TensorRT优化指南:提升模型性能的最佳实践
发布时间: 2024-03-27 03:41:44 阅读量: 122 订阅数: 36 

TensorRT-Best-Practices.pdf
# 1. 介绍TensorRT及其作用
TensorRT是英伟达(NVIDIA)推出的高性能神经网络推理(Inference)引擎,旨在提供最佳的推理性能和低延迟,适用于深度学习模型。TensorRT利用深度学习推理的主要优势,即在最新的NVIDIA GPU架构上进行优化,从而实现快速且高效的模型推理。通过TensorRT,开发人员可以将经过训练的深度学习模型转换为高效的推理引擎,以利用GPU的并行计算能力来加速推理过程。
TensorRT的主要作用包括但不限于:
- 加速深度学习推理过程
- 优化模型以提高推理性能
- 针对特定GPU架构进行优化
- 支持FP16精度推理,提高性能的同时减少内存占用
- 支持批处理和流水线操作,进一步提高推理性能
在接下来的章节中,我们将深入探讨TensorRT优化模型的准备工作以及优化工具和技术的具体应用。
# 2. 模型优化前的准备工作
在进行模型优化之前,我们需要进行一些准备工作,确保我们能够顺利地使用TensorRT进行加速。以下是一些关键的准备工作步骤:
1. **选择合适的模型架构:** 在选择模型时,要考虑到模型的推理速度和准确性之间的平衡。通常,深度神经网络模型中的参数越多,推理速度就会越慢,因此需要根据应用场景进行权衡选择。
2. **导出模型:** 在选择好模型后,需要将其导出为常见的深度学习框架支持的模型格式,如TensorFlow的.pb文件、PyTorch的.pth文件等。
3. **准备测试数据:** 在进行模型优化前,需要准备一定量的测试数据,以便在优化后对模型性能进行评估。
4. **安装TensorRT:** 在开始优化之前,需要确保已经正确安装了NVIDIA的TensorRT库,并且版本与所使用的深度学习框架兼容。
5. **熟悉TensorRT API:** 在进行模型优化时,需要熟悉TensorRT的API接口,以便正确地使用TensorRT对模型进行优化。
通过以上准备工作,我们可以更好地进行模型优化,提高推理速度并降低计算成本。接下来,我们将介绍TensorRT的优化工具和技术,帮助读者更深入地了解如何利用TensorRT加速深度学习模型的推理过程。
# 3. TensorRT优化工具和技术概述
TensorRT是一个用于高性能深度学习推理的C++库,由NVIDIA开发和维护。它可以优化深度学习模型,提高推理性能,降低延迟,并有效管理内存使用。TensorRT支持各种深度学习框架,如TensorFlow、PyTorch和ONNX等。
TensorRT包含以下主要组件和优化技术:
- **深度学习推理引擎**: 用于构建和优化深度学习模型进行推理的引擎。可在生产环境中部署高性能推理。
- **层和算法优化**: TensorRT通过融合相邻层、量化权重、剪枝等技术优化深度学习模型。
- **内存优化**: 可减少推理期间的内存占用,提高推理性能。
- **精度混合**: 可以在FP16和INT8等低精度数据类型上进行推理,提高性能的同时减少计算成本。
- **动态尺寸支持**: TensorRT支持动态尺寸的输入和输出,适用于不固定尺寸的推理。
通过利用TensorRT提供的这些工具和技术,可以显著提高深度学习模型的推理性能和效率。
# 4. 使用FP16精度加速推理
在TensorRT中,使用FP16精度进行推理可以显著加速模型的计算过程。FP16(Half Precision)是一种低精度浮点数表示方法,可以有效减少计算的内存占用和运算时间。下面我们将演示如何在TensorRT中使用FP16精度进行推理优化。
```python
import tensorrt as trt
import pycuda.driver as cuda
import numpy as np
# 创建TensorRT引擎
def build_engine_fp16(onnx_file_path):
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
parser = trt.OnnxParser(network, TRT_LOGGER)
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
builder.fp16_mode = True
engine = builder.build_cuda_engine(network)
return engine
# 加载FP16引擎进行推理
def infer_fp16(engine, input_data):
runtime = trt.Runtime(trt.Logger(trt.Logger.INFO))
context = engine.create_execution_context()
input_shape = engine.get_binding_shape(0)
input_host = input_data.astype(np.float32)
input_device = cuda.mem_alloc(input_host.nbytes)
output_shape = engine.get_binding_shape(1)
output_host = np.empty(output_shape, dtype=np.float32)
output_device = cuda.mem_alloc(output_host.nbytes)
with engine.create_execution_context() as context:
cuda.memcpy_htod(input_device, input_host)
context.set_binding_shape(0, input_shape)
context.set_binding_shape(1, output_shape)
context.execute_v2([int(input_device), int(output_device)])
cuda.memcpy_dtoh(output_host, output_device)
return output_host
# 加载模型并进行推理
engine = build_engine_fp16('model.onnx')
input_data = np.random.rand(1, 3, 224, 224).astype(np.float32)
output = infer_fp16(engine, input_data)
# 输出推理结果
print(output)
```
通过上述代码示例,我们成功构建了一个使用FP16精度进行推理优化的TensorRT引擎,并且进行了简单的推理过程演示。通过这种方式,可以加速模型的计算并减少内存占用,提高推理效率。
# 5. 使用FP16精度加速推理
在推理过程中,常规情况下我们使用的是32位浮点数(FP32)进行计算。TensorRT提供了一种可以加速推理过程的技术,就是使用半精度浮点数(FP16)来进行计算。虽然FP16的计算范围较窄,但在很多情况下可以取得比较好的加速效果。
下面我们将演示如何在TensorRT中使用FP16精度来加速推理过程。
```python
import tensorrt as trt
# 创建一个TensorRT的builder对象
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
# 定义输入和输出的tensor
input_tensor = network.add_input('input', dtype=trt.float32, shape=(1, 3, 224, 224))
output_tensor = network.add_output('output', dtype=trt.float32, shape=(1, 1000))
# 添加网络层
# 设置builder的配置,将精度设置为FP16
builder.fp16_mode = True
# 构建Engine
engine = builder.build_cuda_engine(network)
```
**代码说明**:
- 首先导入TensorRT库。
- 创建一个TensorRT的builder对象,并创建一个网络。
- 定义输入和输出的tensor。
- 将网络层加入到网络中。
- 将builder的精度模式设置为FP16。
- 使用builder来构建一个CUDA Engine。
通过以上步骤,我们就成功地将精度设置为FP16,从而加速了推理过程。
**结果说明**:
使用FP16精度进行推理一般会带来一定的性能提升,尤其是在支持混合精度计算的GPU上。但需要注意的是,由于FP16的计算范围较窄,可能会导致精度损失,所以在实际应用中需要根据具体情况进行权衡和测试。
# 6. 减少网络层和冗余操作
在进行模型优化时,我们需要仔细审视网络结构,减少不必要的网络层和冗余操作,以提高推理效率和减少推理时间。
以下是一个示例代码,展示如何通过减少网络层和冗余操作来优化模型:
```python
import torch
import torchvision
import onnx
import onnx_tensorrt
# 导入PyTorch模型
model = torchvision.models.alexnet(pretrained=True)
model.eval()
# 创建虚拟输入数据
x = torch.randn(1, 3, 224, 224, requires_grad=True)
# 导出ONNX模型
torch.onnx.export(model, x, "alexnet.onnx", export_params=True)
# 加载ONNX模型
onnx_model = onnx.load("alexnet.onnx")
# 检查模型并优化
optimized_model = onnx_tensorrt.optimizer.optimize(onnx_model)
# 保存优化后的模型
onnx.save(optimized_model, "optimized_alexnet.onnx")
print("模型优化完毕!")
```
在这段代码中,我们首先导入PyTorch中的AlexNet模型,并将其导出为ONNX格式。然后,我们使用TensorRT中的优化器对模型进行优化,最后保存优化后的模型文件。
通过减少网络层和冗余操作,我们可以显著提高模型推理的速度和效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"tensorrt部署"为主题,涵盖了多篇文章,囊括了TensorRT的基础概念、优化指南、与其他部署工具的性能对比、以及在不同领域中的应用实践等内容。从初识TensorRT到深入探究其与深度学习框架的集成,再到如何在嵌入式设备上进行优化部署,专栏中旨在为读者提供全面的知识体系和实用技巧。无论是针对模型性能提升的最佳实践,还是针对大规模推理服务的搭建指南,本专栏将为读者带来丰富而实用的内容,帮助他们更好地利用TensorRT进行深度学习模型部署与优化。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
昆仑通态MCGS脚本编程进阶课程:脚本编程不再难

# 摘要
MCGS脚本编程作为一种适用于工业人机界面(HMI)的脚本语言,具备自动化操作、数据处理和设备通讯等功能。本文深入探讨了MCGS脚本的基础语法,实践技巧,以及高级功能开发,包括变量、常量、数据类型、控制结构、函数定义、人机界面交互、数据动态显示、设备通讯等关键要素。通过对多个实际案例的分析,展示了MCGS脚本编程在提高工业自动化项目效率和性能方面的应用。最后,本文展望了MCGS脚本编程的未来趋势,包括新技术
深入解析ISO20860-1-2008:5大核心策略确保数据质量达标

# 摘要
本文全面探讨了ISO20860-1-2008标准在数据质量管理领域的应用与实践,首先概述了该标准的基本概念和框架,随后深入阐述了数据质量管理体系的构建过程,包括数据质量管理的原则和关键要求。文中详细介绍了数据质量的评估方法、控制策略以及持续改进的措施,并探讨了核心策略在实际操作中的应用,如政策制定、技术支持和人力资源管理。最后,通过案例研究分析与
【BSC终极指南】:战略规划到绩效管理的完整路径
# 摘要
平衡计分卡(Balanced Scorecard, BSC)作为一种综合战略规划和绩效管理工具,已在现代企业管理中广泛运用。本文首先介绍了BSC战略规划的基础知识,随后详细阐述了BSC战略地图的构建过程,包括其概念框架、构建步骤与方法,并通过案例研究深入分析了企业实施BSC战略地图的实操过程与效果。第三章聚焦于绩效指标体系的开发,讨论了绩效指标的选择、定义、衡量和跟踪方法。第四章探讨了BSC如何与组织绩效管理相结合,包括激励机制设计、绩效反馈和持续改进等策略。最后,本文展望了BSC战略规划与绩效管理的未来发展趋势,强调了BSC在应对全球化和数字化挑战中的创新潜力及其对组织效能提升的重
卫星信号捕获与跟踪深度解析:提升定位精度的秘诀

# 摘要
本文全面探讨了卫星信号捕获与跟踪的基础知识、理论与实践、提升定位精度的关键技术,以及卫星导航系统的未来发展趋势。从信号捕获的原理和算法分析开始,深入到信号跟踪的技术细节和实践案例,进一步讨论了影响定位精度的关键问题及其优化策略。本文还预测了卫星导航系统的发展方向,探讨了定位精度提升对行业和日常生活的影响。通过对多径效应的消除、环境干扰的抗干扰技术的深入研究,以及精度优化
【Shell脚本自动化秘籍】:4步教你实现无密码服务器登录
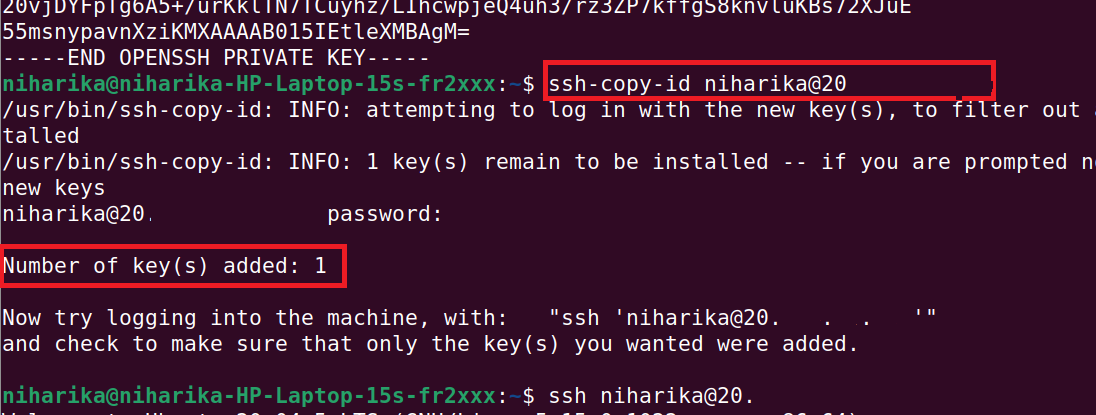
# 摘要
随着信息技术的快速发展,自动化成为了提高运维效率的重要手段。本文首先介绍了Shell脚本自动化的基本概念,接着深入探讨了SSH无密码登录的原理,包括密钥对的生成、关联以及密钥认证流程。此外,文章详细阐述了提高无密码登录安全性的方法,如使用ssh-agent管理和配置额外的安全措施。进一步地,本文描述了自动化脚本编写和部署的关键步骤,强调了参数化处理和脚本测试的重要性
【SR-2000系列扫码枪集成秘籍】:兼容性分析与系统对接挑战

# 摘要
本文详细介绍了SR-2000系列扫码枪的特性、兼容性、系统对接挑战及实际应用案例,并对其未来技术发展趋势进行了展望。首先概述了SR-2000系列扫码枪的基础知识,随后深入探讨了其在不同软硬件环境下的兼容性问题,包括具体的兼容性测试理论、问题解析以及解决方案和最佳实践。接着,文章着重分析了SR-2000系列在系统对接中面临的挑战,并提供了应对策略和实施步骤。实际应用案例分析则涵盖了零售、医疗健康和
PLECS个性化界面:打造属于你的仿真工作空间
# 摘要
PLECS个性化界面是一个强大的工具,可帮助用户根据特定需求定制和优化工作空间。本文旨在全面介绍PLECS界面定制的基础知识、高级技巧和实际应用场景。首先,概述了PLECS界面定制的原则和方法,包括用户理念和技术途径。接着,探讨了布局和组件的个性化,以及色彩和风格的应用。第三章深入讨论了高级定制技巧,如使用脚本自动化界面、数据可视化和动态元素控制。第四章展示了PLECS界面在仿真工
华为云服务HCIP深度解析:10个关键问题助你全面掌握云存储技术
# 摘要
华为云服务HCIP概述了华为云存储产品的架构、关键技术、技术特色、性能优化以及实践应用,同时探讨了华为云存储在安全与合规性方面的策略,并展望了云存储技术的未来趋势。文章深入解析了云存储的定义、逻辑结构、数据分布式存储、冗余备份策略以及服务模式。针对华为产品,介绍了其产品线、功能、技术特色及性能优化策略。实践应用部分阐述了华为云存储解决方案的部署、数据迁移与管理以及案例
微服务架构下的服务网格实战指南
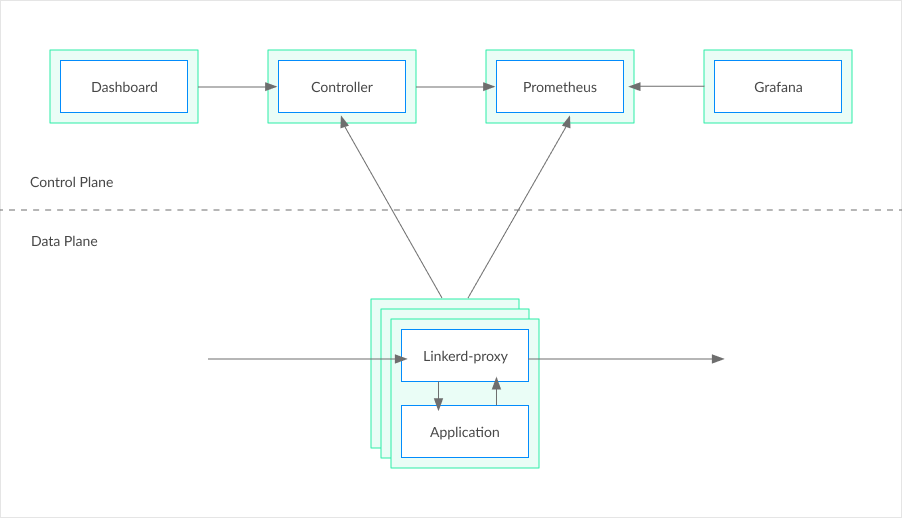
# 摘要
本文系统地探讨了微服务架构下服务网格技术的各个方面。首先介绍了服务网格的基础概念和重要性,然后详细比较了主流服务网格技术,如Istio和Linkerd,并指导了它们的安装与配置。接着,探讨了服务发现、负载均衡以及高可用性和故障恢复策略。文章深入分析了服务网格的安全性策略,包括安全通信、安全策略管理及审计监控。随后,重点讨论了性能优化和故障排除技巧,并介
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )