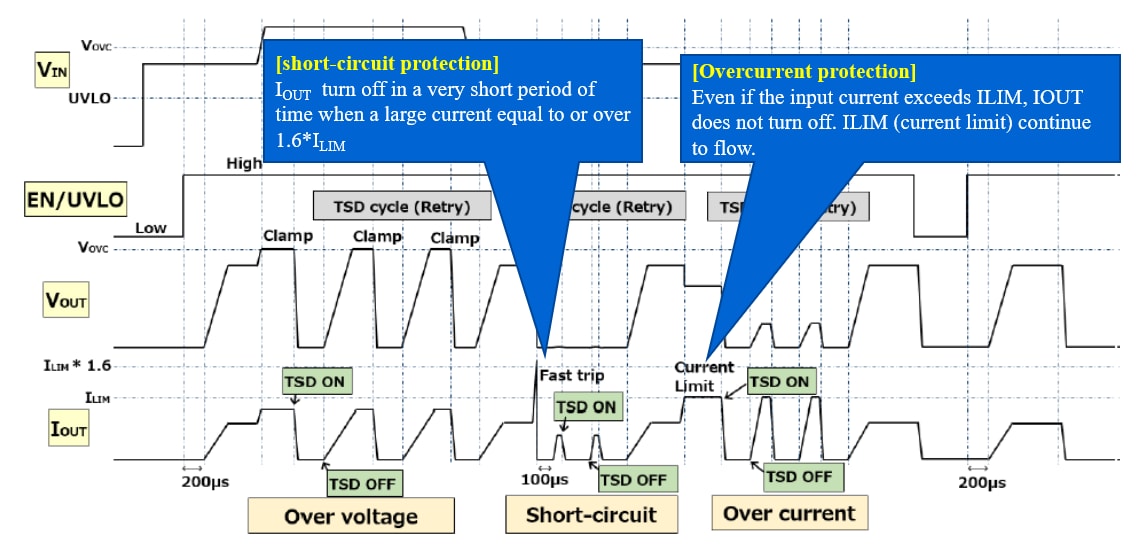
# 摘要
本安电源作为煤矿等易燃易爆环境中不可或缺的电源设备,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )