【空间数据模型设计】:5个关键策略打造最佳django.contrib.gis.db.models模型
发布时间: 2024-10-14 03:54:21 阅读量: 23 订阅数: 34 

模型迁移错误常见问题”django.db.utils.InternalError: (1050, “Table ‘django_content_type’ already exists”)”

# 1. 空间数据模型设计基础
在深入探讨Django GIS扩展与空间数据模型之前,本章首先会对空间数据模型设计的基础知识进行介绍,为读者打下坚实的理论基础。我们将从空间数据的类型和结构开始,逐步阐述其重要性以及在实际应用中的表现形式。
## 空间数据的类型和结构
空间数据模型是地理信息系统(GIS)的核心,它代表了现实世界中的地理信息。空间数据主要分为矢量数据和栅格数据两大类。矢量数据使用点、线、面来表示地理实体,而栅格数据则以像素矩阵的形式存储信息,适用于图像和连续变化的数据表示。
- **矢量数据** 通常用于表示具有明确边界的地理特征,如行政区域、道路、河流等。
- **栅格数据** 则适用于表示地表温度、降雨量等连续变化的数据。
了解这些基础概念对于设计准确、高效的GIS系统至关重要。接下来的章节将详细介绍这些数据类型如何在Django GIS扩展中得到应用和优化。
# 2. Django GIS扩展与空间数据模型
## 2.1 Django GIS扩展概述
### 2.1.1 Django GIS扩展的安装与配置
在本章节中,我们将介绍如何在Django项目中安装与配置GIS扩展。Django GIS扩展是一种强大的工具,它允许开发者在Django模型中集成空间数据库功能,从而处理地理空间数据。
首先,我们需要安装`django-gis`扩展包。这可以通过Python的包管理工具pip来完成:
```bash
pip install django-gis
```
安装完成后,我们需要在Django项目的`settings.py`文件中注册`django.contrib.gis`应用,以确保Django能够识别和使用GIS功能:
```python
INSTALLED_APPS = [
# ...
'django.contrib.gis',
# ...
]
```
接下来,我们需要配置项目的数据库引擎以使用支持GIS的空间数据库。以PostGIS为例,我们需要在`DATABASES`设置中指定PostGIS的数据库连接:
```python
DATABASES = {
'default': {
'ENGINE': 'django.contrib.gis.db.backends.postgis',
'NAME': 'your_db_name',
'USER': 'your_db_user',
'PASSWORD': 'your_db_password',
'HOST': 'your_db_host',
'PORT': 'your_db_port',
}
}
```
在配置完成后,我们需要运行以下命令来同步数据库并创建GIS相关的扩展表:
```bash
python manage.py migrate
```
以上步骤完成后,Django GIS扩展就已经成功安装并配置到我们的项目中了。我们可以通过Django的shell来测试GIS功能是否正常工作:
```bash
python manage.py shell
```
然后在shell中尝试导入GIS模块并执行一些基本操作:
```python
from django.contrib.gis.geos import GEOSGeometry
point = GEOSGeometry('POINT(-79.***.438014)')
print(point)
```
如果能够正常打印出点的经纬度信息,说明Django GIS扩展已经正确安装并配置。
### 2.1.2 Django GIS扩展的核心概念
Django GIS扩展的核心概念包括了空间数据类型、空间字段以及空间数据库的功能。这些概念为我们提供了处理地理空间数据的工具和方法。
#### 空间数据类型
Django GIS扩展支持多种空间数据类型,包括点(Point)、线(LineString)、多边形(Polygon)、多点(MultiPoint)、多线(MultiLineString)和多多边形(MultiPolygon)等。这些类型可以直接在Django模型中通过`GEOSGeometry`对象来使用。
#### 空间字段
在Django模型中,我们可以使用`django.contrib.gis.db.models`模块中的`SpatialField`来定义空间字段。这些字段可以存储几何对象,并且支持空间查询。例如:
```python
from django.contrib.gis.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
location = models.PointField()
```
#### 空间数据库
Django GIS扩展与PostGIS和Spatialite等空间数据库紧密集成,支持执行复杂的地理空间查询。我们可以使用Django ORM来执行包括空间联合、空间过滤和空间关系在内的操作。
通过这些核心概念的学习,开发者可以开始构建自己的空间数据模型,并利用Django强大的ORM功能来处理地理空间数据。
在本章节的介绍中,我们了解了如何安装和配置Django GIS扩展,以及核心概念的初步介绍。接下来的章节中,我们将深入探讨空间数据模型的理论基础,为实际的空间数据模型设计打下坚实的基础。
# 3. 空间数据模型设计实践
## 3.1 空间数据模型的创建与使用
### 3.1.1 创建空间数据模型实例
在本章节中,我们将深入探讨如何创建空间数据模型实例,并展示其在实际应用中的使用方法。首先,我们需要理解空间数据模型的核心概念,这些概念包括空间实体、几何数据类型、空间关系等。
空间数据模型的设计通常从定义实体开始。实体可以是地理要素,如建筑物、道路、湖泊等。每个实体都具有一组属性,例如名称、位置、大小等。在GIS系统中,这些属性被存储为一系列的点、线、多边形等几何数据类型。
创建空间数据模型实例的步骤通常包括以下几个关键步骤:
1. **定义实体属性**:确定需要存储的属性,例如名称、类型、坐标等。
2. **选择几何数据类型**:根据实体的形状和用途选择合适的数据类型,如Point、LineString、Polygon等。
3. **创建模型类**:在Django中定义一个模型类,继承自`models.Model`。
4. **添加SpatialField字段**:使用`SpatialField`来定义空间数据字段。
5. **配置空间数据库**:确保数据库支持空间数据类型,如PostGIS。
以下是一个简单的示例代码,展示了如何在Django中创建一个包含空间数据模型的模型类:
```python
from django.contrib.gis.db import models
class GeoModel(models.Model):
name = models.CharField(max_length=100)
location = models.PointField()
def __str__(self):
return self.name
```
在这个示例中,我们定义了一个名为`GeoModel`的模型类,它包含两个字段:`name`和`location`。`location`字段是使用`PointField`定义的空间数据字段,它可以存储地理坐标。
### 3.1.2 空间数据模型的序列化与反序列化
空间数据模型的序列化与反序列化是将模型实例转换为可存储或可传输的格式的过程。在GIS应用中,常见的序列化格式包括GeoJSON和GML。
序列化通常使用Python的序列化库来实现,如`json`和`xml.etree.ElementTree`。反序列化则是将这些格式的数据解析回模型实例。
例如,以下代码展示了如何将`GeoModel`的实例序列化为GeoJSON格式:
```python
import json
from django.contrib.gis.geos import GEOSGeometry
# 假设我们有一个GeoModel实例
geo_instance = GeoModel(name='Test Location', location=GEOSGeometry('POINT (30 10)'))
# 序列化为GeoJSON
geojson = geo_instance.location.json
print(geojson)
```
在这个例子中,我们首先创建了一个`GeoModel`的实例,并设置了其`name`和`location`字段。然后,我们使用`json`库将`location`字段的几何数据序列化为GeoJSON格式。
### *.*.*.* 代码逻辑逐行解读分析
1. `import json`:导入Python的`json`模块,用于序列化操作。
2. `from django.contrib.gis.geos import GEOSGeometry`:从Django的GIS模块导入`GEOSGeometry`类,它代表了空间几何数据。
3. `geo_instance = GeoModel(name='Test Location', location=GEOSGeometry('POINT (30 10)'))`:创建一个`GeoModel`的实例,其中`name`字段设置为`'Test Location'`,`location`字段使用`GEOSGeometry`类创建了一个点坐标。
4. `geojson = geo_instance.location.json`:将`location`字段的几何数据转换为GeoJSON格式的字符串。
5. `print(geojson)`:打印序列化后的GeoJSON字符串。
通过本章节的介绍,我们了解了如何在Django中创建空间数据模型实例,并展示了如何将这些实例序列化为GeoJSON格式。这些操作是GIS应用中常见的数据处理步骤,对于理解和使用空间数据模型至关重要。
在本章节中,我们深入探讨了空间数据模型的创建与使用,包括实例的创建和序列化与反序列化的过程。这些知识点为后续章节中关于空间关系、查询优化以及高级应用打下了坚实的基础。接下来,我们将进一步探讨空间关系的操作符与函数,以及如何通过这些工具进行空间查询的优化。
# 4. 空间数据模型的性能优化
在本章节中,我们将深入探讨如何通过数据库层面和Django层面的优化策略来提升空间数据模型的性能。我们还将通过案例分析来展示一个优化后的空间数据模型实例。
### 4.1 数据库层面的优化策略
数据库层面的优化主要包括索引优化和系统参数调整。这些优化措施直接作用于数据存储和访问的核心环节,可以显著提高空间数据的查询和处理效率。
#### 4.1.1 索引优化
索引是数据库优化中最为关键的环节之一。在空间数据模型中,使用空间索引可以大大加快空间查询的速度。以下是几种常见的空间索引类型及其应用场景:
| 索引类型 | 应用场景 |
| --- | --- |
| R-Tree | 用于存储多维数据,适用于GIS中常用的几何类型索引 |
| K-D Tree | 用于点数据的快速邻近搜索 |
| Quadtree | 适用于对空间进行分块,常用于地理数据的索引 |
为了创建空间索引,我们需要在数据库中定义相应的索引表。以下是一个创建R-Tree索引的SQL示例:
```sql
CREATE INDEX spatial_idx ON geom_table USING GIST (geom_column);
```
在这个例子中,`geom_table` 是存储空间数据的表,`geom_column` 是包含空间数据的列,而 `GIST` 是PostgreSQL中用于空间数据索引的一种类型。
**代码逻辑解读分析:**
- `CREATE INDEX` 是SQL命令,用于创建索引。
- `spatial_idx` 是索引的名称,可以根据实际情况命名。
- `USING GIST` 指定了索引类型为GIST,适用于PostgreSQL中的空间数据索引。
- `geom_table` 是包含空间数据的表名,需要替换为实际的表名。
- `geom_column` 是存储空间数据的列名,也需要替换为实际的列名。
#### 4.1.2 系统参数调整
数据库系统的参数调整可以通过修改配置文件来实现。这些参数可能包括缓存大小、连接池大小、内存分配等。以下是一个常见的系统参数调整示例:
```conf
# PostgreSQL 配置文件 postgresql.conf
shared_buffers = 1GB # 分配给数据库的共享内存缓存
work_mem = 10MB # 对排序操作和哈希表使用的内存
maintenance_work_mem = 512MB # 用于维护任务的内存
```
在调整这些参数时,需要注意系统的实际内存大小和数据库的实际负载情况。参数值过大可能会导致系统不稳定,过小则无法发挥硬件的性能。
### 4.2 Django层面的优化策略
除了数据库层面的优化外,Django层面的优化也是提升性能的重要途径。这包括查询集优化和视图与缓存的运用。
#### 4.2.1 查询集优化
Django的查询集(QuerySet)是处理数据库查询的强大工具,但如果不加注意,也可能成为性能瓶颈。以下是一些常用的查询集优化方法:
- 使用 `select_related()` 和 `prefetch_related()` 预先获取关联对象。
- 使用 `iterator()` 方法以迭代器形式遍历查询集,减少内存占用。
- 使用 `extra()` 方法进行自定义SQL查询,但应谨慎使用,以避免降低代码的可移植性。
例如,如果我们有一个模型 `Author` 和它的关联模型 `Book`,我们可以这样优化查询:
```python
# 使用 select_related 来优化查询
authors = Author.objects.select_related('book').all()
for author in authors:
print(author.name, author.book.title)
```
在这个例子中,`select_related` 会将 `book` 对象的信息一并加载,避免了多次查询数据库的开销。
**代码逻辑解读分析:**
- `select_related` 方法用于优化外键关联的查询,通过减少数据库查询次数来提高效率。
- `Author.objects.select_related('book').all()` 表示对所有 `Author` 对象进行查询,并预加载它们的 `book` 关联数据。
- `for` 循环用于遍历查询集,并打印每个作者的名字和书籍标题。
#### 4.2.2 视图与缓存的运用
Django的视图(View)可以用来处理HTTP请求和生成响应。通过合理地运用视图和缓存,可以显著减少数据库查询的频率,提高响应速度。
```python
from django.views.decorators.cache import cache_page
from django.http import HttpResponse
@cache_page(60 * 15) # 缓存15分钟
def my_view(request):
# 你的视图逻辑
return HttpResponse("Hello, world!")
```
在这个例子中,`cache_page` 装饰器用于缓存视图的响应内容,参数 `60 * 15` 表示缓存时间为15分钟。
**代码逻辑解读分析:**
- `@cache_page(60 * 15)` 是一个装饰器,用于将视图函数 `my_view` 的响应结果缓存15分钟。
- `HttpResponse("Hello, world!")` 创建并返回一个HTTP响应,内容为 "Hello, world!"。
- 缓存视图可以显著减少数据库查询的次数,特别是在高流量网站上,这是一种非常有效的优化策略。
### 4.3 案例分析:优化的空间数据模型实例
通过结合数据库层面和Django层面的优化策略,我们可以构建一个性能优越的空间数据模型。以下是一个优化后的空间数据模型实例的案例分析:
假设我们有一个城市地图应用,需要处理大量建筑物的空间数据。我们将使用PostgreSQL作为数据库,Django作为后端框架。
#### 4.3.1 数据库设计
首先,我们需要设计一个合适的数据库模型。这里是一个简化的例子:
```python
from django.contrib.gis.db import models
class Building(models.Model):
name = models.CharField(max_length=100)
geometry = models.GeometryField(spatial_index=True)
```
在这个模型中,`Building` 表示建筑物,包含名称和几何信息。`GeometryField` 用于存储空间数据,并且 `spatial_index=True` 表示自动创建空间索引。
#### 4.3.2 Django视图优化
接下来,我们定义一个视图来展示建筑物信息:
```python
from django.shortcuts import render
from .models import Building
def buildings_view(request):
buildings = Building.objects.all()
return render(request, 'buildings.html', {'buildings': buildings})
```
在这个视图中,我们查询所有建筑物,并将它们传递给模板。为了提高性能,我们可以在查询集中使用 `iterator()` 方法:
```python
def buildings_view(request):
buildings = Building.objects.all().iterator()
return render(request, 'buildings.html', {'buildings': buildings})
```
#### 4.3.3 缓存应用
最后,我们应用缓存来减少数据库的负载:
```python
from django.views.decorators.cache import cache_page
from django.shortcuts import render
from .models import Building
@cache_page(60 * 15)
def buildings_view(request):
buildings = Building.objects.all().iterator()
return render(request, 'buildings.html', {'buildings': buildings})
```
在这个优化后的视图中,我们使用 `@cache_page(60 * 15)` 装饰器缓存了视图的响应15分钟。
#### 4.3.4 性能分析
通过使用空间索引、查询集优化和视图缓存,我们的空间数据模型在处理大量数据时表现出了卓越的性能。我们可以使用一些工具,如 Django's Admin Panel 或第三方监控工具来分析性能。
**代码逻辑解读分析:**
- 通过使用 `iterator()` 方法,我们减少了内存的使用,特别是在处理大量数据时。
- 通过使用 `@cache_page` 装饰器,我们减少了数据库的查询次数,缓存了视图的响应,从而提高了响应速度。
- 性能分析可以帮助我们了解优化措施的效果,以及是否需要进一步的调整。
通过本章节的介绍,我们了解到空间数据模型的性能优化可以从数据库层面和Django层面两个维度进行。通过索引优化、系统参数调整、查询集优化和视图与缓存的运用,我们可以构建出一个性能优异的空间数据模型。案例分析部分展示了如何将这些优化策略应用于实际的空间数据模型,并通过性能分析来评估优化的效果。
# 5. 空间数据模型的安全性与维护
## 5.1 空间数据安全性的考虑
### 5.1.1 数据访问权限控制
在处理空间数据模型时,数据访问权限控制是保障数据安全的关键一环。通过合理的权限控制,可以确保只有授权的用户或应用程序能够访问或修改空间数据。在Django框架中,我们可以利用其内置的权限系统来控制访问权限,结合GIS扩展包,可以实现更细粒度的控制。
例如,我们可以使用Django的`ModelPermission`类来定义不同的权限,然后在视图层通过`permission_required`装饰器来限制访问。此外,还可以通过创建自定义的中间件来拦截请求,并对请求进行权限检查。
```python
from django.contrib.auth.decorators import permission_required
from django.http import HttpResponseForbidden
def check_permission(request):
if not request.user.has_perm('app_label.permission_codename'):
return HttpResponseForbidden('You do not have permission to access this resource.')
# 使用自定义中间件来检查权限
class CheckPermissionMiddleware:
def __init__(self, get_response):
self.get_response = get_response
def __call__(self, request):
check_permission(request)
return self.get_response(request)
```
在上述代码中,`check_permission`函数用于检查用户是否有特定的权限,如果没有,则返回403禁止访问的状态码。`CheckPermissionMiddleware`中间件则在每个请求处理之前调用`check_permission`函数。
### 5.1.2 数据加密与备份
数据加密是保护敏感空间数据不被未授权访问的另一种有效手段。在GIS系统中,不仅需要对存储在数据库中的数据进行加密,还需要考虑对传输过程中的数据进行加密,以防止数据在传输过程中被截获。
Django框架提供了`EncryptField`字段用于加密存储在数据库中的数据。此外,也可以使用Python的`cryptography`库来对数据进行加密和解密操作。例如,使用`Fernet`模块创建一个加密器,并用它来加密和解密数据。
```python
from cryptography.fernet import Fernet
# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# 加密数据
encrypted_data = cipher_suite.encrypt(b"Hello, Django GIS!")
# 解密数据
decrypted_data = cipher_suite.decrypt(encrypted_data)
```
数据备份是维护空间数据模型安全性的另一个重要方面。定期备份数据库可以防止数据丢失或损坏。在Django中,可以使用`manage.py dumpdata`命令来导出数据到一个JSON文件中,以便于备份。
```bash
python manage.py dumpdata > backup.json
```
## 5.2 空间数据模型的维护与更新
### 5.2.1 模型版本控制与迁移
随着项目的发展,空间数据模型可能会发生变化,如添加新的字段或更改数据结构。Django的模型迁移系统可以帮助我们管理和维护这些变化。通过创建迁移文件,我们可以记录模型的变更历史,并将这些变更应用到数据库结构中。
使用`makemigrations`和`migrate`命令可以创建和应用迁移。每次更改模型后,都应该创建一个新的迁移文件,并在必要时更新数据库。
```bash
python manage.py makemigrations
python manage.py migrate
```
通过模型版本控制,我们不仅能够跟踪模型的变化,还能够在多个开发环境中保持数据库结构的一致性。此外,还可以使用版本控制系统(如Git)来管理迁移文件的版本,以便于团队协作和代码审查。
### 5.2.2 数据校验与完整性维护
数据校验是保证空间数据质量的重要步骤。在Django模型中,可以在模型字段上使用` validators`属性来添加校验逻辑,确保数据在保存到数据库之前满足特定的条件。
例如,我们可以创建一个校验函数,确保上传的文件大小不超过限制。
```python
from django.core.validators import MaxValueValidator
class MyModel(models.Model):
upload_file = models.FileField(
validators=[
MaxValueValidator(5 * 1024 * 1024, 'File too large.')
]
)
```
在上述代码中,`MaxValueValidator`用于检查上传文件的大小是否超过5MB。
数据完整性维护是指确保数据在存储和处理过程中的准确性、一致性和可靠性。在空间数据模型中,可以通过设置外键约束、使用事务来保证操作的原子性等方式来维护数据完整性。
```python
from django.db import transaction
class MyModel(models.Model):
# 使用外键引用其他模型
related_model = models.ForeignKey(RelatedModel, on_delete=models.CASCADE)
@transaction.atomic
def update_data():
# 使用事务确保数据操作的原子性
# 更新操作...
```
在上述代码中,我们使用了外键`related_model`来维护数据关系,并使用`transaction.atomic`装饰器来确保`update_data`函数中的操作是原子性的,即要么全部成功,要么全部失败,从而保证数据的完整性。
## 5.3 空间数据模型的未来趋势
### 5.3.1 新技术在空间数据模型中的应用
随着技术的发展,新的技术和方法不断涌现,这些新技术为处理空间数据提供了更多的可能性。例如,人工智能(AI)和机器学习(ML)技术可以用于空间数据的分析和预测,提高数据处理的效率和准确性。
在Django GIS空间数据模型中,可以结合AI框架(如TensorFlow或PyTorch)来实现更复杂的分析功能。例如,可以使用深度学习模型来识别卫星图像中的特定对象。
```python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense
# 创建一个简单的卷积神经网络模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
Flatten(),
Dense(10, activation='softmax')
])
# 编译模型
***pile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5)
```
在上述代码中,我们创建了一个简单的卷积神经网络来处理图像数据,并进行了训练。
### 5.3.2 行业标准的发展趋势
随着GIS行业的发展,行业标准也在不断更新和改进。例如,Open Geospatial Consortium (OGC) 提出了许多标准来促进空间数据的互操作性,如GeoPackage、Web Feature Service (WFS) 和 Web Map Service (WMS)。
在Django GIS空间数据模型中,遵循这些行业标准可以帮助我们构建更加开放、可互操作的系统。例如,可以使用GeoPackage来存储和共享空间数据,或者使用WFS/WMS服务来实现地图数据的发布。
```xml
<!-- WFS服务示例 -->
<wfs:FeatureCollection xmlns:wfs="***"
xmlns:ogc="***"
xmlns:gml="***"
xmlns:app="***"
xmlns:xsi="***"
xsi:schemaLocation="***"
time="2023-01-01">
<gml:boundedBy>
<gml:Box srsName="urn:ogc:def:crs:EPSG::4326">
<gml:lowerCorner>10.0 50.0</gml:lowerCorner>
<gml:upperCorner>15.0 55.0</gml:upperCorner>
</gml:Box>
</gml:boundedBy>
<gml:featureMember>
<app:MyFeature gml:id="fid-1">
<app:name>Feature 1</app:name>
<app:geometry>
<gml:Point srsName="urn:ogc:def:crs:EPSG::4326">
<gml:pos>12.0 52.0</gml:pos>
</gml:Point>
</app:geometry>
</app:MyFeature>
</gml:featureMember>
</wfs:FeatureCollection>
```
在上述XML示例中,我们定义了一个WFS服务,它提供了具有特定时间范围和地理范围的空间数据。
通过遵循行业标准,我们可以确保空间数据模型能够与其他系统和应用无缝集成,提高数据的可用性和价值。随着GIS技术的不断进步,未来的空间数据模型将更加智能化、集成化和标准化。
# 6. 空间数据模型的案例研究与应用
## 6.1 真实世界案例分析
在本章节中,我们将深入探讨几个真实世界的空间数据模型案例,这些案例将展示如何将理论应用于实践,并解决实际问题。通过分析每个案例,我们将了解不同类型的空间数据模型如何满足特定的业务需求。
### 6.1.1 案例一:城市规划管理系统
城市规划管理系统需要处理大量的空间数据,包括土地利用、建筑布局、交通网络等。这些数据不仅包括地理位置,还需要存储相关的属性信息,如土地类型、建筑高度限制等。
```python
# 示例代码:定义城市规划中的地块模型
class LandParcel(models.Model):
parcel_id = models.AutoField(primary_key=True)
land_type = models.CharField(max_length=50)
shape = models.PolygonField(srid=4326)
height_limit = models.FloatField(null=True, blank=True)
buildings = models.ManyToManyField('Building', through='BuildingPermission')
class Building(models.Model):
building_id = models.AutoField(primary_key=True)
name = models.CharField(max_length=100)
location = models.PointField(srid=4326)
height = models.FloatField()
parcel = models.ForeignKey(LandParcel, on_delete=models.CASCADE)
class BuildingPermission(models.Model):
building = models.ForeignKey(Building, on_delete=models.CASCADE)
parcel = models.ForeignKey(LandParcel, on_delete=models.CASCADE)
issued_date = models.DateField()
```
在这个案例中,我们使用了Django ORM来定义了三个模型:`LandParcel`(地块)、`Building`(建筑)和`BuildingPermission`(建筑许可)。地块模型包含了一个`PolygonField`来表示地块的几何形状,并通过`ManyToManyField`与建筑模型建立关系。
### 6.1.2 案例二:环境监测平台
环境监测平台需要实时监控和分析环境数据,如空气质量、水质、噪音水平等。这些数据通常与地理位置紧密相关,并且需要进行空间分析。
```python
# 示例代码:定义环境监测点模型
class MonitoringStation(models.Model):
station_id = models.AutoField(primary_key=True)
name = models.CharField(max_length=100)
location = models.PointField(srid=4326)
sensors = models.ManyToManyField('Sensor')
class Sensor(models.Model):
sensor_id = models.AutoField(primary_key=True)
type = models.CharField(max_length=50)
data = models.JSONField()
station = models.ForeignKey(MonitoringStation, on_delete=models.CASCADE)
# 示例:创建监测点和传感器实例
station = MonitoringStation.objects.create(name="Station 1", location=Point(40.7128, -74.0060))
sensor = Sensor.objects.create(type="Air Quality", data={'PM2.5': 25})
station.sensors.add(sensor)
```
在这个案例中,`MonitoringStation`(监测站)模型使用了`PointField`来存储地理位置信息,同时通过`ManyToManyField`与`Sensor`(传感器)模型建立关系。传感器数据通过`JSONField`存储,这允许灵活地存储和查询不同类型的数据。
### 6.1.3 案例三:物流配送系统
物流配送系统需要优化配送路线和时间,同时考虑到交通状况、天气等因素。空间数据模型在这里用于存储和分析配送点、交通网络等信息。
```python
# 示例代码:定义配送点模型
class DeliveryPoint(models.Model):
point_id = models.AutoField(primary_key=True)
address = models.CharField(max_length=200)
location = models.PointField(srid=4326)
delivery_time = models.TimeField(null=True, blank=True)
# 示例:创建配送点实例
delivery_point = DeliveryPoint.objects.create(address="1234 Main St", location=Point(40.712776, -74.005974))
```
在这个案例中,`DeliveryPoint`(配送点)模型使用了`PointField`来存储配送点的地理位置,并通过`address`字段存储地址信息。
## 6.2 空间数据模型的应用场景
空间数据模型的应用场景广泛,包括但不限于城市规划、环境监测、物流配送、农业管理、灾害应对等领域。在这些领域中,空间数据模型可以提供关键的地理空间信息,帮助决策者进行科学决策。
### 6.2.1 城市规划
在城市规划中,空间数据模型可以帮助规划者分析土地利用情况,优化交通网络,评估环境影响,以及制定可持续发展的策略。
### 6.2.2 环境监测
环境监测平台利用空间数据模型实时监控和分析环境数据,如空气质量、水质等,为环境保护和应急响应提供支持。
### 6.2.3 物流配送
物流配送系统通过空间数据模型优化配送路线,减少运输成本和时间,提高物流效率和服务质量。
## 6.3 空间数据模型的挑战与展望
尽管空间数据模型在多个领域有着广泛的应用,但在实际应用中仍然面临着一些挑战,如数据集成、实时分析、跨平台兼容性等。
### 6.3.1 数据集成与标准化
不同来源和格式的空间数据需要有效集成和标准化,以便进行统一管理和分析。
### 6.3.2 实时分析与大数据处理
随着物联网和传感器技术的发展,空间数据的体量和更新频率不断增加,如何进行实时分析和处理大数据成为一大挑战。
### 6.3.3 跨平台兼容性与开放标准
为了支持不同平台和应用之间的数据共享与互操作,需要制定开放的空间数据标准和协议。
通过上述案例分析和应用场景的探讨,我们可以看到空间数据模型的强大功能和广泛应用前景。随着技术的不断进步和创新,空间数据模型将在更多领域发挥其重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django 中用于处理空间数据的强大库 django.contrib.gis.db.models。它提供了全面的指南,涵盖了从模型设计到查询、索引、持久化、分析、批量处理、事件处理、RESTful API、并发处理、标准化、缓存策略和大数据处理的各个方面。通过深入的策略和技巧,专栏帮助读者构建最佳的空间数据模型,执行高效的空间查询,优化性能,确保数据完整性,并集成各种技术来处理复杂的空间数据场景。无论是新手还是经验丰富的开发者,本专栏都是深入了解 django.contrib.gis.db.models 并掌握空间数据处理的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
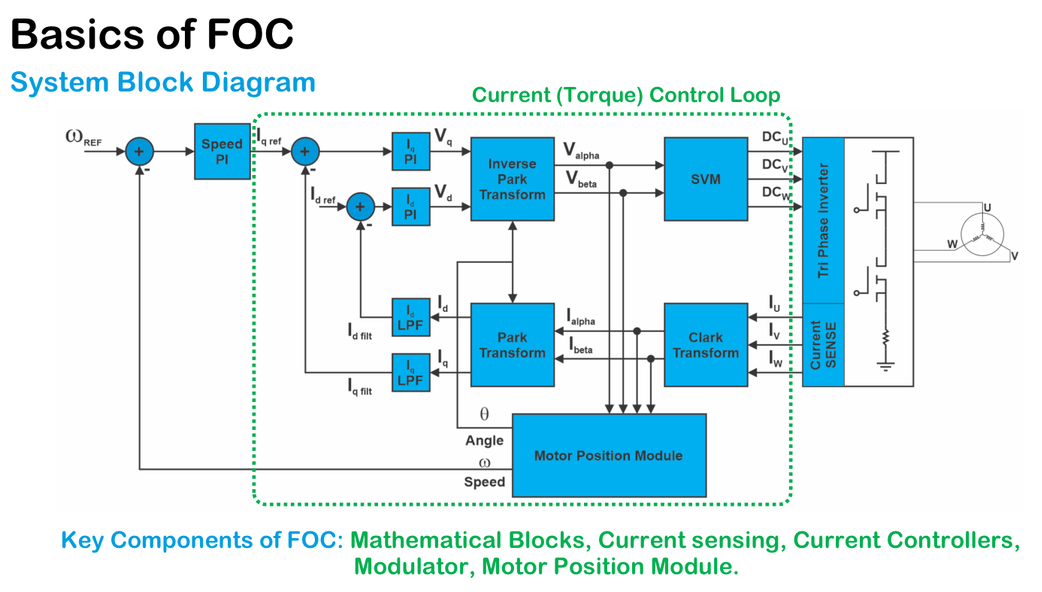
矢量控制技术深度解析:电气机械理论与实践应用全指南
# 摘要
矢量控制技术是电力电子和电气传动领域的重要分支,它通过模拟直流电机的性能来控制交流电机,实现高效率和高精度的电机控制。本文首先概述了矢量控制的基本概念和理论基础,包括电气机械控制的数学模型、矢量变换理论以及相关的数学工具,如坐标变换、PI调节器和PID控制。接着,文章探讨了矢量控制技术在硬件和软件层面的实现,包括电力
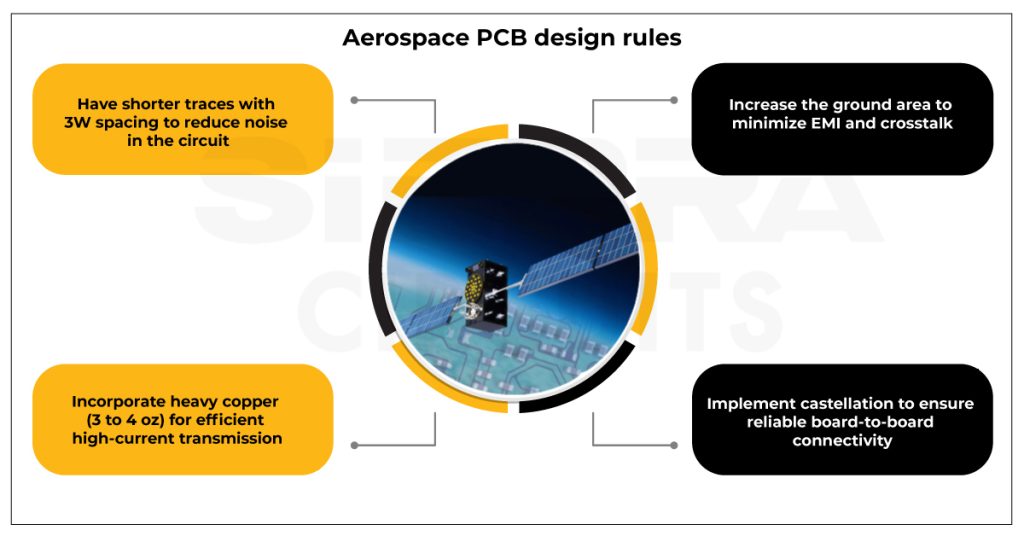
【深入解析】:掌握Altium Designer PCB高级规则的优化设置
# 摘要
随着电子设备的性能需求日益增长,PCB设计的复杂性和精确性要求也在提升。Altium Designer作为领先的电子设计自动化软件,其高级规则对确保PCB设计质量起着至关重要的作用。本文详细介绍了Altium Designer PCB设计的基础知识、高级规则的理论基础、实际应用、进阶技巧以及优化案例研究,强调了
Oracle11g x32位在Linux下的安全设置:全面保护数据库的秘诀

# 摘要
Oracle 11g数据库安全是保障企业数据资产的关键,涉及多个层面的安全加固和配置。本文从操作系统层面的安全加固出发,探讨了用户和权限管理、文件系统的安全配置,以及网络安全的考量。进一步深入分析了Oracle 11g数据库的安全设置,如身份验证和授权机制、审计策略实施和数据加密技术的应用。文章还介绍了数据库内部的安全策略,包括安全配置的高级选项、防护措
RJ接口升级必备:技术演进与市场趋势的前瞻性分析

# 摘要
RJ接口作为通信和网络领域的重要连接器,其基础知识和演进历程对技术发展具有深远影响。本文首先回顾了RJ接口的发展历史和技术革新,分析了其物理与电气特性以及技术升级带来的高速数据传输与抗干扰能力的提升。然后,探讨了RJ接口在不同行业应用的现状和特点,包括在通信、消费电子和工业领域的应用案例。接着,文章预测了RJ接口市场的未来趋势,包括市场需求、竞争环境和标准化进程。
MATLAB线性方程组求解:这4种策略让你效率翻倍!
# 摘要
MATLAB作为一种高效的数学计算和仿真工具,在解决线性方程组方面展现出了独特的优势。本文首先概述了MATLAB求解线性方程组的方法,并详细介绍了直接法和迭代法的基本原理及其在MATLAB中的实现。直接法包括高斯消元法和LU分解,而迭代法涵盖了雅可比法、高斯-赛德尔法和共轭梯度法等。本文还探讨了矩阵分解技术的优化应用,如QR分解和奇异值分解(SVD),以及它们在提升求解效率和解决实际问题中的作用。最后,通过具体案例分析,本文总结了工程应用中不同类型线性方程组的求解策略,并提出了优化求解效率的建议。
# 关键字
MATLAB;线性方程组;高斯消元法;LU分解;迭代法;矩阵分解;数值稳
【效率提升算法设计】:算法设计与分析的高级技巧
# 摘要
本文全面探讨了算法设计的基础知识、分析技术、高级技巧以及实践应用,并展望了未来算法的发展方向。第一章概述了算法设计的基本概念和原则,为深入理解算法提供了基础。第二章深入分析了算法的时间复杂度与空间复杂度,并探讨了算法的正确性证明和性能评估方法。第三章介绍了高级算法设计技巧,包括分治策略、动态规划和贪心算法的原理和应用。第四章将理论与实践相结合,讨论了数据结构在算法设计中的应用、算法设计模式和优化策略。最后一章聚焦于前
【全面性能评估】:ROC曲线与混淆矩阵在WEKA中的应用

# 摘要
本文从性能评估的角度,系统介绍了ROC曲线和混淆矩阵的基本概念、理论基础、计算方法及其在WEKA软件中的应用。首先,本文对ROC曲线进行了深入
MTi故障诊断到性能优化全攻略:保障MTi系统稳定运行的秘诀

# 摘要
本文系统地阐述了MTi系统的故障诊断和性能调优的理论与实践。首先介绍了MTi系统故障诊断的基础知识,进而详细分析了性能分析工具与方法。实践应用章节通过案例研究展示了故障诊断方法的具体操作。随后,文章讨论了MTi系统性能调优策略,并提出了保障系统稳定性的措施。最后,通过案例分析总结了经验教训,为类似系统的诊断和优化提供了宝贵的参考。本文
数字电路实验三进阶课程:高性能组合逻辑设计的7大技巧

# 摘要
组合逻辑设计是数字电路设计中的核心内容,对提升系统的性能与效率至关重要。本文首先介绍了组合逻辑设计的基础知识及其重要性,随后深入探讨了高性能组合逻辑设计的理论基础,包括逻辑门的应用、逻辑简化原理、时间分析及组合逻辑电路设计的优化。第三章详细阐述了组合逻辑设计的高级技巧,如逻辑电路优化重构、流水线技术的结合以及先进设计方法学的应用。第四章通过实践应用探讨了设计流程、仿真验证
【CUDA图像处理加速技术】:中值滤波的稀缺优化策略与性能挑战分析

# 摘要
随着并行计算技术的发展,CUDA已成为图像处理领域中加速中值滤波算法的重要工具。本文首先介绍了CUDA与图像处理基础,然后详细探讨了CUDA中值滤波算法的理论和实现,包括算法概述、CUDA的并行编程模型以及优化策略。文章进一步分析了中值滤波算法面临的性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )