【LAMMPS数据后处理实战】:数据文件与分析工具的完美融合
发布时间: 2024-12-17 05:32:57 阅读量: 27 订阅数: 12 

LAMMPS 19个典型案例包括in文件后处理

参考资源链接:[LAMMPS Data文件创建:从Ms到Atomsk与OVITO](https://wenku.csdn.net/doc/7478dbc96n?spm=1055.2635.3001.10343)
# 1. LAMMPS数据后处理概述
## 简介
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)是一个分子动力学模拟软件,广泛应用于材料科学、化学、物理等领域。数据后处理是LAMMPS模拟完成后的重要步骤,它涉及到数据分析、可视化和结果解释等关键环节。通过有效的数据后处理,研究人员可以从复杂的数据集中提取出有价值的信息,以辅助科学研究和工程决策。
## 数据后处理的重要性
在分子动力学模拟中,模拟运行产生的输出文件包含大量原子级或更高层次的数据。有效利用这些数据,需要对数据进行清洗、组织和分析。数据后处理不仅帮助我们验证模拟的准确性,还可以揭示材料的微观行为和宏观特性之间的联系。例如,通过后处理可以计算晶格常数、扩散系数、结合能等重要的物理量,这些信息对于理解材料的行为至关重要。
## 数据后处理流程
通常,LAMMPS数据后处理流程包括以下几个步骤:
1. **数据收集**:整理LAMMPS输出的各类数据文件,例如轨迹文件(dump文件)和日志文件(log文件)。
2. **数据解析**:解析数据文件,提取需要的信息,如原子坐标、速度、温度等。
3. **数据处理**:对解析出的数据进行必要的预处理,如数据格式转换、数据归一化或数据插值等。
4. **数据分析**:使用统计和分析工具,进行趋势分析、相关性分析等。
5. **数据可视化**:将处理后的数据进行可视化展示,如制作时间序列图、空间分布图等。
6. **结果解释**:根据可视化和分析结果,对研究目标进行解释和讨论。
通过上述流程,研究人员能够深入了解模拟的物理化学过程,为实验设计、材料开发和理论预测提供支撑。在接下来的章节中,我们将详细探讨每一步骤的实现方法和工具应用。
# 2. LAMMPS数据文件解析与管理
## 2.1 LAMMPS数据文件的结构和内容
### 2.1.1 原子数据文件
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)是一款经典的分子动力学模拟软件,其原子数据文件通常用于定义模拟系统的初始条件。原子数据文件包括了原子类型、坐标、速度、质量以及可能的势能参数等信息。
**结构解析:** 在原子数据文件中,以特定格式排列数据,以便LAMMPS能够识别和读取。例如,首行通常记录了原子的总数和类型数,紧接着的是原子类型、坐标和速度等数据。
```text
5 atoms
1 atom types
0.000000 0.000000 0.000000 units box
1 1 1.0 1.0 1.0
2 1 2.0 1.0 1.0
3 1 3.0 1.0 1.0
4 1 4.0 1.0 1.0
5 1 5.0 1.0 1.0
```
在上述示例中,原子数据文件包含5个原子,每个原子属于1个类型。每行的后续数据代表原子的ID、类型以及在盒子单位中的x、y、z坐标。
### 2.1.2 动力学模拟数据文件
动力学模拟数据文件是LAMMPS进行分子动力学模拟的重要输入文件。其包含了原子间势能参数、边界条件、模拟时间步长、总步数等关键信息。
**内容说明:** 这类文件通常以`.in`为扩展名,配置项非常丰富,例如:
```text
units lj
atom_style atomic
boundary p p p
atom_modify map array
read_data data.file
pair_style lj/cut 2.5
pair_coeff 1 1 1.0 1.0 2.5
velocity all create 1.44 87287 loop geom
fix 1 all nve
timestep 0.005
thermo 100
run 10000
```
这里定义了模拟单位(lj),原子类型(atomic),边界条件(p p p),设置了势能参数,并指定了模拟的步长(0.005),总共运行步数(10000步)。该文件指示LAMMPS执行非体积温度等概率(NVE)系综的动力学模拟。
### 2.1.3 热力学数据文件
热力学数据文件包含了LAMMPS模拟中计算出的热力学性质,如温度、压力、能量等信息,这些数据用于后续的分析,以评估模拟系统的热力学行为。
**数据展示:** 这类文件通过LAMMPS的`thermo`命令输出,通常记录了每一步计算的结果。以下是一个简单的热力学数据文件内容展示:
```text
Step Temp E_pair E_vdwl E_kin Press
0 0.14721953 -1.3782128 0.0000000 -0.0000000 0.3286301
100 0.14983311 -1.3673389 0.0000000 -0.0000000 0.3365110
200 0.14602687 -1.3567046 0.0000000 -0.0000000 0.3334219
```
每一行代表了一个时间步长的热力学数据,`Step` 是模拟步数,`Temp` 是系统温度,`E_pair` 和 `E_vdwl` 分别是配对势能和范德华势能,`E_kin` 是动能,`Press` 是压力。
## 2.2 数据文件的组织和管理
### 2.2.1 多数据文件处理策略
在复杂的模拟项目中,经常需要处理多个数据文件。合理组织和管理这些文件对于确保模拟的准确性和效率至关重要。
**策略实践:** 可以使用shell脚本批量处理,例如:
```bash
#!/bin/bash
for file in *.data; do
lmp -in ${file/.data/.in} > ${file/.data/.log}
done
```
上述脚本中,利用循环遍历所有`.data`扩展名的文件,然后执行LAMMPS命令将每个数据文件转换为对应的输入文件,最后运行模拟,并把输出保存到`.log`文件。
### 2.2.2 数据文件的归档与检索
随着模拟规模的增加,数据文件会迅速积累,合理地进行数据归档与检索变得尤为重要。
**归档与检索:** 可以使用tar命令进行数据压缩,以及使用grep等工具进行数据检索。
```bash
tar -czf simulation_data.tar.gz *.data *.log
grep "Temperature" simulation.log
```
第一个命令创建了一个包含所有数据文件的压缩包,第二个命令则用于快速检索log文件中与温度相关的数据。
## 2.3 数据文件的预处理
### 2.3.1 数据清洗技巧
数据清洗是确保模拟前数据质量的关键步骤,包括检查数据的完整性、一致性、准确性等。
**技巧应用:** 可以使用文本编辑器手动修正错误,或编写脚本自动化数据清洗。例如,使用Python脚本检查和修正原子ID的唯一性:
```python
import pandas as pd
data = pd.read_csv("datafile.data", delim_whitespace=True)
if any(data['id'].duplicated()):
data['id'] = pd.RangeIndex(len(data))
data.to_
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探究 LAMMPS 中的数据文件,提供全面的指南,涵盖从新手入门到专家优化等各个方面。它深入解析数据结构,指导构建高性能模拟,并提供高级配置和个性化设置技巧。专栏还探讨了复杂系统的构建、调试和性能提升策略,以及数据可视化和后处理工具。此外,它还介绍了脚本自动化、分子动力学基础、热力学分析、机械性能测试、扩散模拟、界面模拟、生物分子模拟、优化算法和并行计算等主题。通过深入浅出的讲解和丰富的实战案例,该专栏旨在帮助读者掌握 LAMMPS 数据文件,提升模拟效率,并探索材料科学、生物物理学和化学等领域的广泛应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微信小程序前端开发必读:表单交互的单选与多选按钮逻辑

# 摘要
微信小程序作为快速发展的应用平台,其表单元素的设计与实现对于用户体验至关重要。本文首先介绍了微信小程序表单元素的基础知识,重点讨论了单选按钮和多选按钮的实现原理、前端逻辑以及样式美化和用户体验优化。在第四章中,探讨了单选与多选在表单交互设计中的整合,以及数据处理和实际应用案例。第五章分析了表单数据的性能优化和安全性考虑,包括防止XSS和CSRF攻击以及数据加密。最后,第六章通过实战演
高级机器人控制算法实现:Robotics Toolbox深度剖析与实践
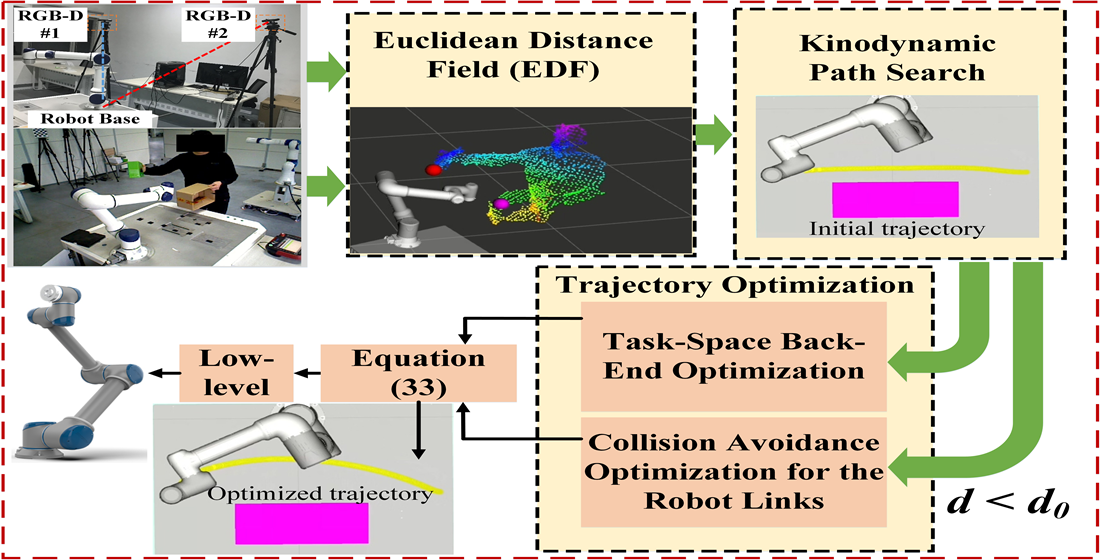
# 摘要
本文全面介绍机器人控制算法的理论基础和实践应用,重点讲解了Robotics Toolbox的理论与应用,并探讨了机器人视觉系统集成的有效方法。文章从基础理论出发,详细阐述了机器人运动学与动力学模型、控制策略以及传感器集成,进而转向实践,探讨了运动学分析、动力学仿真、视觉反馈控制策略及
TerraSolid实用技巧:提升你的数据处理效率,专家揭秘进阶操作详解!

# 摘要
TerraSolid软件作为专业的遥感数据处理工具,广泛应用于土木工程、林业监测和城市规划等领域。本文首先概述了TerraSolid的基本操作和数据处理核心技巧,强调了点云数据处理、模型构建及优化的重要性。随后,文章深入探讨了脚本自动化与自定义功能,这些功能能够显著提高工作效率和数据处理能力。在特定领域应用技巧章节中,本文分析了TerraSolid在土木、林
【目标代码生成技术】:从编译原理到机器码的6大步骤
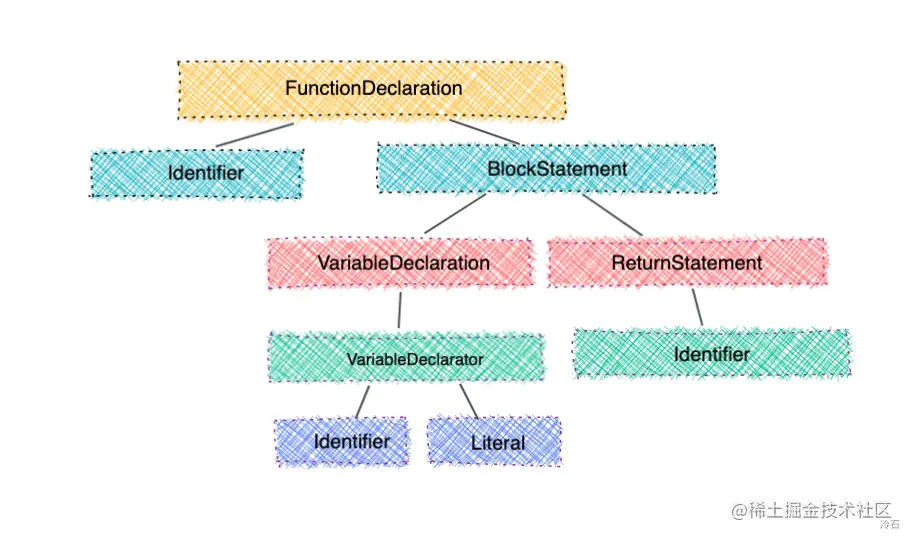
# 摘要
本文旨在全面探讨目标代码生成技术,从编译器前端的词法分析和语法分析开始,详细阐述了抽象语法树(AST)的构建与优化、中间代码的生成与变换,到最终的目标代码生成与调度。文章首先介绍了词法分析器构建的关键技术和错误处理机制,然后讨论了AST的形成过程和优化策略,以
公钥基础设施(PKI)深度剖析:构建可信的数字世界
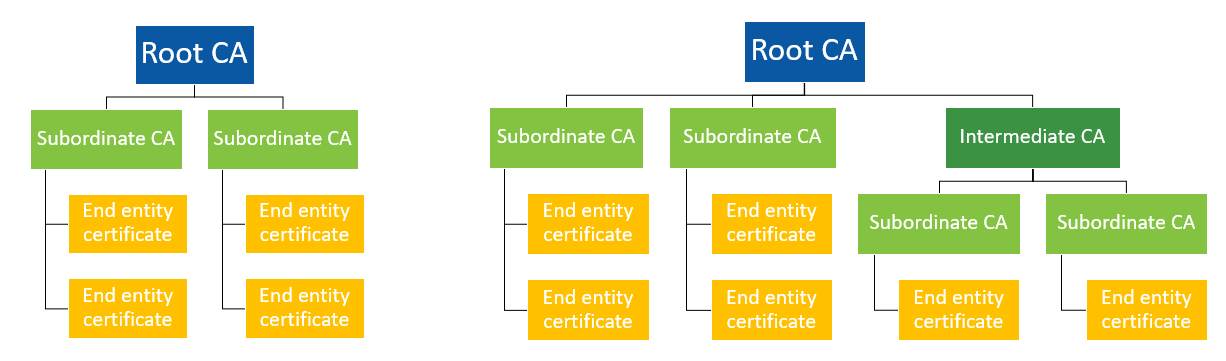
# 摘要
公钥基础设施(PKI)是一种广泛应用于网络安全领域的技术,通过数字证书的颁发与管理来保证数据传输的安全性和身份验证。本文首先对PKI进行概述,详细解析其核心组件包括数字证书的结构、证书认证机构(CA)的职能以及证书颁发和撤销过程。随后,文章探讨了PKI在SSL/TLS、数字签名与身份验证、邮件加密等领域的应用实践,指出其在网络安全中的重要性。接着,分析了PKI实施过程中的
硬件测试新视角:JESD22-A104F标准在电子组件环境测试中的应用
# 摘要
本文对JESD22-A104F标准进行了全面的概述和分析,包括其理论基础、制定背景与目的、以及关键测试项目如高温、低温和温度循环测试等。文章详细探讨了该标准在实践应用中的准备工作、测试流程的标准化执行以及结果评估与改进。通过应用案例分析,本文展示了JESD22-A104F标准在电子组件开发中的成功实践和面临的挑战,并提出了相应的解决方案。此外,本文还预测了标准的未来发展趋势,讨论了新技术、新材料的适应性,以及行业面临的挑战和合作交流的重要性。
# 关键字
JESD22-A104F标准;环境测试;高温测试;低温测试;温度循环测试;电子组件质量改进
参考资源链接:[【最新版可复制文字
MapReduce常见问题解决方案:大数据实验者的指南

# 摘要
MapReduce是一种广泛应用于大数据处理的编程模型,它通过简化的编程接口,允许开发者在分布式系统上处理和生成大规模数据集。本文首先对MapReduce的概念、核心工作流程、以及其高级特性进行详细介绍,阐述了MapReduce的优化策略及其在数据倾斜、作业性能调优、容错机制方面的常见问题和解决方案。接下来,文章通过实践案例,展示了MapReduce在不同行业的应用和效果。最后,本
【Omni-Peek教程】:掌握网络性能监控与优化的艺术

# 摘要
网络性能监控与优化是确保网络服务高效运行的关键环节。本文首先概述了网络性能监控的重要性,并对网络流量分析技术以及网络延迟和丢包问题进行了深入分析。接着,本文介绍了Omni-Peek工具的基础操作与实践应用,包括界面介绍、数据包捕获与解码以及实时监控等。随后,文章深入探讨了网络性能问题的诊断方法,从应用层和网络层两方面分析问题,并探讨了系统资源与网络性能之间的关系。最后,提出了网络性能优
【PCB设计:电源完整性的提升方案】
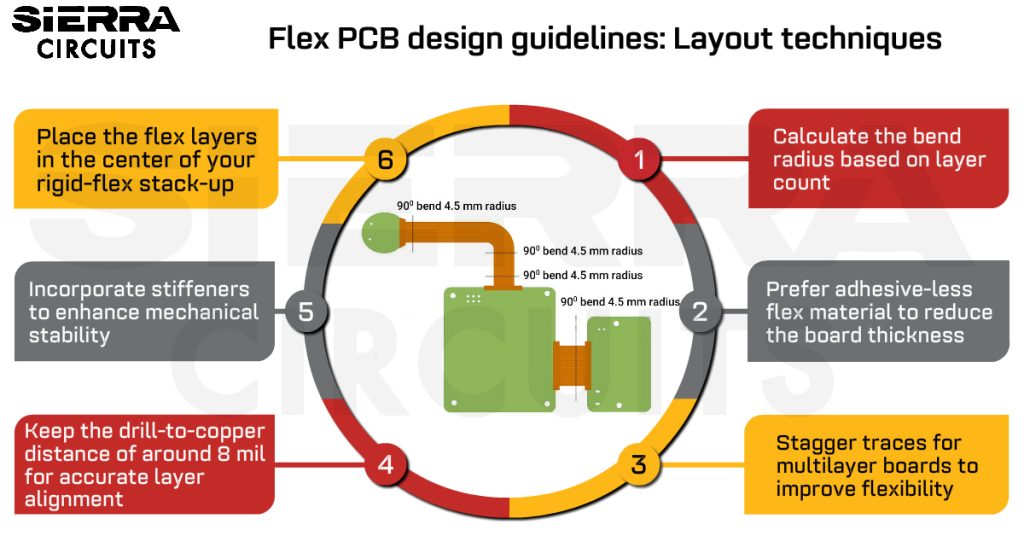
# 摘要
电源完整性作为电子系统性能的关键因素,对现代电子设备的稳定性和可靠性至关重要。本文从基本概念出发,深入探讨了电源完整性的重要性及其理论基础,包括电源分配网络模型和电源噪声控制理论。通过分析电源完整性设计流程、优化技术以及测试与故障排除策略,本文提供了电源完整性设计实践中的关键要点,并通过实际案例分析展示了高
【组合数学在电影院座位设计中的角色】:多样布局的可能性探索

# 摘要
本文探讨了组合数学与电影院座位设计的交汇,深入分析了组合数学基础及其在座位设计中的实际应用。文章详细讨论了集合与排列组合、组合恒等式与递推关系在空间布局中的角色,以及如何通过数学建模解决座位设计中的优化问题。此外,研究了电影院座位布局多样性、设计优化策略,以及实际案例分析,包括创新技术的应用与环境可持续性考量。最后,对电影院座位设计的未来趋势进行了预测,并讨论了相关挑战与应对策略。本文旨在提供一个全面的视角,将理论与实践相
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )