使用kubeadm初始化单master节点Kubernetes集群
发布时间: 2024-03-07 04:43:18 阅读量: 36 订阅数: 22 

部署一套单Master的K8s集群(kubeadm-V1.21)
# 1. 介绍
## 1.1 什么是kubeadm
Kubeadm是一个Kubernetes官方发布的用于快速部署Kubernetes集群的工具。它可以通过简单的命令来完成Kubernetes集群的初始化,而无需深入了解复杂的集群部署流程。
## 1.2 Kubernetes集群概述
Kubernetes是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。Kubernetes通过将容器部署、伸缩、维护和组织的自动化进行标准化,从而改善了应用程序的部署和运维处理。Kubernetes集群由多个运行Kubernetes的节点组成,其中包括Master节点和Worker节点。
# 2. 准备工作
在开始初始化Kubernetes集群之前,需要做一些准备工作。本章将介绍硬件和操作系统的要求,以及如何安装Docker、kubeadm、kubelet和kubectl。
### 2.1 硬件和操作系统要求
在准备安装Kubernetes之前,首先需要确保主机满足以下硬件和操作系统要求:
- **硬件要求**:
- 64位处理器
- 2GB或更多RAM
- 20GB或更多可用磁盘空间
- **操作系统要求**:
- Ubuntu 16.04/18.04/20.04
- CentOS 7
- Debian 9/10
- RHEL 7/8
### 2.2 安装Docker
在安装Kubernetes之前,需要先安装Docker作为容器运行时。以下是在Ubuntu 20.04上安装Docker的步骤:
```bash
# 更新系统
sudo apt update
# 安装依赖包
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
# 添加Docker官方GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加Docker软件仓库
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 更新apt软件包缓存,并安装Docker
sudo apt update
sudo apt install -y docker-ce
# 启动Docker服务并设置开机自启
sudo systemctl start docker
sudo systemctl enable docker
# 验证安装
docker --version
```
### 2.3 安装kubeadm、kubelet和kubectl
安装完Docker后,接下来安装Kubernetes所需的工具:kubeadm、kubelet和kubectl。
```bash
# 添加Kubernetes软件源
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"
# 更新apt软件包缓存
sudo apt update
# 安装kubeadm、kubelet和kubectl
sudo apt install -y kubeadm kubelet kubectl
# 验证安装
kubeadm version
kubectl version --client
kubelet --version
```
至此,准备工作完成,现在可以继续初始化单master节点Kubernetes集群。
# 3. 初始化单master节点Kubernetes集群
#### 3.1 创建Master节点
在初始化单master节点Kubernetes集群之前,首先需要准备一个能够承载Kubernetes Master角色的节点。通常情况下,这个节点会比较强大,具有足够的计算和存储资源来支撑整个集群的管理。
#### 3.2 使用kubeadm初始化Kubernetes集群
使用kubeadm工具来初始化Kubernetes集群非常简单。首先通过以下命令安装kubeadm:
```bash
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
```
安装完成后,使用以下命令初始化Kubernetes集群:
```bash
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
```
在初始化过程中,kubeadm将下载所需的Kubernetes组件镜像,并自动配置Kubernetes Master节点。初始化完成后,根据输出结果中的提示,执行相应的命令来设置当前用户对Kubernetes的访问权限。
#### 3.3 验证集群状态
使用以下命令验证Kubernetes集群状态:
```bash
kubectl get nodes
kubectl get pods --all-namespaces
```
如果输出结果显示Master节点已经 Ready,并且系统 Pod 正在运行,那么表示Kubernetes集群初始化成功。
本节内容介绍了如何初始化单master节点的Kubernetes集群,并验证集群状态。接下来我们将继续学习如何加入Worker节点到集群中。
# 4. 加入Worker节点
在部署Kubernetes集群之后,我们通常需要将Worker节点加入到集群中,以扩展集群的计算能力。本章节将详细介绍如何部署Worker节点并将其加入到Kubernetes集群中。
#### 4.1 部署Worker节点
在准备部署Worker节点之前,确保已经完成了准备工作中的硬件和操作系统要求,并且已经安装了Docker、kubeadm、kubelet和kubectl。
以下是部署Worker节点的详细步骤:
1. 在Worker节点上安装Docker
使用以下命令安装Docker:
```shell
# 安装Docker CE
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get install -y docker-ce
# 启动并加入开机启动
sudo systemctl start docker
sudo systemctl enable docker
```
2. 部署Kubelet和kubeadm
使用相同的版本号安装Kubelet和kubeadm:
```shell
# 安装指定版本的kubelet和kubeadm
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm
sudo apt-mark hold kubelet kubeadm
```
3. 部署CNI插件
根据实际需求选择并部署合适的CNI插件,例如Flannel、Calico等。
#### 4.2 加入Worker节点到集群
部署完成Worker节点之后,使用以下命令将Worker节点加入到Kubernetes集群中:
```shell
# 在Master节点上执行以下命令
kubeadm token create --print-join-command
# 将输出的加入命令拷贝到Worker节点执行
```
执行成功后,Worker节点即可成功加入到Kubernetes集群中。
通过以上步骤,我们完成了Worker节点的部署和加入,实现了Kubernetes集群的扩展。
# 5. Kubernetes集群管理
Kubernetes集群已经搭建完成,接下来我们将学习如何管理Kubernetes集群,包括部署应用程序到集群、扩展集群以及监控集群状态。
#### 5.1 部署应用程序到集群
在Kubernetes集群中部署应用程序通常需要创建一个Pod,并为其定义一个Deployment或者StatefulSet。以下是一个简单的示例,我们将部署一个名为nginx的Pod到集群中:
```yaml
# nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
通过kubectl命令将该部署文件应用到集群中:
```bash
kubectl apply -f nginx-deployment.yaml
```
#### 5.2 扩展集群
当集群中的资源不足以满足应用程序的需求时,我们需要扩展集群。可以通过增加Worker节点或者扩展现有节点的资源来实现集群的扩展。
添加一个Worker节点:
```bash
kubeadm join <MASTER_NODE_IP>:6443 --token <TOKEN> --discovery-token-ca-cert-hash <HASH>
```
#### 5.3 监控集群状态
Kubernetes集群状态可以通过一系列工具来监控,例如Kubernetes Dashboard、Prometheus和Grafana等。这些工具可以帮助我们监视集群中各个资源的使用情况,及时发现并解决潜在问题。
以上是Kubernetes集群管理的简要介绍,接下来我们将进入常见问题解决部分。
# 6. 常见问题解决
在部署和管理Kubernetes集群的过程中,经常会遇到一些常见问题,下面列举了一些可能遇到的问题以及相应的解决方法。
#### 6.1 kubeadm初始化失败的排查方法
在使用kubeadm初始化Kubernetes集群的过程中,可能会遇到各种问题导致初始化失败。这些问题可能包括网络配置、硬件资源不足、API server无法访问等。针对不同的失败场景,可以采取不同的排查和解决方法,比如检查日志、验证网络连通性、排查硬件资源等。
```bash
# 示例代码
# 检查初始化日志
sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
sudo journalctl -u kubelet
# 验证网络连通性
ping <Master节点IP>
# 排查硬件资源
kubectl get nodes
```
#### 6.2 节点无法加入集群的解决方案
当尝试将Worker节点加入Kubernetes集群时,可能会遇到节点无法加入的问题。这可能是由于节点配置错误、网络问题、证书过期等原因引起的。针对这些问题,可以通过检查节点配置、重新生成证书、验证网络通信等方式来解决。
```bash
# 示例代码
# 检查节点配置
cat /etc/kubernetes/kubelet.conf
# 重新生成证书
kubeadm alpha phase certs all --config=kubeadm-config.yaml
# 验证网络通信
kubectl get nodes
```
#### 6.3 其他常见问题及解决
除了以上列举的常见问题外,还可能会遇到诸如Pod无法调度、集群状态异常、证书过期等其他问题。针对这些问题,可以通过调整调度策略、重启组件、更新证书等方式来解决。
```bash
# 示例代码
# 调度Pod
kubectl describe pod <pod-name>
# 重启组件
kubectl delete pod -n kube-system <pod-name>
# 更新证书
kubeadm alpha phase certs renew all --config=kubeadm-config.yaml
```
以上是一些常见问题的解决方法,希望能帮助读者更好地排查和解决在部署和管理Kubernetes集群过程中可能遇到的各种问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
LabVIEW TCP_IP编程进阶指南:从入门到高级技巧一步到位
# 摘要
本文旨在全面介绍LabVIEW环境下TCP/IP编程的知识体系,从基础概念到高级应用技巧,涵盖了LabVIEW网络通信的基础理论与实践操作。文中首先介绍了TCP/IP通信协议的深入解析,包括模型、协议栈、TCP与UDP的特点以及IP协议的数据包结构。随后,通过LabVIEW中的编程实践,本文展示了TCP/IP通信在LabVIEW平台下的实现方法,包括构建客户端和服务器以及UDP通信应用。文章还探讨了高级应用技巧,如数据传输优化、安全性与稳定性改进,以及与外部系统的集成。最后,本文通过对多个项目案例的分析,总结了LabVIEW在TCP/IP通信中的实际应用经验,强调了LabVIEW在实
移动端用户界面设计要点
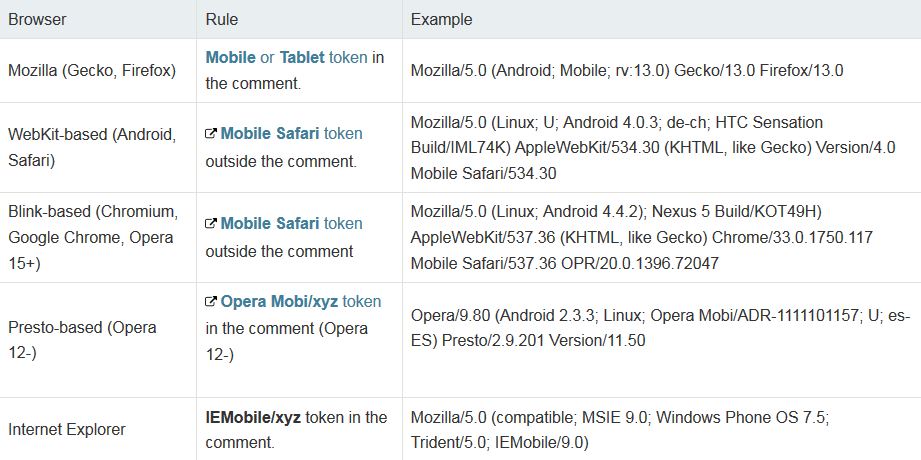
# 摘要
本论文全面探讨了移动端用户界面(UI)设计的核心理论、实践技巧以及进阶话题。第一章对移动端UI设计进行概述,第二章深入介绍了设计的基本原则、用户体验设计的核心要素和设计模式。第三章专注于实践技巧,包括界面元素设计、交互动效和可用性测试,强调了优化布局和响应式设计的重要性。第四章展望了跨平台UI框架的选择和未来界面设计的趋势,如AR/VR和AI技术的集成。第五章通过案例研究分析成功设计的要素和面临的挑战及解决
【故障排查的艺术】:快速定位伺服驱动器问题的ServoStudio(Cn)方法
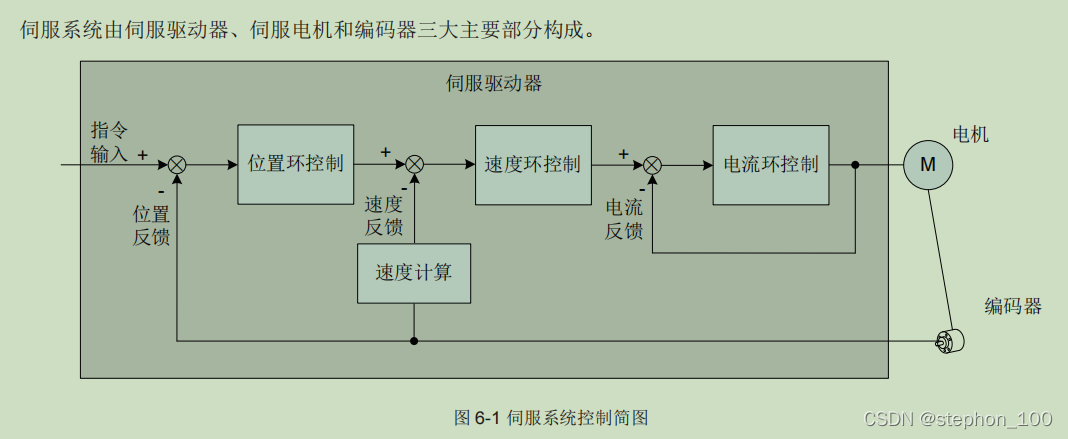
# 摘要
本文全面介绍了伺服驱动器的故障排查艺术,从基础理论到实际应用,详细阐述了伺服驱动器的工作原理、结构与功能以及信号处理机
GX28E01散热解决方案:保障长期稳定运行,让你的设备不再发热
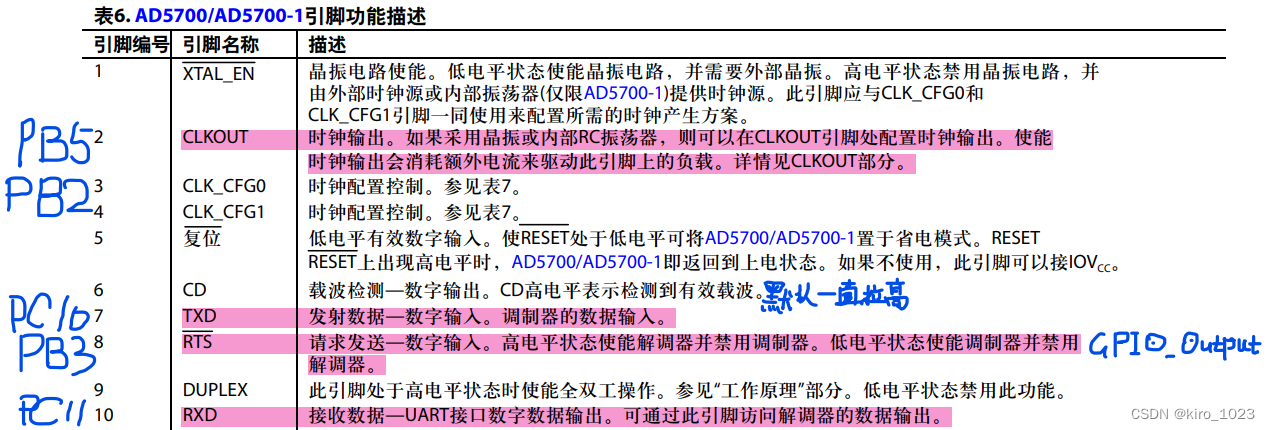
# 摘要
本文针对GX28E01散热问题的严峻性进行了详细探讨。首先,文章从散热理论基础出发,深入介绍了热力学原理及其在散热中的应用,并分析了散热材料与散热器设计的重要性。接着,探讨了硬件和软件层面的散热优化策略,并通过案例分析展示了这些策略在实际中的应用效果。文章进一步探讨了创新的散热技术,如相变冷却技术和主动冷却系统的集成,并展望了散热技术与热管理的未来发展趋势。最后,分析了散热解决方案的经济效益,并探讨了散
无缝集成秘籍:实现UL-kawasaki机器人与PROFINET的完美连接

# 摘要
本文综合介绍了UL-kawasaki机器人与PROFINET通信技术的基础知识、理论解析、实践操作、案例分析以及进阶技巧。首先概述了PROFINET技术原理及其
PDMS设备建模准确度提升:确保设计合规性的5大步骤

# 摘要
本文探讨了PDMS设备建模与设计合规性的基础,深入分析了建模准确度的定义及其与合规性的关系,以及影响PDMS建模准确度的多个因素,包括数据输入质量、建模软件特性和设计者技能等。文章接着提出了确保PDMS建模准确度的策略,包括数据准备、验证流程和最佳建模实践。进一步,本文探讨了PDMS建模准确度的评估方法,涉及内部和外部评估
立即掌握!Aurora 64B-66B v11.2时钟优化与复位策略

# 摘要
本文全面介绍了Aurora 64B/66B的时钟系统架构及其优化策略。首先对Aurora 64B/66B进行简介,然后深入探讨了时钟优化的基础理论,包括时钟域、同步机制和时
掌握CAN协议:10个实用技巧快速提升通信效率
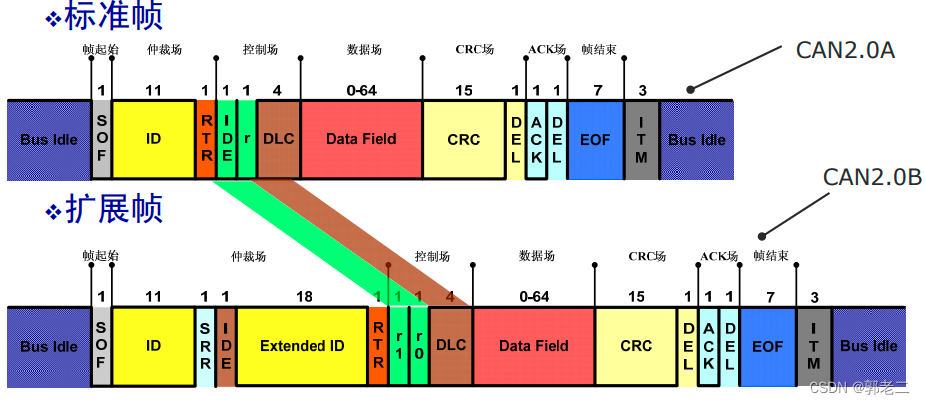
# 摘要
本论文全面介绍了CAN协议的基础原理、硬件选择与配置、软件配置与开发、故障诊断与维护以及在不同领域的应用案例。首先,概述了CAN协议的基本概念和工作原理,然后详细探讨了在选择CAN控制器和收发器、设计网络拓扑结构、连接硬件时应考虑的关键因素以及故障排除技巧。接着,论文重点讨论了软件配置,包括CAN协议栈的选择与配置、消息过滤策略和性能优化。此外,本研究还提供了故障诊断与维护的基
【金字塔构建秘籍】:专家解读GDAL中影像处理速度的极致优化

# 摘要
本文系统地介绍了GDAL影像处理的基础知识、关键概念、实践操作、高级优化技术以及性能评估与调优技巧。文章首先概述了GDAL库的功能和优势,随后深入探讨了影像处理速度优化的理论基础,包括时间复杂度、空间复杂度和多线程并行计算原理,以及GPU硬件加速的应用。在实践操作章节,文章分析了影像格式优化、缓冲区与瓦片技术的应用以及成功案例研究。高级优化技术与工具章节则讨论了分割与融合技术
电子技术期末考试:掌握这8个复习重点,轻松应对考试
# 摘要
本文全面覆盖电子技术期末考试的重要主题和概念,从模拟电子技术到数字电子技术,再到信号与系统理论基础,以及电子技术实验技能的培养。首先介绍了模拟电子技术的核心概念,包括放大电路、振荡器与调制解调技术、滤波器设计。随后,转向数字电子技术的基础知识,如逻辑门电路、计数器与寄存器设计、时序逻辑电路分析。此外,文章还探讨了信号与系统理论基础,涵盖信号分类、线性时不变系统特性、频谱分析与变换。最后,对电子技术实验技能进行了详细阐述,包括电路搭建与测试、元件选型与应用、实验报告撰写与分析。通过对这些主题的深入学习,学生可以充分准备期末考试,并为未来的电子工程项目打下坚实的基础。
# 关键字
模拟
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )