HTTP报文结构与解析
发布时间: 2024-01-11 07:48:04 阅读量: 50 订阅数: 41 

http报文解析
# 1. 介绍HTTP协议和报文的基本概念
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的应用层协议,它是互联网的基础协议之一。HTTP基于TCP/IP协议栈,通过可靠的传输机制,在客户端和服务器之间进行通信。HTTP协议使用请求-响应模式,客户端发送HTTP请求,服务器处理请求并返回HTTP响应。
HTTP报文是HTTP通信中的基本单位,它用于在客户端和服务器之间传输数据。HTTP报文分为请求报文和响应报文两种类型。
请求报文由客户端发送给服务器,用于描述客户端的需求。在请求报文中,包含了请求行、请求头部和请求主体。
响应报文由服务器发送给客户端,用于回应客户端的请求。在响应报文中,包含了状态行、响应头部和响应主体。
HTTP报文的结构如下所示:
```
<start line>
<headers>
<blank line>
<entity body>
```
其中,每一部分的具体内容和结构如下所述:
## 2. HTTP报文的结构和组成部分
### 2.1 请求报文的结构和字段
请求报文的结构如下所示:
```
<Method> <Request-URI> <HTTP-Version>
<headers>
<blank line>
<message-body>
```
- `Method`表示请求方法,常见的方法有GET、POST、PUT、DELETE等,用于指示服务器对资源的操作类型。
- `Request-URI`指定了请求的资源的位置。它可以是一个绝对URL,也可以是一个相对URL。
- `HTTP-Version`指定了使用的HTTP协议版本。
除了上述基本字段,请求报文还可以包含多个请求头部字段,用于携带额外的信息。常见的请求头部字段有`Host`、`User-Agent`、`Content-Type`等。
### 2.2 响应报文的结构和字段
响应报文的结构如下所示:
```
<HTTP-Version> <Status-Code> <Reason-Phrase>
<headers>
<blank line>
<message-body>
```
- `HTTP-Version`指定了服务器使用的HTTP协议版本。
- `Status-Code`表示服务器对请求的处理结果,常见的状态码有200表示成功,404表示未找到资源,500表示内部服务器错误等。
- `Reason-Phrase`是对状态码的简要解释。
与请求报文类似,响应报文也可以包含多个响应头部字段,常见的响应头部字段有`Content-Type`、`Content-Length`、`Server`等。
### 2.3 报文头部字段的含义和用途
报文头部字段用于携带附加的信息,包括请求和响应的各种元数据。常见的报文头部字段有:
- `Content-Type`指定了报文主体的类型。常见的类型有text/plain、application/json、image/png等。
- `Content-Length`指定了报文主体的长度。
- `Host`指定了服务器的主机名和端口号。
- `User-Agent`指定了发起请求的用户代理,如浏览器类型和版本。
- `Server`指定了响应的服务器软件。
报文头部字段的具体使用和含义,可以根据实际需要进行设置。
### 2.4 报文主体的格式和传输方式
报文主体是HTTP报文中可选的部分,用于携带实际的数据。报文主体的格式和传输方式可以根据需要来定义。
常见的报文主体格式有:
- 文本格式:如JSON、XML、HTML等。
- 二进制格式:如图片、视频、音频等。
报文主体的传输方式可以通过多种方式实现,常见的传输方式有:
- 普通文本传输:直接将报文主体作为字符串传输。
- 基于Content-Encoding的压缩传输:将报文主体进行压缩后传输。
- 分片传输:将报文主体分成多个片段传输。
根据实际需求,可以选择合适的报文主体格式和传输方式。
以上是HTTP协议和报文的基本概念和组成部分。接下来,我们将详细介绍HTTP请求报文的解析过程。
# 2. HTTP报文的结构和组成部分
HTTP报文是HTTP协议中用于客户端与服务器之间通信的载体。它由请求报文和响应报文组成。
#### 2.1 请求报文的结构和字段
请求报文由请求行、请求头部和请求主体三个部分组成。
**2.1.1 请求行**
请求行包含了请求方法、请求URL和HTTP协议版本三个字段,它们之间用空格分隔。
```http
GET /index.html HTTP/1.1
```
请求方法表示对资源的具体操作,常见的有GET、POST、PUT、DELETE等。请求URL是要访问的资源路径,HTTP协议版本是指使用的HTTP协议的版本号。
**2.1.2 请求头部**
请求头部由多个字段组成,每个字段都包含了字段名和字段值。字段名和字段值之间使用冒号分隔,每个字段占据一行。
```http
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Content-Type: application/json
```
常见的请求头部字段有:
- Host:请求的主机名
- User-Agent:浏览器或客户端的信息
- Content-Type:请求主体的数据类型
- Accept:客户端能够接受的响应数据类型
- Authorization:请求的身份认证信息
**2.1.3 请求主体**
请求主体是可选的,通常用于传输一些需要提交的数据,比如表单数据或JSON数据。
```http
POST /api/login HTTP/1.1
Content-Type: application/x-www-form-urlencoded
username=admin&password=123456
```
请求主体的格式和传输方式需要与Content-Type字段中指定的数据类型相对应。
#### 2.2 响应报文的结构和字段
响应报文由状态行、响应头部和响应主体三个部分组成。
**2.2.1 状态行**
状态行包含了HTTP协议版本、状态码和状态消息三个字段,它们之间用空格分隔。
```http
HTTP/1.1 200 OK
```
HTTP协议版本是指服务器使用的HTTP协议的版本号,状态码表示服务器对请求的处理结果,状态消息是对状态码的简要描述。
**2.2.2 响应头部**
响应头部与请求头部类似,由多个字段组成,每个字段都包含了字段名和字段值。
```http
Content-Type: text/html; charset=utf-8
Content-Length: 1024
Server: Apache/2.4.43 (Win64) OpenSSL/1.1.1g PHP/7.4.6
```
常见的响应头部字段有:
- Content-Type:响应主体的数据类型
- Content-Length:响应主体的长度
- Server:服务器的软件信息
- Set-Cookie:设置响应的Cookie
**2.2.3 响应主体**
响应主体包含了服务器返回的具体数据,它可以是HTML文档、JSON数据、图片等。
```http
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
<!DOCTYPE html>
<html>
<head>
<title>Welcome to my website</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
```
#### 2.3 报文头部字段的含义和用途
报文头部字段用于承载一些额外的信息,以指导和控制请求和响应的处理过程。
- Host字段用于指定请求的目标主机名
- User-Agent字段用于标识请求的客户端信息
- Content-Type字段用于指示请求或响应主体的数据类型
- Accept字段用于指示客户端能够接受的响应数据类型
- Authorization字段用于请求的身份认证信息
#### 2.4 报文主体的格式和传输方式
报文主体的格式和传输方式取决于报文头部字段中Content-Type的值。
- text/html:HTML文档,使用HTML标记语言编写的网页
- application/json:JSON数据,用于交换数据的轻量级数据格式
- multipart/form-data:表单数据,用于文件上传
- application/x-www-form-urlencoded:URL编码的表单数据,用于通过URL传输数据
- application/octet-stream:二进制数据流,用于传输文件等二进制数据
传输方式可以是通过HTTP协议直接传输,也可以使用HTTPS进行加密传输。
以上是HTTP报文的结构和组成部分的介绍。在实际开发和调试中,理解HTTP报文的结构和字段含义对排查和解决问题非常重要。在接下来的章节中,将进一步介绍HTTP请求报文的解析过程和HTTP响应报文的解析过程。
# 3. HTTP请求报文的解析过程
HTTP请求报文是客户端发送给服务器的数据,用于请求某个资源或执行某个操作。解析HTTP请求报文的过程可以分为请求行的解析、请求头部的解析、请求主体的解析以及URL的编码和解码等部分。
#### 3.1 请求行的解析
请求行由请求方法、请求目标和HTTP版本号组成,格式如下:
```http
请求方法 请求目标 HTTP版本号
```
请求方法定义了客户端希望服务器执行的操作,常见的请求方法有:
- GET:获取资源
- POST:提交数据
- PUT:更新资源
- DELETE:删除资源
请求目标是一个统一资源标识符(URL),表示客户端希望操作的资源。
HTTP版本号指明了客户端使用的HTTP协议版本。
通过解析请求行,可以获得客户端的请求方法、请求目标和HTTP版本号等信息。
#### 3.2 请求头部的解析
请求头部包含了客户端向服务器传递的一些附加信息,以键值对的形式表示。常见的请求头部字段有:
- Accept:指定客户端可以接受的响应类型
- Content-Type:指定请求主体的媒体类型
- User-Agent:标识客户端的信息,比如浏览器类型和版本号
通过解析请求头部,可以获取客户端传递的附加信息,以便服务器做出相应的处理。
#### 3.3 请求主体的解析
请求主体包含了客户端发送给服务器的具体数据,比如表单提交的内容或上传的文件等。根据请求头部中的Content-Type字段,可以确定请求主体的格式和解析方式。
对于普通的表单提交,请求主体通常以键值对的形式进行编码,可以使用URL编码或多部分形式(multipart/form-data)进行传输。解析请求主体时,需要根据Content-Type进行相应的解码操作,以获取实际的数据。
#### 3.4 URL编码和解码
URL编码和解码用于在URL中传递特殊字符和非ASCII字符。URL编码将特殊字符转换成%加十六进制值的形式进行传输,URL解码则将编码后的字符串还原成原始字符。
在HTTP请求中,URL编码和解码通常在请求目标和请求参数中使用。解析HTTP请求时,需要对URL进行解码,以获取正确的请求目标和参数信息。
以下是用Python示例代码演示HTTP请求报文的解析过程:
```python
import urllib.parse
def parse_request(request):
# 解析请求行
request_line = request.split('\r\n')[0]
method, target, http_version = request_line.split(' ')
# 解析请求头部
headers = {}
for line in request.split('\r\n')[1:]:
if line:
key, value = line.split(': ')
headers[key] = value
# 解析请求主体
body = request.split('\r\n\r\n')[1]
# URL解码
target = urllib.parse.unquote(target)
return {
'method': method,
'target': target,
'http_version': http_version,
'headers': headers,
'body': body
}
# 示例请求报文
request = '''POST /login HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
username=foo&password=bar'''
parsed_request = parse_request(request)
print(parsed_request)
```
代码解析了一个示例的HTTP请求报文,将请求行的方法、目标和HTTP版本号,请求头部的字段和值,请求主体以及URL解码后的请求目标等信息解析并封装到一个字典中。最后打印出解析结果。
这样的解析过程可以帮助开发人员理解HTTP请求的组成部分,并可以根据实际需求进行相应的处理和操作。
# 4. HTTP响应报文的解析过程
HTTP响应报文是服务器向客户端返回的数据。它由状态行、响应头部和响应主体组成。在接收到响应报文后,客户端会对其进行解析以获取所需的数据。
### 4.1 状态行的解析
HTTP响应报文的状态行包含了HTTP版本、状态码和状态短语。状态码用于表示服务器响应的状态,常见的状态码有200表示成功,404表示资源未找到,500表示服务器内部错误等。
对于客户端来说,解析状态行的过程主要是解析状态码,并根据状态码进行相应的处理。而对于服务器来说,解析状态行的过程则是在生成响应报文时设置好状态码和状态短语。
以下是一个基于Java的例子,演示了如何解析状态行:
```java
import java.net.HttpURLConnection;
public class HttpResponseParser {
public static void parseStatusLine(HttpURLConnection connection) {
try {
int statusCode = connection.getResponseCode();
String statusMessage = connection.getResponseMessage();
// 打印状态码和状态短语
System.out.println("Status Code: " + statusCode);
System.out.println("Status Message: " + statusMessage);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// 假设已建立HTTP连接
HttpURLConnection connection = ...;
// 调用解析状态行的方法
parseStatusLine(connection);
}
}
```
此代码演示了如何使用Java的`HttpURLConnection`类获取响应的状态码和状态短语。通过`getResponseCode()`方法可以获得状态码,通过`getResponseMessage()`方法可以获得状态短语。
### 4.2 响应头部的解析
HTTP响应报文的头部包含了丰富的信息,如服务器类型、内容类型、日期、内容长度等。在解析响应头部的过程中,客户端可以通过读取头部字段来获取这些信息。
以下是一个基于Python的例子,演示了如何解析响应头部:
```python
import requests
response = requests.get("https://www.example.com")
# 遍历响应的头部字段
for key, value in response.headers.items():
print(key + ": " + value)
```
上述代码使用了Python的requests库发送了一个HTTP GET请求,并接收到了一个响应对象。通过访问响应对象的`headers`属性,可以获得一个字典,其中包含了所有的头部字段和对应的值。通过遍历这个字典,我们可以逐个打印出头部字段的名称和值。
### 4.3 响应主体的解析
HTTP响应报文的主体部分包含了实际的数据。在解析响应主体时,客户端根据报文头部中的一些字段(如Content-Type)来确定如何解析和处理主体数据。
以下是一个基于Go的例子,演示了如何解析响应主体:
```go
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
response, _ := http.Get("https://www.example.com")
// 读取响应主体的内容
body, _ := ioutil.ReadAll(response.Body)
// 打印主体内容
fmt.Println(string(body))
}
```
上述代码使用了Go的net/http包发送了一个HTTP GET请求,并接收到了一个响应对象。通过访问响应对象的`Body`属性,可以获得一个可读取的流。通过使用ioutil包的`ReadAll()`函数,我们将整个响应主体读取出来并以字符串的形式打印出来。
### 4.4 响应状态码的含义和分类
HTTP响应报文的状态码用于表示服务器处理请求的结果。状态码分为五类,分别以不同的数字开头。
- 1xx:信息性状态码,表示请求已被接收,需要继续处理。
- 2xx:成功状态码,表示请求已成功被服务器接收、理解和处理。
- 3xx:重定向状态码,表示需要进一步的操作,常用于网页跳转等场景。
- 4xx:客户端错误状态码,表示客户端发送的请求有错误。
- 5xx:服务器错误状态码,表示服务器在处理请求时发生了错误。
常见的状态码包括200 OK(请求成功)、404 Not Found(资源未找到)、500 Internal Server Error(服务器内部错误)等。
通过解析响应报文中的状态码,客户端可以根据不同的状态码来进行相应的处理,例如重试请求、重新定位、显示错误信息等。对于服务器端,通过设置不同的状态码,可以告知客户端请求的处理结果。
以上是关于HTTP响应报文的解析过程的简要介绍。在实际开发中,需要根据具体的情况对报文进行更加详细和准确的解析和处理。
# 5. HTTP报文的常见问题与调试技巧
在实际的网络通信中,HTTP报文可能会出现各种问题,包括结构错误、编码问题、性能优化和安全性等方面。针对这些常见问题,我们需要掌握一些调试技巧和解决方案。
#### 5.1 常见报文结构错误的诊断和修复
HTTP报文结构错误可能导致服务器无法正确解析请求或客户端无法正确处理响应,常见的报文结构错误包括:
- 缺少请求行、状态行或报文头部
- 报文头部字段格式错误
- 报文主体与报文头部不符
针对这些问题,我们可以通过使用HTTP请求/响应分析工具(例如Wireshark、Fiddler等)来捕获网络数据包,分析报文结构是否符合HTTP协议标准。同时,可以借助HTTP请求/响应库(例如requests、http.client等)来模拟发送请求和解析响应,进而诊断和修复报文结构错误。
```python
import requests
# 模拟发送请求
response = requests.get('https://www.example.com')
# 输出响应报文
print(response.text)
```
#### 5.2 报文编码和解码问题的处理
在实际应用中,由于字符编码的差异或者特殊字符的处理,可能会导致HTTP报文在传输或解析过程中出现编码和解码问题。为了避免这些问题,我们可以使用URL编码/解码和字符编码转换工具来处理报文中的特殊字符和编码方式,保证报文在传输和解析时能够正确处理。
```python
import urllib.parse
# 对URL进行编码
encoded_url = urllib.parse.quote('https://www.example.com/index.html')
# 对URL进行解码
decoded_url = urllib.parse.unquote(encoded_url)
```
#### 5.3 报文的大小和性能优化
大型的HTTP报文可能会影响网络传输的性能和耗费资源,因此需要进行报文大小和性能优化。常见的优化技巧包括使用HTTP压缩和分块传输编码、减少不必要的报文头部字段、合并多个小请求等方式来优化报文的大小和传输性能。
```python
import requests
# 使用HTTP压缩来优化报文大小
response = requests.get('https://www.example.com', headers={'Accept-Encoding': 'gzip, deflate'})
```
#### 5.4 报文的安全性和防护措施
在HTTP通信过程中,需要关注报文的安全性和防护措施,包括防止劫持、伪造请求、跨站脚本攻击(XSS)、跨站请求伪造(CSRF)等安全威胁。针对这些问题,可以通过使用HTTPS加密通信、使用安全的Cookie属性、实施安全的身份认证等方式来加强报文的安全性和防护措施。
综上所述,对于HTTP报文的常见问题,我们可以通过分析报文结构、处理编码问题、优化报文性能和加强安全防护来保障HTTP通信的稳定和安全。
# 6. HTTP报文的新发展和未来趋势
随着互联网的不断发展,HTTP协议作为Web通信的基础协议也在不断演进,适应着新的需求和挑战。本章将介绍HTTP报文的新发展和未来趋势,包括HTTP/2、HTTP/3以及报文传输的加密和认证方案,以及报文的自动化和智能化处理技术。
#### 6.1 HTTP/2报文结构的改进和优势
HTTP/2作为HTTP/1.x的替代协议,在报文结构上进行了一系列的改进和优化,主要包括以下几点:
- **二进制分帧层**:HTTP/2采用二进制分帧层,将所有传输的信息分割为更小的消息和帧,实现了多路复用,可以在一个TCP连接上并行交错的请求和响应,避免了HTTP/1.x中的队头阻塞问题。
- **首部压缩**:HTTP/2使用HPACK算法对报文头部进行压缩,减少了报文头部的大小,降低了网络带宽的消耗。
- **服务端推送**:服务器可以在客户端的请求之前将相应的资源主动推送给客户端,减少了额外的客户端请求延迟。
- **流的优先级**:HTTP/2引入了流的概念,可以对不同的HTTP请求设置优先级,提高了资源请求的灵活性和效率。
#### 6.2 HTTP/3报文的变化和特性
HTTP/3是基于QUIC协议的新一代HTTP协议,与之前的HTTP协议相比,有以下变化和特性:
- **基于UDP传输**:HTTP/3使用QUIC协议,基于UDP传输数据,相比于TCP有更低的连接建立和传输延迟,尤其在移动网络下表现更优秀。
- **拥塞控制**:HTTP/3内置了拥塞控制机制,能够更好地适应网络状况的变化,提供更稳定和高效的传输性能。
- **0-RTT握手**:支持0-RTT连接建立,可以在保证安全性的前提下实现更快的连接建立与数据传输。
#### 6.3 报文传输的加密和认证方案
随着网络安全问题的日益突出,报文传输的加密和认证变得尤为重要。传统的HTTP报文通过明文传输,容易被窃听和篡改,因此加密和认证技术的应用变得至关重要。现阶段主流的加密和认证方案包括:
- **TLS/SSL协议**:通过传输层加密协议(TLS)或其前身安全套接层协议(SSL),对HTTP报文进行加密传输,保障通信的安全性和隐私性。
- **数字证书**:使用数字证书对服务器和客户端进行身份认证,防止中间人攻击和伪造身份。
#### 6.4 报文的自动化和智能化处理技术
随着人工智能和大数据技术的发展,报文处理也开始向自动化和智能化方向发展,包括但不限于:
- **智能路由**:基于报文内容和网络状态进行智能路由,提高数据传输的效率和稳定性。
- **智能压缩**:利用机器学习等技术,对报文进行智能压缩,减少网络传输的开销。
- **自动化性能优化**:通过大数据分析报文传输过程中的性能问题,实现自动化的性能优化和调试。
综上所述,HTTP报文的新发展和未来趋势主要体现在协议本身的优化,传输安全性和稳定性的提升,以及报文处理技术的自动化和智能化,这些技术变革为Web通信的效率和安全带来了新的可能性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了HTTP通信协议和URLConnection的相关知识。文章包括HTTP通信协议的简介、URL和URI的概念与用法、HTTP状态码的初步理解、HTTP请求方法的解析、HTTP请求头和响应头的解析、HTTP报文的结构和解析等内容。同时还介绍了如何使用Java实现简单的HTTP请求、处理HTTP重定向和请求重试、进行HTTP持久连接和连接池管理以及了解HTTP缓存机制。此外,还介绍了使用URLConnection进行POST请求、处理HTTP响应的重定向和错误、使用URL类处理URL编码和解码、HTTP代理的使用与原理、HTTPS和SSL_TLS的基本原理、SSL证书和HTTPS连接的建立过程、Java实现HTTPS请求以及HTTP_2和SPDY协议的介绍、HTTP_2的多路复用和头部压缩等内容。该专栏覆盖了HTTP通信协议和URLConnection的各个方面,旨在帮助读者深入理解和运用相关知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【调试达人】:Eclipse中JFreeChart图表生成的高效调试技巧

# 摘要
本文详细介绍了Eclipse集成开发环境中使用JFreeChart生成、调试和优化图表的方法。首先概述了JFreeChart图表生成的基本原理和结构,然后深入探讨了如何在Eclipse中搭建调试环境、诊断和解决图表生成过程中的常见问题。文章还涉及了图表定制化、复杂数据集展示和交互功能实现的实战应用,以及如何进行代码重构
性能提升秘籍:Vector VT-System测试效率的关键优化步骤
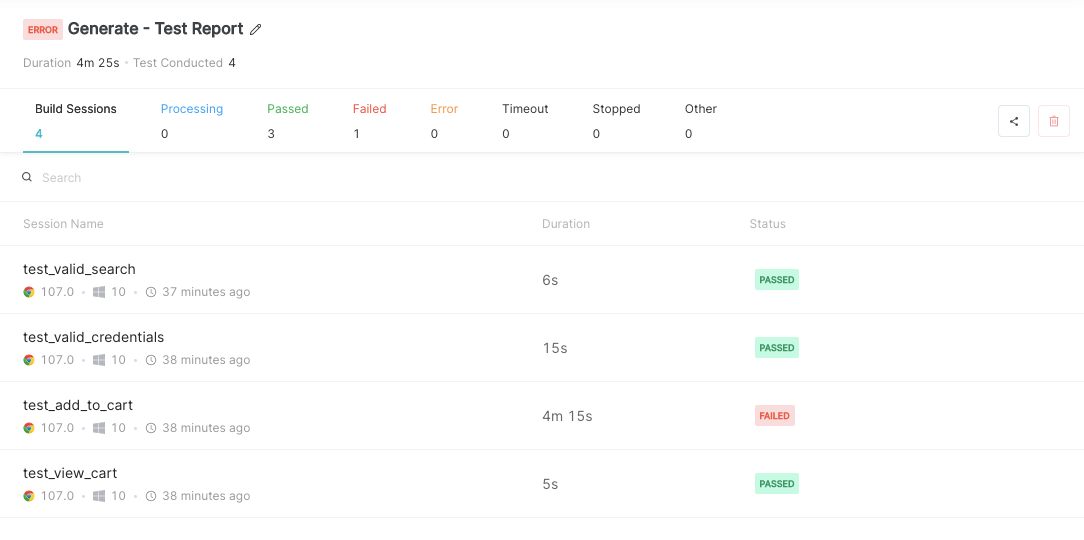
# 摘要
随着软件和系统的日益复杂化,性能测试成为确保产品质量和系统稳定性的关键环节。本文系统地介绍了Vector VT-System在性能测试中的应用,从基础理论出发,探讨了性能测试的目标与意义、类型与方法,并提供了性能测试工具的选择与评估标准。进一步深入配置与优化VT-System测试环境,包括测试环境搭建、测试脚本开发
揭秘混沌通信:DCSK技术如何革命性提升无线网络安全(权威技术指南)
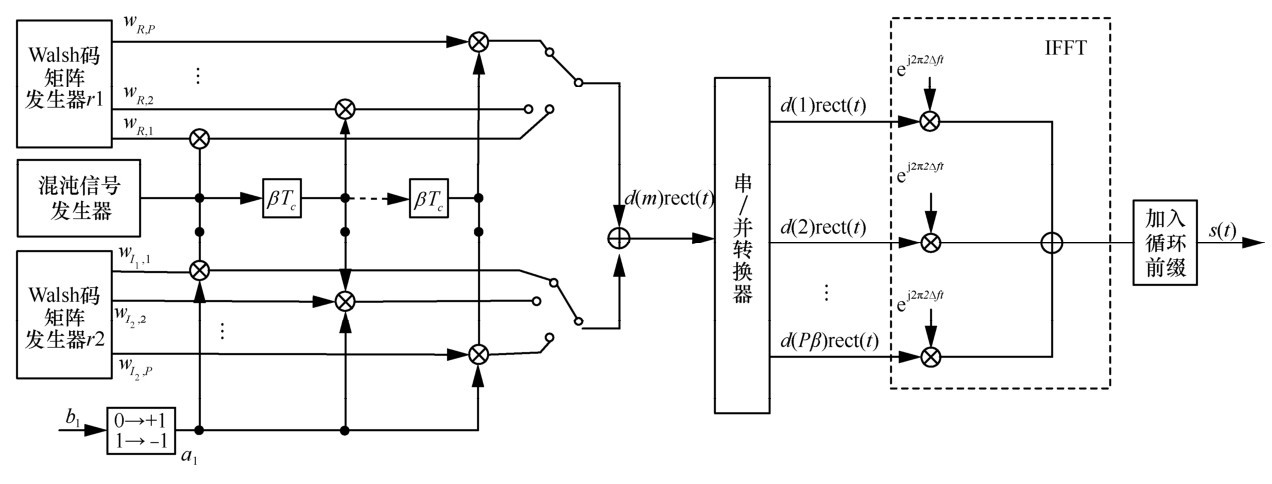
# 摘要
混沌通信作为一门新兴技术,其基础理论与应用在信息安全领域日益受到关注。本文首先介绍了混沌通信的基础知识,然后深入解析直接序列混沌键控(DCSK)技术,探讨其理论基础、关键技术特性以及在无线网络中的应用。接着,文章着重分析了DCSK技术的实现与部署,包括硬件设计、软件编程以及网络部署和测试。此外,本文还讨论了DC
【故障排除必备】:RRU和BBU问题诊断与解决方案

# 摘要
本文重点探讨了无线通信系统中的射频拉远单元(RRU)和基带处理单元(BBU)的故障排除方法。文章首先介绍了RRU和BBU的基本工作原理及其系统架构,并详细阐述了它们的通信机制和系统诊断前的准备工作。随后,文章详细论述了RRU和BBU常见故障的诊断步骤,包括硬件故障和软件故障的检测与处理。通过具体的案例分析,本文深入展示了如何对射频链路问题、时钟同步故障以及信号覆盖优化进行有效的故障诊断
VS2022汇编项目案例分析:构建高质量代码的策略与技巧

# 摘要
本文针对VS2022环境下的汇编语言基础及其在高质量代码构建中的应用展开了全面的研究。首先介绍了汇编语言的基本概念和项目架构设计原则,重点强调了代码质量标准和质量保证实践技巧。随后,深入探讨了VS2022内建的汇编开发工具,如调试工具、性能分析器、代码管理与版本控制,以及代码重构与优化工具的使用。文章进一步分析了构建高质量代码的策略,包括模块化编程、代码复
【PSCAD安装与故障排除】:一步到位,解决所有安装烦恼
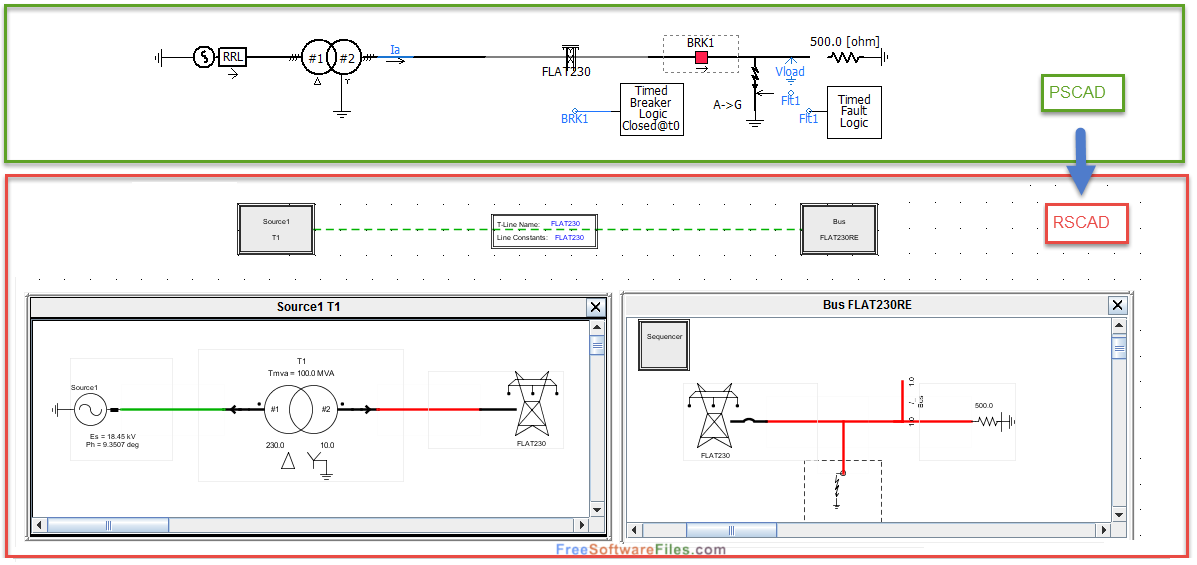
# 摘要
本文系统介绍PSCAD软件的基础知识、系统需求、安装步骤及故障排除技巧。首先概述了PSCAD软件的功能和特点,随后详述了其在不同操作系统上运行所需的硬件和软件环境要求,并提供了详细的安装指导和常见问题解决方案。在故障排除部分,文章首先介绍了故障诊断的基础知识和日志分析方法,然后深入探讨了PSCAD的高级故障诊断技巧,包括使用内置
打造人机交互桥梁:三菱FX5U PLC与PC通信设置完全指南

# 摘要
本文旨在介绍和解析PC与PLC(可编程逻辑控制器)的通信过程,特别是以三菱FX5U PLC为例进行深入探讨。首先,概述了PLC与PC通信的基础知识和重要性,然后详细解释了三菱FX5U PLC的工作原理、硬件结构以及特性。接着,本文探讨了不同PC与PLC通信协议,包括Modbus和Ethernet/IP,并着重于如何选择和配置这些协议以适应具体应用
CATIA文件转换秘籍:数据完整性确保大揭秘

# 摘要
CATIA文件转换是产品设计与工程领域中的一项重要技术,它涉及将不同格式的文件准确转换以保持数据的完整性和可用性。本文系统地介绍了CATIA文件转换的理论基础、工具与技巧,以及实践应用,并探讨了进阶技术与未来展望。文章深入分析了转换过程中可能遇到的挑战,如数据丢失问题,以及应对的策略和技巧,例如使用标准化转换工具
CATIA_CAA二次开发新手必看:7个批处理脚本快速入门技巧

# 摘要
本文首先概述了CATIA_CAA二次开发的基础知识,着重于环境搭建和批处理脚本语言的基础。接着,深入探讨了批处理脚本编写技巧,包括自动化任务实现、错误处理和脚本效率提升。随后,文章详细介绍了批处理脚本与CAA API的交互,包括CAA API的基本概念、批处理脚本如何集成C
SAP登录日志合规性检查:5步骤确保安全合规性
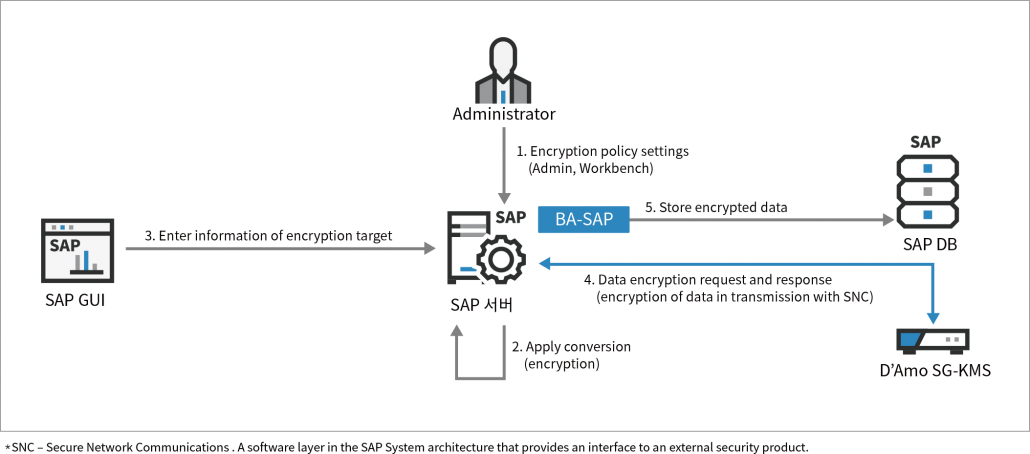
# 摘要
随着信息安全法规的日益严格,SAP登录日志的合规性显得尤为重要。本文首先介绍了SAP登录日志的基本概念和合规性的法律及规范框架,然后阐述了合规性检查的理论基础,包括合规性检查流程、政策和原则以及风险评估与监控机制。接下来,文章详细讨论了合规性检查的实践操作,如审计计划制定、日志分析工具应用以及问题的发现与解决
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )