【高性能计算核心】:MIPS32指令集在计算密集型应用中的作用
发布时间: 2024-12-14 13:36:19 订阅数: 3 
参考资源链接:[MIPS32指令集详细指南(中文版)](https://wenku.csdn.net/doc/67i6xj6m2s?spm=1055.2635.3001.10343)
# 1. MIPS32指令集概述
MIPS32指令集是MIPS架构中的32位处理器版本,以其简洁、高效的特性在嵌入式系统和高性能计算领域广泛使用。MIPS32基于精简指令集计算机(RISC)原则设计,具有固定的指令长度、大量的寄存器和简单的指令格式。本章节将介绍MIPS32指令集的起源、基本结构和特点,为接下来深入分析MIPS32架构提供必要的背景知识。MIPS32的简单指令和高速执行特性使其在实时系统、网络设备和多媒体应用中尤其受到青睐。通过理解其基本指令和操作模式,开发者可以更有效地利用MIPS32处理器的资源,设计出高性能的应用程序。接下来的章节将进一步探讨MIPS32的寄存器设计、指令格式、寻址模式以及它如何在现代计算环境中实现性能优化。
# 2. MIPS32基础架构与性能分析
## 2.1 MIPS32架构特点
### 2.1.1 寄存器组的设计
MIPS32架构中的寄存器设计是其性能优化的关键因素之一。MIPS32拥有32个通用寄存器,其中部分寄存器用于特定目的,如寄存器R0固定为0,R31用作函数调用的链接寄存器。这种设计简化了编译器的工作,因为编译器可以轻松跟踪寄存器的使用和管理。
```assembly
# 示例代码,展示MIPS32寄存器的使用
add $t0, $s1, $s2 # 将寄存器$s1和$s2的值相加,结果存储在$t0中
```
在上述汇编指令中,`$t0` 是一个临时寄存器,用于存储运算结果;`$s1` 和 `$s2` 是保存操作数的寄存器。这种清晰的寄存器使用规范使得处理器指令执行更为高效。
### 2.1.2 指令格式和寻址模式
MIPS32的指令格式是固定长度的,每条指令都占用32位,使得指令的解析更为简单快速。它支持多种寻址模式,包括立即数寻址、寄存器直接寻址、基址寻址和跳转寻址。这种灵活性保证了程序在不同应用场景下的高效执行。
```assembly
# 示例代码,展示不同寻址模式的使用
lw $t0, 100($s1) # 基址寻址,从地址$s1+100处加载一个字到$t0
```
在上例中,`lw` 指令表示加载字(load word),`$t0` 是目的寄存器,`$s1` 是基址寄存器,`100` 是偏移量。
## 2.2 性能考量
### 2.2.1 指令执行效率
MIPS32指令集精简并且功能强大,每个指令能够执行一个简单的操作,这使得指令的执行效率很高。更重要的是,MIPS32的指令流水线设计允许在前一条指令的某些阶段完成之后,立即开始执行下一条指令。
### 2.2.2 管道化和流水线设计
MIPS架构实现了五级流水线:取指、译码、执行、访存、写回。这种流水线技术显著提高了指令的吞吐量。然而,流水线的设计也引入了复杂性,比如当遇到分支指令时,需要处理流水线的冒险问题。
### 2.2.3 缓存策略和内存管理
MIPS32架构采用统一的缓存管理策略,无论是数据缓存还是指令缓存都采用相同的策略。缓存策略包括写回和写直达两种模式。内存管理单元(MMU)通过虚拟内存管理,提升了内存访问效率和保护。
```mermaid
graph TD
A[取指令] -->|寄存器| B[译码]
B -->|寄存器| C[执行]
C -->|寄存器| D[访存]
D -->|寄存器| E[写回]
```
以上mermaid流程图简要展示了MIPS32的五级流水线工作流程。这种流程图有助于理解MIPS32如何在不同的流水线阶段处理指令。
MIPS32架构的性能分析表明,其设计特点和架构选择对于现代计算需求而言,在很多方面仍然具有竞争力。通过理解这些架构和性能考量,可以更好地优化和利用MIPS32处理器的潜力。
# 3. MIPS32在计算密集型应用中的实现
计算密集型应用通常需要处理大量数据或执行复杂的数学运算,这对于处理器的性能提出了更高的要求。MIPS32架构通过其独特的设计理念和指令集扩展,为这些应用提供了强大的支持。在本章节中,我们将探讨如何通过算法优化以及专用指令集扩展来在MIPS32处理器上实现高性能计算。
## 3.1 算法优化与MIPS32
当面对需要大量计算的应用时,算法优化是提高效率的关键。在MIPS32架构上,这可以通过多种编程技术实现,包括循环展开、向量化技术、多线程以及指令并行。
### 3.1.1 循环展开和向量化技术
循环展开通过减少循环的迭代次数,减少了循环控制开销,使得代码可以运行得更快。向量化技术则利用MIPS32的SIMD指令集扩展,一次性对多个数据元素执行相同的操作。
```assembly
# MIPS32伪代码示例: 循环展开和向量化
loop: lw $t0, 0($a0) # 加载数据到寄存器
lw $t1, 4($a0)
add $t2, $t0, $t1 # 并行处理两个数据
add $t3, $t0, $t1
sw $t2, 0($a1)
sw $t3, 4($a1)
addi $a0, $a0, 8 # 移动指针
addi $a1, $a1, 8
bne $a0, $a2, loop # 循环条件
```
在这个示例中,我们加载两个数据值,并执行四次加法操作,这相当于循环展开四次。同时,我们通过向量化技术实现了对多个数据的并行处理。
### 3.1.2 多线程和指令并行
为了进一步提升性能,可以使用多线程技术。MIPS32支持多线程处理器架构,能够有效利用处理器资源,提高指令级并行度。多线程允许在单个处理器核心上切换不同的线程,同时避免了传统单线程程序中的停顿和延迟。
```c
// 多线程示例代码
void* thread_function(void* arg) {
// 执行线程任务...
return NULL;
}
int main() {
pthread_t thread_id;
pthread_create(&thread_id, NULL, thread_function, NULL);
pthread_join(thread_id, NULL);
return 0;
}
```
多线程的实现使得程序能够充分利用处理器核心,并且通过合理的设计,可以避免线程间的竞争条件和同步问题。
## 3.2 MIPS32专用指令集扩展
MIPS32提供了专用的指令集扩展,以更好地支持各种计算密集型应用。特别地,MIPS32的SIMD扩展和浮点运算优化提供了更强大的计算能力。
### 3.2.1 单指令多数据(SIMD)扩展
MIPS32的SIMD扩展,即MIPS SIMD Architecture (MSA),提供了特殊的寄存器和指令来支持单指令多数据操作。这使得对向量数据的操作更加高效,特别适合图形和视频处理等多媒体应用。
```assembly
# MIPS32 MSA指令示例: 并行数据处理
vadd_q_h $vs2, $vs1, $vs0 # 向量加法
vsub_q_h $vs3, $vs1, $vs0 # 向量减法
```
上述代码演示了MSA指令集中的向量加法和减法操作,可以高效地处理图像和视频数据。
### 3.2.2 浮点运算优化
在科学计算等领域,浮点运算速度至关重要。MIPS32架构支持高性能的浮点指令集,如MIPS Digital Media Extensi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
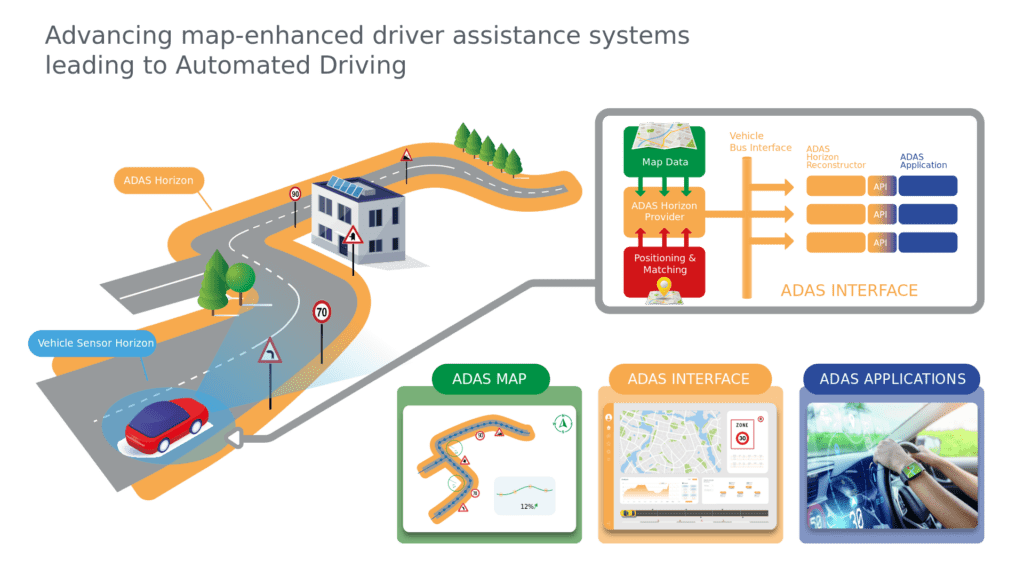
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )